






大家好,今天将详细介绍如何训练HunyuanVideo模型的LoRA,从环境配置到最终的模型测试,每个步骤都会提供详细的操作指导和注意事项。本教程适合所有想要定制化训练自己视频生成模型的用户。
一、基础环境配置
1. 环境要求
成功训练HunyuanVideo LoRA需要以下基础环境:
-
Python 3.10 或更高版本
-
PyTorch 2.5.1 或更高版本
-
CUDA 兼容的显卡(推荐16GB及以上显存)
💡 小贴士:建议使用虚拟环境进行安装,可以避免依赖冲突。创建虚拟环境的命令:
python -m venv hunyuan-env。
2. 安装必要依赖
按照以下步骤进行依赖安装:
# 1. 激活虚拟环境 # Windows系统: hunyuan-env\Scripts\activate # Linux/Mac系统: source hunyuan-env/bin/activate # 2. 安装PyTorch pip install torch torchvision --index-url https://download.pytorch.org/whl/cu124 # 3. 安装项目依赖 pip install -r requirements.txt # 4. 安装扩展功能依赖(推荐) pip install ascii-magic matplotlib tensorboard
💡 小贴士:对于显存较小的显卡,推荐安装FlashAttention或SageAttention来优化显存使用,这些优化可以显著降低显存占用。
二、模型文件准备
1. 下载必要模型文件
训练过程需要以下核心模型文件:
- DiT模型文件:
- 从huggingface.co/tencent/HunyuanVideo下载
mp_rank_00_model_states.pt
- VAE模型文件:
- 下载
pytorch_model.pt
- 文本编码器文件:
-
Text Encoder 1:
llava_llama3_fp16.safetensors -
Text Encoder 2:
clip_l.safetensors
💡 小贴士:推荐按照以下结构组织模型文件,便于管理和调用:
ckpts/ ├── hunyuan-video-t2v-720p/ │ ├── transformers/ │ │ └── mp_rank_00_model_states.pt │ └── vae/ │ └── pytorch_model.pt ├── text_encoder/ │ └── llava_llama3_fp16.safetensors └── text_encoder_2/ └── clip_l.safetensors
三、数据集配置
1. 准备数据集配置文件
创建TOML格式的数据集配置文件,命名为dataset_config.toml:
[general] resolution = "720,1280" # 训练视频的分辨率 batch_size = 1 # 训练的批处理大小 [[datasets]] data_path = "path/to/your/dataset" # 数据集所在路径 caption_extension = ".txt" # 文本描述文件的扩展名
💡 小贴士:数据集中的视频帧必须与对应的描述文本一一对应,确保文件名匹配且格式规范。
2. 数据预处理
训练前需要进行两步数据预处理:
- 潜空间数据缓存:
python cache_latents.py --dataset_config dataset_config.toml \ --vae ckpts/hunyuan-video-t2v-720p/vae/pytorch_model.pt \ --vae_chunk_size 32 --vae_tiling
- 文本特征缓存:
python cache_text_encoder_outputs.py \ --dataset_config dataset_config.toml \ --text_encoder1 ckpts/text_encoder \ --text_encoder2 ckpts/text_encoder_2 \ --batch_size 16
💡 小贴士:显存不足时,可以调整
vae_spatial_tile_sample_min_size到128,并适当降低batch_size。显存低于16GB时,建议启用--fp8_llm参数。
四、模型训练
1. 启动训练流程
使用以下命令启动训练:
accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 hv_train_network.py \ --dit ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states.pt \ --dataset_config dataset_config.toml \ --sdpa --mixed_precision bf16 --fp8_base \ --optimizer_type adamw8bit \ --learning_rate 1e-3 \ --gradient_checkpointing \ --max_data_loader_n_workers 2 \ --persistent_data_loader_workers \ --network_module networks.lora \ --network_dim 32 \ --timestep_sampling sigmoid \ --discrete_flow_shift 1.0 \ --max_train_epochs 16 \ --save_every_n_epochs 1 \ --seed 42 \ --output_dir path/to/output_dir \ --output_name hunyuan-lora-v1
💡 小贴士:
显存不足时可以使用
--blocks_to_swap参数(最大值36)使用
--show_timesteps image可以监控训练过程建议从较小的
network_dim值开始尝试
五、模型测试与应用
1. 生成测试视频
使用以下命令测试训练好的LoRA模型:
python hv_generate_video.py \ --fp8 \ --video_size 544 960 \ --video_length 5 \ --infer_steps 30 \ --prompt "测试提示词" \ --save_path output/videos \ --output_type both \ --dit ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states.pt \ --attn_mode sdpa \ --split_attn \ --vae ckpts/hunyuan-video-t2v-720p/vae/pytorch_model.pt \ --text_encoder1 ckpts/text_encoder \ --text_encoder2 ckpts/text_encoder_2 \ --lora_weight path/to/your/lora.safetensors \ --seed 1234
💡 小贴士:
视频长度参数建议设置为4的倍数加1
使用
--output_type both可以同时保存中间结果,方便调试可以通过调整
lora_multiplier参数控制LoRA的效果强度
常见问题与解决方案
- 训练时显存不足的解决方案
-
降低batch_size值
-
启用
--fp8_base参数 -
使用
--blocks_to_swap功能 -
减小
network_dim参数值
- 生成视频黑屏的解决方法
-
确认PyTorch版本不低于2.5.1
-
尝试切换不同的注意力机制
- 训练速度优化方案
-
适当增加数据加载线程数
-
使用SSD存储训练数据
-
考虑使用更高性能的显卡
HunyuanVideo的LoRA训练是一个需要不断优化和调试的过程,建议在训练过程中详细记录各项参数和效果,以便找到最佳配置。本教程提供的参数和建议可以作为基础配置,大家可以根据实际情况进行调整和优化。
如何训练LorA
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!

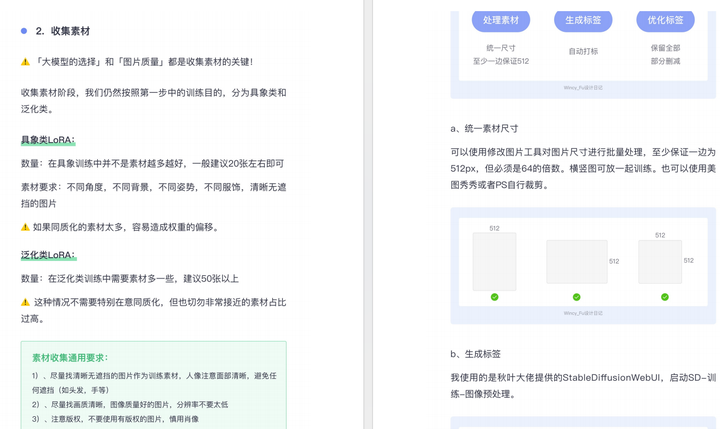
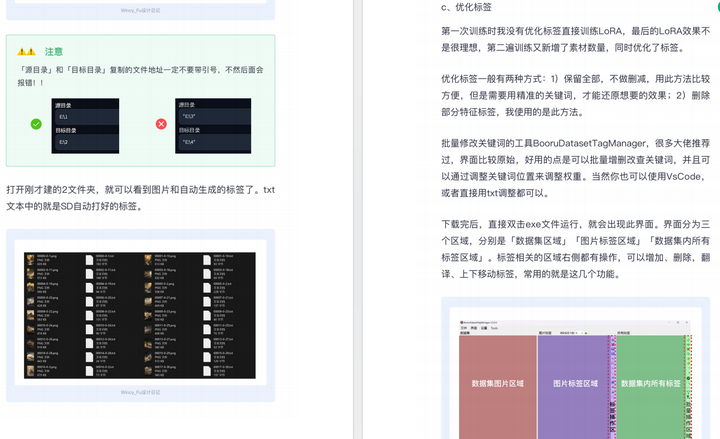
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









