







课程来源: 链接
课程文本部分来源(参考): 链接
以及(强烈推荐) Birandaの
前提知识了解
数据集
包括DataSet以及DataLoader两部分,是用于加载的数据集包括数据和索引两部分,而DataLoader是用于引入数据集的Mini-Batch
Mini-Batch
均衡于算法的时间复杂度(加载全部数据训练更快)以及算法的准确度(加载单个数据训练更准)
在外层循环中,每一层是一个epoch(训练周期),在内层循环中,每一次是一个Mini-Batch(Batch的迭代)
for epoch in range(training_epochs):
for i in range(total_batch):
常用术语
Epoch:所有的样本都进行了一次前馈计算和反向传播即为一次epoch
Batch-Size:每次训练的时候所使用的样本数量
Iterations:batch分的次数
DataLoader
核心参数
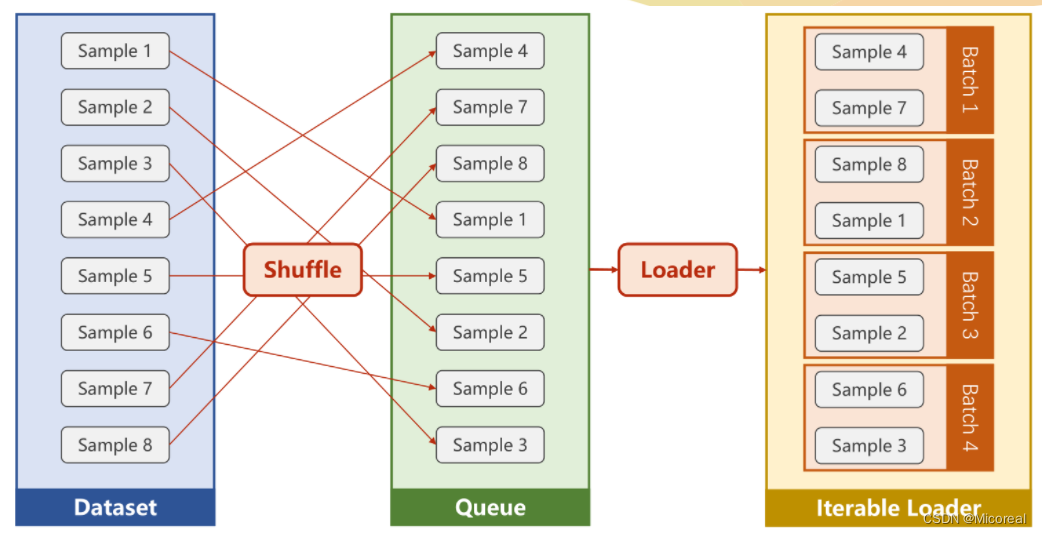
batch_size,shuffle(洗牌,用于打乱顺序)
核心功能
通过获得DataSet的索引以及数据集大小,来自动得生成小批量训练集
DataLoader先对数据集进行洗牌,再将数据集按照Batch_Size的长度划分为小的Batch,并按照Iterations进行加载,以方便通过循环对每个Batch进行操作。
小tips
注:在windows中利用多线程读取,需要将主程序(对数据操作的程序)封装到函数中
eg:
if __name__ =='__main__':
for epoch in range(100):
for i,data in enumerate(train_loader, 0):
以及如果既有测试数据又有训练数据,即二者需要分开

课程代码实例
在构造数据集时,两种对数据加载到内存中的处理方式如下:
- 加载所有数据到dataset,每次使用时读索引,适用于数据量小的情况
- 只对dataset进行初始化,仅存文件名到列表,每次使用时再通过索引到内存中去读取
import torch
import numpy as np
#DataSet是抽象类,无法实例化
from torch.utils.data import Dataset
#DataLoader可实例化
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
#获得数据集长度
self.len=xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
#获得索引方法
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
#获得数据集长度
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
#num_workers表示多线程的读取
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
if __name__ =='__main__':
for epoch in range(100):
#enumerate:可获得当前迭代的次数
for i,data in enumerate(train_loader,0):
#准备数据dataloader会将按batch_size返回的数据整合成矩阵加载
inputs, labels = data
#前馈
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
#反向传播
optimizer.zero_grad()
loss.backward()
#更新
optimizer.step()















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









