







TextCNN 模型主要由一维卷积层和时序最大池化层构成,一维卷积层是高为 1 的二维卷积层,在每个通道上,卷积核与输入做互相关运算,并将通道之间的结果相加得到输出结果。

时序最大池化层对应一维全局最大池化层,特点是卷积窗口和输入数组的宽高对应相同,每个通道只输出一个元素。例如,输入的文本序列由 n 个词组成,词向量为 d 维,输入样本的宽为 n,高为1,输入通道数为 d,卷积核的高度为 d,卷积核的个数即为输出通道数。
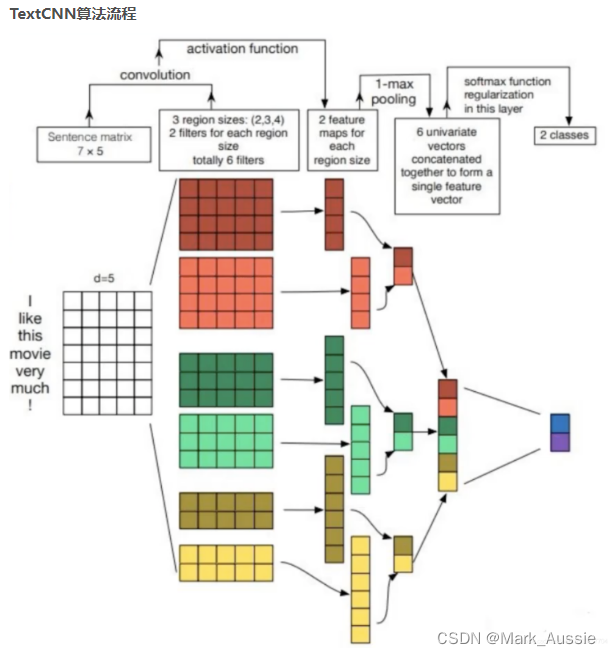
TextCNN步骤:
定义多个一维卷积核,对输入分别做卷积计算,宽度不同的卷积核会捕捉到不同个数的相邻词的相关性。对输出的所有通道分别做时序最大池化,将通道的池化输出值连结为向量。通过全连接层将连结后的向量变换为有关各类别的输出。
如上面的流程图,输入文本 shape 为 7 * 5,设置了三种卷积,高为(3,4,5),宽都为 5,每种卷积数量为 2,每个卷积输出 (7 - (3/4/5)) + 1 个结果,再用最大池化,将池化结果时输入全连接。
PyTorch 实例
filter_num = 2,embed_dim=128,seq_len=17,filter_size=[3,4,5]
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNNModule(nn.Module):
def __init__(self, seq_len, filter_num, filter_size, vocab_size, embed_dim, class_num):
super(TextCNNModule, self).__init__()
self.seq_len = seq_len
self.filter_size = filter_size
self.total_filter_num = filter_num * len(filter_size)
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.weight = nn.Linear(self.total_filter_num, class_num, bias=False)
self.Bias = nn.Parameter(torch.ones([class_num]))
self.filter_list = nn.ModuleList([nn.Conv2d(1, filter_num, (i, embed_dim)) for i in filter_size])
def forward(self, X):
embed_char = self.embedding(X)
embed_char = embed_char.unsqueeze(1) # 增加一个维度
pooled_output = []
for i, conv in enumerate(self.filter_list):
conv2d = conv(embed_char)
h = F.relu(conv2d)
p = nn.MaxPool2d((self.seq_len - self.filter_size[i] + 1, 1))
pooled = p(h).permute(0, 3, 2, 1)
pooled_output.append(pooled)
h_pool = torch.cat(pooled_output, len(self.filter_size))
h_pool_flat = torch.reshape(h_pool, [-1, self.total_filter_num])
m = self.weight(h_pool_flat) + self.Bias
return m
seq_len=17,conv_num=2,conv_size_list=[3,4,5]
class TextCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, seq_len, conv_num, conv_size_list, dropout, class_num):
super(TextCNN, self).__init__()
self.seq_len = seq_len
self.conv_size_list = conv_size_list
self.embed = nn.Embedding(vocab_size, embedding_dim)
# 1 代表输入 channel, conv_num 代表输出 channel, 输入是图片时两者应相同;
# 处理文本时输入是一条文本样本, 其channel为1, 如10个token的样本, shape=(10, embed_dim),
# conv_num 代表用conv_num个核的卷积对样本做卷积计算,每个核输出一个值
self.conv_list = nn.ModuleList([nn.Conv2d(1, conv_num, (i, embedding_dim)) for i in conv_size_list])
self.dropout = nn.Dropout(dropout)
total_conv_num = conv_num * len(conv_size_list)
self.fc = nn.Linear(total_conv_num, class_num, bias=True)
def forward(self, x):
x_embed = self.embed(x).unsqueeze(1) # 在第二个位置添加一维,shape=(4,1,17,128)
pools = []
for index, conv in enumerate(self.conv_list):
x_conv = conv(x_embed)
# xr = nn.ReLU(x_conv) # nn.ReLU()返回的是ReLU类
x_conv_sq = x_conv.squeeze(3)
xr = F.relu(x_conv_sq) # F.relu()返回的是tensor
xr_sq = xr.squeeze(2)
p = nn.MaxPool1d(self.seq_len - self.conv_size_list[index] + 1, 1)
# p = F.max_pool1d(self.seq_len - self.conv_size_list[index] + 1, 1) # 输入需要是 tensor
x_pool = p(xr_sq) # shape(4,2,1), 2代表的是conv_num, 每个 conv 输出一个结果
pools.append(x_pool)
h_pool = torch.cat(pools, 1) # 按照pools中元素(x_pool)第二个维度合并, shape=(4,6,1)
h_pool = h_pool.squeeze(2) # 去除最后一维(1), shape=(4,6)
# x_drop = self.dropout(h_pool) # 数据量小时,可能导致欠拟合
output = self.fc(h_pool)
return output
使用Conv1d遇到的问题
使用CNN中的conv1d做特征提取,输入数据特征为50,随机生成了1000条数据,目标是用每条数据的50个特征做回归预测。
定义模型时开始使用如下输入shape,报错:ValueError: One of the dimensions in the output is <= 0 due to downsampling in conv1d. Consider increasing the input size. Received input shape [None, 1, 50] which would produce output shape with a zero or negative value in a dimension.
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(1, 50)))
解决办法:调整输入shape,Conv1d是为时间序列设计的,我的目标是用一条50个特征做预测,划分数据时一条数据就是一个批次,训练时只是使用batch_size参数,网上有解释此处不能为1。
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(50, 1)))
Pytorch中的conv1d
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
in_channels (int):输入图片的通道数量,在文本分类中为词向量的维度
out_channels (int) :卷积产生的通道,代表1维卷积数量;
kernel_size (int or tuple) :卷积核的尺寸,第二个维度由in_channels决定,卷积核大小为kernel_size*in_channels
stride (int or tuple, optional):卷积步长,Default=1;
padding (int or tuple, optional) :输入的每一条边补充0的层数,Default=0
padding_mode (string, optional) :‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’,Default=‘zeros’
dilation (int or tuple, optional) :Spacing between kernel elements,Default=1
groups (int, optional) :Number of blocked connections from input channels to output channels, Default=1,该参数控制输入和输出的连接。当groups = 2时,相当于有两个conv层并排,每个conv层看到一半的输入通道,产生一半的输出通道,然后两者concate起来。
当groups = in_channels 且out_channels = K * in_channels, K为正整数,得到 “depthwise convolution”。
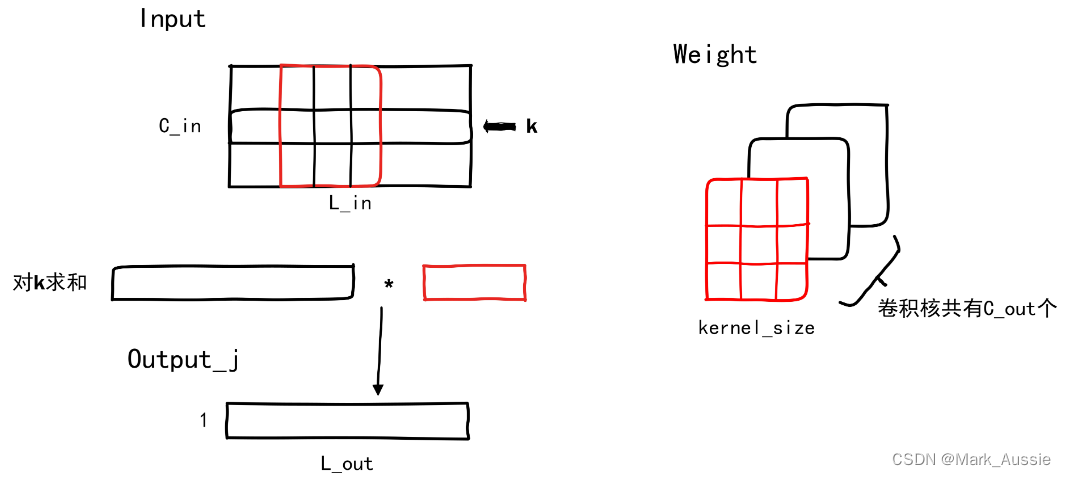
一维卷积计算示意图
有C_out个卷积核,取一个卷积核(红色部分),让其在输入数据中“滑动”,“滑动”的次数代表输出的序列长度。
输入矩阵的第 k行和卷积核的第k行做互相关的计算,即卷积核不断移动,与输入对应位置的元素做对应元素逐个相乘并求和。
纵向看,输入的每一个通道与卷积核相应行卷积出的向量(序列)加在一起。
参考:
pytorch 实现 textCNN_pytorch textcnn_明日何其多_的博客-CSDN博客
pytorch搭建TextCNN与使用案例_textcnn pytorch_呆萌的代Ma的博客-CSDN博客















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









