






任务:检测舌头上的裂纹和齿痕
已经有了labelme标注的数据集,并且转为了coco格式
参考:
详细!正确!COCO数据集(.json)训练格式转换成YOLO格式(.txt)_coco数据集的train.txt-CSDN博客
coco数据集转yolo数据集(简单易懂)_coco转yolo-CSDN博客
【模型复现】自制数据集上复现刚发布的最新 yolov9 代码_yolov9复现-CSDN博客
数据集转换
首先将coco格式转为YOLO格式
参考:coco数据集转yolo数据集(简单易懂)_coco转yolo-CSDN博客
我自己备份一下
转换代码
#COCO 格式的数据集转化为 YOLO 格式的数据集
#--json_path 输入的json文件路径
#--save_path 保存的文件夹名字,默认为当前目录下的labels。
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
#这里根据自己的json文件位置,换成自己的就行
parser.add_argument('--json_path', default='D:/workSpace/pycharm/yolov5/MyTest/SAR_coco/annotations/instances_val2017.json',type=str, help="input: coco format(json)")
#这里设置.txt文件保存位置
parser.add_argument('--save_path', default='D:/workSpace/pycharm/yolov5/MyTest/SAR_coco/Lable/val2017', type=str, help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
#round函数确定(xmin, ymin, xmax, ymax)的小数位数
x = round(x * dw, 6)
w = round(w * dw, 6)
y = round(y * dh, 6)
h = round(h * dh, 6)
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {} # coco数据集的id不连续!重新映射一下再输出!
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(f"{category['name']}\n")
id_map[category['id']] = i
# print(id_map)
#这里需要根据自己的需要,更改写入图像相对路径的文件位置。
list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
#将图片的相对路径写入train2017或val2017的路径
list_file.write('./images/train2017/%s.jpg\n' %(head))
print("convert successful!")
list_file.close()
修改json和txt地址即可
转换完成打开相关文件,检查一下路径、文件名之类的有没有问题。
根目录/my_datasets/
├─train.txt
├─val.txt
|─test.txt # 这个没有也OK
├─images
│ ├──train2017
│ │ ├──xxx.jpg
│ │ └──xxx.jpg
│ └──val2017
│ ├──xxx.jpg
│ └──xxx.jpg
│ └──test2017
│ ├──xxx.jpg
│ └──xxx.jpg
└──labels
├──train2017
│ ├──xxx.txt
│ └──xxx.txt
|──val2017
| ├──xxx.txt
| └──xxx.txt
└──classes.txtYOLOv9的复现
先下载代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
下载预训练文件:YOLOv9-C
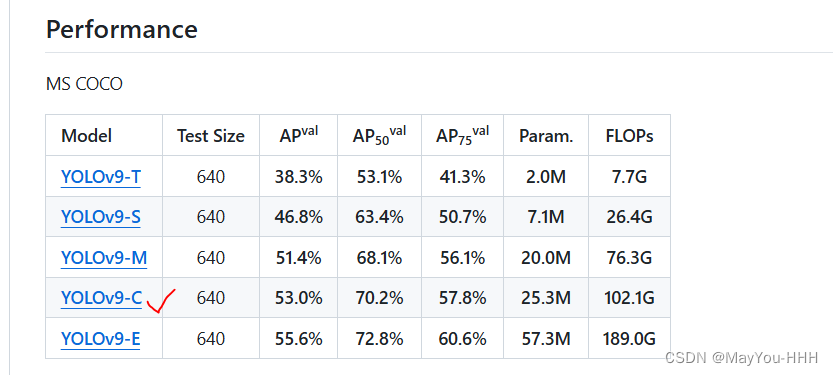
点这儿下载的是yolov9-c-converted.pt,点下面将yolov9-c.pt下载到根目录即可。
搭建虚拟环境
# 创建环境
conda create -n yolov9 python=3.8
# 激活环境
conda activate yolov9
# torch 安装
# 本机 CUDA 为 11.8,故安装了符合要求的 pytorch==1.13,这里需要自行根据 CUDA 版本安装适配的 torch 版本
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
pip install Pillow==9.5.0
# pip 包
cd yolov9
pip install -r requirements.txt
修改数据文件
在 yolov9/data 路径下新建 my_datasets.yaml 文件,以路径下的 coco.yaml 为标准进行参数配置,
修改 path 为数据存储路径
修改 names 为对应的标签名,编号名称要对应
path: ./datasets # dataset root dir
train: train.txt
val: val.txt
test: test.txt # optional
# Classes
names:
0: chihen
1: liewen2
2: liewen1
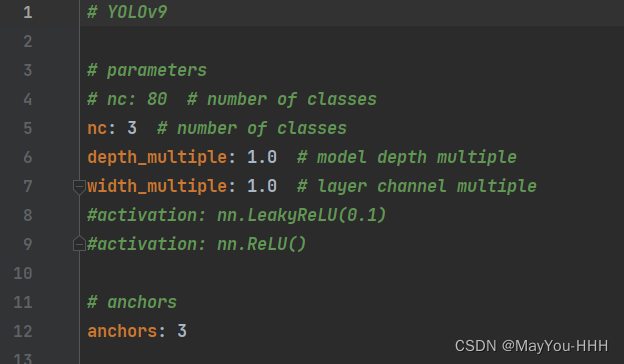
修改模型配置文件
./models/detect/yolov9-c.yaml
--nc 类别数量改一下就行
配置训练的超参数
我们使用的是train_dual.py,val_dual.py,detect_dual.py都有_dual,使用train.py的话

修改train_dual.py,当然更妥当的方式应该是重写这个py文件
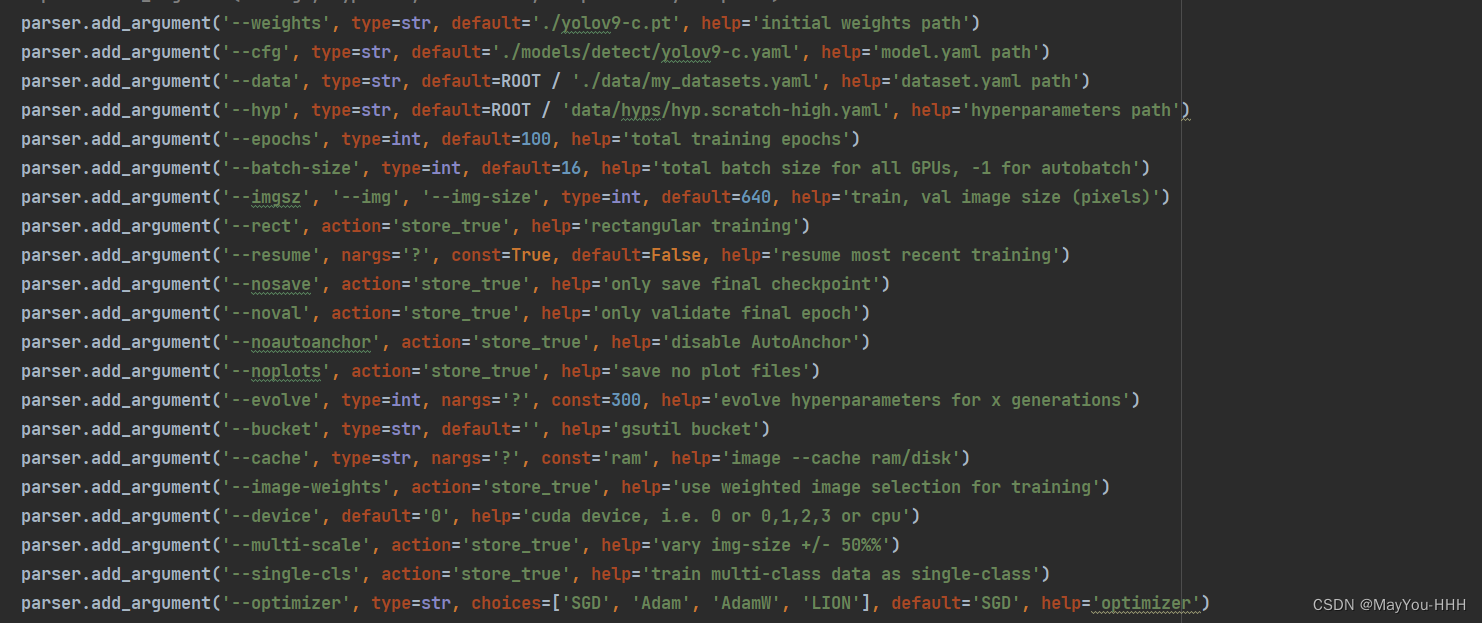 --weights yolov9-c.pt 预训练权重文件的地址
--weights yolov9-c.pt 预训练权重文件的地址
--cfg yolov9-c.yaml 文件的地址
--data my_datasets.yaml文件的地址
--hyp data/hyps/hyp.scratch-high.yaml 这个文件夹里面应该只有一个high没有low
--epochs
--batch-size
--imgsz
--dedvice 看你有几张卡,改一下
--optimizer
开始训练
终端输入命令
单卡训练指令
python train_dual.py
多卡训练指令
python -m torch.distributed.launch --nproc_per_node 8 train_dual.py
看到下述界面,即成功开始训练!!!
训练完
exp里面会有训练的一些数据,exp15为例

配置验证超参数
修改val_dual.py
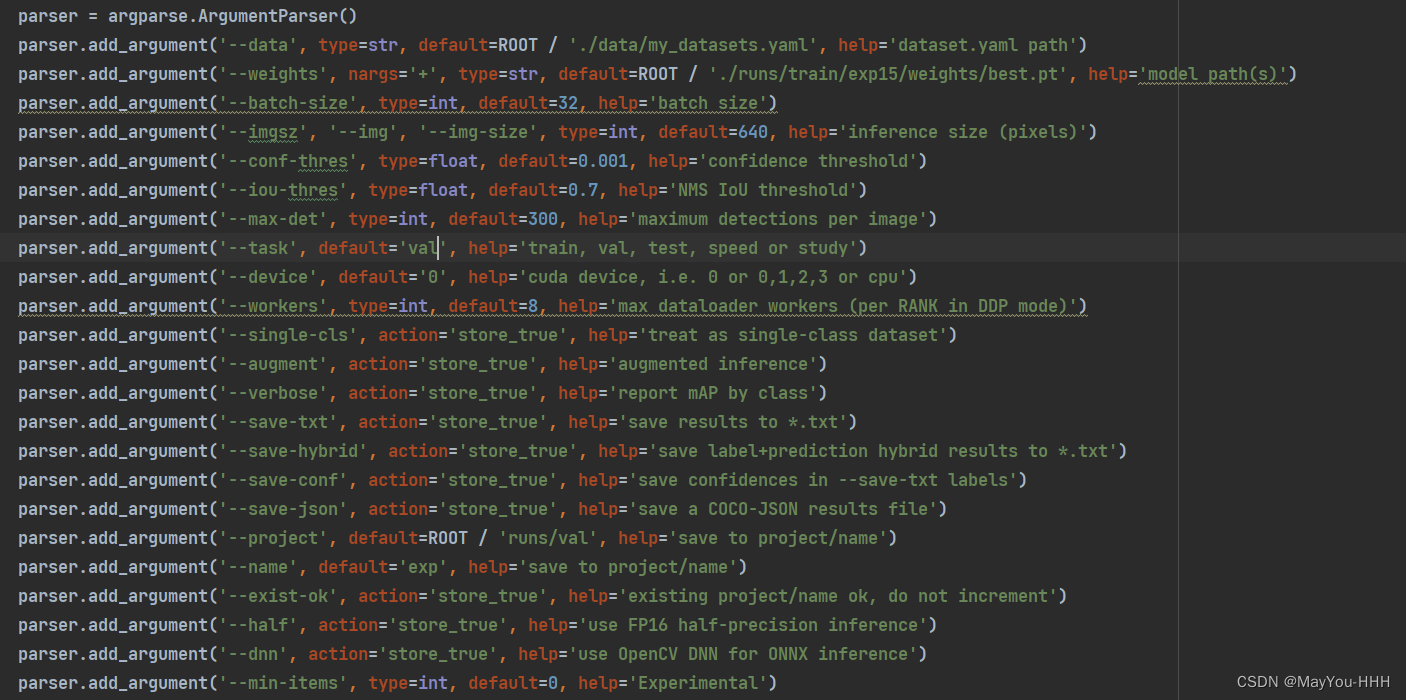
类似train_ dual.py,额外多一个
task:验证数据集选择,如val,test
开始验证
单卡验证指令
python val_dual.py
多卡验证指令
python -m torch.distributed.launch --nproc_per_node 8 val_dual.py
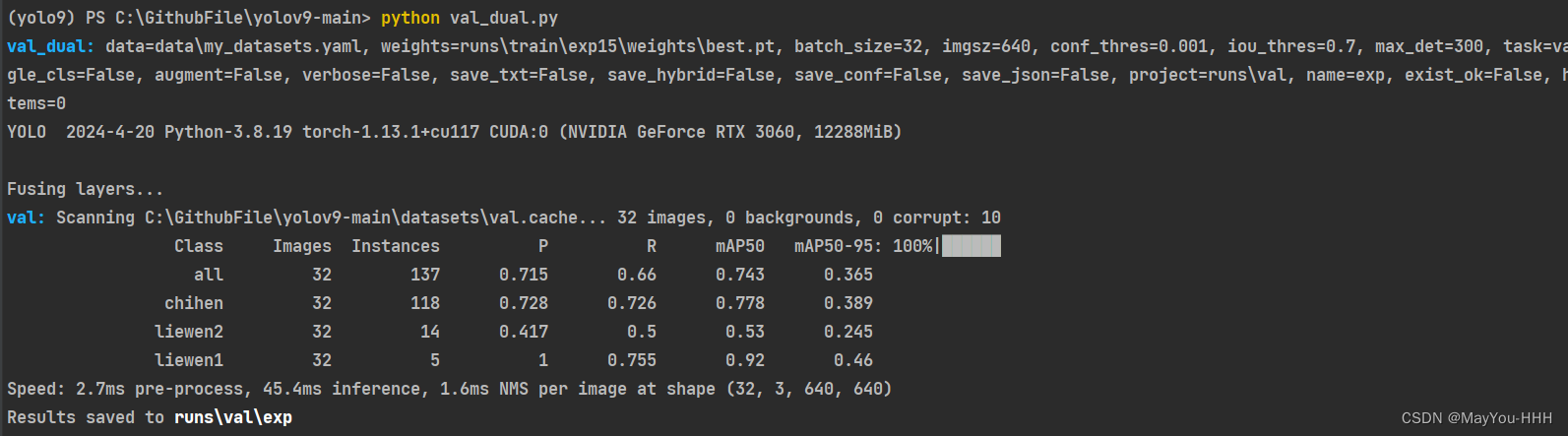
验证成功
配置推理超参数
修改detect_dual.py
开始推理
单卡推理指令
python detect_dual.py
多卡推理指令
python -m torch.distributed.launch --nproc_per_node 8 detect.py
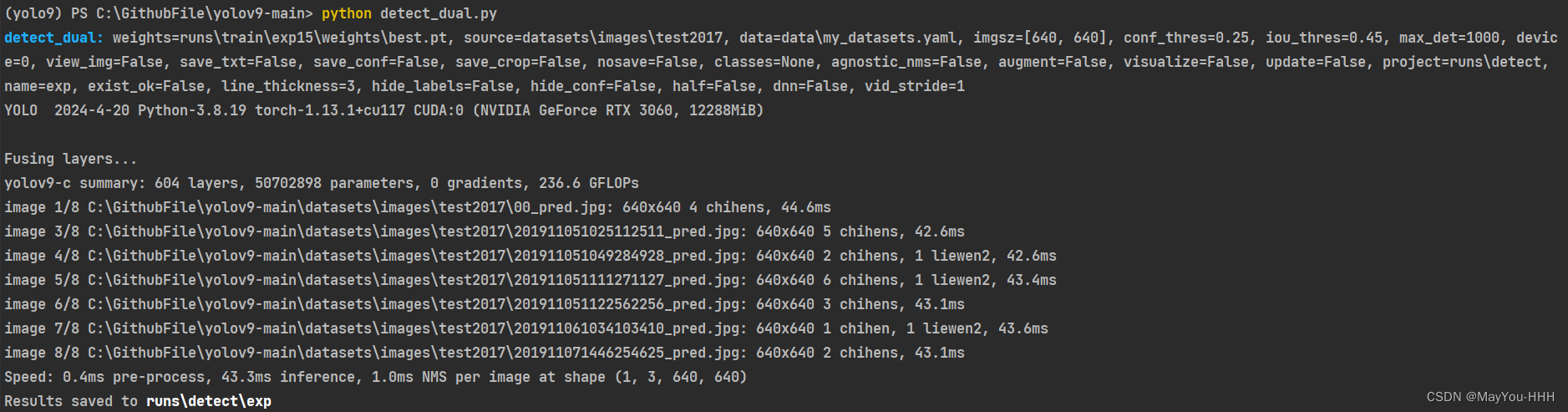
只要把需要推理的图片放在./datasets/images/test2017文件夹中,运行推理命令即可
推理的结果保存在runs\detect\exp
可以查看评估一下
一些问题
遇到问题首先去官方issues里面查查
我的问题都能在这里解决
Q1
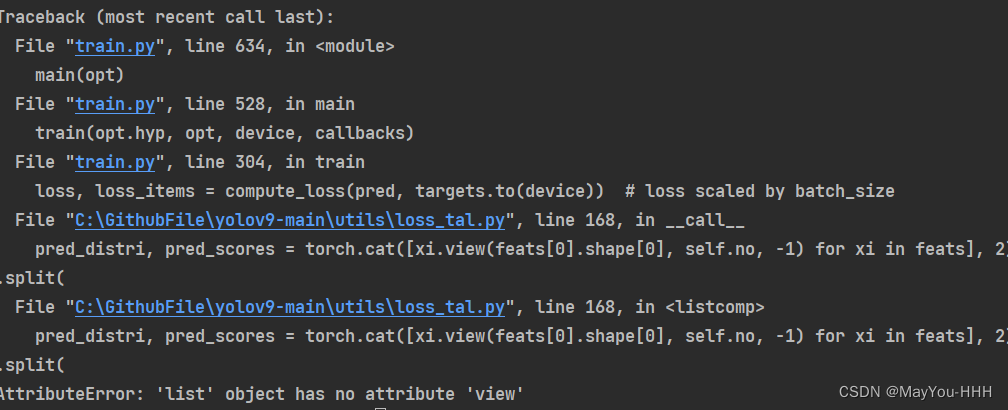
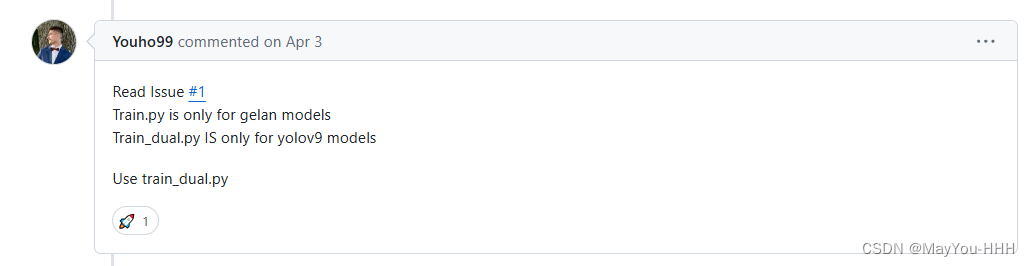
Q2
![]()

yolo可以做分类吗?
YOLO(You Only Look Once)是一种实时对象检测系统,最初设计用于对象检测任务。然而,它也可以用于分类任务,尽管其主要用途并非如此。
YOLO 是一个单阶段对象检测器,它同时预测多个对象的边界框和类别标签。为了将 YOLO 用于纯分类任务,可以进行一些调整:
- 去掉边界框预测部分:只保留分类部分的网络层。
- 修改损失函数:从检测损失函数(包含分类损失和定位损失)修改为仅分类损失。
尽管可以调整 YOLO 进行分类任务,但这并不是最优选择。YOLO 的设计和架构使其在处理对象检测时表现出色,但在纯分类任务中,使用专门设计的分类网络(如 VGG、ResNet 等)通常更为高效和准确。















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









