







vi/vim使用
0 移至行首
$ 移至行尾
u 撤销
dd 删除光标所在行
u 撤销上一步操作

替换所有字符串:
:%s/1/2/g
把所有1替换成2
vim文件比对:
vimdiff file1 file2
或者
vim -d file1 file2
还可以在vim打开一个文件的情况下
再输入以下命令进入 diff 模式:
:vertical diffsplit FILE_RIGHT
运行脚本两种方式:
1、source scriptname //这种方式就像直接输入一样
2、./scriptname //这种方式脚本运行在子shell
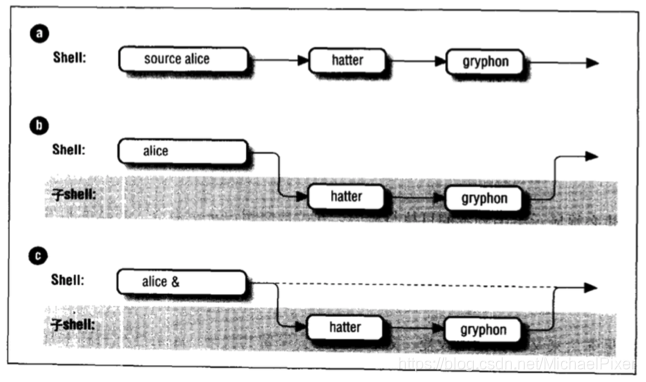
可以使用scriptname &使脚本运行在后台,从而可以进行进一步命令而不需要等待完成
find命令
一般形式为:
find pathname -options [-print -exec -ok]
例:
-name选项:
$ find ~ -name "*.txt" -print
$ find . -name "[A-Z]*" -print //当前目录及子目录中查找以大写字母开头
$ find . -name "[a-z][a-z][0--9][0--9].txt" -print //在当前目录查找文件名以两个小写字母开头,跟着是两个数字,最后是 *.txt的文件
-type选项:
$ find /etc -type d -print //查找所有的文件夹
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
find . -type f -size 文件大小单元
文件大小单元:
b —— 块(512字节)
c —— 字节
w —— 字(2字节)
k —— 千字节
M —— 兆字节
G —— 吉字节
例如:
搜索大于10KB的文件
find . -type f -size +10k
搜索小于10KB的文件
find . -type f -size -10k
搜索等于10KB的文件
find . -type f -size 10k
grep命令:
grep一般格式为:
grep [选项] 基本正则表达式 [文件] //基本正则表达式可为字符串。
常用的grep选项有:
-c 只输出匹配行的计数,匹配的有几行
-i 不区分大小写(只适用于单字符)。
-h 查询多文件时不显示文件名。
-l 查询多文件时只输出包含匹配字符的文件名。
-n显示匹配行及行号。
-s 不显示不存在或无匹配文本的错误信息。
-v 显示不包含匹配文本的所有行
-r 文件夹递归查找
例子:
$ grep "sort" *.doc
$ grep "string<tab>" * //<Tab>表示点击 tab键
$ grep '48[346]' * //使用 []来指定字符串范围,这里用48开始,以3或4或6结尾
$ grep '[A-Z][B-Z]..C' * //匹配头两个是大写字母,以C结尾,中间两位任意
$ grep -rn "字符串" * //查找当前目录(包含子目录)的字符串,并输出行号
awk命令:
动作用{}括起来,if后面的条件用 () 括起来
awk执行时,其浏览域标记为 $1,
2...
2...
2...n。这种方法称为域标识。使用$1, $3表示参照第1和第3域,可使用 $0,意即所有域
例子:
$ awk '{print $0}' grade.txt >test //重定向输出到文件test,此时不显示
$ awk '{print $0}' grade.txt | tee test //重定向输出到文件test,并显示到屏幕
匹配:使用~紧跟正则表达式
$ docker ps -a | awk '{if($2~/p/) print $1}’ // 通过管道找到docker ps -a命令输出中匹配第二列包含p的,然后输出第一列


$ awk '{if($4~/brown/) print $0}' grade.txt //匹配第四列包含字符串brown的,然后打印匹配记录行
精确匹配用==
$ awk '$3=="brown" {print $0}' grade.txt
$ awk '{if($4 !~/brown/) print $0}' grade.txt //不匹配第四列包含字符串brown的,然后打印匹配记录行
sort命令:
将文件的每一行作为一个单位,相互比较,比较原则是从左向右,依次按ASCII码值进行比较,最后将他们按升序输出
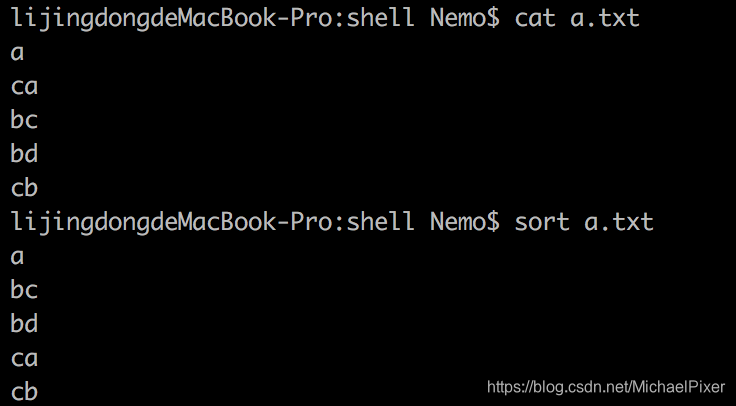
常用语法:
sort filename
sort -r filename //逆序排列
sort -u filename //去除重复行
sort -n filename //作为数值排序
-t //指定分隔符,默认为tab键为分隔符
-k //选择按哪个域来排序,即哪一列
-f //将小写字母都转换为大写字母来进行比较,亦即忽略大小写
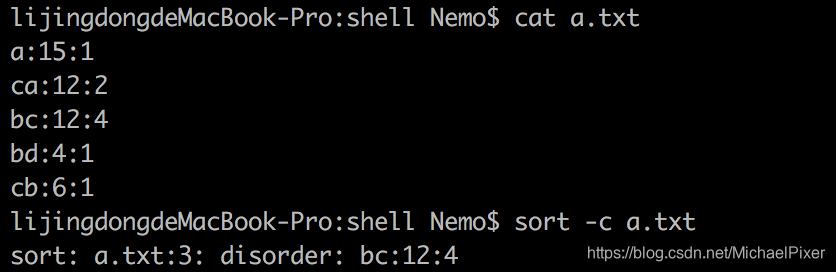
-c //检查文件是否已排好序,如果乱序,则输出第一个乱序的行的相关信息
sort -t: -k2 -n filename //以冒号为分隔符,以第2域作为数值型进行排序
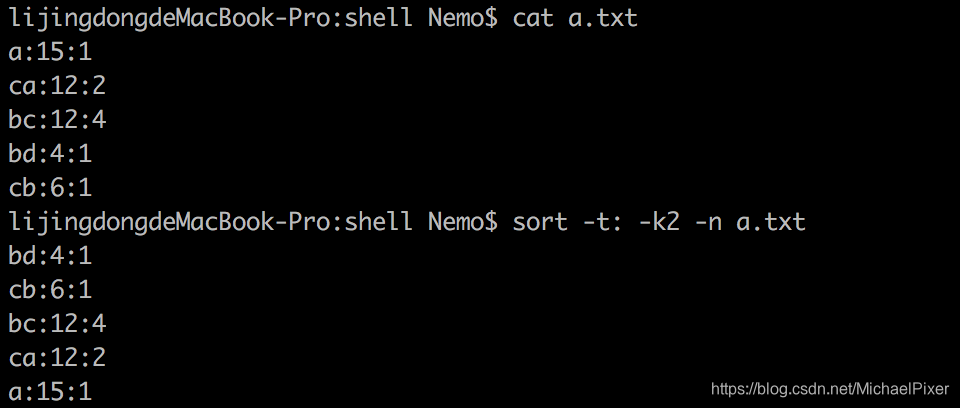
sort -n -t: -k2 -k3 filename //先以第2域,再以第3域排序

sort -c filename
sort和awk组合使用进行排序并输出的两种方法:
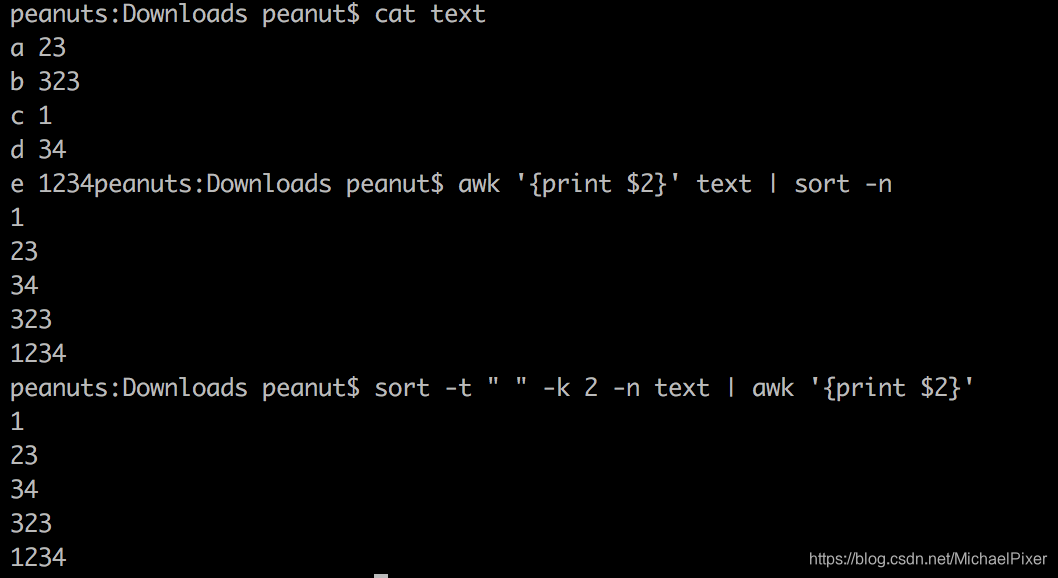
ls命令:
ll等价于 ls -l
输出文件大小以B为单位














 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









