






引言
LLM意为大型语言模型。ChatGPT就是一种LLM,作为一种人工智能技术,通过使用深度学习算法来处理和生成自然语言文本,这些模型通常需要大量的数据来训练,以便能够理解和生成人类语言。
本文将依次介绍Greedy Search(贪婪搜索)、Beam Search(集束搜索)、Top-K与Top-P(固态采样与动态采样),最后是Top-P中的几个常用概率缩放,并结合Python_tensorflow库进行编写。
Greedy Search(贪婪搜索)
Greedy Search有时也称作启发式搜索,在LLM中,通常指在每个 t 时刻选择下一个词时,根据 wt=argmaxwP(w|w1:t−1) 选择概率最高的词。
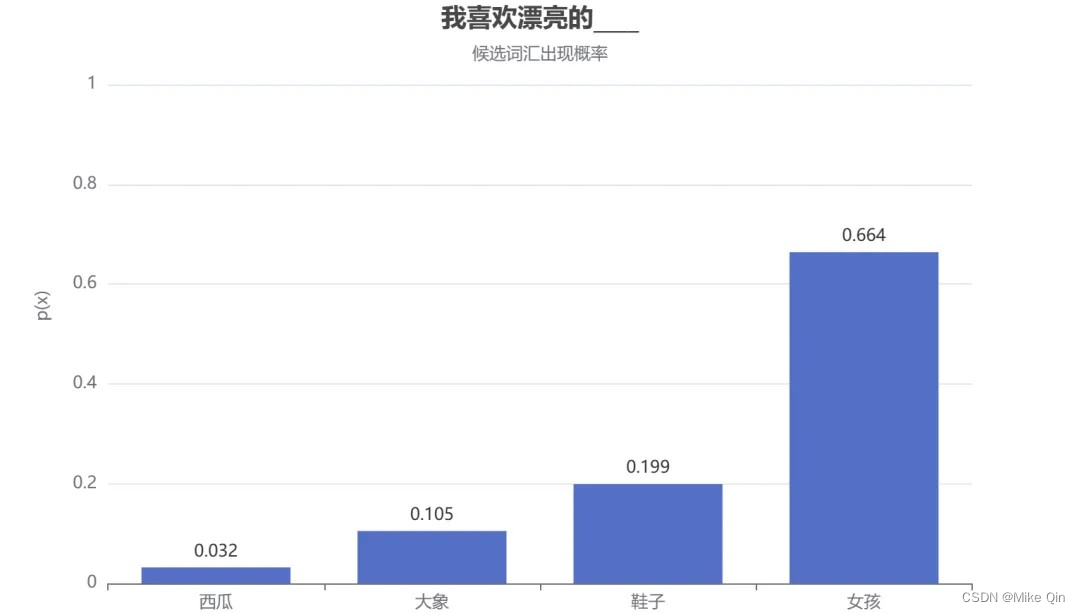
假设训练了一个描述个人喜好的模型,想让它来补全“我喜欢漂亮的___”这个句子。一般语言模型会按照下图的流程来工作:

模型会计算所有可能的单词,并根据其概率分布从中采样,以预测下一个词。假设模型预设的词汇量不大,只有:“大象”、“西瓜”、“鞋子”和“女孩”。通过下图的词汇概率可以发现,“女孩”的选中概率最高(p=0.664),“西瓜”的选中概率最低(p=0.032)。
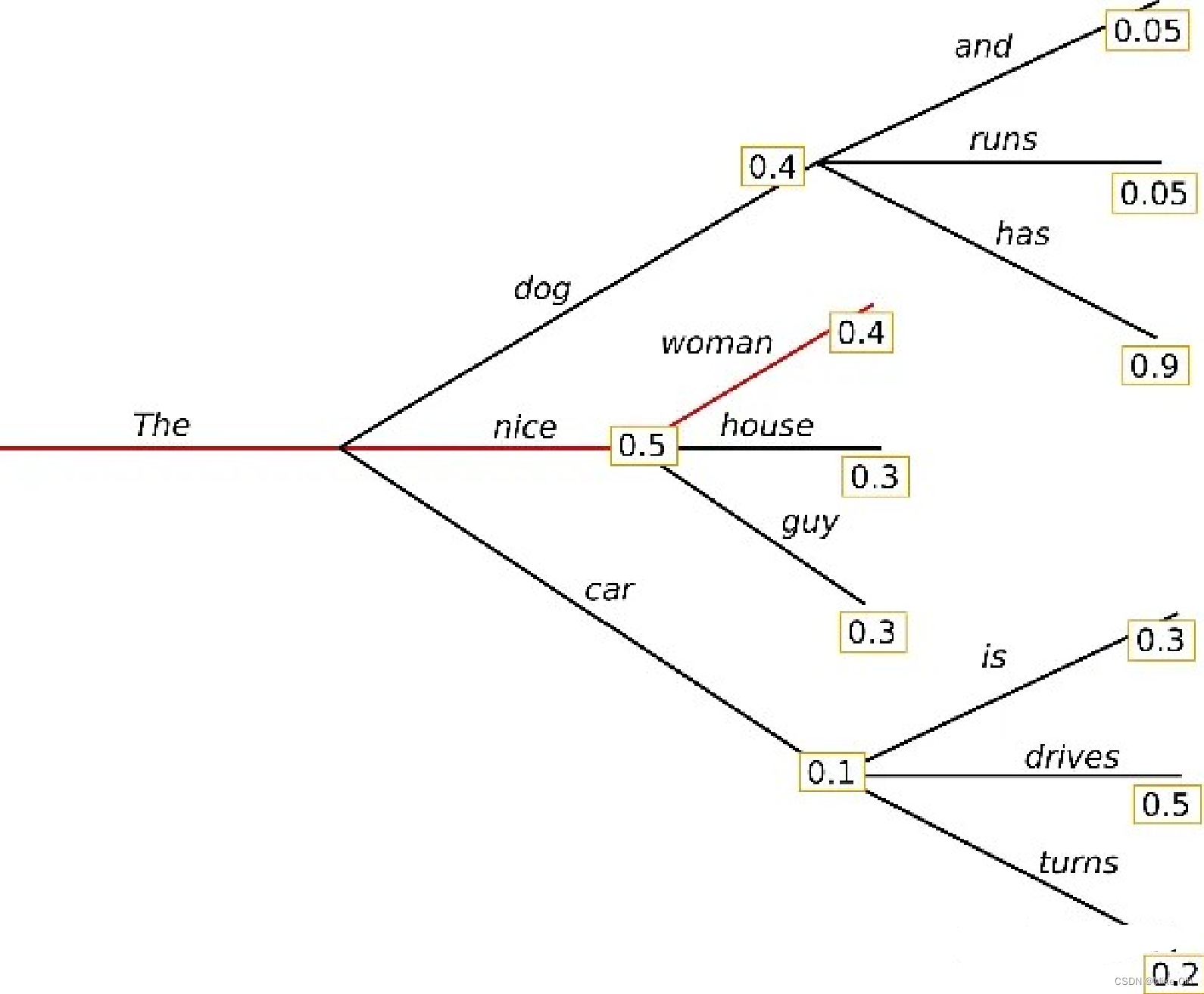
上面的例子中,很明显“女孩”最可能被选中,这就是 “贪心策略”,永远选择分数或概率最大的token。而贪婪搜索存在的一个最大的问题在于,只考虑了当前的最高概率词,忽略了中概率词:还是这个例子,词“has”在词“dog”后面,条件概率高达0.9,但词“dog”的条件概率只排第二,所以贪婪搜索错过了词序列“The”、“dog”、“has”。
下面来看贪婪搜索的Python实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
greedy_output = model.generate(input_ids, max_length=50)
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))请注意:为使程序正常运行,请先安装tensorflow库,官方源下载命令如下:
$> pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.0.0-cp35-cp35m-win_x86_64.whl或:
$> pip install --upgrade --ignore-installed tensorflow若无法安装成功,请先排除python版本问题,再去内地镜像站寻找可用的.whl。
在cohere的文档中,也有一个这样的例子:
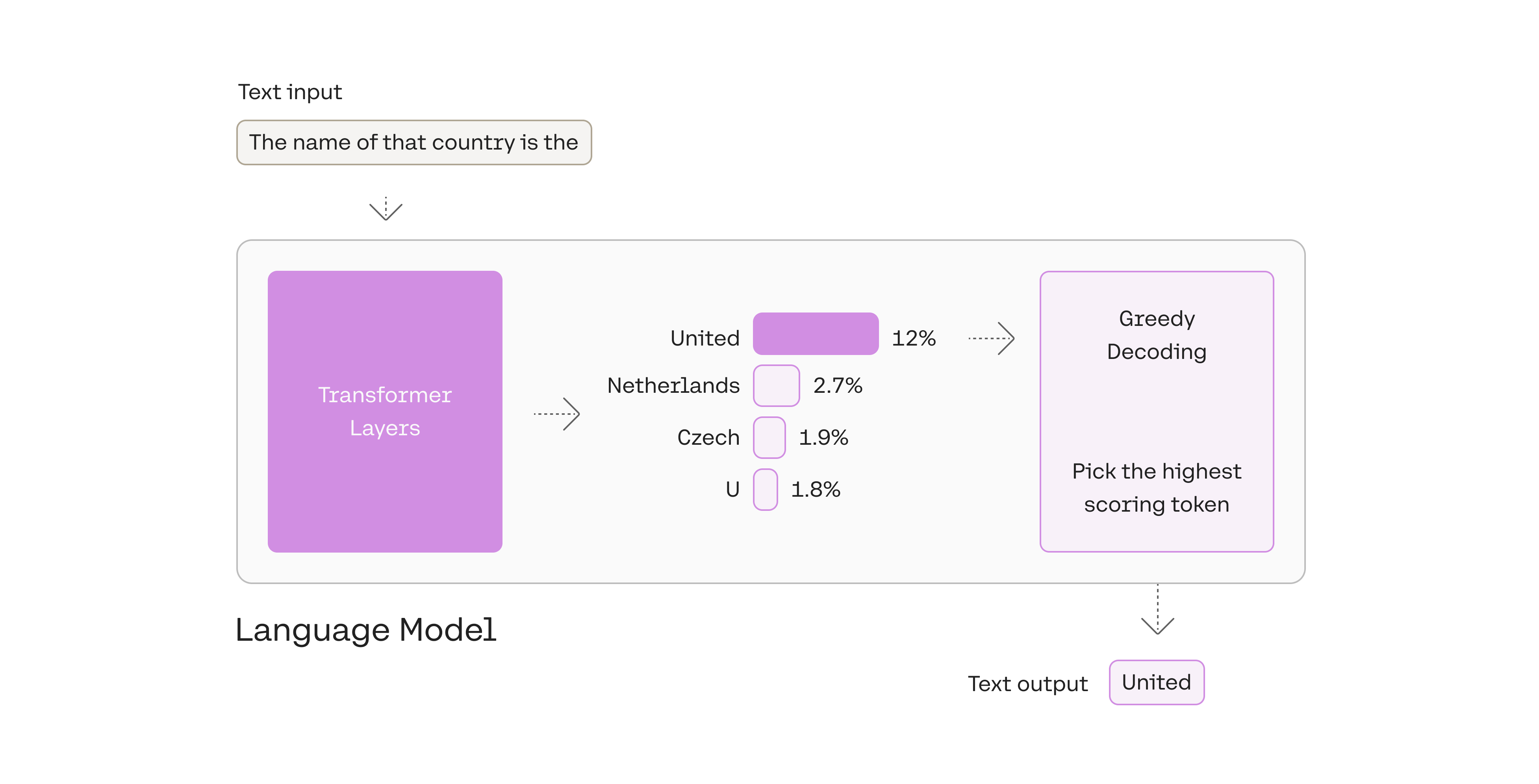
总是选择概率最高的token被称为“贪婪解码(贪婪算法)”。它很有用,但也有一些缺点。
贪婪解码是一种合理的策略,但也有一些缺点,例如:输出可能会卡在重复循环中。想想智能手机自动建议中的建议。当你不断选择建议最高的单词时,它可能会变成重复的句子。
Beams Search(集束搜索)
与贪婪搜索不同,集束搜索为了避免错过隐藏的高概率词,Beam Search通过参数num_beams的配置,可以在每个时刻,记录概率最高的前num_beams个路径,在下一个时刻可以有多个基础路径同时搜索。
当t=1时,最大概率的路径是(“The”、“nice”),beam search同时也会记录概率排第二的路径(“The”、“dog”);当t=2时,集束搜索也会发现路径(“The”、“dog”、“has”)有0.36的概率超过了路径(“The”、“nice”、“women”)的概率0.2。因此,两条路径中,找到了概率最高的路径,得到了更为合理的答案。
集束搜索生成的词序列比贪婪搜索生成的词序列的综合概率更高,但是也不能保证是概率最高的词序列。下面来看代码实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))不过,在开放领域生成任务的很多时候,集束搜索都不是最好的解码方式:
首先,集束搜索在做像是翻译和摘要这类可以大致预测生成长度的场景中表现还可以,但是在像是对话和故事生成这类开放生成领域效果就差得多了。
其次,我们已经看到集束搜索经常会生成重复内容,在故事生成中,我们很难决定要不要n-gram惩罚,因为我们很难确定强制不要重复还是有重复会更好。
最后,就是章首所提到的,高水平的人类语言不会按照下一个词条件概率最高的方式排列,所以就需要在此基础上优化采样方式。
Top-K固态采样与Top-P动态采样
从最高概率的Token中挑选:Top-K
Beam Search每次会选择在Beam中最大概率的词汇,Top-k采样是对前略面“贪心策”的优化,它从排名前k的token种进行抽样,允许其他分数或概率较高的token也有机会被选中,以达到有一定机率不选最大概率的词,常用的方法是从前3个token的候选名单中抽取样本,这种方法允许其他高概率token有机会被选中,而其引入的随机性有助于在许多情况下提高生成质量。
来看下面的示意图:
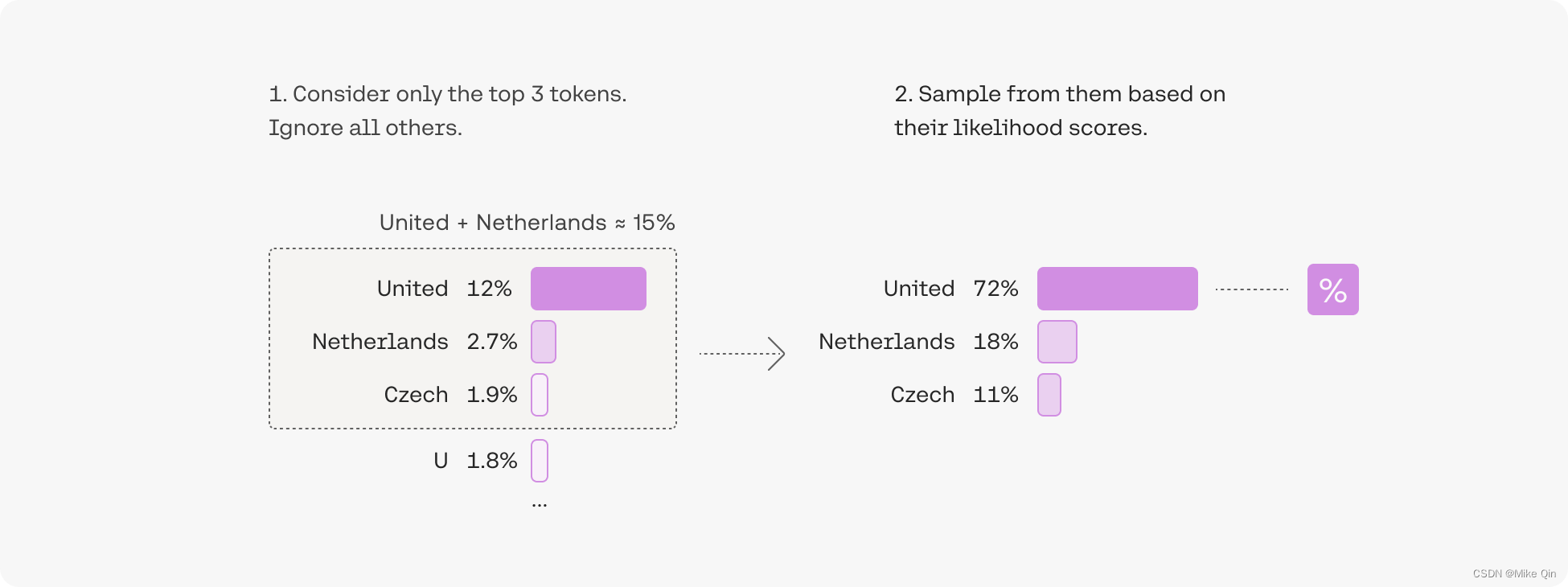
添加一些随机性有助于使输出文本更加自然:在前3名token中,我们首先筛选出三个token,然后通过考虑它们的似然分数对其中一个token进行采样。
选择前三个token意味着将Top-k参数设置为3。更改Top-k参数可设置模型在输出每个token时从中采样的候选列表的大小。若Top-k参数设置为1时,将成为贪婪搜索。具体的调整参照如下:
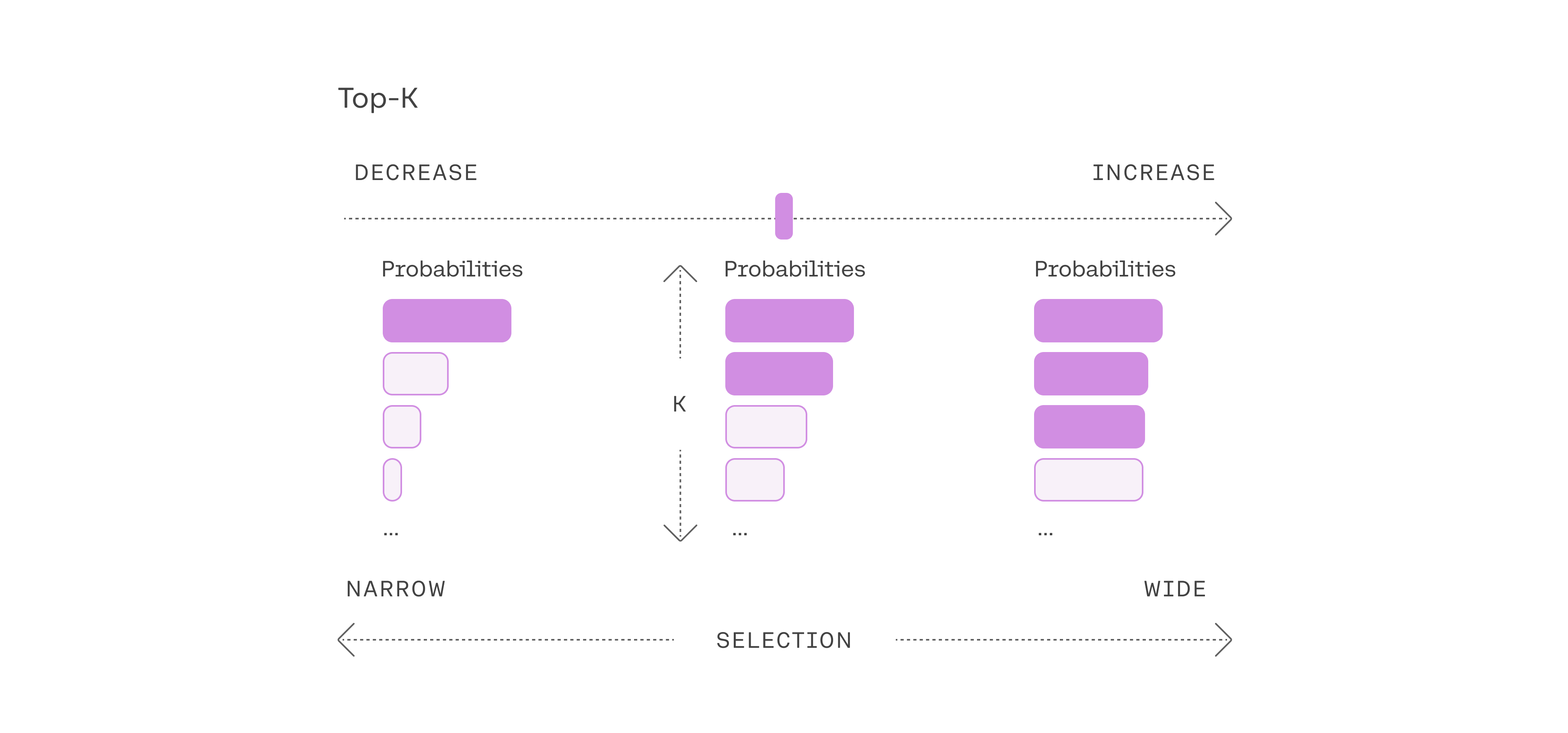
下面是Top-K的代码实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
tf.random.set_seed(0)
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=10
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))从概率加起来为 15% 的高概率Token中挑选:Top-P
选择最佳Top-k参数不简单,而Top-P方法可以动态设置token候选列表的大小。这种方法也称为 Nucleus Sampling(核采样),通过选择可能性总和不超过特定值的高概率token来创建候选名单。可以来看下面的示意图:
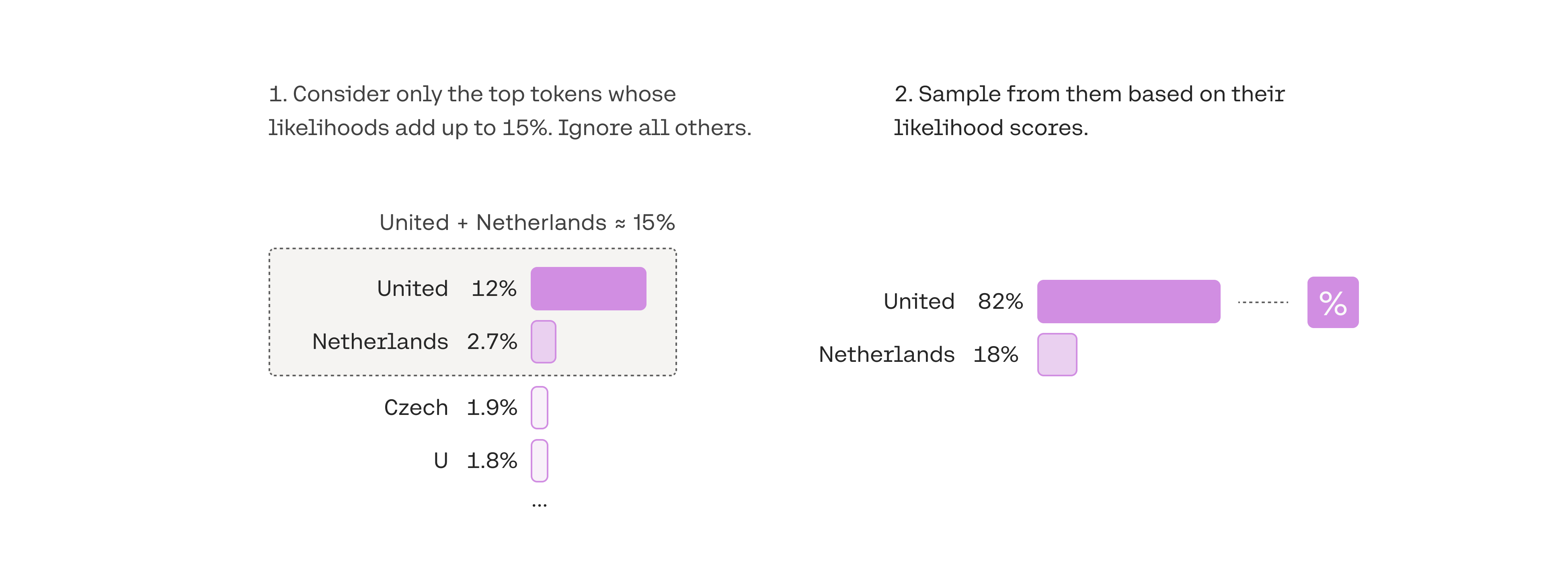
Top-p通常设置为高值(如 0.75),目的是限制可能采样的低概率token的长度。我们可以同时使用Top-k和Top-p。如果同时启用两者,则Top-p在Top-k之后执行操作。
下面是Top-p的代码示例:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
tf.random.set_seed(0)
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=3
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))强化采样:Temperature
Temperature(下文简称 T )是指从生成模型中抽样具有随机性,因此每次点击“生成”时,相同的提示可能会产生不同的输出。因此,T是用于调整随机度的参数。
来看下面的示意图:
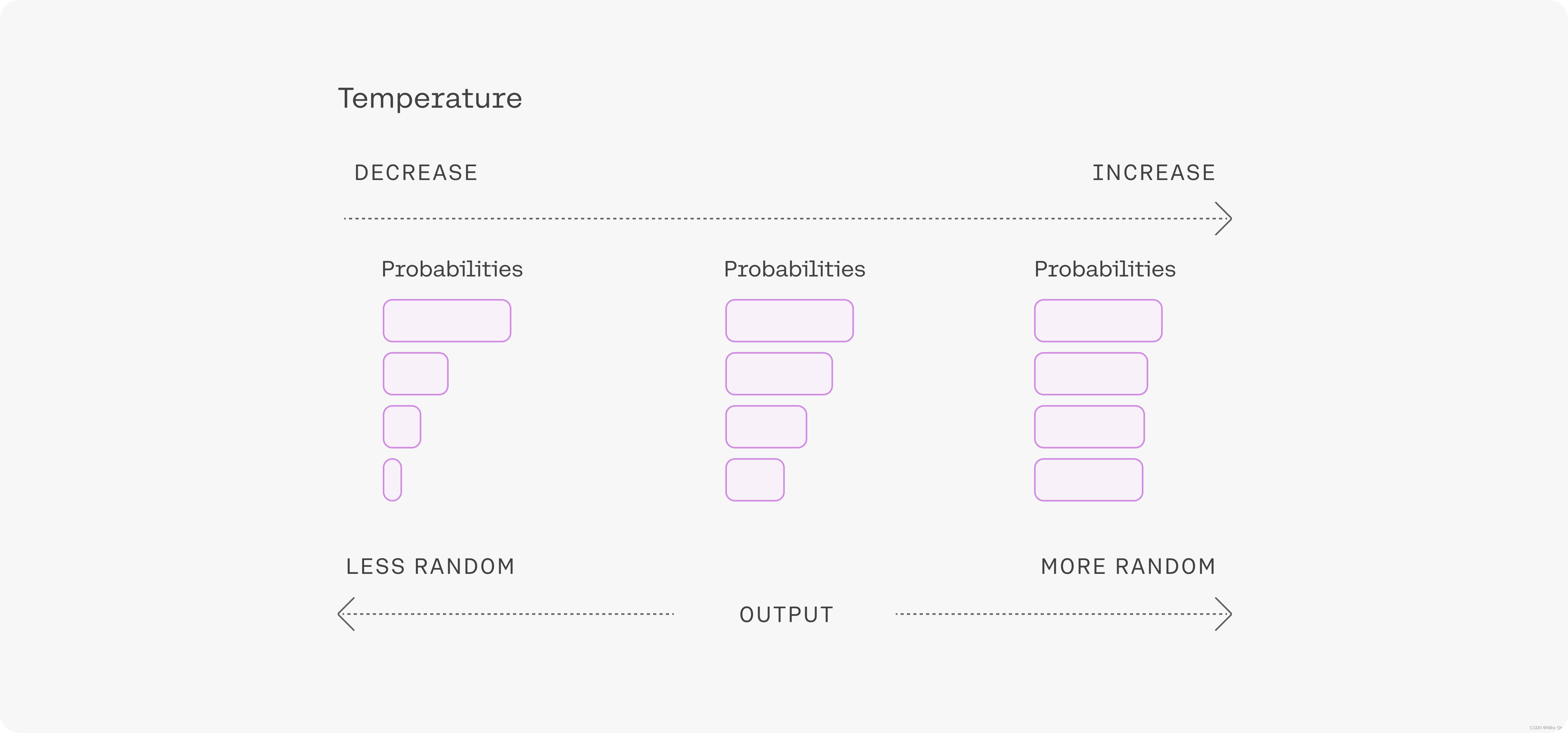
高T意味着更多的随机性。这可以帮助模型提供更多创造性的输出,但如果你使用的是检索增强生成(RAG),这也可能意味着它没有正确使用你提供的上下文。如果模型开始偏离主题,给出无意义的输出,则表明T参数设置过高。
下面来看Temperature的设置:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
tf.random.set_seed(0)
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=3,
temperature=1.5,
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))














 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









