







MIMO-UNet:一种2021年发表在ICCV上的去模糊网络
网络整体结构如下:
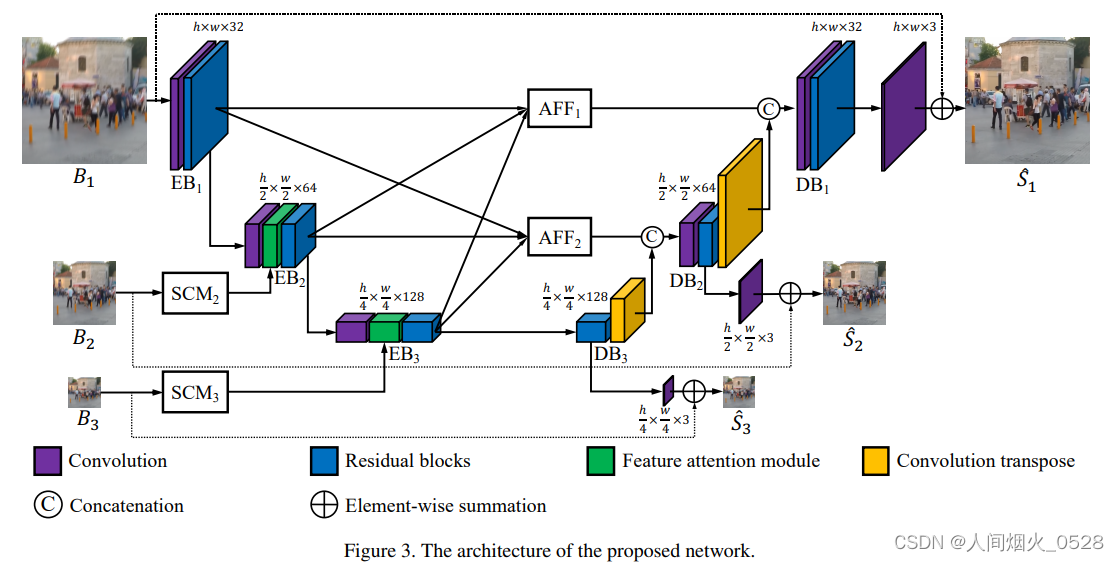
组成模块如下:
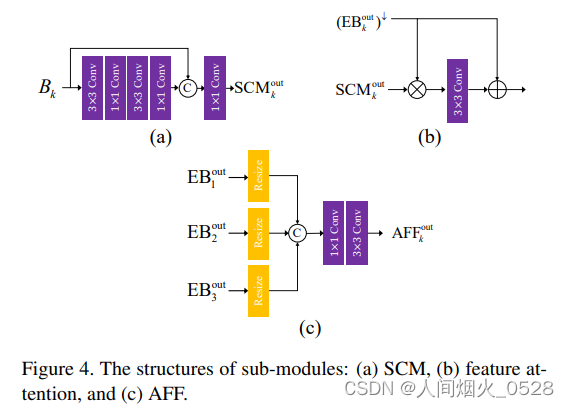
根据整体的网络框架,网络主要有以下部分组成:
1. EBlock 和 DBlock
这两个类分别代表编码器(EBlock)和解码器(DBlock)中的基本模块,它们内部均使用一系列的 ResBlock(残差块)。
输入:对于每个 ResBlock,输入是一组多通道的特征图(张量),通常其形状为 (batch_size, channels, height, width)。
输出:每个 ResBlock 的输出同样是多通道的特征图,形状与输入相同。EBlock 或 DBlock 作为一个整体,其输出是由内部多个 ResBlock 依次处理后的最终特征图。
连接方式:在 EBlock 或 DBlock 内部,多个 ResBlock 通过 nn.Sequential 连接,形成一个顺序执行的结构。特征图从第一个 ResBlock 输入,逐个经过所有 ResBlock 处理后得到最终输出。
2. AFF
AFF (Affine Flow Field) 模块用于实现特征融合。
输入:三个张量 x1, x2, x4,它们代表不同层次或尺度的特征图。
输出:经过两个基本卷积层处理后的融合特征图。
连接方式:首先将输入的三个张量在通道维度(dim=1)上进行连接,然后通过包含两个基本卷积层的 nn.Sequential 结构进行处理。
3. SCM
SCM 模块是一个特定的卷积模块,包含多个基本卷积层。
输入:单个特征图。
输出:经过该模块处理后的特征图。
连接方式:直接将输入特征图送入由多个基本卷积层组成的 nn.Sequential 结构进行处理。
4. FAM
FAM (Feature Attention Module) 模块用于实现特征注意力机制。
输入:两个特征图 x1 和 x2。
输出:经过特征注意力机制处理后的输出特征图。
连接方式:首先将输入特征图进行元素乘积融合,然后将融合结果与其中一个输入特征图通过一个基本卷积层(merge)结合并相加,得到最终输出。
5. MIMOUNet 和 MIMOUNetPlus
这两个类代表整个 MIMO-UNet 和 MIMO-UNetPlus 模型架构,它们内部包含了多个上述组件以及其他辅助模块。
输入:一个三维图像张量 x,形状为 (batch_size, channels, height, width)。
输出:一个包含多个中间输出的列表,每个输出是不同尺度下的处理结果(通常是图像)。
连接方式:
编码器(Encoder):将输入图像经过一系列 EBlock 进行下采样和特征提取,得到不同层次的特征图。
特征提取模块(feat_extract):包含多个基本卷积层,用于进一步处理编码器的输出或解码器的输入。
解码器(Decoder):通过一系列 DBlock 进行上采样,同时融合来自编码器的特征图,恢复图像细节。
中间卷积层(Convs):用于调整特征图的通道数,以便与解码器输出进行拼接。
输出卷积层(ConvsOut):生成最终的输出图像。
自适应特征融合模块(AFFs):融合不同尺度的特征图。
特征注意力模块(FAM1, FAM2, SCM1, SCM2):在特定阶段应用特征注意力机制或特殊卷积处理。
整体流程如下:
输入图像首先通过编码器进行下采样和特征提取。
编码器的输出通过特征提取模块进行进一步处理。
解码器对编码器输出进行上采样,并在适当位置融合来自编码器的特征图。
中间卷积层调整特征图通道数以适应解码器输出。
输出卷积层生成最终的图像输出。
自适应特征融合模块和特征注意力模块在特定步骤中插入,以增强特征交互和信息传递。
基础层部分代码:
import torch
import torch.nn as nn
class BasicConv(nn.Module): #定义基础卷积部分,定义紫色模块部分,对于编程来说定义好每一个模块,再进行调用
def __init__(self, in_channel, out_channel, kernel_size, stride, bias=True, norm=False, relu=True, transpose=False):
"""
初始化BasicConv类的实例。
:param in_channel: 输入通道数
:param out_channel: 输出通道数
:param kernel_size: 卷积核大小
:param stride: 卷积步长
:param bias: 是否使用偏置,默认为True
:param norm: 是否使用归一化,默认为False
:param relu: 是否使用ReLU激活函数,默认为True
:param transpose: 是否使用转置卷积,默认为False
"""
super(BasicConv, self).__init__()
# 如果同时设置了偏置和归一化,则关闭偏置
if bias and norm:
bias = False
# 计算padding值以保持输入输出尺寸一致,输入和输出大小不改变
padding = kernel_size // 2
layers = list()
# 如果是转置卷积,则调整padding值并添加到layers中
if transpose:
padding = kernel_size // 2 - 1
layers.append(nn.ConvTranspose2d(in_channel, out_channel, kernel_size, padding=padding, stride=stride, bias=bias))
else:
# 否则,添加普通的卷积层到layers中
layers.append(
nn.Conv2d(in_channel, out_channel, kernel_size, padding=padding, stride=stride, bias=bias))
# 如果设置了归一化,则添加BatchNorm2d层
if norm:
layers.append(nn.BatchNorm2d(out_channel))
# 如果设置了ReLU激活函数,则添加ReLU层
if relu:
layers.append(nn.ReLU(inplace=True))
# 将所有层封装成一个Sequential容器,可以直接调用main
self.main = nn.Sequential(*layers)
def forward(self, x):
"""
实现前向传播过程。
参数:
self -- 对象的自引用。
x -- 输入数据。
返回值:
返回经过模型主要结构处理后的结果。
"""
return self.main(x) # 调用main模块进行主要的前向传播处理
#定义残差模块,这里指的是定义一个单独的残差模块,后面还有把8个残差模块封装在一起的部分
class ResBlock(nn.Module):
"""
ResBlock的构造函数。
该构造函数初始化了一个残差块,包含两个基本卷积层。
参数:
- in_channel: 输入通道数
- out_channel: 输出通道数
返回值:
- 无
"""
def __init__(self, in_channel, out_channel):
super(ResBlock, self).__init__()
self.main = nn.Sequential(
# 第一个基本卷积层,用于特征提取
BasicConv(in_channel, out_channel, kernel_size=3, stride=1, relu=True),
# 第二个基本卷积层,不使用ReLU激活函数,为特征映射
BasicConv(out_channel, out_channel, kernel_size=3, stride=1, relu=False)
)
def forward(self, x):
return self.main(x) + x
网络实现部分代码:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from .layers import *
# EBlock类:构造包含多个ResBlock层的序列模型
class EBlock(nn.Module):
"""
EBlock类的构造函数。
用于创建一个包含多个ResBlock层的序列模型。
参数:
- out_channel: int, 输出通道数。
- num_res: int, ResBlock的数量,默认为8。
返回:
- 无
"""
def __init__(self, out_channel, num_res=8):
super(EBlock, self).__init__()
# 通过列表推导式创建num_res个ResBlock层,并将它们封装到nn.Sequential中
layers = [ResBlock(out_channel, out_channel) for _ in range(num_res)]
self.layers = nn.Sequential(*layers)
def forward(self, x):
"""
实现前向传播过程。
参数:
- x输入数据,可以是单个数据样本或数据批量。
返回值:
- 经过所有层处理后的输出结果。
"""
return self.layers(x) # 通过self.layers中的层对输入x进行处理
class DBlock(nn.Module):
"""
DBlock类:定义了一个包含多个ResBlock层的深度块。
参数:
- channel: int, 每个ResBlock层的通道数。
- num_res: int, DBlock中ResBlock层的数量,默认为8。
返回值:
- 无
"""
def __init__(self, channel, num_res=8):
super(DBlock, self).__init__()
# 通过循环构造num_res个ResBlock层,并将它们串联起来
layers = [ResBlock(channel, channel) for _ in range(num_res)]
self.layers = nn.Sequential(*layers)
# self.layers即为包含num_res个ResBlock层的序列,可用于模型的前向传播。
def forward(self, x):
"""
实现前向传播过程。
参数:
- x输入数据,可以是单个数据样本或数据批量。
返回值:
- 经过所有层处理后的输出结果。
"""
return self.layers(x) # 通过self.layers中的层对输入x进行处理
# AFF类:初始化AFF(Affine Flow Field)模块
class AFF(nn.Module):
"""
初始化AFF(Affine Flow Field)模块。
该模块用于创建一个包含两个基本卷积层的序列,第一个卷积层用于转换输入通道到输出通道,第二个卷积层保持输出通道不变。
参数:
- in_channel(int): 输入通道数。
- out_channel(int): 输出通道数。
属性:
- conv(nn.Sequential): 包含两个基本卷积层的序列。
"""
def __init__(self, in_channel, out_channel):
super(AFF, self).__init__()
# 创建一个包含两个基本卷积层的序列:
# 第一个卷积层用于从in_channel转换到out_channel,
# 第二个卷积层保持out_channel不变。
self.conv = nn.Sequential(
BasicConv(in_channel, out_channel, kernel_size=1, stride=1, relu=True),
BasicConv(out_channel, out_channel, kernel_size=3, stride=1, relu=False)
)
def forward(self, x1, x2, x4):
"""
实现前向传播过程。
参数:
- x1, x2, x4: 输入的三个张量,它们将在维度1上连接。
返回:
- 经过self.conv卷积操作处理后的张量。
"""
# 在维度1上连接输入的三个张量
x = torch.cat([x1, x2, x4], dim=1)
# 通过卷积层处理连接后的张量
return self.conv(x)
class SCM(nn.Module):
"""
SCM类:实现了一个特定的卷积模块。
参数:
- out_plane: 输出通道数。
方法:
- forward: 前向传播方法。
"""
def __init__(self, out_plane):
"""
初始化SCM模块。
参数:
- out_plane: 输出通道数。
"""
super(SCM, self).__init__()
# 定义主要的卷积序列,包括四个基本卷积层
self.main = nn.Sequential(
BasicConv(3, out_plane//4, kernel_size=3, stride=1, relu=True),
BasicConv(out_plane // 4, out_plane // 2, kernel_size=1, stride=1, relu=True),
BasicConv(out_plane // 2, out_plane // 2, kernel_size=3, stride=1, relu=True),
BasicConv(out_plane // 2, out_plane-3, kernel_size=1, stride=1, relu=True)
)
# 定义一个额外的卷积层,用于最后的特征融合
self.conv = BasicConv(out_plane, out_plane, kernel_size=1, stride=1, relu=False)
def forward(self, x):
"""
定义前向传播路径。
参数:
- x: 输入特征数据。
返回:
- 经过SCM模块处理后的特征数据。
"""
# 将输入特征与主卷积序列的输出在通道维度上连接
x = torch.cat([x, self.main(x)], dim=1)
# 使用额外的卷积层处理连接后的特征数据
return self.conv(x)
# FAM类:实现特征注意力模块
class FAM(nn.Module):
"""
FAM(Feature Attention Module)类,继承自nn.Module,用于实现特征注意力模块。
参数:
- channel: 输入通道数
方法:
- forward: 前向传播方法。
"""
def __init__(self, channel):
"""
初始化FAM模块。
参数:
- channel: 输入特征的通道数。
"""
super(FAM, self).__init__()
self.merge = BasicConv(channel, channel, kernel_size=3, stride=1, relu=False)
def forward(self, x1, x2):
"""
定义前向传播操作。
参数:
- x1: 输入特征1
- x2: 输入特征2
返回:
- out: 经过特征注意力机制处理后的输出特征。
"""
x = x1 * x2 # 通过元素乘积融合两个输入特征
out = x1 + self.merge(x) # 将融合后的特征与原始特征x1通过BasicConv模块结合,并相加得到最终输出
return out
# MIMOUNet类:定义MIMOUNet模型
class MIMOUNet(nn.Module):
"""
MIMOUNet模型的类定义。
该模型用于图像处理任务,具体结构包括编码器、特征提取模块、解码器等部分。
参数:
- num_res: int, 默认为8, 表示残差块的数量。
"""
def __init__(self, num_res=8):
super(MIMOUNet, self).__init__()
base_channel = 32
# 初始化编码器模块列表
self.Encoder = nn.ModuleList([
EBlock(base_channel, num_res),
EBlock(base_channel*2, num_res),
EBlock(base_channel*4, num_res),
])
# 初始化特征提取模块列表
self.feat_extract = nn.ModuleList([
BasicConv(3, base_channel, kernel_size=3, relu=True, stride=1),
BasicConv(base_channel, base_channel*2, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*2, base_channel*4, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*4, base_channel*2, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel*2, base_channel, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel, 3, kernel_size=3, relu=False, stride=1)
])
# 初始化解码器模块列表
self.Decoder = nn.ModuleList([
DBlock(base_channel * 4, num_res),
DBlock(base_channel * 2, num_res),
DBlock(base_channel, num_res)
])
# 初始化中间卷积层模块列表
self.Convs = nn.ModuleList([
BasicConv(base_channel * 4, base_channel * 2, kernel_size=1, relu=True, stride=1),
BasicConv(base_channel * 2, base_channel, kernel_size=1, relu=True, stride=1),
])
# 初始化输出卷积层模块列表
self.ConvsOut = nn.ModuleList(
[
BasicConv(base_channel * 4, 3, kernel_size=3, relu=False, stride=1),
BasicConv(base_channel * 2, 3, kernel_size=3, relu=False, stride=1),
]
)
# 初始化自适应特征融合(Adaptive Feature Fusion)模块列表
self.AFFs = nn.ModuleList([
AFF(base_channel * 7, base_channel*1),
AFF(base_channel * 7, base_channel*2)
])
# 初始化特征注意力模块(Feature Attention Module)
self.FAM1 = FAM(base_channel * 4)
self.SCM1 = SCM(base_channel * 4)
self.FAM2 = FAM(base_channel * 2)
self.SCM2 = SCM(base_channel * 2)
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入图像的张量。
返回值:
- outputs: 一个包含多个中间输出的列表。
"""
# 缩小输入图像尺寸
x_2 = F.interpolate(x, scale_factor=0.5)
x_4 = F.interpolate(x_2, scale_factor=0.5)
# 通过SCM模块处理缩小后的图像
z2 = self.SCM2(x_2)
z4 = self.SCM1(x_4)
outputs = list()
# 通过特征提取(卷积层)和编码器进行处理,并保存中间结果
x_ = self.feat_extract[0](x)
res1 = self.Encoder[0](x_)
z = self.feat_extract[1](res1)
z = self.FAM2(z, z2)
res2 = self.Encoder[1](z)
z = self.feat_extract[2](res2)
z = self.FAM1(z, z4)
z = self.Encoder[2](z)
# 进行特征的上采样和融合
z12 = F.interpolate(res1, scale_factor=0.5)
z21 = F.interpolate(res2, scale_factor=2)
z42 = F.interpolate(z, scale_factor=2)
z41 = F.interpolate(z42, scale_factor=2)
res2 = self.AFFs[1](z12, res2, z42)
res1 = self.AFFs[0](res1, z21, z41)
# 通过解码器和输出卷积层得到最终输出
z = self.Decoder[0](z)
z_ = self.ConvsOut[0](z)
z = self.feat_extract[3](z)
outputs.append(z_+x_4)
z = torch.cat([z, res2], dim=1)
z = self.Convs[0](z)
z = self.Decoder[1](z)
z_ = self.ConvsOut[1](z)
z = self.feat_extract[4](z)
outputs.append(z_+x_2)
z = torch.cat([z, res1], dim=1)
z = self.Convs[1](z)
z = self.Decoder[2](z)
z = self.feat_extract[5](z)
outputs.append(z+x)
return outputs
class MIMOUNetPlus(nn.Module):
"""
MIMOUNetPlus网络结构,用于图像处理任务。
参数:
- num_res (int): 用于编码器和解码器中的残差块的数量。
返回:
- 无
"""
def __init__(self, num_res = 20):
super(MIMOUNetPlus, self).__init__()
# 初始化基本通道数和编码器模块列表
base_channel = 32
self.Encoder = nn.ModuleList([
EBlock(base_channel, num_res),
EBlock(base_channel*2, num_res),
EBlock(base_channel*4, num_res),
])
# 初始化特征提取模块列表
self.feat_extract = nn.ModuleList([
BasicConv(3, base_channel, kernel_size=3, relu=True, stride=1),
BasicConv(base_channel, base_channel*2, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*2, base_channel*4, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*4, base_channel*2, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel*2, base_channel, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel, 3, kernel_size=3, relu=False, stride=1)
])
# 初始化解码器模块列表
self.Decoder = nn.ModuleList([
DBlock(base_channel * 4, num_res),
DBlock(base_channel * 2, num_res),
DBlock(base_channel, num_res)
])
# 初始化中间卷积模块列表
self.Convs = nn.ModuleList([
BasicConv(base_channel * 4, base_channel * 2, kernel_size=1, relu=True, stride=1),
BasicConv(base_channel * 2, base_channel, kernel_size=1, relu=True, stride=1),
])
# 初始化输出卷积模块列表
self.ConvsOut = nn.ModuleList(
[
BasicConv(base_channel * 4, 3, kernel_size=3, relu=False, stride=1),
BasicConv(base_channel * 2, 3, kernel_size=3, relu=False, stride=1),
]
)
# 初始化注意力融合模块列表
self.AFFs = nn.ModuleList([
AFF(base_channel * 7, base_channel*1),
AFF(base_channel * 7, base_channel*2)
])
# 初始化特征注意力模块
self.FAM1 = FAM(base_channel * 4)
self.SCM1 = SCM(base_channel * 4)
self.FAM2 = FAM(base_channel * 2)
self.SCM2 = SCM(base_channel * 2)
# 初始化dropout层
self.drop1 = nn.Dropout2d(0.1)
self.drop2 = nn.Dropout2d(0.1)
def forward(self, x):
"""
前向传播函数。
参数:
- x (Tensor): 输入图像的张量。
返回:
- outputs (list of Tensor): 输出图像的列表,每个元素为不同尺度下的处理结果。
"""
# 缩小输入图像尺度
x_2 = F.interpolate(x, scale_factor=0.5)
x_4 = F.interpolate(x_2, scale_factor=0.5)
# 通过SCM模块处理不同尺度的输入
z2 = self.SCM2(x_2)
z4 = self.SCM1(x_4)
outputs = list()
# 通过特征提取和编码器模块处理输入图像
x_ = self.feat_extract[0](x)
res1 = self.Encoder[0](x_)
z = self.feat_extract[1](res1)
z = self.FAM2(z, z2)
res2 = self.Encoder[1](z)
z = self.feat_extract[2](res2)
z = self.FAM1(z, z4)
z = self.Encoder[2](z)
# 进行特征融合和尺度跳接
z12 = F.interpolate(res1, scale_factor=0.5)
z21 = F.interpolate(res2, scale_factor=2)
z42 = F.interpolate(z, scale_factor=2)
z41 = F.interpolate(z42, scale_factor=2)
res2 = self.AFFs[1](z12, res2, z42)
res1 = self.AFFs[0](res1, z21, z41)
res2 = self.drop2(res2)
res1 = self.drop1(res1)
# 通过解码器和输出卷积模块得到最终输出
z = self.Decoder[0](z)
z_ = self.ConvsOut[0](z)
z = self.feat_extract[3](z)
outputs.append(z_+x_4)
z = torch.cat([z, res2], dim=1)
z = self.Convs[0](z)
z = self.Decoder[1](z)
z_ = self.ConvsOut[1](z)
z = self.feat_extract[4](z)
outputs.append(z_+x_2)
z = torch.cat([z, res1], dim=1)
z = self.Convs[1](z)
z = self.Decoder[2](z)
z = self.feat_extract[5](z)
outputs.append(z+x)
return outputs
def build_net(model_name):
"""
根据提供的模型名称构建相应的网络模型。
参数:
- model_name: 字符串,指定要构建的模型名称。
返回值:
- 返回一个初始化好的指定模型实例。
异常:
- ModelError: 如果模型名称不正确,则抛出此自定义异常。
"""
# 定义一个自定义的模型错误异常类
class ModelError(Exception):
def __init__(self, msg):
# 初始化异常信息
self.msg = msg
def __str__(self):
# 返回异常信息的字符串表示
return self.msg
# 根据模型名称选择对应的模型类进行实例化
if model_name == "MIMO-UNetPlus":
return MIMOUNetPlus()
elif model_name == "MIMO-UNet":
return MIMOUNet()
# 如果模型名称不符合预期,抛出ModelError异常
raise ModelError('Wrong Model!\nYou should choose MIMO-UNetPlus or MIMO-UNet.')

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









