







整理一下Transformer相关论文的计算量和计算流程
一、Vision Transformer
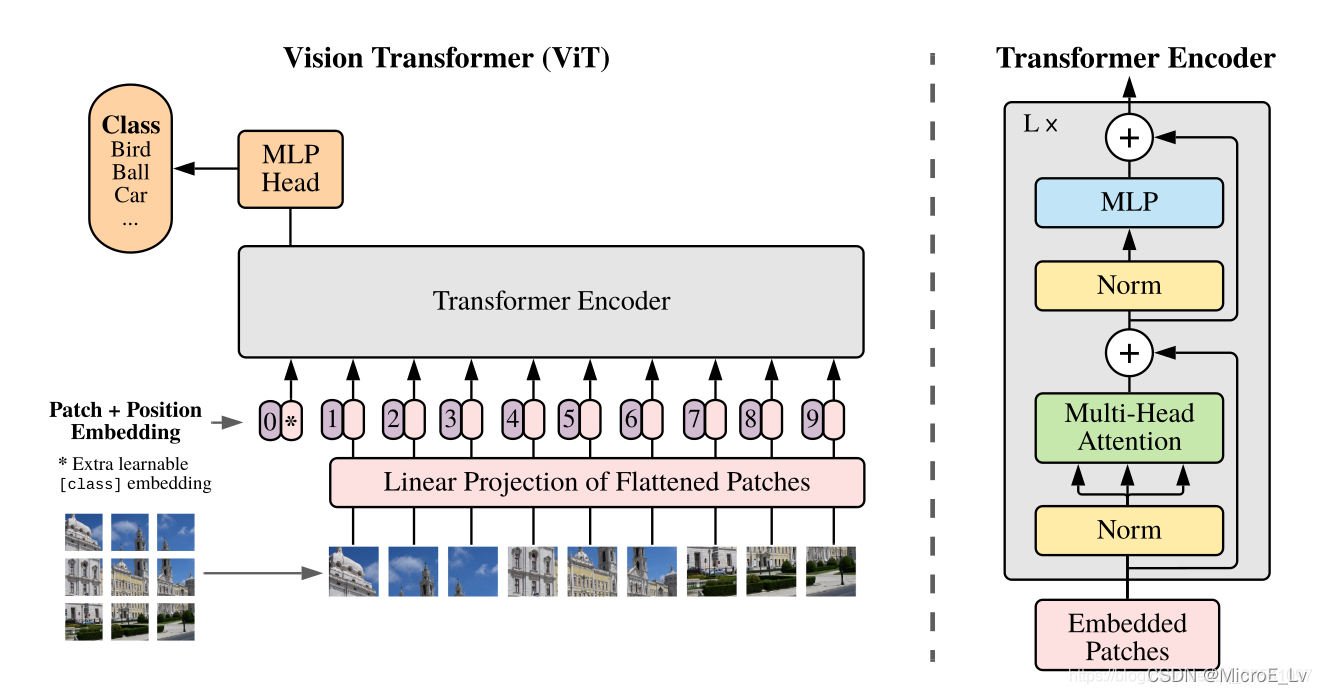
Vision Transformer的结构在大佬 “太阳花的小绿豆” 的博文里面有明确的分析。这里我也是借由这篇博文来写的。
图片来源:太阳花的小绿豆-Vision Transformer详解
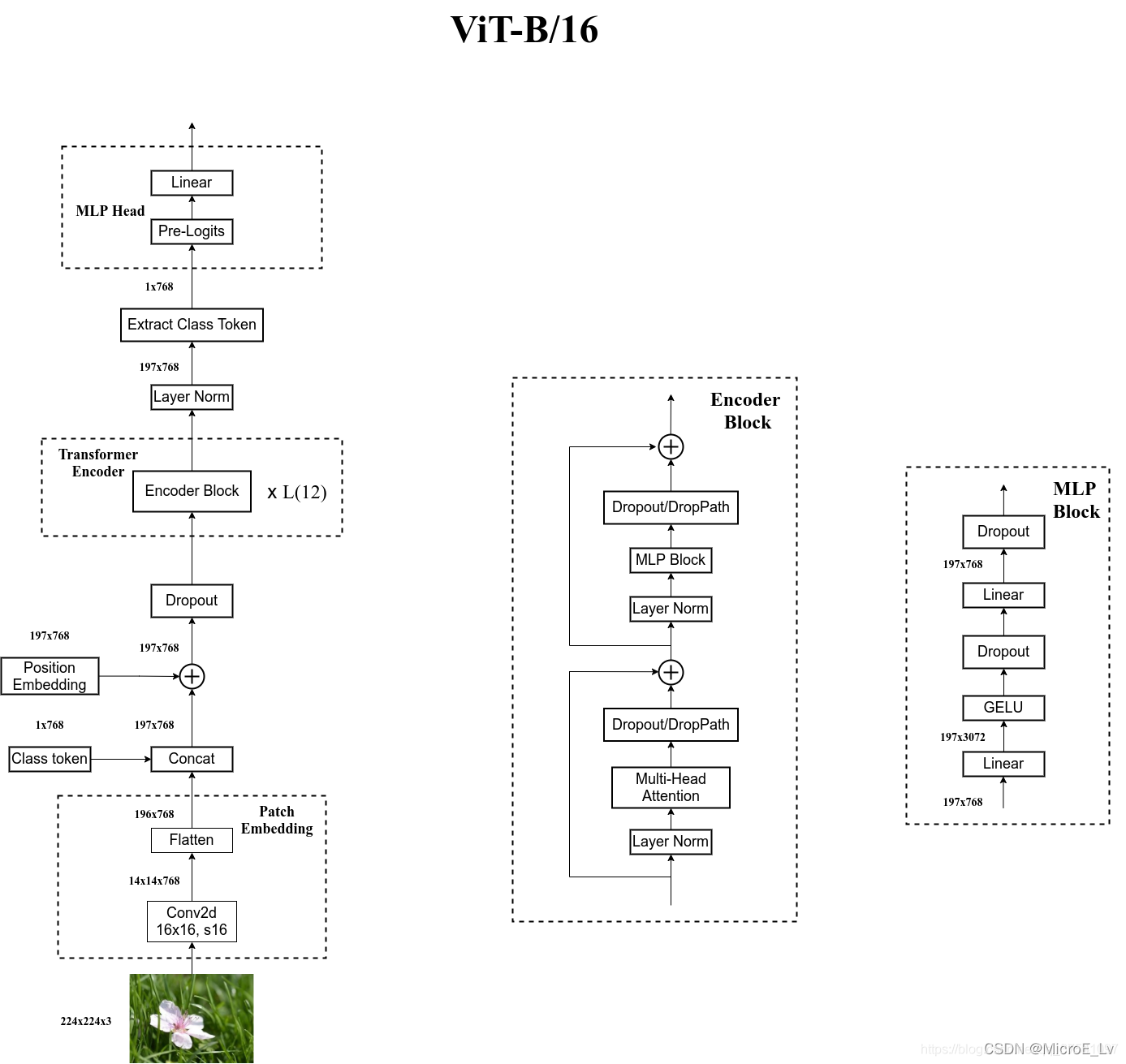
I. Patch Embedding层分析
输入输出:
- 224 × 224 × 3 224 \times 224 \times 3 224×224×3
- 196 × 768 196 \times 768 196×768
运算:
- Conv2d(卷积核大小 [ O , I , H , W ] → [ 768 , 3 , 16 , 16 ] [O, I, H, W] \rightarrow [768, 3, 16, 16] [O,I,H,W]→[768,3,16,16],步长是16)
- Flatten: [ 14 , 14 , 768 ] → [ 196 , 768 ] [14, 14, 768] \rightarrow [196,768] [14,14,768]→[196,768]
分析:
在原文中的计算量是主要是一个卷积层的计算量。这个卷积的主要作用就是,将输入图片下采样到 14 × 14 14\times 14 14×14,变成一个个小的patches, 再flatten之后就可以变成transformer的encoder层需要的输入了。
II. Concat & Position Embedding
Class token的插入:
Class token的维度是 1 × 768 1\times 768 1×768,并且是一个可训练的参数。在这里插入之后和Patch Embedding的输出拼接之后得到: C o n c a t ( [ 1 , 768 ] , [ 196 , 768 ] ) → [ 197 , 768 ] Concat([1, 768], [196,768]) \rightarrow [197,768] Concat([1,768],[196,768])→[197,768]
Position Embedding:
将每一个patch对应的position信息都要加入进来,所以是和Concat之后的维度是一样的,运算就是一个简单的加法,Position信息也是一个可训练的参数。
- 运算: A d d ( [ 197 , 768 ] , [ 197 , 768 ] ) → [ 197 , 768 ] Add([197, 768], [197,768]) \rightarrow [197,768] Add([197,768],[197,768])→[197,768]
- 维度: [ 197 , 768 ] [197,768] [197,768]
III. Transformer Encoder
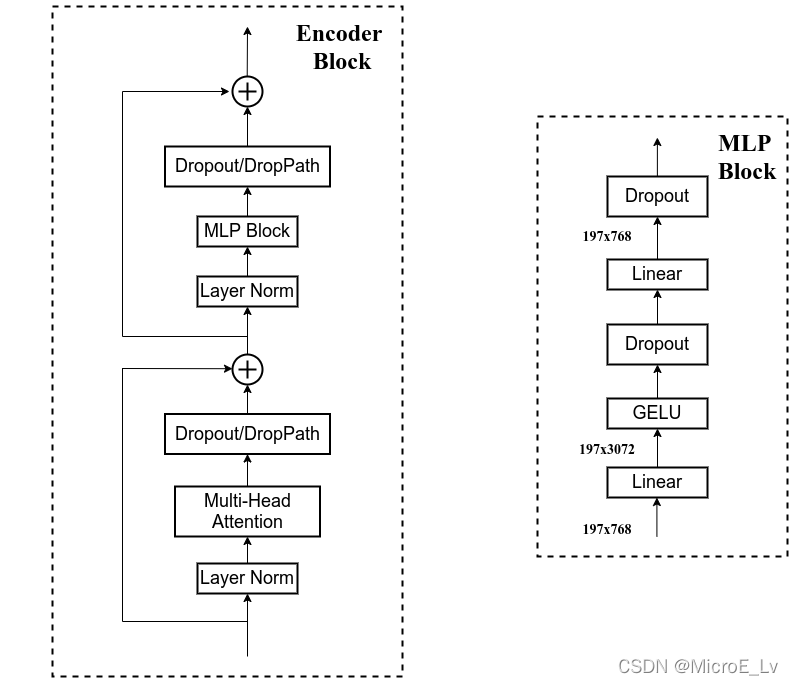
Encoder Block里面的整体结构大致如上图所示,包含以下几个部分:
- 第一个Residual结构里面有三个block和一个连线,分别是:
- Layer Normalization
- Multi-Head Attention
- Dropout
- 第二个Residual结构里面同样也有三个block和一个连线,分别是:
- Layer Normalization
- MLP Block
- Linear
- GELU
- Dropout
- Linear
- Dropout
- Dropout
下面分模块讲述。
A. 第一个 Layer Normalization
Layer Normalization的公式与Batch Normalization基本一致,即需要以下操作
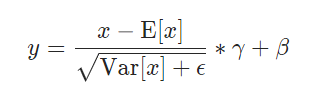
但是不同的是,Batch Normalization是对一个batch内的所有feature map,取它们每个channel的均值和方差进行channel级别的标准化,而Layer Normalization是对一个feature map中某个或某几个维度进行标准化。
运算:
Layer Normalization因为标准化的维度与BN有明显的不同,所以这就导致了它无法像BN一样可以在训练过程中直接获得 r u n n i n g _ m e a n running\_mean running_mean和 r u n n i n g _ v a r running\_var running_var,从而上面公式中可以作为参数的仅仅只有 γ \gamma γ和 β \beta β。因此,具体的运算如下:
- 求取该层的指定维度的期望: E [ x ] E[x] E[x]
- 求取该层的指定维度的方差: V a r [ x ] Var[x] Var[x]
- 根据已训练好的 γ \gamma γ和 β \beta β来运算标准化之后的结果
输入输出维度:
- 输入: [ 197 , 768 ] [197,768] [197,768]
- 输出: [ 197 , 768 ] [197,768] [197,768]
B. Multi-Head Attention
1. Self-Attention
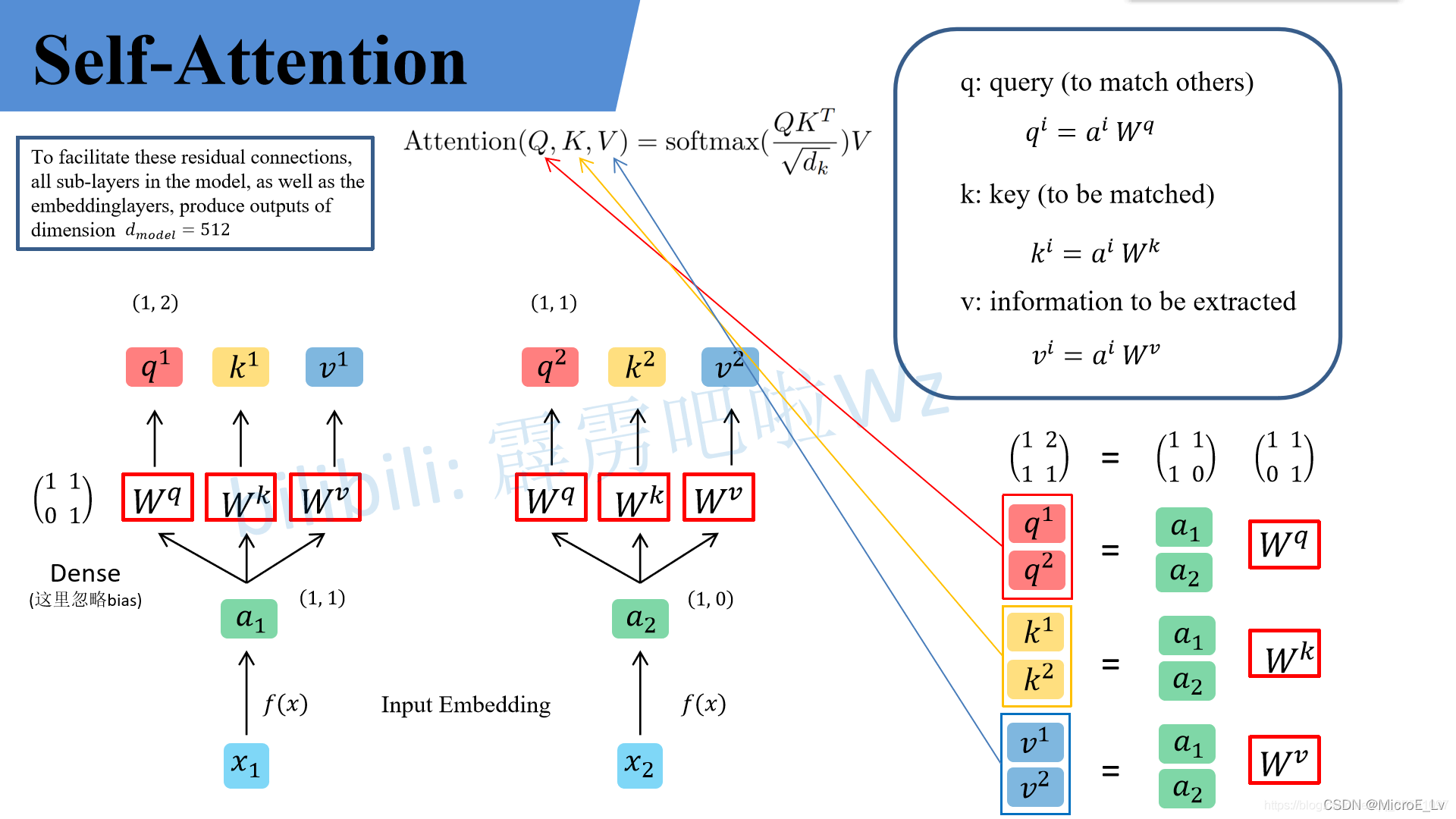
(图片来源于太阳花的小绿豆)
上图是非常基本的Self-Attention的运算流程。在上述运算中,可以看到最为重要的运算其实为两步:
- 得到 Q , K , V Q,K,V Q,K,V矩阵:即用输入值 a a a与对应的三个权重矩阵进行Matrix-Matrix Multiplication就可以得到三个矩阵。
- 计算Attention结果:即运算下面的公式,其中
S
o
f
t
m
a
x
Softmax
Softmax是对
Q
K
T
/
d
k
QK^T/\sqrt{d_k}
QKT/dk这个结果矩阵的每一行进行运算的。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
2. Multi-Head Self-Attention
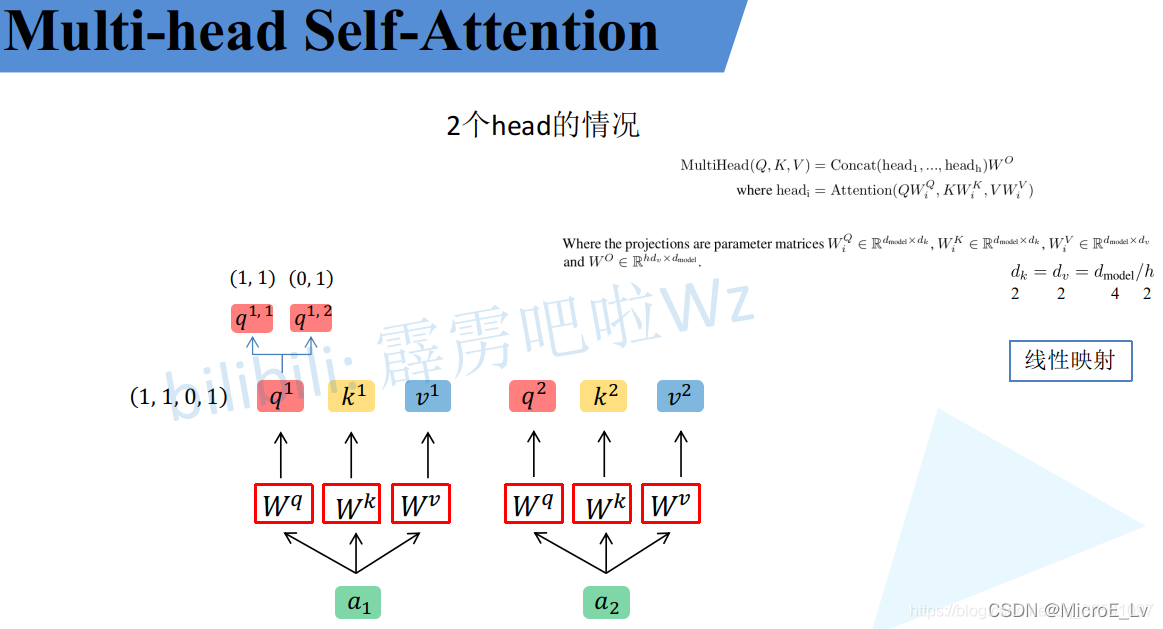
(图片来源于太阳花的小绿豆)
Multi-head Self-Attention 顾名思义就是在Self-Attention基础上将其中的部分矩阵变成Multi-head的形式,来获得更好的效果,其基本运算与Self-Attention大致无异,主要是多了一步多head的concat以及一个矩阵矩阵乘法:
- 得到 Q , K , V Q,K,V Q,K,V矩阵:即用输入值 a a a与对应的三个权重矩阵进行Matrix-Matrix Multiplication就可以得到三个矩阵。(这一步与Self-Attention保持一致)
- 将得到的 Q , K , V Q,K,V Q,K,V矩阵按照头的数量进行均匀的按行分配:这一步按照上面的图的方式进行分开。原本原文中是需要乘以对应的 W i Q , W i K , W i V ) W_i^Q, W_i^K, W_i^V) WiQ,WiK,WiV)来进行分开,但是实际操作大可不必。
- 对分开的 Q i , K i , V i Q_i,K_i,V_i Qi,Ki,Vi运算Self-Attention:这一步与上一节讲的Self-Attention运算基本一致。
- 将多头的Attention结果进行拼接,然后乘以
W
O
W^O
WO:这一步就是图中的:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W O MultiHead(Q,K,V) = Concat(head_1, \dots,head_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
3. ViT中的Multi-Head Self-Attention分析
原文中ViT-Base取得是12个head,那么下面就以12个head为例来分析一下维度问题。
按照前面几个图的计算流程,我推导出了下面的计算维度变化:
- 关键维度:
- d m o d e l = 768 d_{model} = 768 dmodel=768
- n u m h e a d = 12 num_{head} = 12 numhead=12
- d k = d m o d e l / n u m h e a d = 64 d_k = d_{model} / num_{head} = 64 dk=dmodel/numhead=64
- d k = 8 \sqrt{d_k} = 8 dk=8
- 输入: a → [ 197 , 768 ] a \rightarrow [197,768] a→[197,768]
- 计算
Q
,
K
,
V
Q,K,V
Q,K,V:
Q
=
a
×
W
q
,
K
=
a
×
W
k
,
V
=
a
×
W
v
Q = a\times W^q, K=a\times W^k, V=a\times W^v
Q=a×Wq,K=a×Wk,V=a×Wv
- W q , Q k , W v → [ 768 , 768 ] W^q, Q^k, W^v \rightarrow [768,768] Wq,Qk,Wv→[768,768]
- Q , K , V → [ 197 , 768 ] Q,K,V \rightarrow [197, 768] Q,K,V→[197,768]
- 多头均分:
Q
i
=
Q
W
i
Q
,
K
i
=
K
W
i
K
,
V
i
=
V
W
i
V
Q_i = Q W_i^Q, K_i = K W_i^K, V_i = V W_i^V
Qi=QWiQ,Ki=KWiK,Vi=VWiV。这个操作其实是将
Q
,
K
,
V
Q,K,V
Q,K,V均分,在实际系统中的倒也可以不用乘以这三个均分矩阵。
- W i Q , Q i K , W i V → [ 768 , 64 ] W_i^Q, Q_i^K, W_i^V \rightarrow [768,64] WiQ,QiK,WiV→[768,64]
- Q i , K i , V i → [ 197 , 64 ] Q_i,K_i,V_i \rightarrow [197, 64] Qi,Ki,Vi→[197,64]
- Attention运算:
- Q i K i T = [ 197 , 64 ] × [ 64 , 197 ] → [ 197 , 197 ] Q_i K_i^T = [197,64] \times [64,197] \rightarrow [197,197] QiKiT=[197,64]×[64,197]→[197,197]
- s o f t m a x ( Q K T d k ) → [ 197 , 197 ] softmax(\frac{QK^T}{\sqrt{d_k}}) \rightarrow [197,197] softmax(dkQKT)→[197,197]
- h e a d i = s o f t m a x ( Q K T d k ) V = [ 197 , 197 ] × [ 197 , 64 ] → [ 197 , 64 ] head_i = softmax(\frac{QK^T}{\sqrt{d_k}}) V = [197,197] \times [197,64] \rightarrow [197,64] headi=softmax(dkQKT)V=[197,197]×[197,64]→[197,64]
- 多头MultiHead运算:
- C o n c a t ( h e a d 1 , … , h e a d n ) → [ 197 , 768 ] Concat(head_1,\dots, head_n) \rightarrow [197,768] Concat(head1,…,headn)→[197,768]
- W O → [ 768 , 768 ] W^O \rightarrow [768,768] WO→[768,768]
- M u l t i H e a d ( Q , K , V ) → [ 197 , 768 ] MultiHead(Q,K,V) \rightarrow [197,768] MultiHead(Q,K,V)→[197,768]
将计算流程梳理完之后可以总结一下这个Multi-Head Self-Attention所需要的运算量大致有哪些:
- 2中的三个M2M
- 4中Attention运算的M2M,Scaling操作,和按行的Softmax,加一个M2M
- 6中在Concat结束之后的一个M2M
C. Dropout
这部分在前向传播中不需要额外运算
D. Residual的支线加
这里包含了一个 A d d ( [ 197 , 768 ] , [ 197 , 768 ] ) Add([197,768], [197,768]) Add([197,768],[197,768]) 矩阵矩阵按元素加法
E. 第二个Layer Normalization
运算与A中的运算基本一致,不需要赘述。
F. MLP Block
MLP Block的结构也如III节的第一个图所示,总共包含五层,下面依次讲解
1. 第一个Linear层
这个Linear层就是简单的全连接层,包含矩阵矩阵乘法和bias的加法。其中的维度变化是 [ 197 , 768 ] × [ 768 , 3072 ] → [ 197 , 3072 ] [197,768]\times [768, 3072] \rightarrow [197,3072] [197,768]×[768,3072]→[197,3072]
全连接层的参数矩阵大小是 [ 3072 , 768 ] [3072, 768] [3072,768]。
2. GELU(Gaussian Error Linear Units)
GELU是一个类似于ReLU的计划函数,但是本质上是在ReLU的基础上加入了Dropout的随机性。其数学表达式如下:
G
E
L
U
(
x
)
=
x
P
(
X
≤
x
)
=
x
Φ
(
x
)
GELU(x) = xP(X \leq x ) = x \Phi(x)
GELU(x)=xP(X≤x)=xΦ(x)
这里
Φ
(
x
)
\Phi(x)
Φ(x) 是正态分布的概率函数。对于假设为标准正态分布的
G
E
L
U
(
x
)
GELU(x)
GELU(x),论文中提供了近似计算的数学公式,如下:
G
E
L
U
(
x
)
=
0.5
x
(
1
+
t
a
n
h
[
2
/
π
(
x
+
0.044715
x
3
)
]
)
GELU(x) = 0.5x (1 + tanh[\sqrt{2/\pi} (x + 0.044715x^3)])
GELU(x)=0.5x(1+tanh[2/π(x+0.044715x3)])
这里参考了 alwayschasing博主的博文。
在实际应用中,其实可以利用近似的公式来进行运算。
3. Dropout
在这里不做赘述
4. 第二个Linear层
这个Linear层就是简单的全连接层,包含矩阵矩阵乘法和bias的加法。其中的维度变化是 [ 197 , 3072 ] × [ 3072 , 768 ] → [ 197 , 768 ] [197,3072]\times [3072, 768] \rightarrow [197,768] [197,3072]×[3072,768]→[197,768]。这个全连接层的主要作用便是将前一个全连接层扩展的特征图维度恢复到初始维度,保证输出的时候可以直接提取结果。
全连接层的参数矩阵大小是 [ 768 , 3072 ] [768,3072 ] [768,3072]。
5. Dropout
在这里同样不做赘述。
G. Dropout
不做赘述
H. 第二个Residual Block的支线加
这里包含了一个 A d d ( [ 197 , 768 ] , [ 197 , 768 ] ) Add([197,768], [197,768]) Add([197,768],[197,768]) 矩阵矩阵按元素加法
IV. MLP Head
根据本文参考的博文的描述,在训练中这个MLP Head是由 Linear + tanh激活函数 + Linear组成,但是在实际运算中,其实可以只用一个Linear就可以。
V. Class
在经过MLP Head之后,取第0个位置的token作为分类的特征就可以得到最终的结果。
















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









