







CSDN ViT: Vision transformer的cls token作用?
根据先前的一篇博客,可以关注到VitT作者引用类似flag的class token,其输出特征加上一个线性分类器就可以实现分类。
那么,为什么可以这样做呢?是怎么实现的呢?
目录
2 cls token在vision transformer中跟随的计算?
3 cls token输出特征加上一个线性分类器就可以实现分类?
1 Flag:究其根源,cls token类似flag?
想必大家都很熟悉立flag的玩笑话,那么其在计算机编程中的flag概念又是怎样的呢?
百度百科指出:FLAG原本是一个编程指令,常被运用于计算机语言,例如C语言或D语言中,常于用来记载变量的一个参数。后指在游戏或影视出现剧情分歧时做出的影响后续剧情发展的选择,源自于编程术语,英语中的原意是信号或旗帜。
在现实中,立flag的后果,无非就是成败之举。相同的在编程代码中,Flag是电脑程序中用于记录程序状态的单比特大小的标记。具体,Flag只有0和1之分,1立flag,0flag倒,两个数值,通常集中存放在内存中固定的区域里。程序在某种状态改变的同时改变flag的值,并在其他操作中通过flag了解状态,并决定接下来的操作。换句话说,flag可以用来帮助程序做复杂条件的判断。
根据Flag的概念,cls token该如何理解?
个人理解:感觉cls token和flag的概念类似之处就是简单?固定?
如果硬要说flag关联,flag和cls token都是简单的状态标记。前期并不作用,单纯作为一个随机token和图像的token陪跑计算,在计算中分一杯羹,因为cls token本身就没有基于图像内容,那么后期所得到的信息就是其他token上的信息做汇聚(全局特征聚合),这也就解释了cls token对所有基于图像内容token一视同仁,可以避免对序列中其他token的偏向性。
flag和cls token都是固定位置。这样能够避免输出受到位置编码的干扰。
2 cls token在vision transformer中跟随的计算?
熟悉vision transformer模型的小伙伴,比较熟悉大致流程:
从image到token,随后添加一个cls token,接着就是embedding。
参与的具体计算就是attention,将cls token当作一个普通token计算就行?
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
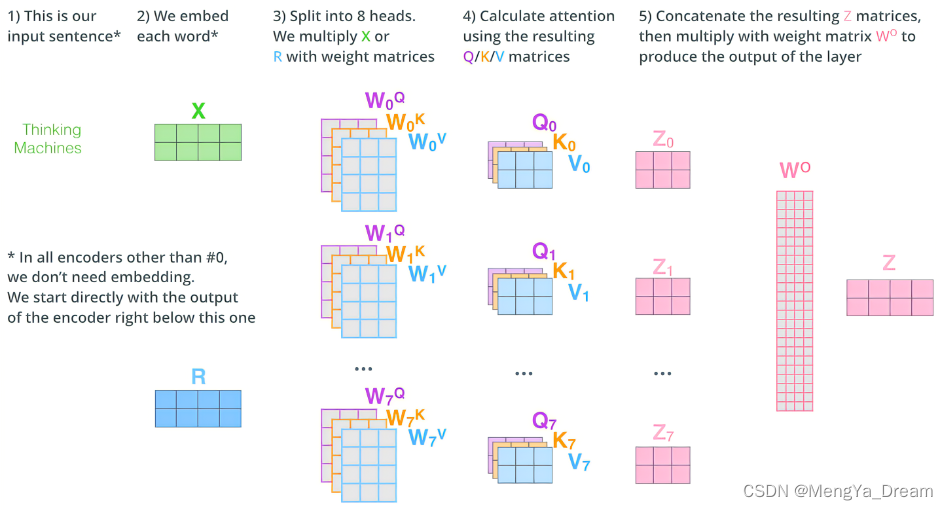
3 cls token输出特征加上一个线性分类器就可以实现分类?
线性分类器的概念?
百度百科:在机器学习领域,分类的目标是指将具有相似特征的对象聚集。而一个线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。对象的特征通常被描述为特征值,而在向量中则描述为特征向量。
定义:如果输入的特征向量是实数向量,则输出的分数为:

其中是一个权重向量,而f是一个函数,该函数可以通过预先定义的功能块,映射两个向量的点积,得到希望的输出。权重向量
是从带标签的训练样本集合中所学到的。通常,"f"是个简单函数,会将超过一定阈值的值对应到第一类,其它的值对应到第二类。一个比较复杂的"f"则可能将某个东西归属于某一类。
对于一个二元分类问题,可以设想成是将一个线性分类利用超平面划分高维空间的情况: 在超平面一侧的所有点都被分类成"是",另一侧则分成"否"。
那么不难理解,cls token经历过attention对其他token得到了一个权重分配,一定程度上就是表示图像的全局关注情况,cls token所得到的输出,结合线性分类器,基于权重向量,不难进行图像分类。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











