







一、介绍
在R中,因子factor常是分类变量。这些变量是已知的、固定的一组值,比如男女,小学生、中学生、大学生等等。
因为在以前,因子操作起来会比字符串更方便,所以基础的R会自动把字符串转为因子。这也导致了,数据集中出现了许多不必要的因子。
但在tidyverse中没有这样的烦恼。forcats就是专门处理因子的一个库,但是它不是tidyverse的核心成员,我们需要额外加载。
二、因子基础
创建因子
创建因子总共分三步。
第一步:创建一个因子组成的字符串向量。
x1 <- c("Mar","Apr","May")`
第二步:创建因子的有效水平列表。
month_level <- c("Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec")`
第三步,通过factor函数来创建一个因子。
y1 <- factor(x1, levels=month_level)
我们打印一下y1看一看

但是如果我们创建的字符串向量中,如果不在level中的话,那会怎样呢?

你瞅瞅,所有没在level中的都被设定成了NA。
这也能让我们避免一些拼写错误。
怎么理解这个因子有效水平列表呢(valid level)?
一方面,它规定了因子的排序,就像电脑怎么才能知道小学生中学生和大学生的排序呢?我们通过level来告诉它;另一方面,它更像是因子的一个集合。
当然,必须设置有效水平(valid level)么?答案是否定的。如果你省去了level,电脑会默认按照字母顺序给因子排序。
除此之外,还有一种方法。
f1 <- x1 %>% factor () %>% fct_inorder()
在这里,我们先用factor创建一个因子,然后用fct_inorder给它指定一个顺序,这个顺序就是我们最初给它的那个顺序。
三、实际应用
使用的数据集
我们使用forcats库提供的gss_cat数据集。
gss_cat是来自综合社会调查的分类变量样本。
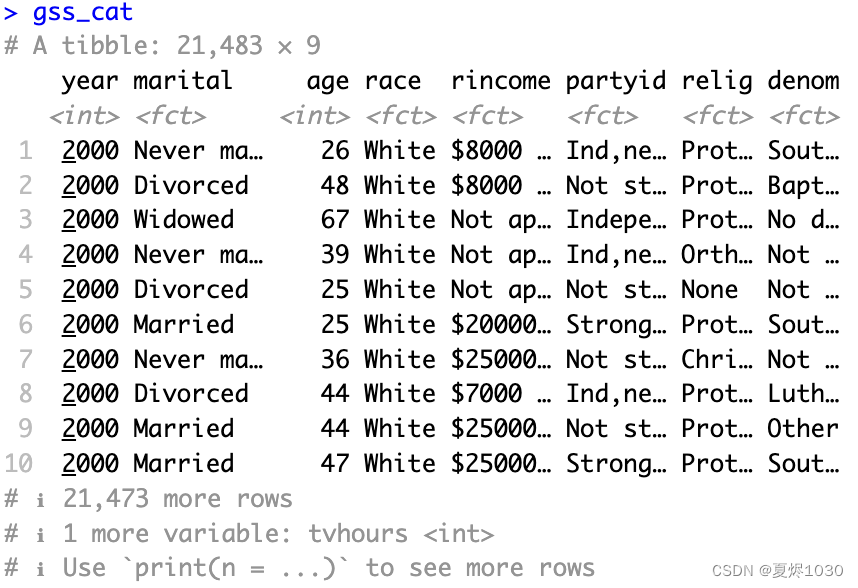
大体看一下变量,除了year,age被设定成int变量,其它都是fct变量。因为这里提供的tibble而不是r中常见的dataframe,所以我们看不出这些分类变量的有效水平有哪些。
这个时候可以用count()函数。

这样,我们就看出了人种就分了三个水平,黑人、白人、其它。
当然,我们也可以用条形图的方式来看一看。(这个是之前的文章里提到的,不明白的同学去翻之前的文章)
ggplot(gss_cat,aes(race))+geom_bar()
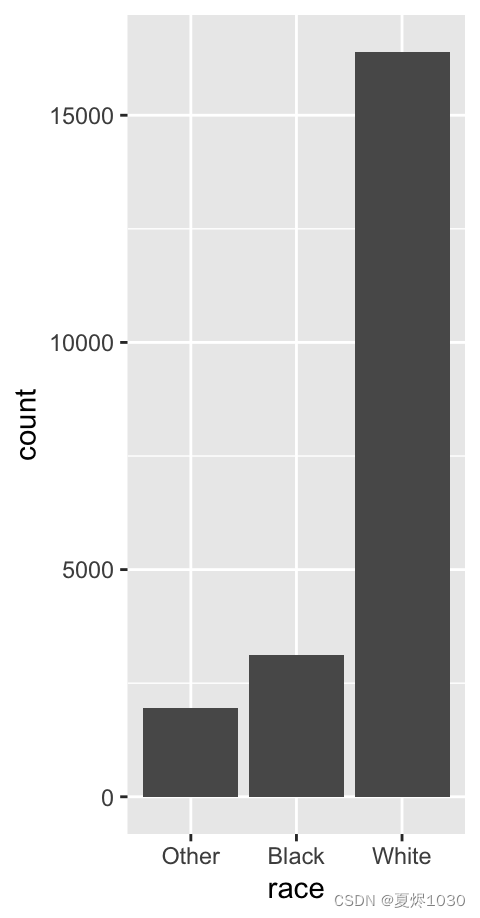
这里就出现了一些问题,比如,因子的顺序问题,我们或许希望other这个因子最后出现。此外,我们也可能想改变因子的值。
这时候该怎么做呢?
改变因子顺序
改变因子顺序用fct_reorder函数,这个函数要求三个值:
- 你要修改的因子变量
- 一个数值型向量,明确因子的顺序
- 最后一个值是可选的值,暂时不表。
例
比如,我们先看一个例子:
relig <- gss_cat %>% group_by(relig) %>% summarize(age=mean(age,na.rm=TRUE),tvhours=mean(tvhours,na.rm=TRUE),n=n())
ggplot(relig,aes(tvhours,relig))+geom_point()
解释一下上面的代码。
首先对gss_cat数据集用group_by函数按照relig分组,在分组之后,用summarize函数进行数据汇总,不同relig组年龄平均值,看电视平均值,和数量。
紧接着用ggplot来绘图,横坐标是tvhours(看电视时间)纵坐标是relig(宗教信仰)。
结果如下:

这样看数据是乱的,所以我们想如果因子能按照看电视的时间进行排序,这代表着,越往上的relig,看电视时长越长,那数据能讲述的内容,就清晰了。
所以,我们对代码进行调整如下:
ggplot(relig,aes(tvhours,fct_reorder(relig,tvhours)))+geom_point()
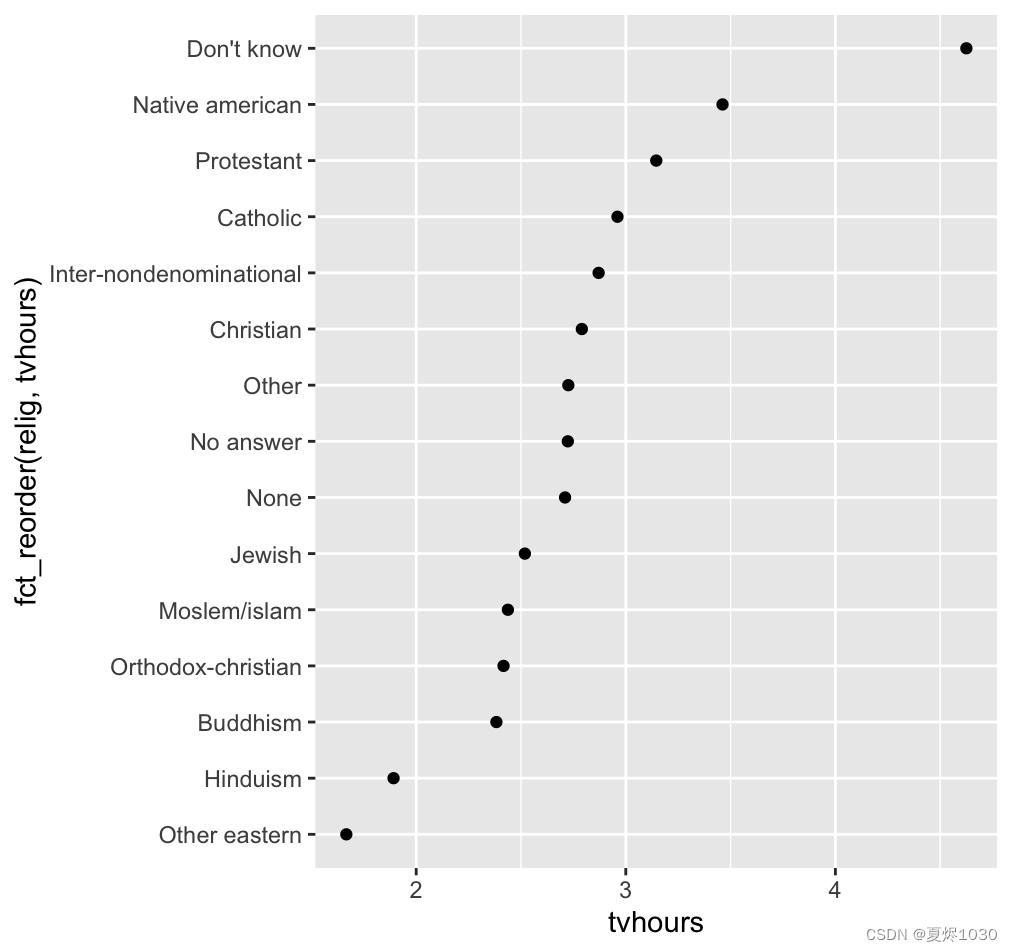
这样,我们这个图就有了更多逻辑,讲述的能力也得到了增强。
在上一步中,我们是在ggplot中对因子进行了排序。那其实还可以更早一步,我们可以把这种顺序,直接作用在relig这个数据集中。
先看一下原本的relig数据集:
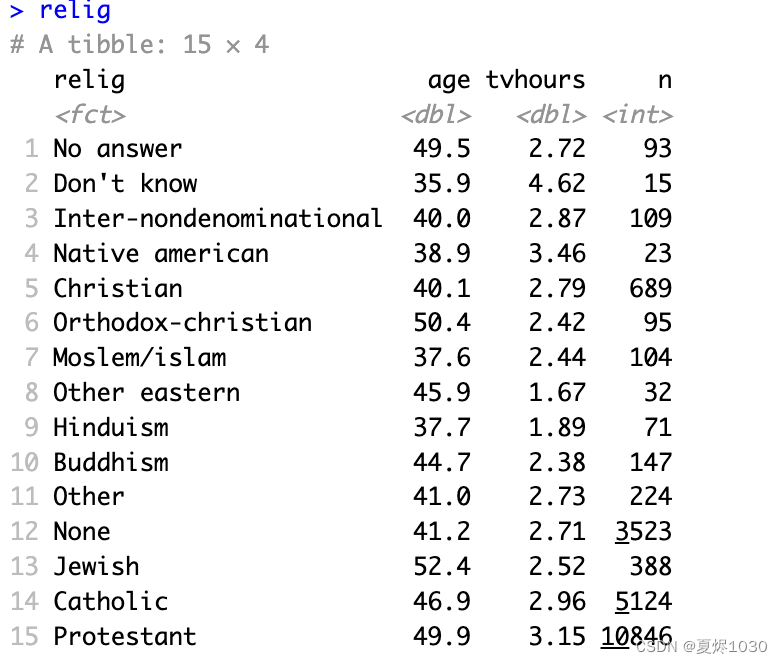
我们通过levels函数来查看一下relig表中relig这个因子变量的顺序。

好,先记住这个顺序,然后我们通过mutate函数,来做一个调整。
relig2 <- relig %>% mutate(relig=fct_reorder(relig,tvhours))
查看一下新生成的relig2数据集:

你会发现和relig没区别。
但是,如果我们用levels函数来看一下:
 那你发现,因子的顺序已经和relig不一样了。
那你发现,因子的顺序已经和relig不一样了。
当我们再用ggplot的时候,直接出来的就是有顺序的因子。
relig2 %>% ggplot(aes(tvhours,relig))+geom_point()

修改因子值
在收集数据的时候,我们会给变量起一些简化的名字,方便操作。但是在发表的时候,尤其是作图的时候,我们需要给这些变量一个能够让大众读懂的名字。在类似的情况下,我们就需要修改因子的值。
这里用到的函数是fct_recode。
举个例子:
我们看看partyid这个因子都有哪些水平。

看看第六条,Ind,near rep,这个非常不友好。所以我们可以这样写:
gss_cat %>% mutate(partyid=fct_recode(partyid,"Democrat,weak"="Not str democrat","Democrat,strong"="Strong democrat")) %>% count(partyid)

如果你想合并几个因子为一个因子,可以这样写:
gss_cat %>% mutate(partyid = fct_collapse(partyid, other = c("No answer", "Don't know", "Other party"), rep = c("Strong republican", "Not str republican"), ind = c("Ind,near rep", "Independent", "Ind,near dem"), dem = c("Not str democrat", "Strong democrat") )) %>% count(partyid)















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









