







在之前的文章中,我提到过dplyr中有一个summarize函数。今天我们来说一下,到底可以汇总哪些信息。
dplyr整理数据
一、简介
汇总函数
- mean(x)取平均数
- median(x)取中位数
- min(x)最小数
- max(x)最大数
- quantile(x,0.25)四分位数(比数据中25%的要大,但比75%的要小)
- first(x)取向量x的第一个值
- last(x)取向量x的最后一个值
- nth(x,2)去向量的第2个值
- n() 不需要参数,返回组的大小
10.n_distinct(x)返回向量x中有多少个独特的值 - count(x)是n()的增强版
以上很多x都可以换成逻辑值比如说:count(x$某一列 > 10)
例子演示
用的还是上次的flights数据集。
n()举例
直接统计flights数据集的个数
summarise(flights,n())
结果如下: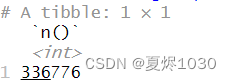
count举例
例1:统计去往不同目的地的航班个数
# 先筛选出没有取消的航班(即去除NA值)
not_cancelled <- flights %>% filter(!is.na(dep_delay),!is.na(arr_delay))
# 按照dest统计航班的数量
not_cancelled %>% count(dest)
结果如下:

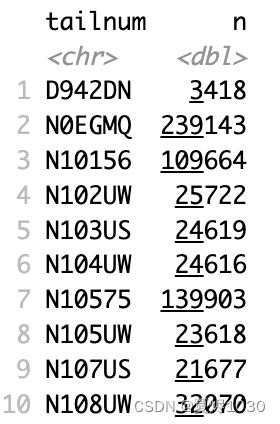
例2:统计不同航班的总里程数
count这个函数如果在加一个wt参数,就可以做sum计算。比如说:
count(x,wt=y)
这就等于按照x进行分组,同时对y进行求和。
not_cancelled %>% count(tailnum,wt=distance)
二、结合group_by函数
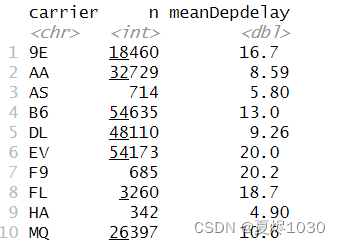
summarize函数和group_by结合往往能进行更具有意义的分析。
比如我们想分析不同航班的平均dep_delay:
flights %>% group_by(carrier)%>% summarize(n=n(),meanDepdelay=mean(dep_delay,na.rm = TRUE))















 2315
2315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









