







背景
很多情况下,数据分析需要处理多个表。我们需要联合多个表来分析数据,回答问题。
今天,我们来看一下如何用dplyr来操作多个表。
如果你学过sql语言,那这一节对你来说会很熟悉
基本概念
当我们把两个表连接在一起时,需要用变量来做链接。这个用来连接两个表的变量被称为键。
常见的键有两种:
1. 主键
所谓的主键,就是能代表本表中唯一一个观测值的变量。
比如说,过两天就高考了,我们把所有高考学生的信息组成一个表。
在这个表里,每个学生都有一个考号,这个考号是唯一的,不可能重复。那我们可以把考号设为这个表的主键。
2.外键
外键能标示出另一个表中的唯一观测值。
接着上一个例子,每个学生除了考号之外,还有个人信息,个人信息里面还有身份证号。
如果还有另外一张表,记录的是全国人的信息。那可以通过这个身份证号找到在全国人表里面的这个考生。
在这种情况下,身份证号就是一个外键。
当然,身份证号这个变量,可以既做主键又做外键,因为它能识别出本表和另外一张表中的唯一观测值。
如何确定是不是主键?
有时,我们拿到一个数据表,也不是特别清楚一个值是不是有重复。这个时候,用count函数数一下到底有多少观测值。
再用之前的nycflights13这个数据集为例,里面有一张表,叫planes,记录了飞机的信息。我们想确认一下tailnum这个变量适不适合作为这张表的主键。
planes %>% count(tailnum) %>% filter(n>1)
结果没有数据,说明没有重复的记录,所以tailnum可以作为主键.
没有主键怎么办?
如果没有主键,可以考虑加上一个代号。
比如:
planes %>% mutate(id=row_number())
这样就多了一列id,这个id是行号,能暂时替代主键。
对两表进行操作
Inner Join内连
inner join最简单,只要是值相等,就会连接起来,但是没有配成对的行不会出现在结果中。换句话说,内连的结果是两个数据集的交集。
比如,我们新建两个数据集。
x<-tribble(~key,~val_x,1,"x1",2,"x2",3,"x3")
y<-tribble(~key,~val_y,1,"y1",2,"y2",4,"y3")
x中,key是主键,它在y中的外键是key。
当我们使用inner_join的时候,x中的key就会和y中的key进行匹配,最后如下:
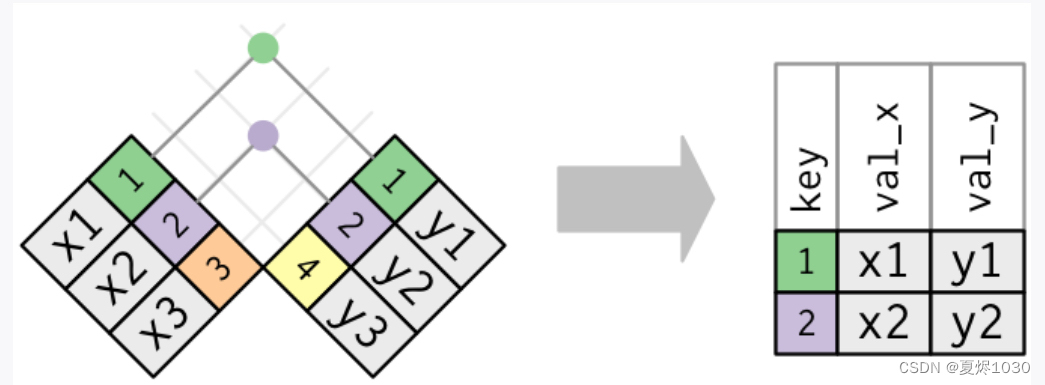
x %>% inner_join(y,by="key")

Outer Joins外连
内连会取的两个数据集的交集,而外链则会保留至少一个数据表的数据。总共可以分三种外连方式。
- left_join:会把左表的数据都留下来(在例子中,就是把x数据集中的数据都保留)
- right_join:会把右表的数据都留下来(在例子中,就是把y数据集中的数据都保留)
- full_join:会把两个表的所有数据都保留下来。
如果没有匹配的数值,则自动填充NA。
如下:
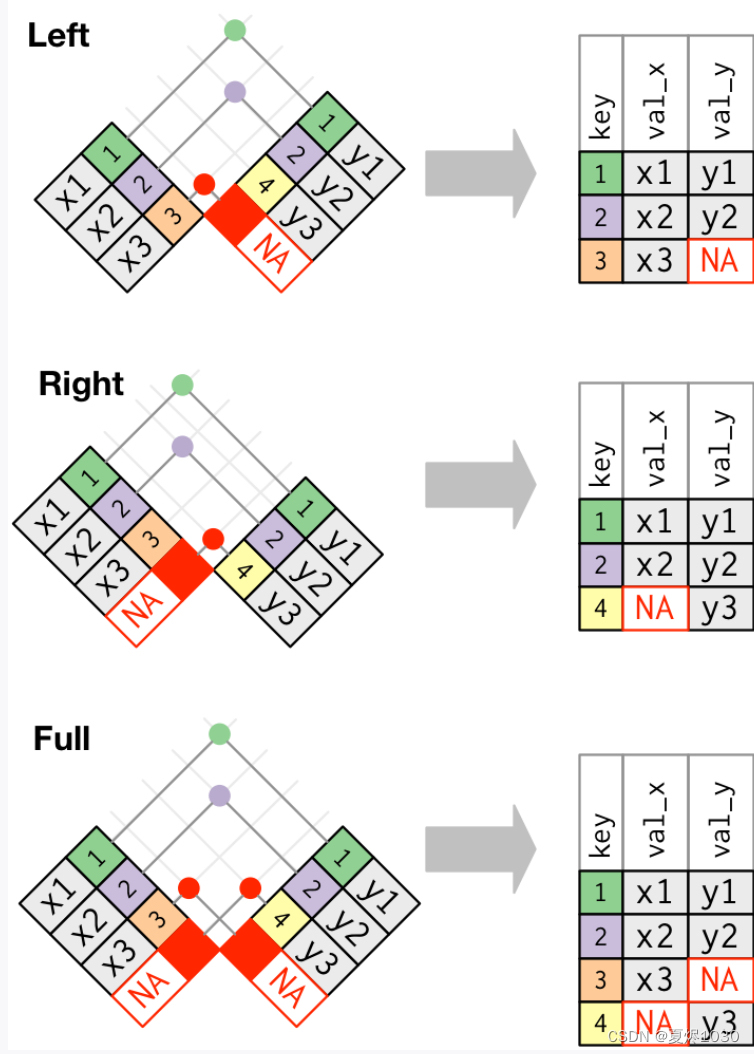
如果用韦恩图的方式来表示,各种连接,则是下面的样子:
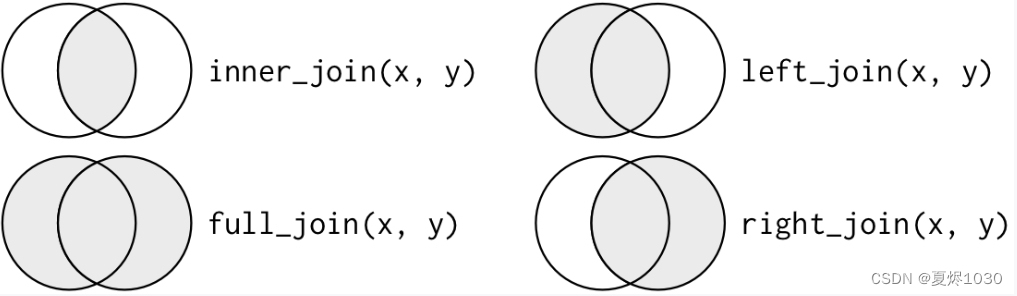
在使用函数的时候,我们使用了by="key"来表示是用key这个变量来连接的。实际上,如果没有这一部分,R会把两个表中相同的变量进行匹配,所以在命名变量名的时候,还是要注意的。
如果相同的变量在不同的表里有不同的变量名,那么可以用by=c(“变量名1”=“变量名2”)的方式进行。
filtering joins
筛选连接,顾名思义,就是用连接的方式进行筛选。
常用的用两种:
- semi_join(x,y)保留x中所有和y有匹配值的观测值
- anti_join(x,y)把x中所有能和y有匹配的值扔掉。
当然,在筛选的时候,我们用filter函数也可以,但是如果你想筛选多个变量,那filter就比较麻烦。可以考虑用semi_join这些函数。















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









