







👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python葡萄酒数据集—分类建模与分析(源码+数据集)【独一无二】
一、要求
分类任务建模与分析:data目录中的data3.csv文件提供了一个葡萄酒数据集,该数据集包含了三种不同类型的葡萄酒(类别1-3)以及每种葡萄酒的13个化学分析特征。你的任务是:
- 对数据进行预处理,包括处理缺失值、异常值和进行必要的特征缩放。(6分)
- 分析数据集的特征分布,了解不同特征对葡萄酒类别预测的影响。(6分)
- 利用one-vs-all或者one-vs-rest思想,建立逻辑回归模型,来预测葡萄酒的类别(要求使用numpy库实现,不允许直接使用sklearn等机器学习库)(10分)
- 再建立至少2种多分类算法来预测葡萄酒的类别。(6分)
- 评估模型的性能,使用适当的评估指标来处理可能的不平衡数据问题,并比较不同算法的优劣。(6分)
- 根据你的分析,讨论哪些特征对于预测葡萄酒类别最为重要,并给出在实际应用中如何进一步提高模型性能的建议。(6分)
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 葡萄酒分类 ” 获取。👈👈👈
二、代码分析
- 数据导入和预处理:
-
使用 Pandas 库读取 CSV 文件,并将数据存储在 DataFrame 中。
-
对缺失值进行处理,使用均值填充。
-
对异常值进行处理,使用 IQR 方法排除异常值。
-
使用 StandardScaler 进行特征缩放,将特征值进行标准化处理。
data = pd.read_csv('data3.csv') data.fillna(data.mean(), inplace=True) for column in data.columns[:-1]: Q1 = data[column].quantile(0.25) # 略.... scaler = StandardScaler() scaled_features = scaler.fit_transform(data.iloc[:, :-1])
-
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 葡萄酒分类 ” 获取。👈👈👈
-
数据集划分:
-
使用 train_test_split 函数将数据集划分为训练集和测试集。
X_train, X_test, y_train, y_test = train_test_split(scaled_features, data['class'], test_size=0.2, random_state=42)
-
-
逻辑回归模型训练:
-
使用 One-vs-Rest 方法实现多类别逻辑回归。
-
定义 sigmoid 函数、损失函数和梯度下降函数。
-
使用梯度下降法训练每个类别的模型。
def sigmoid(z): return 1 / (1 + np.exp(-z)) def cost_function(X, y, weights): m = len(y) y_pred = sigmoid(np.dot(X, weights)) error = (-y * np.log(y_pred)) - ((1 - y) * np.log(1 - y_pred)) cost = np.sum(error) / m return cost # 略..... y_train_ovr = pd.get_dummies(y_train).values models = np.array([logistic_regression(X_train, y_train_ovr[:, i]) for i in range(y_train_ovr.shape[1])])
-
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 葡萄酒分类 ” 获取。👈👈👈
- 模型评估:
-
使用测试集进行预测。
-
输出分类报告和混淆矩阵。
y_pred = predict_ovr(X_test, models) print(classification_report(y_test, y_pred)) print(confusion_matrix(y_test, y_pred))
-

👉👉👉源码关注【测试开发自动化】公众号,回复 “ 葡萄酒分类 ” 获取。👈👈👈
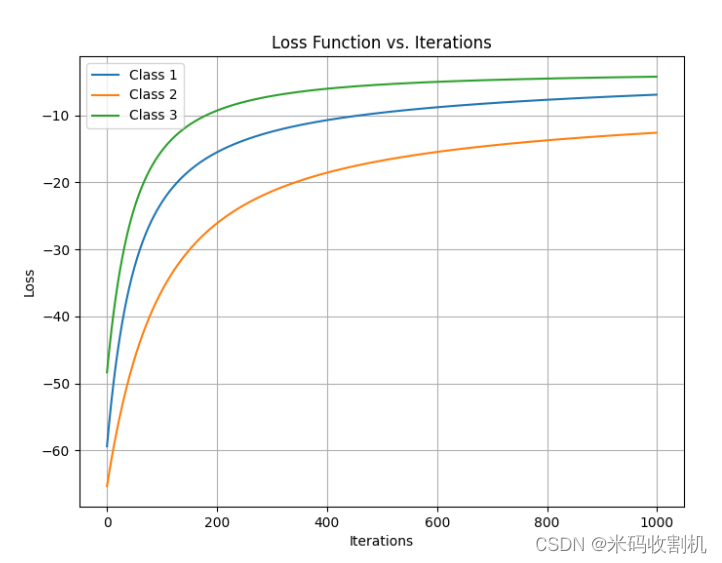
- 绘制损失函数随迭代次数变化的折线图:
-
绘制了每个类别在训练过程中损失函数的变化情况。
plt.figure(figsize=(8, 6)) for i in range(len(models)): plt.plot(models[i][1], label=f'Class {i+1}') plt.title('Loss Function vs. Iterations') plt.xlabel('Iterations') plt.ylabel('Loss') plt.legend() plt.grid(True) plt.show()
-
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 葡萄酒分类 ” 获取。👈👈👈
















 5900
5900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











