







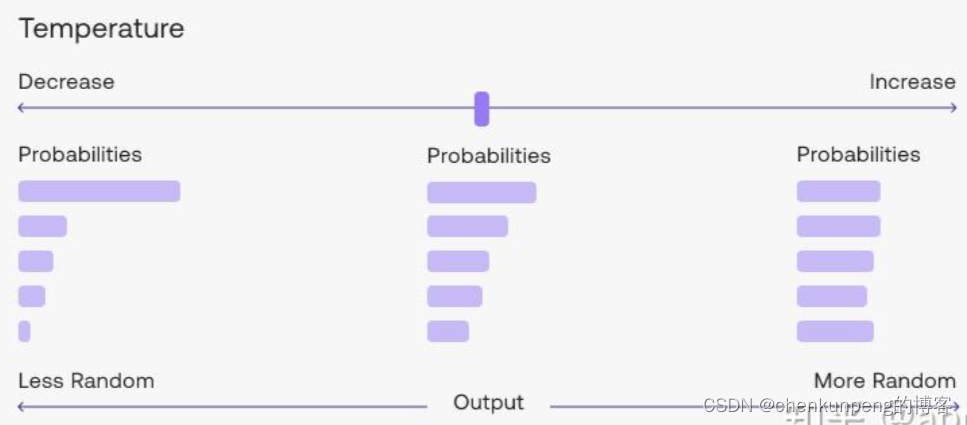
temperature
temperature用于调整模型softmax输出层的概率的平滑度,温度越高,概率分布越平滑;温度越低,概率分布越尖锐
所以较低的温度代表了确定性,适用于需要确定性答案或稳定效果的场景,如nl2sql,代码生成等;
较高的温度代表了随机性,适用于需要较大发挥空间的场景,如诗歌创作等。
top-p
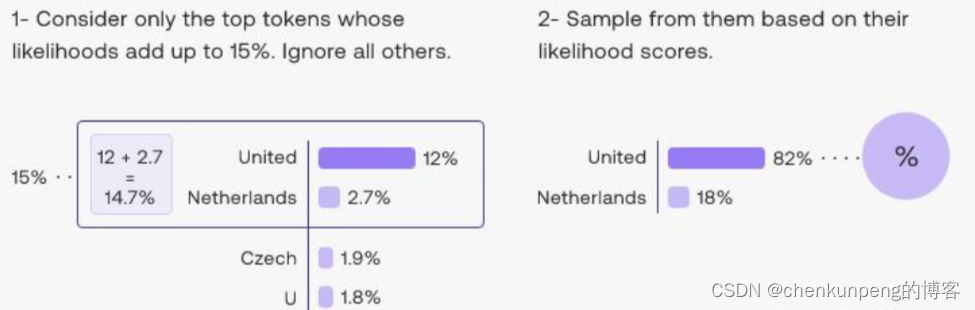
大模型选择输出token的时候,会有一个采样策略,用于选择输出哪些token,其中两种主要的采样方法就是top-k和top-p
top-p原理:
从概率加起来之和为p的top token中采样,称作top-p;该策略动态设置tokens候选列表的大小。这种称为Nucleus Sampling 的方法将可能性之和不超过特定值的top tokens列入候选名单。下图是top-p=0.15的例子:
使用建议
-
从上面的原理可以看到,temperature、top-p等参数用于控制生成文本的随机性,值越大随机性越大,意味着多样性和创造性,但可能产生胡言乱语。值越
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1900
1900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









