






论文地址: 《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》
源码地址: InsightFace: 2D and 3D Face Analysis Project
我优化的项目地址: insight_face_pro
本小节,人脸识别代码 insight_face_pro 项目讲解
二. 人脸识别代码 insight_face_pro 项目讲解
insight_face_pro 项目 结构如下:

我这里,仅以 f_mobile_face_net.py 网络模型来说明,如果你想尝试其他网络模型,请参考论文源码,修改一下,就可以用的了。
在对项目操作前,请先看 README.md 和 config.py 文件,这里,一个是说明文件,一个是配置文件。
README.md 文件 (论文,模型,数据,项目都可以从里面找到下载地址)
-
# [insight_face_pro](https://github.com/wandaoyi/insight_face_pro)
-
tensorflow, mxnet 版本的 insight_face 人脸识别项目
2020
-07
-23
-
-
-
-
-
- [论文地址](https://arxiv.org/abs/
1801.07698)
-
- [论文对应源码地址](https://github.com/deepinsight/insightface)
-
- [我的 CSDN 博客](https://blog.csdn.net/qq_38299170)
-
- 环境依赖(其实版本要求并不严格,你的版本要是能跑起来,那也是OK的):
-
```bashrc
-
pip install easydict
-
pip install numpy==
1.16
-
conda install tensorflow-gpu==
1.12
.0
-
pip install mxnet-cu90
-
pip install opencv-python
-
```
-
-
-
- [训练和验证数据下载地址](https://github.com/deepinsight/insightface/wiki/Dataset-Zoo)
-
- [预训练模型下载地址](https://github.com/deepinsight/insightface/wiki/Model-Zoo)
-
- All face images are aligned by [MTCNN](https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html)
and cropped to
112x112
-
- Face Detection, Please check RetinaFace(我的代码中没加入有, 但在作者源码中有)
for more details
-
-
-
-
-
- 将数据放到指定的文件目录下(config.py 文件):
-
- 其实,做好依赖,拿到数据,就仔细看看 config.py 文件,里面全是配置。配好路径或一些超参,基本上,后面就是一键运行就 OK 了。
-
- 对 config.py 进行配置设置。
-
-
## 数据生成
-
- 对于模型的训练或验证,我们都需要数据,这些数据,可以去下载开源的,也可以自己制作。
-
- 这里对于制作人脸数据,我使用的是数据蒸馏的方法。
-
- data_distillation.py 图原图进行人脸检测,人脸分类,人脸聚类等操作
-
- prepare.py 对分类或聚类后的人脸数据生成 .bin, .rec, .idx 等数据
-
- video_2_image.py 是将 视频流 转为 图像流
-
-
-
## 训练模型
-
- face_train.py 人脸识别训练
-
-
-
## 模型验证
-
- verification_model.py 人脸识别模型验证
-
-
-
- 对于模型测试,想弄的话,也很简单,利用数据库保存录入人的信息
-
- 测试的初始化,就将初始化
128 维人脸特征保存到缓存
-
- 当新的图像进入,先人脸检测,人脸矫正,再提取
128 维人脸特征
-
- 之后,再将新图像的
128 维特征 与 缓存的
128 维特征进行相似度计算
-
- 最后,选择大于阈值的人脸结果,再根据缓存获取到该用户的信息
-
-
-
## 本项目的优点
-
- 就是方便,很多东西,我已经做成傻瓜式一键操作的方式。里面的路径,如果不喜欢用相对路径的,可以在 config.py 里面选择 绝对路径
-
- 本人和唠叨,里面的代码,基本都做了注解,就怕有人不理解,不懂,我只是希望能给予不同的你,一点点帮助。
-
-
1. 模型验证(verification_model.py)
根据从 README.md 中下载的 数据 和 预训练模型,将其放置到 verification_model.py 文件中所指定的路径下,或,修改 config.py 中的路径,然后,一键运行 verification_model.py 文件,即可验证模型的精度。

我们可以观察到,预训练模型的 mAp 精度在 99.4% ~ 99.5% 左右。精度是相当高的,但是,对于人脸识别来说,这样的精度是不够的,需要更高的精度,才能满足业务需求(现在商汤人脸识别精度达到 99.8%左右)。这就需要对预训练模型,进行进一步训练,从而提升精度来契合业务需求。
2. 模型训练(face_train.py)
打开 face_train.py 文件,观察 def __init__(self): 方法中的 config.py 配置文件,配置好,还有将 __C.COMMON.STRUCTURE_DICT 中的参数配置好,就可以一键运行 face_train.py 文件,开始训练模型。
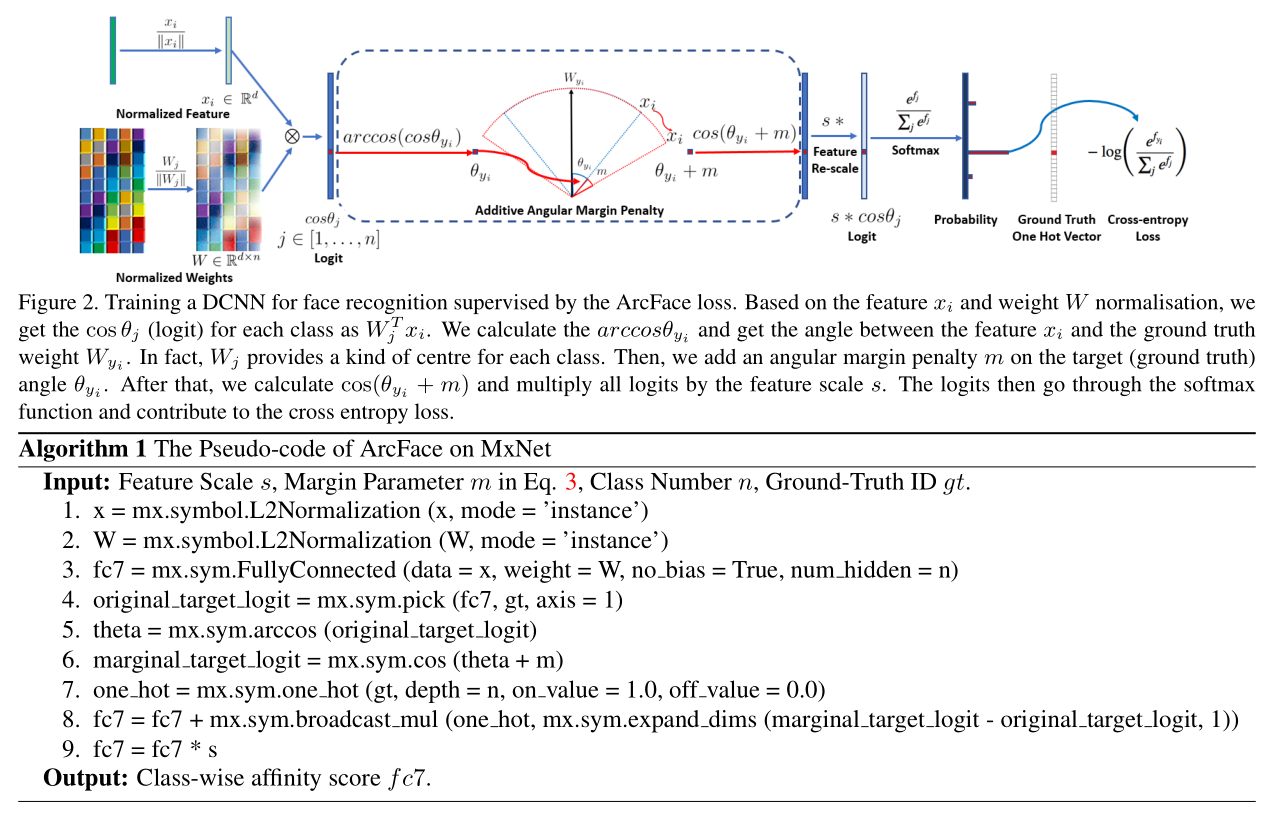
f_mobile_face_net.py 使用的是一个全卷积的残差网络,最后再加上一个 128 维的全连接层,然后,引入 margin_softmax 损失函数。训练的过程,请参考论文中的 Figure. 2 图所示:
在训练的过程中,发现有时候精度很难再提高,这时就需要对训练进行调优操作了:如学习率,数据,迭代次数,交叉验证,优化器等等。
对于训练和验证,可以参考 README.md 文件,里面有更多的 数据集 和 预训练模型。可以让你玩得开心。

3. 数据制作
这里的数据制作,包括两步:一步是数据蒸馏(data_distillation.py),一步是将目标数据制作成 .bin、.rec、.idx 验证和训练数据(prepare.py)。文件,都是一键运行操作的。
这里的数据蒸馏,是相对于图像来进行的,如果我们一下子搞不到大量的图像数据,我们可以通过将视频流转为图像流,从而得到大量的图像(video_2_image.py)。

数据蒸馏,大致可以分为 3 步(data_distillation.py):
(1). 对输入 图像 进行人脸检测 和人脸矫正

工作原理为: MTCNN_face_detection_alignment


(2). 对矫正后的人脸图像,进行分类,根据 identity 来对人脸进行分类。

在人脸分类中,info 文件夹中会生成三个 txt 文件(这 3 个文件只是用来做人工细化,对代码运行并无影响):

create_lib.txt 表示创建 新的 identity 文件夹,即表示当前的人脸与已有的人脸 identity 不同。

in_storage.txt 表示 与当前已有的人脸 identity 相同,然后会根据人脸相似度入库到对应的文件夹中去。

not_recognize.txt 表示没辨认出来的人脸,图像会输出到 output 文件夹中

在人脸分类后,我们可以人工参照 txt 和 identity 人脸文件夹中的人脸来进行辨别,是否有分错的,有些明显分错的人脸,我们要重新对它们入库,或移除。
(3). 对分类后的人脸图像进行聚类,以消除部分噪声人脸
人脸聚类,可以在一定程度上对 identity 身份文件夹中分错的人脸,或同样的人脸,进行一步提炼,会根据 人脸相似度来移除那些分错的人脸,和相同的人脸。从而在一定程度上减少手动观察筛选的操作,提高了工作效率。如果有相同的图像或分错的图像,也会在 info 文件夹中生成 txt 文件。
在人脸数据蒸馏的过程中,常常会于是一种脸盲的尴尬地步。就是,有时候,你会发现,有很多人脸,你感觉,它们都长得一样的,但是,计算机却有判断它们不一样。或,你明明感觉,它们不太像,但是,计算机又判断它们是同一个 identity。从而有些怀疑人生的感觉

生成训练、测试数据:
将上面数据蒸馏得到的好数据,用于生成 训练、测试数据(prepare.py): 通过上面数据蒸馏的繁琐操作,到了这里,就简单了,将数据放到指定的文件夹,一键运行操作即可得到目标数据。生成的训练数据中,property 文件表示如下:
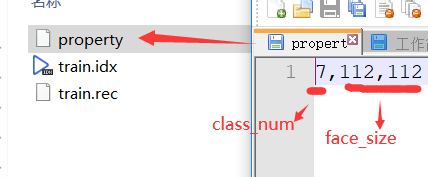
class_num 即为 identity number 的意思,表示有多少个人脸身份。
info 文件夹中会有这 3 个 txt 文件生成:
pair.tx 表示 生成 .bin 文件中,两两配对的图像,是否是同一个身份。如果是 True 则为同一个身份,False 则为不同身份
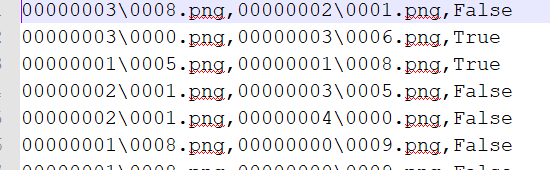
train_data.txt 表示 训练数据

val_data.txt 表示验证数据,pair.txt 就是由 这里的数据生成的。
这些 info 中的文件,只是用于参考 ,并不影响项目的运行。















 7902
7902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









