






前言
以下内容为小白学习vit内容记录,如理解有误,望帮助指出修正。基于Paddle框架学习,aistudio课程即可学习。此次记录课程中vit模型全流程、deit算法的学习内容
一、VIT模型全流程
在之前的课程内容,基本把VIT的结构模块学习完成。结构如下图所示。

输入的图片经过patch_embeding,切分成image tokens送入Encoders,最后带有特征的数据经过head(softmax,linear)得到分类结果。
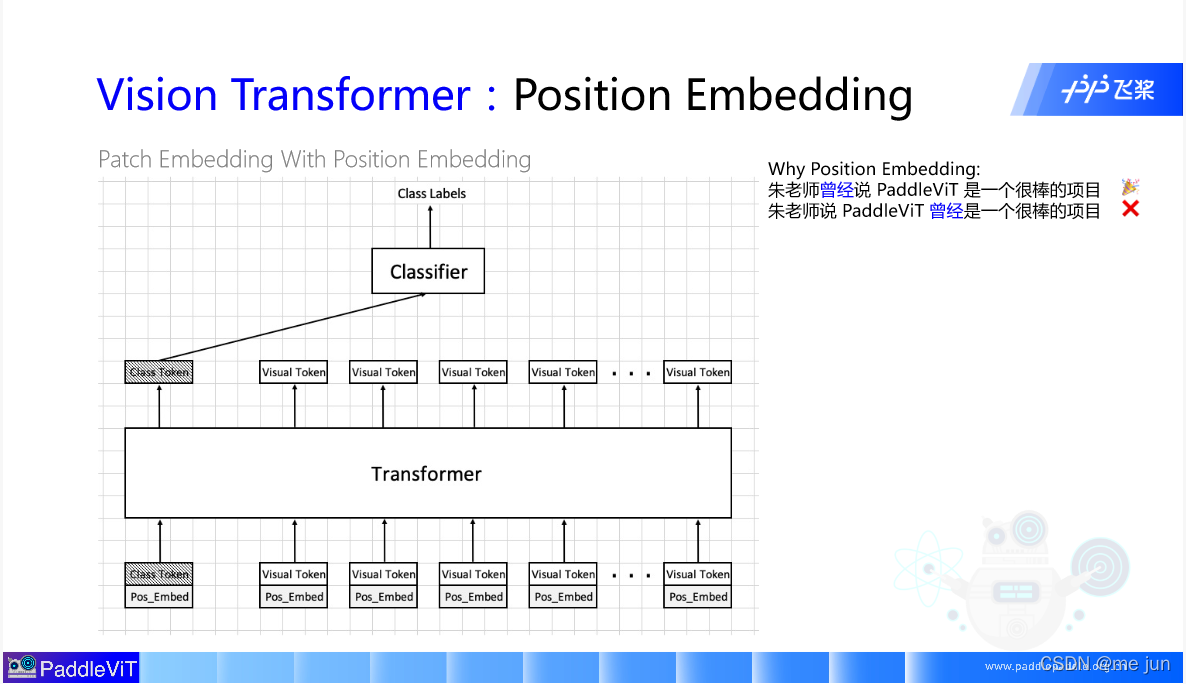
这次课程中再对之前的内容进行完善,对结构增加了细节和新的可学习参数。cls_tokens以及位置编码(position embeding)

二、Cls Tokens
在原来的image tokens上加入一个可学习参数cls_token ,一同输入到原来的模型主体中(encoder),输出带有特征的数据,取cls_token用于计算分类效果,因为cls_tokens的注意力计算可以包含所有的image Tokens 看的更加完整,不同于第一次课程中的方式对所有的image tokens取自适应平均池化,再进行分类。

三、位置编码(position embeding)
图片经过patch_embeding切成了多分image tokens 但是却无法找到原来对应的位置,失去了位置编码,所以对于现在的输入,为每一个参数都加上位置编码,这个参数也是可学习的。加上位置编码的 Tokens最终送入模型主体(encoder)
代码实现
import paddle
import paddle.nn as nn
class PatchEmbedding(nn.Layer):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.):
super().__init__()
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embedding = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
# TODO: add class token
self.class_tokens = paddle.create_parameter(shape = [1,1,embed_dim],
dtype = 'float32',
default_initializer=nn.initializer.Constant(0))
# TODO: add position embedding
self.pos_tokens = paddle.create_parameter(shape = [1,n_patches + 1, embed_dim],
dtype = 'float32',
default_initializer = nn.initializer.TruncatedNormal(std=.02))
def forward(self, x):
# [n, c, h, w]
# TODO: forward
cls_tokens = self.class_tokens.expand((x.shape[0], -1, -1))
x = self.patch_embedding(x) ## [batchsize,embed_dim,h',w']
x = x.flatten(2) ## [ batchsize, embed_dim, h' * w']
x = x.transpose((0,2,1))
x = paddle.concat((cls_tokens,x),axis=1)
x = x + self.pos_tokens
return x四、Deit
解决了原来VIT的问题,更加方便的使用训练。这部分的课程内容主要介绍了在VIT上结合知识蒸馏算法对VIT进行训练。
1.知识蒸馏

平常的模型训练就是,数据进入模型,得到预测结果与标签值进行计算loss再反向传播。而知识蒸馏。首先拿到一个teacher model 指的是在大量的数据集上训练具有较好的分类能力的模型(论文中使用的是regnet),图片数据输入到teacher model 然后对特征数据除以一个参数,再进行softmax分类得到分类结果soft labels(红色线条指示),对于我们需要训练的模型(student model)相同的步骤得到 soft prediction(绿色线条指示) 对这两个结果计算 KLDIVLoss。还有一次前向计算,与平常的模型训练一样。图片数据输入student model中,返回的特征数据无需除以参数,直接送入soft中进行分类,再与图片自身的label计算loss最终两个loss经过加权求和得到最后的Total loss进行反向传播。这个过程就是知识蒸馏。
总结
正在入门深度学习,其中的理解与解释比较牵强,后面会不断学习此课程,学习记录。














 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









