









 文章介绍了一种名为BoomGate的新型解决方案,它在高基数网络中通过受限中间节点非最小路由(RINR)和机会流量控制(OFC)避免死锁,同时优化路径多样性和减少虚拟通道需求。评估结果显示,BoomGate在性能损失和所需缓冲区数量方面优于全局自适应路由策略。
文章介绍了一种名为BoomGate的新型解决方案,它在高基数网络中通过受限中间节点非最小路由(RINR)和机会流量控制(OFC)避免死锁,同时优化路径多样性和减少虚拟通道需求。评估结果显示,BoomGate在性能损失和所需缓冲区数量方面优于全局自适应路由策略。
BoomGate: Deadlock Avoidandce in Non-Minimal Routing for High-Radix Networks
Author: Gyuyoung Kwauk, …
Organization: KAIST
Abstract
- 对于高基数拓扑的大型系统,通常使用虚拟通道VC来防止路由死锁,但深度缓冲区和VC的成本很高。
- 这篇文章提出了BoomGate来避免大规模网络中的死锁,主要由两部分组成:
- 受限的中间节点非最小路由 RINR
- 机会流量控制 OFC
- 这两部分都利用高基数网络的低直径的特性,同时最大化拓扑内的路径多样性。
- 首先确定了全连接拓扑中的路由死锁是由非最小路由引起的,并限制非最小路由以确保没有额外虚拟通道的情况下避免死锁,提出算法RINR确保多路径同时实现负载平衡。并通过OFC机会流量控制来补充RINR算法,当且仅当可保证足够的缓冲区以确保不会发生循环依赖时,才允许非法路由。
- 评估了BoomGate的性能,并证明与全局自适应路由相比,性能损失最小,同时将所需的缓冲区数量减小到50%。
INTRODUCTION
- 互连网络是大型系统的重要组成部分,可影响整体的可扩展性和性能。
- 互连网络的拓扑决定了网络直径在内的性能界限。
- 鉴于路由器管脚带宽的增加,大型系统拓扑已经利用高基路由器的可用性来创建高基拓扑,Butterfly, Dragonfly, HyperX, Slimfly, Megafly… 高基拓扑的特点-拓扑内完全连接。
- 这项工作利用高基拓扑中的全连接性来避免路由死锁,无需额外的VC通道。拓扑决定了网络性能的界限,路由决定了可以实现多少性能。
- 而最近提出的高基拓扑依赖全局自适应路由,并需要非最小路由来充分利用对抗性流量模式的路径多样性,然而具有非最小路由的全局自适应路由引入了路由死锁。虽然通过引入VC可以避免,但一些研究建议不使用VC避免路由。
- 因此提出了Balanced, Oblivious, Non-Minimal, Global Adaptive Routing. RINR OFC
BACKGROUND
- 高基数拓扑和路由
- 路由器中端口带宽的增加导致具有高端口数的高基数路由器,低基数拓扑2Dmesh等不一定会利用高端口数。
- 高基数拓扑的关键组成部分是拓扑实现的高路径多样性。通常完全连接。同时为了充分利用这些完全连接的拓扑,需要非最小路由。并且全局自适应路由通常用于在最小路径和非最小路径之间进行适应。
- 相关工作
- 死锁
- 当且仅当网络CDG图中存在一个或多个循环依赖。创建无死锁可以创建非循环CDG。一个方法是引入虚拟通道并严格排序VC占用。
- 另一个方法是死锁恢复,解决死锁条件保证前进。死锁回复不应频繁,可能影响性能,因为必须执行死锁检测盒恢复。
- 此外,大规模网络的约束条件也有很大不同。例如,片上网络通常具有单周期通道延迟,但在大规模网络中,通道延迟不仅更高,而且存在纠错、链路层协议、准同步、时钟边界跨越等,增加了路由器到路由器的通信复杂性。因此,先前提出的技术不一定适用于大规模网络。
- 气泡流控制
- up/down routing:
- 将所有通道标记为上行或下行通道,合法路由为零个或多个上行路由后跟零个或多个下行路由。
- 死锁
MOTIVATION
-
Observations
- 非最小路由和死锁:
- 在完全连接的拓扑中,最小路由数据包不会导致网络内死锁,因为不会跨多个通道创建依赖关系。
- 而非最小路由会产生死锁,非最小路由由一个错误路由组成,最大跳数为2,也需要三个以上路由器创建循环依赖。而非最小路由对于高基数拓扑实现对抗流量模式的高性能是必要的。VC可以用,VC0用于mis路由,VC1用于到目的地的路由,VC按递增访问,以VC为代价避免了路由死锁。
- 死锁的频率可能会随节点数量的增加/或数据包的大小增加而变化。(可做实验证明)
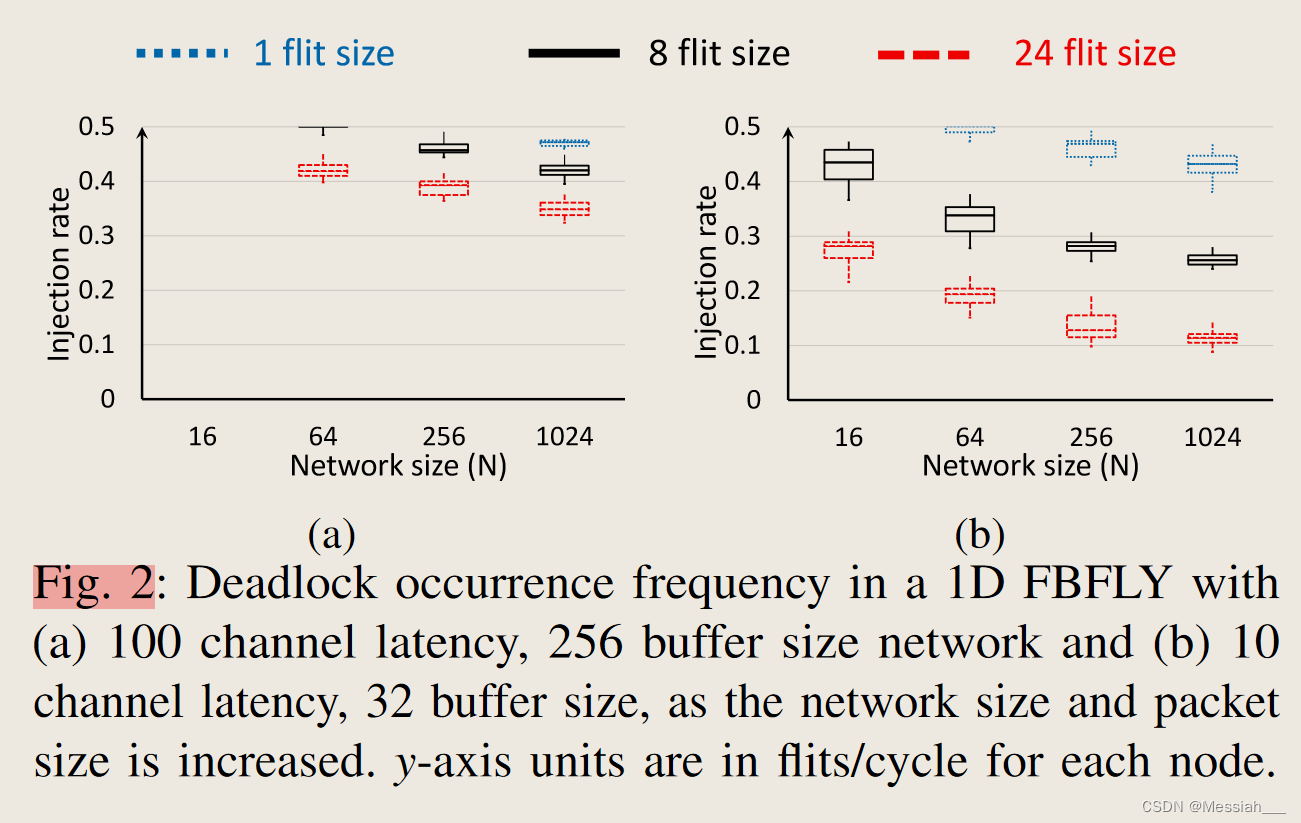
- 非最小路由和死锁:
-
虚拟通道的开销
- limited VCs: 虽然在全连接拓扑中只需要一个额外的VC来避免死锁,但是避免路由死锁所需的VC数量会随每个流量类别而增加。则每个流量类别需要额外的VC来避免路由死锁,并且需要t额外的VC来避免路由死锁(可以以valiant为例)。但是大型系统中的VC数量很少,鉴于 VC 资源数量有限,如果它们不用于路由死锁而是用于隔离流量和实现流量类别,则会更有利。
- 深度缓冲区:互连网络中的输入缓冲区需要覆盖信用往返延迟。考虑到大型系统的电缆很长,往返延迟可能非常高,从而导致输入缓冲区很深。
- 缓冲区利用率:使用专用缓冲区来避免路由死锁的另一个挑战是缓冲区利用率。
RINR 受限中间节点非最小路由
-
合法的非最小路由
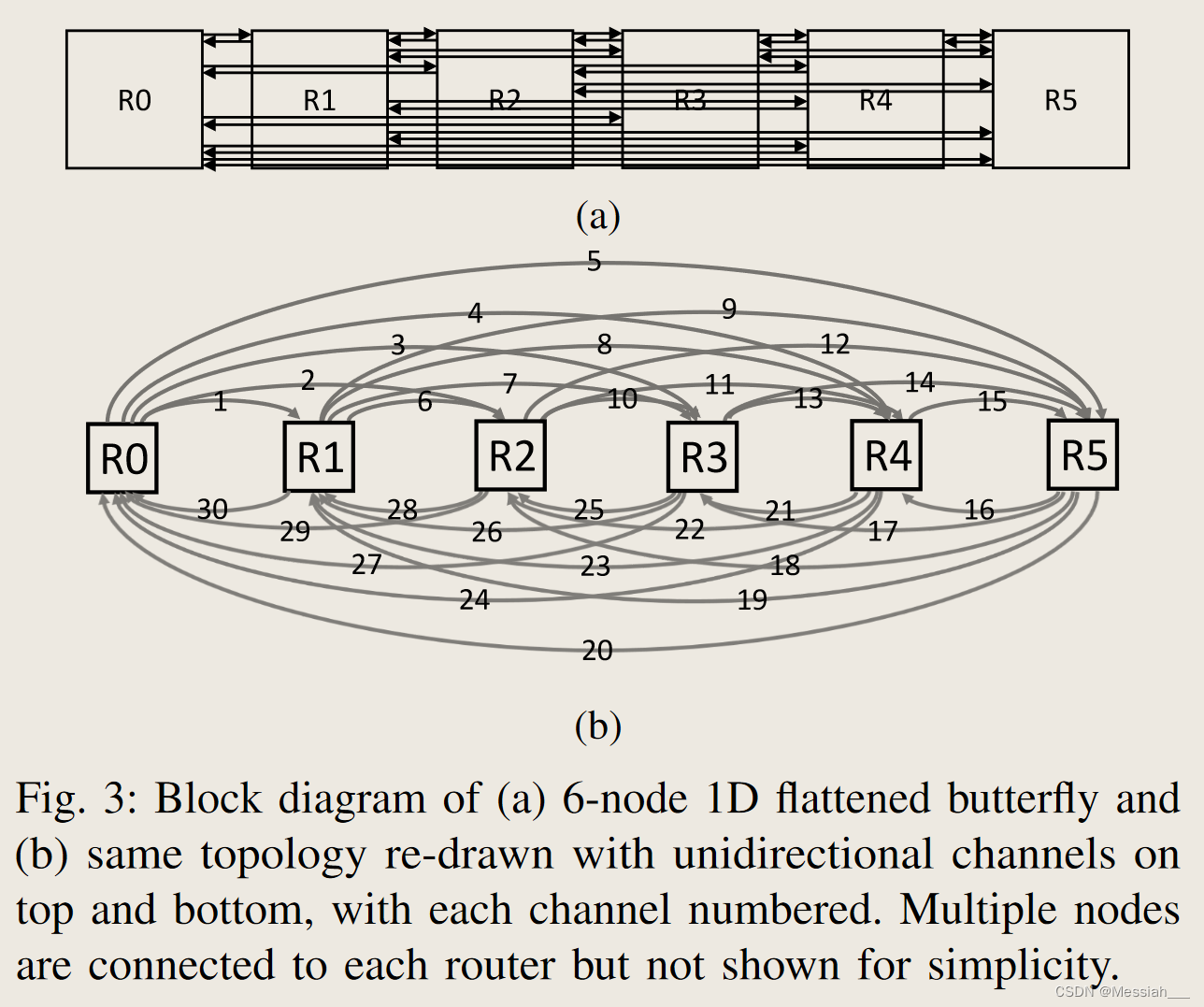
- 编号
- 定义1:合法非最小路由:按升序访问通道的非最小路由
- 定义2:不合法非最小路由:按降序访问。
- 基于这些定义,提出了RINR路由,它利用拓扑中的合法非最小路由。
- 定义3:受限中间节点非最小路由RINR:仅允许合法的非最小路由 并且随机选择。
- 定理:如果使用 RINR 实现非最小路由的全局自适应路由,则路由算法在全连接拓扑中只有 1 个 VC 时不会出现死锁。
- 证明:全局自适应路由[51]由最小路由和非最小路由组成。情况一:最小路由:最小路由只遍历一个网络通道,不会造成路由死锁。情况二:非最小路由:基于通道依赖图(CDG)[15],如果通道资源中不存在循环依赖,则可以避免死锁。如果所有资源都严格排序,则可以避免死锁。通过仅使用合法的非最小路由,网络接入通道中的所有非最小路由都按照严格递增的顺序排列,因此不会出现循环通道依赖。
- 算法流程:
- 选择一个合法的随机的中间节点
- 确定中间节点后,根据最短和非最短的拥塞信息:跳数×占用率,选择最小和非最小路由。
-
负载平衡限制
-
六节点 1D flattened butterfly 的例子中,非最小路由的最大路径多样性为4,最左边的节点可选择所有中间节点,而最右边的节点则会收到限制,例如R5到R4所有的非最小路径都不可用,会严重限制吞吐量。
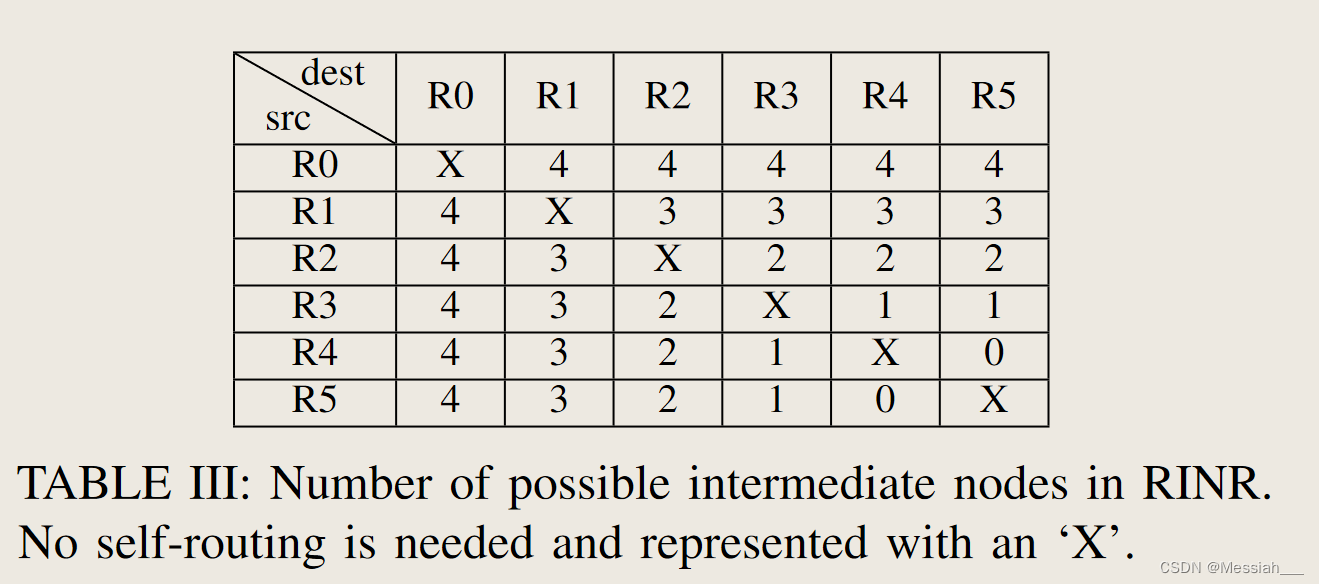
-
一般来说,对于 N 节点全连接拓扑,最小非最小路径多样性为 0,最大路径多样性为 N − 2。可以创建死锁的节点(或通道)的最小数量是 3。因此,选择的 3 个通道的不同可能组合是 NP3,因为死锁中的顺序很重要。对于每种死锁可能性,必须禁用 3 个路径中的 1 个,因此,使用 RINR 禁用 1/3 NP3 非最小路径。每个节点采用RINR路由算法的非最小路由的平均数量为2/3 (N − 2)。
-
B RINR
由于不需要非最小路由,RINR 算法可将负载平衡(良性)流量的性能损失降至最低。然而,由于某些源-目的地的路径多样性受到限制,因此对抗性流量的性能可能受到限制。
-
重新平衡通道
- 通过重新编号通道,并采用相同的路由限制,定义三 即可实现更好的负载平衡。bRINR
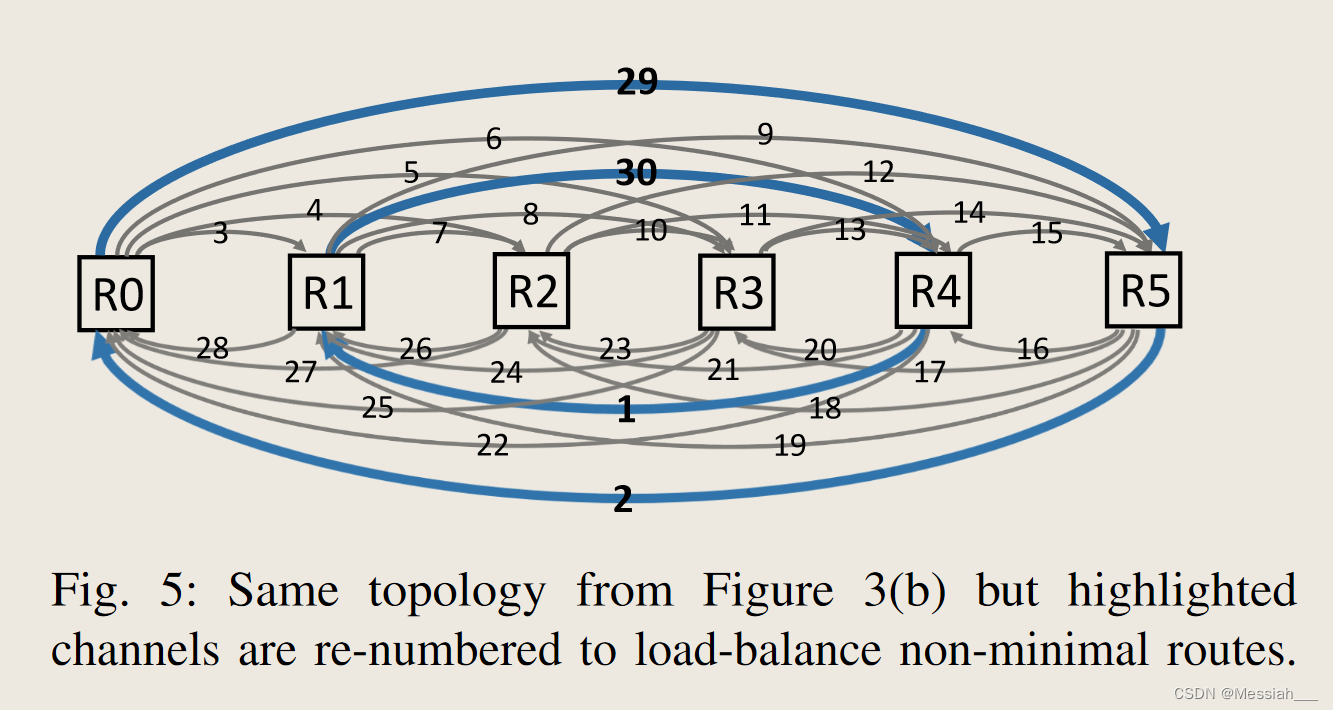
- 通过重新编号通道,并采用相同的路由限制,定义三 即可实现更好的负载平衡。bRINR
-
负载均衡算法
- 平衡非最小路径的目标是确保所有节点至少有 2(n − 2)/3c(向下取整) 个非最小路径
- 通过有效地牺牲源自 Rx 的路径的非最小路径,可以启用可通过 Rx 路由的其他非最小路径(或 Rx 为中间节点的非最小路径)。
- 替代channel编号:基线RINR从规律分配信道编号开始,并描述了如恶化实现平衡的RINR。然而RINR不限于任何特定的信道分配,甚至可以随机编号,但只要避免非法路由,路由算法将不会出现死锁。
- 实际意义:非最小全局自适应路由提供了实用的替代方案。
机会性流量控制 OPPOTUNISTIC FLOW CONTROL
提出了一种流量控制,可以利用非法路由,而不会产生路由死锁的可能性。
-
缓冲区利用
由于需要非法路由来避免死锁,因此未能利用拓扑的完整路径多样性。非法路由路径中的路由器缓冲区没得到充分利用。为提高非法路由的缓冲区利用率并解决通道的负载不平衡问题。
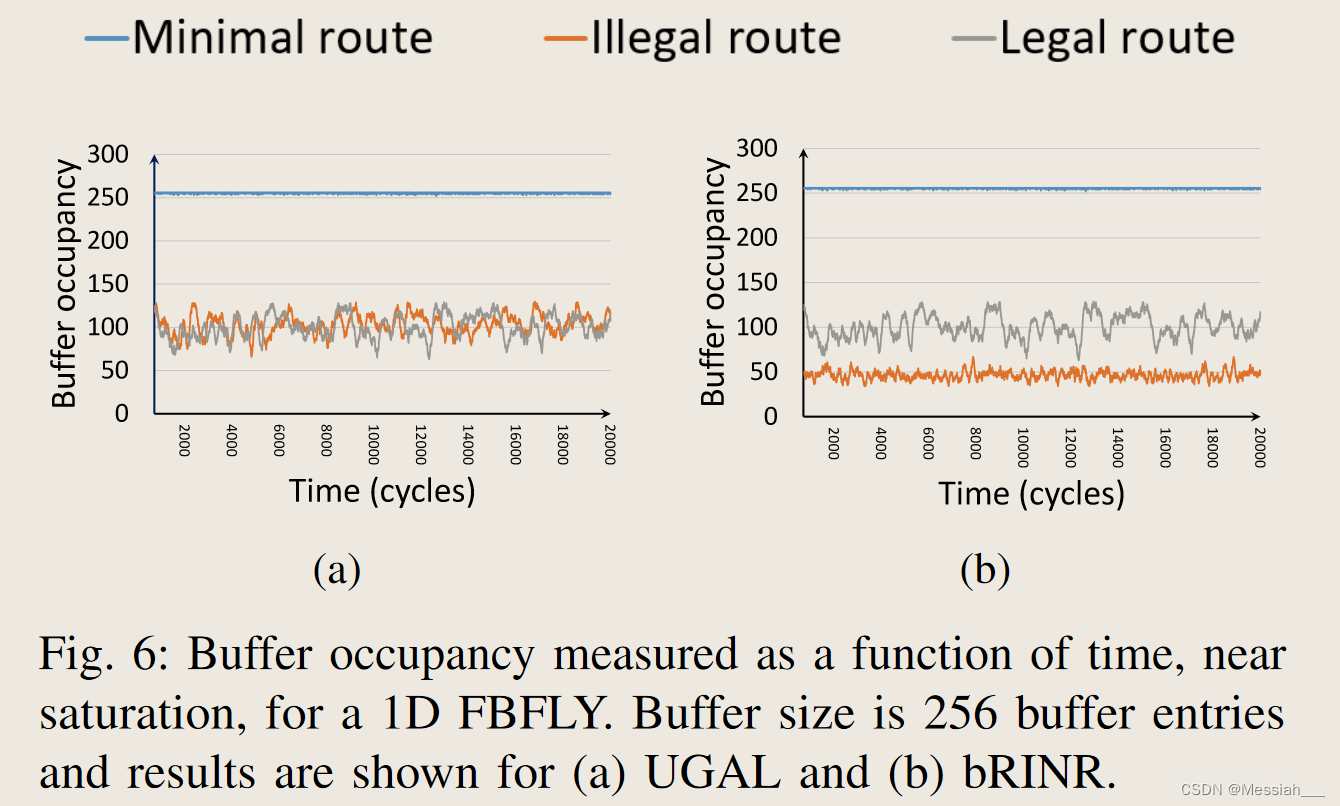
-
静态sOFC
- 其中一些缓冲区专用于或“保留”给非法非最小路由。将信用分为两种不同类型的信用——合法路线信用(CRL)和非法路线信用(CRI)。由于不会创建跨多个缓冲区的通道依赖性,因此可以保证无死锁。
- 当bRINR与OFC结合时,路由算法的唯一区别是算法1中的合法路由位掩码。bRINR仅选择合法的非最小路径,但如果有足够的CRI用于非法路由,则bRINR+sOFC会考虑非法的非最小路径。否则,将使用相同的路由算法。
-
动态dOFC
- sOFC 的信用往返延迟增加了 2 倍。
- 中间路由器非法信用 (CRI) 在收到来自目标路由器的信用之前无法向上游发送。然而,如果有额外的合法信用 (CRL),dOFC 就会利用额外的信用来用完额外的 CRL(即 CRL– 和 CRI++)。
- 如果 CRL 不可用,则 dOFC 无法提前向上游返回积分。
-
死锁避免
- 在所提出的 OFC 中,当且仅当相邻路由器和下游路由器资源(即信用)都可以通过 OFC 获得时,数据包才会穿过非法非最小路由。因此,利用非法路由的数据包不能参与循环依赖。
评估
-
方法论
- Booksim2
- 提出的RINR和bRINR 以及机会流量控制在模拟器中实现。
- 评估针对64节点以及1024节点的1D扁平蝶形网络或全连接网络。
- 设置路由器单周期延迟和single-flit数据包,并评估了数据包大小的影响。
- 对比的路由算法包括:最小路由MIN Valiant路由VAL 通用全局自适应路由UGAL。其中VAL和UGAL使用2VC去避免路由死锁,RINR使用1VC。因此输入缓冲区只是UGAL的一半。
- 对于真实的工作负载的评估,使用了与 SST/Macro 集成的修改后的 BookSim,使用以下 MPI 工作负载跟踪:HILO(中子传输评估和测试套件)[32]、BigFFT(具有 2D 域分解模式的大型 3D FFT)[41]、FB(生产 PDE 求解器的填充边界操作)[7]、 MG(来自生产椭圆求解器的几何多重网格 v 循环)[7]、CNS(来自 BoxLib 库的可压缩 Navier Stokes)[7] 和 NB(Nekbone:使用共轭梯度迭代且无预处理器的毒方程求解器)[11]。
-
结果
- 对于均匀随机流量模式,所有路由方案都显示出高饱和率,而VAL仅实现50%的吞吐量和高零负载延迟。
- 对于最坏的流量模式,RINR 显示的性能与 MIN 非常相似,因为只能利用少数非最小路径。正如预期的那样,由于 RINR 中的非最小路由限制,VAL(和 UGAL)在最差流量模式下提供比 RINR 更高的网络吞吐量。然而,bRINR 通过平衡所有节点之间的合法路由数量来提高吞吐量。如图 9d 所示,随着节点数量的增加,通过非最小路由实现更好的路径多样性带来的性能提升也随之增加。
- 由于 bRINR 不能完全提供所有路径分集,因此可以实现的吞吐量明显低于 VAL 可以实现的吞吐量。相比之下,UGAL 性能几乎与 UR 流量的 MIN 和 WC 流量的 VAL 相当。
- BoomGATE——一种高基数网络的死锁避免机制,不需要额外的 VC 资源,由路由算法和流量控制组成。特别是,我们提出了一种受限自适应路由,它定义了非法路由,但演示了如何平衡路径多样性,并提出了新颖的流量控制,使非法路由能够在“安全”时使用,并在高基拓扑中实现完整的路径多样性被利用来最大化整体性能。
















 1953
1953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











