







本文总结 lspci 相关的知识点 1‘ 2’ 3‘ 4’ 5’ 6。
本文的内容主要源自互联网技术博客及 SSDfans 网站 7。
持续更新中 …
Update: 2023 / 3 / 23
PCIe | 基础知识点扫盲
总览
总线,PCI 和 PCIe
总线
什么是总线?总线是一种传输信号的路径或信道。
典型情况是,总线是连接于一个或多个导体的电气连线,总线上连接的所有设备可在同一时间收到所有的传输内容。
总线由电气接口和编程接口组成。
PCI
PCI 是 Peripheral Component Interconnect(外围设备互联)的简称,是普遍使用在桌面及更大型的计算机上的外设总线规范
操作系统中的 PCI/PCI-E 设备驱动以及操作系统内核,都需要访问 PCI 及 PCI-E 配置空间。PCI / PCI-E 设备的正常运行,离不开 PCI / PCI-E 配置空间。通过读写 PCI / PCI-E 配置空间,可以更改设备运行参数,优化设备运行。
在
Linux内核中,为PCI / PCI-E只适用了一种总线PCI(内核提供的总线系统),故访问PCI-E配置空间,也包括了PCI设备配置空间。
PCIe
PCI-Express ( peripheral component interconnect express ),简称 PCIe,是一种高速串行计算机扩展总线标准,主要用于扩充计算机系统总线数据吞吐量以及提高设备通信速度。
PCIe 本质上是一种全双工的的连接总线,传输数据量的大小由通道数 lane 决定的。一般,1 个连接通道 lane 称为 X1,每个通道 lane 由 2 对数据线组成,1 对发送,1 对接收,每对数据线包含两根差分线。即 X1 只有 1 个 lane,4 根数据线,每个时钟每个方向 1bit 数据传输。依次类推,X2 就有 2 个 lane,由 8 根数据线组成,每个时钟传输 2bit。类似的还有X12、X16、X32。
和 PCI 并行总线不同,PCIe 的总线采用了高速差分总线,并采用端到端的连接方式, 因此在每一条 PCIe 链路中两端只能各连接一个设备, 如果需要挂载更多的 PCIe 设备,那就需要用到Switch 转接器,如下所示 8:

发展
接口的发展的关键时间节点如下:
| 时间 | 接口 |
|---|---|
| 1987 | ISA |
| 1992 | PCI |
| 2003 | PCIe Gen1 |
| 2017 | PCIe Gen5 |
| todo | PCIe Gen6 |
SSD 采用 PCI 接口是因为它比 SATA 快。
PCIe 是从 PCI 发展过来的,PCI 的 e 是 express 的简称,表示 快。
因为 PCIe 使用的是串口传输,而 PCI 使用并口传输(如下图所示)。

- 使用并口传输,虽然在并口时可以同时传输若干比特(比串口 ”划算“),但是接受端必须等最慢的那个
bit数据到了以后才能锁住整个数据。
随着技术发展,要求数据传输速率越来越快,意味着对时钟频率要求也越来越高。
在发送端发送出数据后,若需在接收端正确采集到数据,要求时钟的周期必须大于数据传输的时间(从发送端到接收端的时间,Flight Time), 受限于数据传输时间,时钟频率也不能太高(周期不能太短)。此外,时钟信号信号在线上传输时也会出现相位偏移(Clock Skew),影响接收端的数据采集。 - 使用串口传输,不需要外部时钟信号(因此不会有相位偏移的问题),时钟信号通过
8 / 10编码或者128 / 130编码嵌入在数据流中,接收端可从数据流中恢复时钟信息。
连接
PCIe

- 2个
PCIe设备之间通过多个Plane,比如1,2,4,8,12,16,32个lane相互连接。就像高速公路一样,有单车道、2车道、4车道等。
常见的是4个lane及以下,但PCIe是可以最多有32个lane的。 - 每个
Lane由1个Tx和 1个Rx组成,每个Tx / Rx由一对差分信号(differential signal)线组成,包含4条物理线。差分信号,抗干扰能力强,需要的电压值低。
差分信号(
Differential Signal)在高速电路设计中的应用越来越广泛,电路中最关键的信号往往都要采用差分结构设计,什么另它这么倍受青睐呢?
a. 抗干扰能力强,因为两根差分走线之间的耦合很好,当外界存在噪声干扰时,几乎是同时被耦合到两条线上,而接收端关心的只是两信号的差值,所以外界的共模噪声可以被完全抵消。
b. 能有效抑制 EMI,同样的道理,由于两根信号的极性相反,他们对外辐射的电磁场可以相互抵消,耦合的越紧密,泄放到外界的电磁能量越少。
c. 时序定位精确,由于差分信号的开关变化是位于两个信号的交点,而不像普通单端信号依靠高低两个阈值电压判断,因而受工艺,温度的影响小,能降低时序上的误差,同时也更适合于低幅度信号的电路。目前流行的LVDS(low voltage differential signaling)就是指这种小振幅差分信号技术。
- 2个设备之间的
PCIe连接,叫做一个Link。两个PCIe设备之间,有专门的发送和接收通道,数据可以同时往2个方向传输,PCIe Spec称这种工作模式为双单工模式(Dual-Simplex),可以理解为全双工模式。
打个比方,常见的 Gen4 速率的 PCIe 设备支持 Gen4 x 4,即双向的8通道高速公路(每个方向4通道),每对双向通道的 带宽 可达 4GB/s 的读写带宽(读带宽 2GB/s 或 写带宽 2GB/s)。
特点
- 对称性,每个连接在每个方向要支持对称数量的
Lane; PCIe是点对点的串行连接;- 全双工 (支持同时收发)
带宽
PCIe 是串行总线。
以 PCIe3.0 为例,线上的比特传输速率为 8 Gbps,物理层使用 128/130 编码进行数据传输,即 128 bit 的数据,实际在物理线路上是需要传输 130 bit 的,多余的 2 bit 用来校验。因此:
PCIe3.0 x 1 的带宽 = (8 Gbps x 2 (双向通道) x ( 128 bit / 130 bit ) / 8 ~= 2 GB/s。
有多少条 Lane,带宽就是 2 GB / s 乘以 Lane 的数目。
由于采用了 128 / 130 编码,即每128 bit的数据,只额外增加了 2 bit 的开销,有效数据传输比率增大。虽然线上比特传输率没有翻倍,但有效数据带宽还是在 PCIe 2.0 的基础上实现了翻倍。
SATA

同 PCIe 一样,SATA 也有独立的发送和接收通道。
但和 PCIe 不同的是,同一时间只有一条通道可以进行数据传输。换句话说,在一条通道上发送数据时在另一条通道上就不能接收数据。反之亦然。这种工作模式称为半双工模式。
打个比方,PCIe 就像双向车道,SATA 是单向车道。
寻址
先来看一个例子,我的电脑装有 1G 的 RAM,1G 以后的物理内存地址空间都是外部设备 IO 在系统内存地址空间上的映射。
/proc/iomem 描述了系统中所有的设备 I/O 在内存地址空间上的映射。我们来看地址从 1G 开始的第一个设备在 /proc/iomem 中是如何描述 的:
40000000-400003ff : 0000:00:1f.1
这是一个 PCI 设备,40000000-400003ff 是它所映射的内存地址空间,占据了内存地址空间的 1024 bytes 的位置。
而 0000:00:1f.1 则是一个 PCI 外设的地址, 它以冒号和逗号分隔为 4 个部分,第一个 16 位表示域,第二个 8 位表示一个总线编号,第三个 5 位表示一 个设备号,最后是 3 位,表示功能号
因为 PCI 规范允许单个系统拥有高达 256 个总线,所以总线编号是 8 位。但对于大型系统而言,这是不够的,所以,引入了域的概念,每个 PCI 域可以拥有最多 256 个总线,每个总线上可支持 32 个设备,所以设备号是 5 位,而每个设备上最多可有 8 种功能,所以功能号是 3 位。由此,我们可以得 出上述的 PCI 设备的地址是 0 号域 0 号总线上的 31 号设备上的 1 号功能。
那上述的这个 PCI 设备到底是什么呢?下面从主机上使用 lspci 命令所获得的输出内容:
00:00.0 Host bridge: Intel Corporation 82845 845 (Brookdale) Chipset Host Bridge (rev 04)
00:01.0 PCI bridge: Intel Corporation 82845 845 (Brookdale) Chipset AGP Bridge(rev 04)
00:1d.0 USB Controller: Intel Corporation 82801CA/CAM USB (Hub #1) (rev 02)
00:1d.1 USB Controller: Intel Corporation 82801CA/CAM USB (Hub #2) (rev 02)
00:1e.0 PCI bridge: Intel Corporation 82801 Mobile PCI Bridge (rev 42)
00:1f.0 ISA bridge: Intel Corporation 82801CAM ISA Bridge (LPC) (rev 02)
00:1f.1 IDE interface: Intel Corporation 82801CAM IDE U100 (rev 02)
00:1f.3 SMBus: Intel Corporation 82801CA/CAM SMBus Controller (rev 02)
00:1f.5 Multimedia audio controller:Intel Corporation 82801CA/CAM AC'97 Audio Controller (rev 02)
00:1f.6 Modem: Intel Corporation 82801CA/CAM AC'97 Modem Controller (rev 02)
01:00.0 VGA compatible controller: nVidia Corporation NV17 [GeForce4 420 Go](rev a3)
02:00.0 FireWire (IEEE 1394): VIA Technologies, Inc. IEEE 1394 Host Controller(rev 46)
02:01.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL-8139/8139C/8139C+(rev 10)
02:04.0 CardBus bridge: O2 Micro, Inc. OZ6933 Cardbus Controller (rev 01)
02:04.1 CardBus bridge: O2 Micro, Inc. OZ6933 Cardbus Controller (rev 01)
lspci 没有标明域,但对于一台 PC 而言,一般只有一个域,即 0 号域。通过这个输出我们可以看到它是一个 IDE interface。由上述的 输出可以看到,我的电脑上共有 3 个 PCI 总线( 0 号,1 号,2 号)。在单个系统上,插入多个总线是通过桥( bridge ) 来完成的,桥是一种用来连接总线的特殊 PCI 外设。所以,PCI 系统的整体布局组织为树型,我们可以通过上面的 lspci 输出,来画出我的电脑上的PCI 系统的树型结构:
00:00.0(主桥)--00:01.0(PCI桥)-----01:00:0(nVidia显卡)
|
|---00:1d(USB控制器)--00:1d:0(USB1号控制器)
| |
| |--00:1d:1(USB2号控制器) |
|-00:1e:0(PCI桥)--02:00.0(IEEE1394)
| |
| |-02:01.0(8139网卡)
| |
| |-02:04(CardBus桥)-02:04.0(桥1)
| |
| |--02:04.1(桥2)
|
|-00:1f(多功能板卡)-00:1f:0(ISA桥)
|
|--00:1f:1(IDE接口)
|
|--00:1f:3(SMBus)
|
|--00:1f:5(多媒体声音控制器)
|
|--00:1f:6(调制解调器)
由上图可以得出,我的电脑上共有 8 个 PCI 设备,其中 0 号总线上(主桥)上连有 4 个,1 号总线上连有 1 个,2 号总线上连有 3 个。00:1f 是一个连有 5 个功能的多功能板卡。
每一个 PCI 设备都有它映射的内存地址空间和它的 I/O 区域,这点是比较容易理解的。除此之外,PCI 设备还有它的配置寄存器。有了配置寄存器, PCI 的驱动程序就不需要探测就能访问设备。配置寄存器的布局是标准化的,配置空间的 4 个字节含有一个独一无二的功能 ID ,因此,驱动程序可通过查询外设的特定 ID 来识别其设备。所以,PCI 接口标准在 ISA 之上的主要创新在于配置地址空间。
前文已讲过,PCI 驱动程序不需要探测就能访问设备,而这得益于配置地址空间。在系统引导阶段,PCI 硬件设备保持未激活状态,但每个 PCI 主板均配备有能够处理 PCI 的固件,固件通过读写 PCI 控制器中的寄存器,提供了对设备配置地址空间的访问。
配置地址空间的前 64 字节是标准化的,它提供了厂商号,设备号,版本号等信息,唯一标识一个 PCI 设备。同时,它也提供了最多可多达 6 个的 I/O 地址区域,每个区域可以是内存也可以是 I/O 地址。这几个 I/O 地址区域是驱动程序找到设备映射到内存和 I/O 空间的具体位置的唯一途径。
有了这两点, PCI 驱动程序就完成了相当于探测的功能。关于这 64 个字节的配置空间的详细情况,可参阅 《Linux设备驱动程序第三版》 P306,不再详述。
示例
网卡设备
在自己的电脑上先用 lspci 命令检测使用的网络设备:
$ lspci | grep 'Eth'
07:00.0 Ethernet controller: Intel Corporation 82574L Gigabit Network Connection (rev 03)
$ lspci -tv
- [0000:00]-+-00.0 Advanced Micro Devices, Inc. [AMD] ... Root Complex
-+-01.0 Advanced Micro Devcies, Inc. [AMD] ... PCIe Dummy Host Bridge
-+-01.2-[01-0c]----00.0-[-2-0c]--+02.0-[03-08]----00.0-[04-08]--+--01.0-[05]----00.0 Intel Corporation Wi-Fi 6
+--03.0-[06]--
+--05.0-[07]----00.0 Intel Corportation 82574L Gigabit Network Connection
...
...
这里使用的网络接口是虚拟网卡 82574L。
注意这里的 07:00.0 表示的是网络接口对应的 pci 号,这些 pci 号唯一表示一个接口,在绑定驱动与解绑驱动时会使用到。
以 igb 驱动为例,查看 /sys/bus/pci/dirvers/igb 目录下的内容,
$ cd /sys/bus/pci/drivers/igb
0000:07:00.0 bind module new_id remove_id uevent unbind
这里的 0000:07:00.0 表示绑定到 igb 驱动上的 pci 接口的 pci 号。
绑定与解绑
网卡接口绑定主要与 bind 与 new_id 两个特殊的文件有关,unbind 是解绑驱动过程中会使用到的文件。
具体的绑定与解绑的过程就是向这几个文件中写入规定格式的数据完成的。linux kernel 源码目录中的 ABI/testing/sysfs-bus-pci 4 对这几个文件的描述信息如下:
-
bind
What: /sys/bus/pci/drivers/.../bind
What: /sys/devices/pciX/.../bind
Date: December 2003
Contact: linux-pci@vger.kernel.org
Description:
Writing a device location to this file will cause
the driver to attempt to bind to the device found at
this location. This is useful for overriding default
bindings. The format for the location is: DDDD:BB:DD.F.
That is Domain:Bus:Device.Function and is the same as
found in /sys/bus/pci/devices/. For example::
# echo 0000:00:19.0 > /sys/bus/pci/drivers/foo/bind
(Note: kernels before 2.6.28 may require echo -n).
这里写入的 0000:00:19.0 就是上面我们提到过的 pci 号。
对 bind 文件写入每一个接口的 pci 号意味着我们可以将一个网卡上的不同口绑定到不同的驱动上 9。
-
unbind
What: /sys/bus/pci/drivers/.../unbind
What: /sys/devices/pciX/.../unbind
Date: December 2003
Contact: linux-pci@vger.kernel.org
Description:
Writing a device location to this file will cause the
driver to attempt to unbind from the device found at
this location. This may be useful when overriding default
bindings. The format for the location is: DDDD:BB:DD.F.
That is Domain:Bus:Device.Function and is the same as
found in /sys/bus/pci/devices/. For example::
# echo 0000:00:19.0 > /sys/bus/pci/drivers/foo/unbind
(Note: kernels before 2.6.28 may require echo -n).
这里向 unbind 文件写入接口的 pci 号就会解除当前绑定的驱动。
一个接口可以不绑定到任何驱动上面,不过我们常常不会这样去做。
-
new_id
What: /sys/bus/pci/drivers/.../new_id
What: /sys/devices/pciX/.../new_id
Date: December 2003
Contact: linux-pci@vger.kernel.org
Description:
Writing a device ID to this file will attempt to
dynamically add a new device ID to a PCI device driver.
This may allow the driver to support more hardware than
was included in the driver's static device ID support
table at compile time. The format for the device ID is:
VVVV DDDD SVVV SDDD CCCC MMMM PPPP. That is Vendor ID,
Device ID, Subsystem Vendor ID, Subsystem Device ID,
Class, Class Mask, and Private Driver Data. The Vendor ID
and Device ID fields are required, the rest are optional.
Upon successfully adding an ID, the driver will probe
for the device and attempt to bind to it. For example::
# echo "8086 10f5" > /sys/bus/pci/drivers/foo/new_id
向 new_id 中写入设备 id,将会动态的在 pci 设备驱动中添加一个新的设备 id。这种功能允许驱动添加更多的硬件而非仅有在编译时包含到驱动中的静态支持设备 ID 列表中的硬件。
写入这个文件的格式中,Vendor Id 与 Device Id 字段是必须的,其它的字段可以不指定。
成功添加一个设备 ID 时,驱动会尝试 probe 系统中匹配到的设备并尝试绑定到它之上。
-
remove_id
What: /sys/bus/pci/drivers/.../remove_id
What: /sys/devices/pciX/.../remove_id
Date: February 2009
Contact: Chris Wright <chrisw@sous-sol.org>
Description:
Writing a device ID to this file will remove an ID
that was dynamically added via the new_id sysfs entry.
The format for the device ID is:
VVVV DDDD SVVV SDDD CCCC MMMM. That is Vendor ID, Device
ID, Subsystem Vendor ID, Subsystem Device ID, Class,
and Class Mask. The Vendor ID and Device ID fields are
required, the rest are optional. After successfully
removing an ID, the driver will no longer support the
device. This is useful to ensure auto probing won't
match the driver to the device. For example::
# echo "8086 10f5" > /sys/bus/pci/drivers/foo/remove_id
remove_id 中写入的格式与 new_id 的写入格式相同。
写入 remove_id 可以用来确保内核不会自动 probe 匹配到这个驱动的设备。
先写入数据到 new_id 添加设备 id 然后进行绑定。
这样确保了首先有注册的设备 id,有了这个设备 id 总线才能够 match 到驱动执行 probe 操作。
没有注册的设备 id,pci 总线不会匹配到指定的驱动,也无法将设备绑定到相应的驱动上。
为了成功绑定接口到 igb 上,我们首先需要在 igb 中添加支持的设备,这个可以通过写入数据到 new_id 添加设备 id 后写入 bind 文件来完成。
同一个设备
id可以写入多次到new_id中,要移除也需要写入相同的次数到remove_id中。注意写入到remove_id并不会解除绑定。
new_id的写入的参数中没有pci号,因此不能指定只绑定相同型号网卡的单个口到驱动中。除非其它口已经绑定到了其它驱动,不然这些口都会被绑定。
异常处理
如果绑定失败的情况,可能导致该结果的情形有:
new_id没有添加,不会match到指定的驱动;probe过程异常,绑定失败;
通常,可以通过查看 dmesg 信息来分析定位问题所在。
当写入设备 id 到 new_id 文件中会出触发总线匹配系统中的接口,属于写入的设备 id 的设备并且没有绑定到任何驱动上的接口将会全部会被绑定到 new_id 所属的驱动。
例如系统中有两个 82574L 网卡接口,都没有绑定驱动,这时我们写入 82574L 的设备 id 到 igb 驱动对应的 new_id 文件中,会导致这两个口都绑定到 igb 上。
如果这种行为对功能有所影响,可以选择在绑定到 igb 之前先将接口绑定到其它驱动上(一般是官方驱动),这样在写入 new_id 文件时,已经绑定到其它驱动的接口就会被 skip。
I / O
可以在目录 /sys/bus/pci/drivers/ 下看到很多以驱动命名的文件夹。在相应的文件夹中,存在以 PCI 设备名命名的子文件夹,但不是说这些设备都存在于你的系统中。
下面来看一下该网卡设备的配置空间的详细情况。
我们进入 /sys/bus/pci/drivers/igb/ 目录,其中有一个以它的设备地址 0000:07:00.0 命名的目录。在这个目录下可以找到该网卡设备相关的很多信息。其中 resource 记录了它的 6 个 I/O 地址区域。内容如下:
0x00000000fc300000 0x00000000fc31ffff 0x0000000000040200
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x000000000000f000 0x000000000000f01f 0x0000000000040101
0x00000000fc320000 0x00000000fc323fff 0x0000000004020000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
由该文件可以看出,此设备使用了两个 I/O 地址区域,一个映射了 I/O 端口范围,一个是它映射的内存地址空间。
关于这两个值可以在 /proc/iomem 和 /proc/ioports 中得到验证,
$ cat /proc/iomem | grep '0000:07:00.0'
fc300000-fc31ffff : 0000:07:00.0
fc320000-fc323fff : 0000:07:00.0
$ cat /proc/ioports | grep '0000:07:00.0'
f000-f01f : 0000:07:00.0
存储设备
在自己的电脑上先用 lspci 命令检测使用的非易失性存储设备:
$ lspci | grep 'Non-Volatile'
01:00.0 Non-Volatile memory controller: ... Device (rev 01)
02:00.0 Non-Volatile memory controller: ... Device (rev 01)
这里的 01:00.0 和 02:00.0 表示的是 SSD 设备对应的 pci 号。
spdk
以 spdk 驱动为例,驱动加载成功后可以在 /sys/module 路径下找到 uio_pci_generic,代表驱动加载成功。也可以通过 lsmod | grep uio 命令来确认驱动是否加载成功。
查看 /sys/bus/pci/dirvers/uio_generic 目录下的内容可确定加载了 spdk 驱动的设备信息,
$ cd /sys/bus/pci/drivers/uio_generic
0000:01:00.0 0000:02:00.0 bind module new_id remove_id uevent unbind
这里的 0000:01:00.0 和 0000:02:00.0 表示绑定到 spdk 驱动上的 pci 接口的 pci 号。
也可以在 /dev 下看到多个 uio 设备。
# ls /dev/uio*
/dev/uio0 /dev/uio1
绑定与解绑
解绑一个设备,只需将设备的 pci 总线 bdf 号写入 /sys/bus/pci/drivers/uio_generic/不同的设备驱动不同/unbind 即可,比如,
echo 0000:01:00.0 > /sys/bus/pci/drivers/uio_generic/unbind
绑定一个设备,和解绑类似,将设备的 pci 总线 bdf 号写入 /sys/bus/pci/drivers/uio_generic/不同的设备驱动不同/bind,比如,
echo 0000:01:00.0 > /sys/bus/pci/drivers/uio_generic/bind
然后,查看如下目录 /sys/bus/pci/devices/0000:01:00.0/ 是否有 uio 子目录,例如下面这样表示驱动绑定成功。
$ ll /sys/bus/pci/devices/0000\:01\:00.0/uio
total 0
drwxr-xr-x 3 root root 0 6月 26 14:52 ./
drwxr-xr-x 5 root root 0 6月 18 23:54 ../
drwxr-xr-x 3 root root 0 6月 26 14:52 uio0/
I / O
可以在目录 /sys/bus/pci/drivers/uio_generic 下看到很多以 PCI 设备名命名的目录,但不是说这些设备都存在于你的系统中。
以其中一个设备为例,进入 0000:01: 00.0 命名的目录。在这个目录下可以找到该设备相关的很多信息。其中 uio/uio0/device/resource 记录了它的 6 个 I/O 地址区域。内容如下:
0x00000000fcb00000 0x00000000fcb03fff 0x0000000000140204
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
$ cat /proc/iomem | grep '0000:01:00.0'
fcb00000-fcb03fff : 0000:01:00.0
$ cat /proc/ioports | grep '0000:01:00.0'
nvme
参考这里 12
linux 内核从 2.6.13-rc3 开始,提供了在用户空间动态的绑定和解绑定设备和设备驱动之间关系的功能。
在这之前,只能通过 insmod( modprobe )和 rmmod 来绑定和解绑,而且这种绑定和解绑都是针对驱动和所有设备的。而新的功能可以设置驱动和单个设备之间的联系。
这里,我们以 pci 总线的 nvme ssd 为例,首先执行 lspci 显示所有的 nvme ssd。
# lspci | grep memory
10:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a802 (rev 01)
有如上这么多 nvme ssd,那么可以在 /dev 下看到多个 nvme 设备( OS 启动后默认加载 nvme 驱动)。
# ls /dev/nvme*
/dev/nvme0 /dev/nvme0n1
同时,对于所有的 nvme 设备(这里我们以 pci 总线 bdf 号为 10:00.0 的 ssd 为例),都可以在 nvme 驱动下看到。其中,bind 和 unbind 文件就是涉及到绑定和解绑的关键文件。
绑定与解绑
解绑一个 nvme 设备,只需将设备的 pci 总线 bdf 号写入 /sys/bus/pci/drivers/nvme(不同的设备驱动不同)/unbind 即可:
/sys/bus/pci/drivers/nvme# echo -n "0000:10:00.0" > unbind
解除绑定成功,再查看目录下文件,该驱动下不再有对应的设备。同时,/dev 下也没有对应的nvme 设备了。
绑定一个 nvme 设备,和解绑类似,将设备的 pci 总线 bdf 号写入 /sys/bus/pci/drivers/nvme(不同的设备驱动不同)/bind:
/sys/bus/pci/drivers/nvme# echo -n "0000:09:00.0" > bind
绑定成功,再次展示该目录下所有文件,可以发现对应设备再次出现。
I / O
可以在目录 /sys/bus/pci/drivers/nvme 下看到很多以 PCI 设备名命名的目录,但不是说这些设备都存在于你的系统中。
以其中一个设备为例,进入 0000:10: 00.0 命名的目录。在这个目录下可以找到该设备相关的很多信息。其中 nvme/nvme0/device/resource 记录了它的 6 个 I/O 地址区域。内容如下:
0x00000000fbc00000 0x00000000fbc03fff 0x0000000000140204
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
$ cat /proc/iomem | grep '0000:10:00.0'
fbc00000-fbc03fff : 0000:10:00.0
$ cat /proc/ioports | grep '0000:10:00.0'
拓扑结构
参考这里 13
树这个概念我们应该是很熟悉的了,生活周围到处都是。树的主要四部分是根、干、枝、叶。
而树根一般在地下。我们常看见的也就是以上的树干、树枝、树叶。
PCI
PCI 采用的是总线型拓扑结构。一条 PCI 总线上挂着若干个 PCI Endpoint 设备或者 PCI Bridge 设备。PCI 总线和这些设备,可以抽象为一颗 tree 上挂着各种树干、树枝、树叶。如下所示,是一个基于 PCI 的传统计算机系统,

北桥下面的那根 PCI 总线,挂载了以太网设备、SCSI 设备、南桥以及其他设备,它们共享那条总线,某个设备只有获得总线使用权才能进行数据传输。
PCIe

PCIe 采用树形拓扑结构,如上所示。
上面的拓扑图显示 RC 和 CPU 是两个独立的部分,事实上,我们常用的处理器目前大部分都是把 CPU 和 RC 集成到了一起。
PCIe 体系架构一般包含根组件 RC( Root Complex ),交换器 Switch,终端设备 EP( endpoint )等类型的 PCIe 设备组成。
RC在总线架构中只有一个,用于CPU处理器和内存子系统与I/O设备之间的连接;Switch的功能通常是以软件形式提供的,它包括两个或更多的逻辑PCI-PCI Bridge,以保持与现有PCI兼容,具体功能类似现在的网络交换机。
每个 PCIe 设备在系统总线上都有自己的标识符,这个标识符就是 BDF( Bus,Device,Function ),PCIe 的配置软件(即 Root 的应用层,一般是 host )应当有能力识别整个 PCIe 总线系统的拓扑逻辑,以及其中的每一条总线( Bus ),每一个设备( Device )和每一项功能( Function)。
在 BDF 中,Bus Number 占用 8 位,Device Number 占用 5 位,Function Number 占用 3 位。
显然,PCIe 总线最多支持 256 个子总线,每个子总线最多支持 32 个设备,每个设备最多支持 8 个功能,如下图所示:

需要注意的是,每 Bus 0 总是分配给 RC,且每个设备必须要有功能 0( Fun0 ),其他的7个功能( Fun1~ Fun7 )都是可选的。
可以使用 lspci -t 命令查看当前使用主机的 PCIe 拓扑结构,只不过这颗显示的树是横向的,转了90 度,如下图所示:

这是一颗倒着生长的树。树的根即是
RC(Root Complex),我们叫做根节点或者根联合体。
RC内部的结构和处理机制如同我们看不到的树在地面以下的错综复杂的根。记住这里是根,是一切的开始就好。
从根节点开始向下生长出树干和树枝(PCIe链路),某些树枝还扩展生长出旁路的分支,这些可以扩展生长的地方,对应拓扑中的Switch。
最末端的叶/果实,对应拓扑中的EP(End Point)。
一个 PCIe 设备的 ID 由以下几个部分组成:
以 0000:00:00.0 为例,分别对应 PCI 域,总线号,设备号,功能号。
PCI 域: PCI 域 ID,目的是为了突破 PCIe 256 条总线的限制。
PCI 总线号:PCI 设备的总线 ID,占用 8 位,所以 PCIe 总线最多支持 256 个子总线。
PCI 设备号:指定总线上,PCI 的设备 ID,Device Number 占用 5 位, 所以每个子总线最多支持 32 个设备。
PCI 功能号:指定设备上,PCI 设备的功能 ID, 一个 PCI 物理设备可以实现多个功能设备,且逻辑功能相互独立,Function Number 占用 3 位,所以每个物理设备最多支持 8 个功能。
BDF( Bus,device,function )构成了每个 PCIe 设备节点的身份标识。
Root Complex
Root Complex ( RC ) 是树的根,它为 CPU 代言,与整个计算机系统其他部分通信,比如 CPU 通过它访问内存、通过它访问 PCIe 系统中的 EP 设备。
RC 的内部实现很复杂,PCIe Spec 也没有规定 RC 该做什么、不该做什么。可以简单将它理解为一条内部的 PCIe 总线( Bus 0 ),以及通过若干个 PCI bridge,扩展出一些 PCIe Port,如下所示,

PCIe Endpoint
PCIe Endpoint,就是 PCIe 终端设备,比如 PCIe SSD、PCIe 网卡 等,这些 Endpoint 可以直接连在 RC 上,也可以通过 Switch 连到 PCIe 总线上。
Switch
Switch 用于扩展链路,提供更多的端口用以连接 Endpoint。拿 USB 打比方,计算机主板上提供的 USB 口有限,如果你要连接很多 USB 设备,比如无线网卡、无线鼠标、USB 摄像头、USB 打印机、U 盘等,USB 口不够用,我会上网买个 USB HUB 用以扩展接口。同理,如果 PCIe Port 不够,可以以 Switch 作为 PCIe Port Hub,拓展更多的接口用以连接多个 PCIe Endpoint 设备。
Switch 扩展了 PCIe 端口,靠近 RC 的那个端口,我们称为上游端口( Upstream Port ),而分出来的其他端口,我们称为下游端口( Downstream Port )。一个 Switch 只有一个上游端口,可以扩展出若干个下游端口。下游端口可以直接连接 Endpoint,也可以连接 Switch,扩展出更多的 PCIe 端口,如下所示,


对每个 Switch 来说,它下面的 Endpoint 或者 Switch,都是归它管的。上游下来的数据,它需要甄别数据是传给它下面哪个设备的,然后进行转发;下面设备向 RC 传数据,也要通过Switch 代为转发。因此,Switch 的作用就是扩展 PCIe 端口,并为挂在它上面的设备( Endpoint 或者 Switch ) 提供路由和转发服务。
每个 Switch 内部,也是有一根内部 PCIe 总线的,然后通过若干个 Bridge,扩展出若干个下游端口,如图所示,

总结
PCIe 采用的是树形拓扑结构。
RC是树的根或主干,它为CPU代言,与PCIe系统其他部分通信,一般为通信的发起者。Switch是树枝,树枝上有叶子(Endpoint),也可节外生枝,Switch上连Switch,归根结底,是为了连接更多的Endpoint。Switch为它下面的Endpoint或Switch提供路由转发服务。Endpoint是树叶,诸如SSD、网卡、显卡等,实现某些特定功能(Function)。我们还看到有所谓的Bridge,用以将PCIe总线转换成PCI总线,或者反过来,不是我们要讲的重点,忽略之。PCIe与采用总线共享式通信方式的PCI不同,PCIe采用点到点(Endpoint to Endpoint)的通信方式,每个设备独享通道带宽,速度和效率都比PCI好。
但是,虽然PCIe采用点到点通信,即理论上任何两个Endpoint都可以直接通信,但实际中很少这样做,因为两个不同设备的数据格式不一样,除非这两个设备是同一个厂商的。通常都是Endpoint与RC通信,或者Endpoint通过RC与另外一个Endpoint通信。
问题
做底层驱动开发特别是 PCIe 驱动相关的开发,经常看到的一个错误就是 “树乱了”。
树乱了从表面上看,即是 lspci -t 的内容发生了错乱,跟正常情况下的树不一样了。
本质上,“树乱了” 由于系统中的某些 PCIe 设备出错或者异常导致的。
lspci -t 时,系统会重新访问这颗树上的所有设备,由于部分 PCIe 设备的异常,访问失败(返回异常值或者全 F),从而影响 pciutils 构建出一颗完整的树,出现部分树枝断裂 (链路 link down ),树叶错位( EP Bar 空间异常)等现象。
分层结构
PCIe 分层结构绝大多数的总线或者接口,都是采用分层实现的。PCIe 也不例外,它的层次结构如图所示,


PCIe 定义了下三层:
- 事务层(
Transaction Layer) - 数据链路层(
Data Link Layer) - 物理层(
Physical Layer,包括逻辑子模块和电气子模块)
每层职能是不同的,但下层总是为上层服务的。
分层设计的一个好处是,如果层次分得够好,接口版本升级时,硬件设计可能只需要改动某一层,其他层可以保持不动。( 分层易于硬件和软件的维护和更改 )
数据传输
PCIe Endpoint 设备

PCIe 传输的数据从上到下,都是以数据包( Packet )的形式传输的,每层数据包都是有其固定的格式。
- 事务层的主要职责是创建(发送)或者解析(接收)
TLP(Transaction Layer Packet)、流量控制、QoS、事务排序等。(TLP创建(发送)或者解析(接收)) - 数据链路层的主要职责是创建(发送)或者解析(接收)
DLLP(Data Link Layer Packet)、Ack / Nak协议(链路层检错和纠错)、流控、电源管理等。 - 物理层的主要职责是处理所有的
Packet数据物理传输,发送端数据分发到各个Lane传输(Stripe),接收端把各个Lane上的数据汇总起来(De-stripe),每个Lane上加扰(Scramble,目的是让0和1分布均匀,去除信道的电磁干扰EMI)和去扰(De-scramble),以及8/10或者128/130编码解码等。
数据打包发送
数据从上到下,一层层打包,上层打包完的数据,作为下层的原始数据,再打包。就像人穿衣服一样,穿了内衣穿衬衫,穿了衬衫穿外套。

Data 是事务层上层(诸如命令层、NVMe 层)给的数据,
- 事务层给它头上加个
Header,然后尾巴上再加个CRC校验,就构成了一个TLP。 - 这个
TLP下传到数据链路层,又被数据链路层在头上加了个包序列号(Sequence Number,SN),尾巴上再加个CRC校验,然后下传到物理层。 - 物理层为其头上加个
Start,尾巴上加个End符号,把这些数据分派到各个Lane上,然后在每个Lane上加扰码,经8 / 10或128 / 130编码,最后通过物理传输介质传输给接收方,如上图所示。
数据剥离接收

- 接收方物理层是最先接收到这些数据的,掐头(
Start)去尾(End),然后交由上层。 - 在数据链路层,校验序列号和
LCRC,如果没问题,剥掉序列号和LCRC,往事务层走;如果校验出差,通知对方重传。 - 在事务层,校验
ECRC,有错,数据抛弃;没错,去掉ECRC,获得数据。
整个过程犹如脱衣睡觉,外套脱了,衬衫脱了,内衣也脱了,光溜溜钻进被窝,如上图所示。
和 PCI 数据裸奔不同,PCIe 的数据是穿衣服的。PCIe 数据以 Packet 的形式传输,比起 PCI 冷冰冰的数据,PCIe 的数据是鲜活有生命的。
Switch

每个 Endpoint 都需要实现这三层,每个 Switch 的 Port 也需要实现这三层。
虽说 Switch 的主要功能是转发数据,但也还需要实现事务层。因为数据的目的地信息是在 TLP 中的,如果不实现这一层,就无法知道目的地址,也就无法实现数据寻址路由。
Root Complex & Switch
如果 RC 要与 EP1 通信,中间要经历怎样的一个过程?
如果把前述的数据发送和接收过程叫作穿衣和脱衣,那么,RC 与 EP1 数据传输过程中,则存在好几次这样穿衣脱衣的过程:
RC帮数据穿好衣服,发送给Switch的上游端口;A为了知道该笔数据发送给谁,就需要脱掉该数据的衣服,找到里面的地址信息。衣服脱光后,Switch发现它是往EP1的,又帮它换了身新衣服,发送给端口B;B又不嫌麻烦的脱掉它的衣服,换上新衣服,最后发送给EP1
总结一下,即 RC --> 上游端口 A --> 下游端口 B --> EP1
如下图所示:

Switch 的主要功能是转发数据,为什么还需要实现事务层?
因为 Switch 必须实现这三层,因为数据的目的地信息是在 TLP 中的,如果不实现这一层,就无法知道目的地址,也就无法实现数据寻址路由。
PCIe TLP
主机与 PCIe 设备之间,或者 PCIe 设备与设备之间,数据传输都是以 Packet 形式进行的。事务层根据上层(软件层或者应用层)请求( Request )的类型、目的地址和其他相关属性,把这些请求打包,产生 TLP( Transaction Layer Packet,事务层数据包)。然后这些 TLP 往下,经历数据链路层、物理层,最终到达目标设备。
TLP 类型
根据软件层的不同请求,事务层产生四种不同的 TLP 请求:
| 请求类型 | 请求用途 | 应用场景 |
|---|---|---|
Memory | 访问内存空间 | 一个设备的物理空间可以通过内存映射( Memory Map )的方式映射到主机内存,有些还可以映射到主机的 IO 空间(如果主机有)。但新的 PCIe 设备只支持内存映射。PCIe 线上主流传输的是 Memory 访问相关的 TLP,主机与设备或者设备与设备之间,数据都是在彼此的 Memory 之间(抛掉IO) 交互,因此,这种 TLP 是我们最常见的。 |
IO | 访问 IO 空间 | |
Configuration | 访问配置空间 | 所有配置空间( Configuration )的访问,都是主机发起的,确切地说是 RC 发起的,往往只在上电枚举和配置阶段会发起配置空间的访问。这样的 TLP 很重要,但不是常态。 |
Message | 中断信息、错误信息等 | 只有在有中断或者有错误等情况下,才会有 Message TLP,这不是常态。 |
前3种( Memory、IO、Configuration ) 在 PCI 或者 PCI-X 时代就有了,最后的 Message 请求是 PCIe 新加的。
在 PCI 或者 PCI-X 时代,像中断、错误以及电源管理相关信息,都是通过边带信号( Sideband Signal ) 进行传输的, 但 PCIe 干掉了这些边带信号线,所有的通信都是走带内信号,即通过 Packet 传输,因此,过去一些由边带信号传输的输入,比如 中断信息、错误信息等,就交由 Message 来进行传输了。
Non-posted / Posted
上面提到的 TLP 类型中,
- 需要对方响应的,我们称之为
Non-Posted TLP; - 不指望对方给响应的,我们称之为
Posted TLP,因为对方能否收到都是个问题。
只有 Memory Write 和 Message 两种 TLP 是 Posted 的就可以了,其他都是 Non-Posted 的。

Configuration和IO访问,无论读写,都是Non-Posted的,这样的请求必须得到设备的响应;在
Configuration一栏,我们看到Type 0和Type 1。在之前的拓扑结构中,我们看到除了Endpoint之外,还有Switch,他们都是PCIe设备,但Configuration配置格式不同,因此用Type 0和Type 1区分。
Memory Read必须是Non-Posted的,我读你数据,你不返回数据(返回数据也是响应),那肯定不行,所以Memory Read必须得到响应;
Message TLP是Posted的,不需要响应;
Memory Write是Posted的,我数据传给你,无须回复。写操作失败丢数据的风险较小,数据链路层提供了ACK/NAK机制,一定程度上能保证TLP正确交互,因此能很大程度上减小了数据写失败的可能。
对 Non-Posted 的 Request ,是一定需要对方响应的,对方需要通过返回一个 Completion TLP 来作为响应。
- 对
Read Request来说,响应者通过Completion TLP返回请求者所需的数据,这种Completion TLP包含有效数据; - 对
Write Request( 现在只有Configuration Write了 )来说,响应者通过Completion TLP告诉请求者执行状态,这样的Completion TLP不含有效数据。

示例
Memory Read

PCIe 设备 C 想读主机内存的数据,因此,它在事务层上生成一个 Memory Read TLP,该 MRd 一路向上,到达 RC 。RC 收到该 Request,就到内存中取 PCIe 设备 C 所需的数据,RC 通过 Completion with Data TLP(CplD) 返回数据,原路返回,直到 PCIe 设备 C 。
一个 TLP 最多只能携带 4KB 有效数据,因此,上例中,如果 PCIe 设备 C 需要读 16KB 的数据,则 RC 必须返回 4 个 CplD 给 PCIe 设备 C。注意,PCIe 设备 C 只需发 1 个 MRd 就可以了。
Memory Write

主机想往 PCIe 设备 B 中写入数据,因此 RC 在其事务层生成了一个 Memory Write TLP(要写的数据在该 TLP 中),通过 Switch 直到目的地。前面说过 Memory Write TLP 是 Posted 的,因此,PCIe 设备 B 收到数据后,不需要返回 Completion TLP(如果这时返回 Completion TLP,反而是画蛇添足)。同样的,由于一个 TLP 只能携带 4KB 数据,因此主机想往 PCIe 设备 B 上写入 16KB 数据,RC 必须发送 4 个 MWr TLP。
TLP 结构
无论是 Request TLP 或者是作为回应的 Completion TLP,他们基本都是同一个结构,如下图所示:

TLP 主要由3部分组成:Header、Data (可选,取决于具体 TLP类型) 和 ECRC (可选)。
TLP 始于发送端的 Trasaction Layer 事务层,终于接收端的 Trasaction Layer 事务层。
- 每个
TLP都有一个Header,跟动物一样,没有头就活不了,所以TLP可以没手没脚,但不能没有Header。事务层根据上层请求内容,生成TLP Header。Header内容包括发送者的相关信息、目标地址(该TLP要发给谁)、TLP类型(如Memory read,Memory Write之类的)、数据长度(如果有的话)等等。 Data Payload域,用以放有效载荷数据。该域不是必须的,因为并不是每个TLP都必须携带数据的,比如Memory Read TLP,它只是一个请求,数据是由目标设备通过Completion TLP返回的。ECRC(End to End CRC)域,它对之前的Header和Data(如果有的话)生成一个CRC,在接收端然后根据收到的TLP,重新生成Header和Data(如果有的话)的CRC,和收到的CRC比较,一样则说明数据在传输过程中没有出错,否则就有错。
它也是可选的,可以设置不加CRC。
一个
TLP最大载重是4KB,数据长度大于4KB的话,就需要分几个TLP传输。
Header
TLP Header 存在通用部分,也存在视具体 TLP 而定的 TLP Header 的部分。
Memory TLP
对一个 PCIe 设备来说,开放给主机访问的设备空间首先会被映射到主机的内存空间。
不同的
PCIe Endpoint设备空间会映射到主机内存空间的不同位置。
- 目标
如果主机想要访问设备的某个空间,TLP Header中的地址应当设置为其在主机内存空间的映射地址。
该TLP经过Switch时,Switch会根据地址信息将其转发到目标设备。 - 源
Memory TLP的源是通过Request ID告知的。每个设备在PCIe系统中都有唯一的ID,该ID由总线Bus、设备Device、功能Function三者唯一确定。只需要知道一个PCIe组成有唯一的一个ID,不管是RC、Switch或者Endpoint。
Configuration TLP
配置可以认为是一个 Endpoint 或者 Switch 的标准空间,不准哪家vendor生产都需要有这段空间且按协议放相应的内容,这段空间在初始化时需要映射到主机的内存空间。
主机软件通过 RC 按协议借助 Configuration TLP 同 Switch 或 Endpoint 交互。
Configuration TLP 中的
Type:Endpoint和Switch的Configuration格式不太一样,分别由Type 0和Type 1来表示;Bus Number + Device + Function就唯一决定了目标设备;Ext Reg Number + Register Number相当于配置空间的偏移。找到了目标设备,指定了配置空间的偏移,就能找到具体想访问的配置空间的某个位置(寄存器)。
Message TLP
Message TLP 用于传输中断、错误、电源管理等信息,取代 PCI 时代的边带信号传输。
Message Code 指定该 Message 的类型。
Completion TLP
对于 TLP 种类为 Non-Posted 的 Request TLP 才有 Completion TLP。
Completion TLP 照搬 Request TLP 中的 Requester ID(发起者) 和 Tag(接收者) 的源地址。
Completion TLP 一方面可返回请求者(比如 Memory Read TLP)的数据,另一方面还可返回该事务的状态。
TLP 路由
参考这里 14
PCIe 共有 3 种路由方式:基于地址( Address )路由,基于设备 ID( Bus number + Device number + Function Number )路由,还有就是隐式( Implicit )路由。
不同类型的 TLP,其寻址方式也不同,下表总结了每种 TLP 对应的路由方式:
TLP 类型 | 路由方式 |
|---|---|
Memory Read/Write TLP | 地址路由 |
Configuration Read/Write TLP | ID 路由 |
Completion TLP | ID 路由 |
Message TLP | 地址路由或者ID路由或者隐式路由 |
下面分别讲讲这几种路由方式。
地址路由
前面提到,Switch 负责路由和 TLP 的转发,而路由信息是存储在 Switch 的 Configuration 空间的,因此,很有必要先理解 Switch 的 Configuration。

BAR0 和 BAR1 没有什么好说,跟前一节讲的 Endpoint 的 BAR 意义一样,存放 Switch 内部空间在 Host 内存空间映射基址。
Switch 有一个上游端口( 靠近 RC )和若干个下游端口,每个端口其实是一个 Bridge,都是有一个 Configuration 的,每个 Configuration 描述了其下面连接设备空间映射的范围,分别由Memory Base 和 Memory Limit 来表示。
对上游端口,其 Configuration 描述的地址范围是它下游所有设备的映射空间范围。
对每个下游端口的 Configuration,描述了连接它端口设备的映射空间范围。
以下面这张图为例,Range 由 Memory Base 和 Memory Limit 限定,


Memory Read或者Memory Write TLP的Header里面都有一个地址信息,该地址是PCIe设备内部空间在内存中的映射地址。
Endpoint

当一个 Endpoint 收到一个 Memory Read 或者 Memory Write TLP,它会把 TLP Header 中的地址跟它 Configuration 当中的所有 BAR 寄存器比较,
- 如果
TLP Header中的地址落在这些BAR的地址空间,那么它就认为该TLP是发给它的,于是接收该TLP; - 否则就忽略。
Switch

Upstream -> Downstream
当一个 Switch 的 upstream 上游端口收到一个 Memory Read 或者 Memory Write TLP,它首先把 TLP Header 中的地址跟它自己 Configuration 当中的所有 BAR 寄存器比较,
- 如果
TLP Header当中的地址落在这些BAR的地址空间,那么它就认为该TLP是发给它的,于是接收该TLP(这个过程与Endpoint的处理方式一样); - 否则,看这个地址是否落在其下游设备的地址范围内( 是否在
memory base和memory limit之间),如果是,说明该TLP是发给它下游设备的,因此它要完成路由转发;
如果地址不落在下游设备的地方范围内,说明该TLP不是发给它下面设备的,因此不接受该TLP。
Downstream -> Upstream
它首先把 TLP Header 中的地址跟它自己 Configuration 当中的所有 BAR 寄存器比较,
- 如果
TLP Header当中的地址落在这些BAR的地址空间,那么它就认为该TLP是发给它的,于是接收该TLP(跟前面描述一样); - 否则,看这个地址是否落在其下游设备的地址范围内(是否在
memory base和memory limit之间),如果是,这个时候不是接受,而是拒绝;相反,如果地址不落在下游设备的地方范围内,Switch则把该TLP传上去。
ID 路由
在一个 PCIe 拓扑结构中,由 ID = Bus number+Device number+Function Number( BDF ) 能唯一找到某个设备的某个功能。这种按设备 ID 号来寻址的方式叫做 ID 路由。
使用 ID 路由的 TLP,其 TLP Header 中含有 BDF 信息:

Endpoint
当一个 Endpoint 收到一个这样的 TLP,它用自己的 ID 和收到 TLP Header 中的 BDF 比较,如果是给自己的,就收下 TLP,否则就拒绝。
Switch
如果是一个 Switch 收到这样的一个 TLP,怎么处理?我们再回头去看看 Switch 的Configuration Header。

看三个寄存器:Subordinate Bus Number,Secondary Bus Number 和 Primary Bus Number,看下图就知道这几个寄存器是什么意思:

对一个 Switch 来说,
- 每个
Port靠近RC( 上游 )的那根Bus叫做Primary Bus,其Number写在其Configuration Header中的Primary Bus Number寄存器;
对上游端口,Subordinate Bus是其下游所有端口连接的Bus编号最大的那个Bus,Subordinate Bus Number写在每个Port的Configuration Header中的Subordinate Bus Number寄存器。 - 每个
Port下面的那根Bus叫做Secondary Bus,其Number写在其Configuration Header中的Secondary Bus Number寄存器;

当一个 Switch 收到一个基于 ID 寻址的 TLP,如上所示:
- 检查
TLP中的BDF是否与自己的ID匹配,如匹配,说明该TLP是给自己的,收下; - 否则,则检查该
TLP中的Bus Number是否落在Secondary Bus Number和Subordinate Bus Number之间,如果是,说明该TLP是发给其下游设备的,然后转发到对应的下游端口;
如果其他情况,则拒绝这些TLP。
隐式路由
Message TLP 的 Header 总是 4DW,如下图所示:

Type 字段,低三位,用 rrr 表示的,指明该 Message 的路由方式,具体如下:

只有 Message TLP 才支持隐式路由。在 PCIe 总线中,有些 Message 是与 RC 通信的,RC 是该 TLP 的发送者或者接收者,因此没有必要明明白白的指定地址或者 ID,而是采用 ”你懂的” 的方式进行路由,这种路由方式为隐式路由。
除此之外,Message TLP 还支持地址路由和 ID 路由,但以隐式路由为主。
以下主要讨论 Message 使用隐式路由的情况。
如果是地址路由或者 ID 路由,Message TLP 的路由跟别的 TLP 一样,不赘述。
Endpoint
当一个 Endpoint 收到一个 Message TLP,检查 TLP Header,如果是 RC 的广播 Message(011b) 或者该 Message 终结于它( 100b ),它就接受该 Message。
Switch
当一个 Switch 收到一个 Message TLP,检查 TLP Header,如果是 RC 的广播 Message(011b),则往它每个下游端口复制该 Message 然后转发;如果该 Message 终结于它 (100b),则接受该 TLP;如果下游端口收到发给 RC 的 message,往上游端口转发便是。
PCIe 配置和地址空间
参考这里 8
概念
PCIe 有 3 个相互独立的物理地址空间:设备存储器地址空间、I/O 地址空间和配置空间。
配置空间是 PCIe 所特有的一个按协议分配内容的物理空间。由于 PCIe 支持设备即插即用,所以 PCIe 设备不占用固定的内存地址空间或 I/O 地址空间,而是通过配置空间来实现地址映射的。
主机软件可以通过读取配置空间获得该设备的一些信息,也可以通过它来配置该设备。
系统加电时,BIOS 检测 PCIe 总线,确定所有连接在 PCIe 总线上的设备以及它们的配置要求,并进行系统配置。
所以,所有的 PCIe 设备必须实现配置空间,从而能够实现参数的自动配置,实现真正的即插即用。
PCI
PCI 或 PCI-X 时代就有配置空间的概念。那时的配置空间结构如下,

PCI 总线规范定义的配置空间总长度为 256 个字节,配置信息按一定的顺序和大小依次存放。
前 64 个字节的配置空间称为配置头,一般有两种,Type0 和 Type1,分别对应 EP 设备和 桥 设备。配置头的主要功能是用来识别设备、定义主机访问 PCI 卡的方式( I/O 访问或者存储器访问,还有中断信息)。
后 192 个字节是 Capability,是设备告诉 Host 它有多牛逼,都会什么绝活。
PCIe
进入 PCIe 时代,PCIe 能耐更大,192 Bytes 不足以罗列它的绝活。为了保持后向兼容,又要不把绝活落下,于是扩展后者的空间,整个配置空间由 256 Bytes 扩展成 4KB,前面 256 Bytes 保持不变:

配置空间结构
PCIe Header (0 ~ 64 bytes)

- 像
Device ID,Vendor ID,Class Code和Revision ID,是只读寄存器,PCIe设备通过这些寄存器告诉Host软件,这是哪个厂家的设备、设备ID是多少、以及是什么类型的设备。 - 对
Endpoint Configuration(Type 0),提供了最多6个BAR(Base Address Register),而对Switch(Type 1)来说,只有2个。
BAR是干什么用的?
每个PCIe设备,都有自己的内部空间,这部分空间如果开放给Host( 软件或者CPU) 访问,那么Host怎样才能往这部分空间写入数据,或者读数据呢?
CPU只能直接访问Host内存(Memory)空间( 或者IO空间,我们不考虑 ),不对PCIe等外设直接操作。
CPU如果想访问某个PCIe设备的配置空间,它不能亲自跟PCIe外设打交道,因此先叫RC通过TLP把数据从PCIe外设读到Host内存,然后CPU从Host内存读数据;如果要往PCIe设备写数据,则先把数据在内存中准备好,然后叫RC通过TLP写入到PCIe设备。

上图例子中,最左边虚线的表示 CPU 要读 Endpoint A 的数据,RC 则通过 TLP(经历Switch )数据交互获得数据,并把它写入到系统内存中,然后 CPU 从内存中读取数据(紫色箭头所示),从而 CPU 间接完成对 PCIe 设备数据的读取。
具体实现就是上电的时候,系统把 PCIe 设备开放的空间映射到内存空间,CPU 要访问该 PCIe 设备空间,只需访问对应的内存空间。RC 检查该内存地址,如果发现该内存空间地址是某个 PCIe 设备空间的映射,就会触发其产生 TLP,去访问对应的 PCIe 设备,读取或者写入PCIe 设备。
一个 PCIe 设备,可能有若干个内部空间(属性可能不一样,比如有些可预读,有些不可预读)需要映射到内存空间,设备出厂时,这些空间的大小和属性都写在 Configuration BAR 寄存器里面,然后上电后,系统软件读取这些 BAR,分别为其分配对应的系统内存空间,并把相应的内存基地址写回到 BAR。( BAR 的地址其实是 PCI 总线域的地址,CPU 访问的是存储器域的地址,CPU 访问 PCIe 设备时,需要把总线域地址转换成存储器域的地址。)

如上图例子,一个 Native PCIe Endpoint,只支持 Memory Map,它有两个不同属性的内部空间要开放给系统软件,因此,它可以分别映射到系统内存空间的两个地方。
还有一个 Legacy Endpoint,它既支持 Memory Map,还支持 IO Map,它也有两个不同属性的内部空间,分别映射到系统内存空间和 IO 空间。
来个例子,看一下一个 PCIe 设备,系统软件是如何为其分配映射空间的,

上电时,系统软件首先会读取 PCIe 设备的 BAR0,得到数据:

然后系统软件往该 BAR0 写入全 1,得到:

BAR 寄存器有些 bit 是只读的,是 PCIe 设备在出厂前就固定好的 bit,写全 1 进去,如果值保持不变,就说明这些 bit 是厂家固化好的,这些固化好的 bit 提供了这块内部空间的一些信息:
低 12 没变,表明该设备空间大小是 4KB( 2 的 12 次方),然后低 4 位表明了该存储空间的一些属性( IO 映射还是内存映射,32 bit 地址还是 64 bit 地址,能否预取?做过单片机的人可能知道,有些寄存器只要一读,数据就会清掉,因此,对这样的空间,是不能预读的,因为预读会改变原来的值),这些都是 PCIe 设备在出厂前都设置好的提供给系统软件的信息。

然后系统软件根据这些信息,在系统内存空间找到这样一块地方来映射这 4KB 的空间,把分配的基地址写入到 BAR0,如上所示,从而最终完成了该 PCIe 空间的映射。
一个 PCIe 设备可能有若干个内部空间需要开放出来,系统软件依次读取 BAR1,BAR2 … 直到 BAR5,完成所有内部空间的映射。
上面主要讲了 Endpoint 的 BAR。
PCIe Capability (64 ~ 256bytes)
这段空间主要存放一些与 MSI / MSI-X 中断机制和电源管理相关的 capbility。
在内核 include/uapi/linux/pci_regs.h 归纳了 Capability ID 和各个 Capability 名称的对应关系:
/* Capability lists */
#define PCI_CAP_LIST_ID 0 /* Capability ID */
#define PCI_CAP_ID_PM 0x01 /* Power Management */
#define PCI_CAP_ID_AGP 0x02 /* Accelerated Graphics Port */
#define PCI_CAP_ID_VPD 0x03 /* Vital Product Data */
#define PCI_CAP_ID_SLOTID 0x04 /* Slot Identification */
#define PCI_CAP_ID_MSI 0x05 /* Message Signalled Interrupts */
#define PCI_CAP_ID_CHSWP 0x06 /* CompactPCI HotSwap */
#define PCI_CAP_ID_PCIX 0x07 /* PCI-X */
#define PCI_CAP_ID_HT 0x08 /* HyperTransport */
#define PCI_CAP_ID_VNDR 0x09 /* Vendor specific */
#define PCI_CAP_ID_DBG 0x0A /* Debug port */
#define PCI_CAP_ID_CCRC 0x0B /* CompactPCI Central Resource Control */
#define PCI_CAP_ID_SHPC 0x0C /* PCI Standard Hot-Plug Controller */
#define PCI_CAP_ID_SSVID 0x0D /* Bridge subsystem vendor/device ID */
#define PCI_CAP_ID_AGP3 0x0E /* AGP Target PCI-PCI bridge */
#define PCI_CAP_ID_EXP 0x10 /* PCI Express */
#define PCI_CAP_ID_MSIX 0x11 /* MSI-X */
#define PCI_CAP_ID_AF 0x13 /* PCI Advanced Features */
#define PCI_CAP_LIST_NEXT 1 /*Next capability in the list */
#define PCI_CAP_FLAGS 2 /* Capability defined flags (16 bits) */
#define PCI_CAP_SIZEOF 4
PCIe 扩展配置空间 (256 ~ 4K bytes)
这段空间主要存放 PCIe 独有的一些 Capbility 结构,如 AER,SR-IOV 等。
PCIe 扩展能力定义如下:
/* Extended Capabilities (PCI-X 2.0 and Express) */
#define PCI_EXT_CAP_ID(header) (header & 0x0000ffff)
#define PCI_EXT_CAP_VER(header) ((header >> 16) & 0xf)
#define PCI_EXT_CAP_NEXT(header) ((header >> 20) & 0xffc)
#define PCI_EXT_CAP_ID_ERR 0x01 /* Advanced Error Reporting */
#define PCI_EXT_CAP_ID_VC 0x02 /* Virtual Channel Capability */
#define PCI_EXT_CAP_ID_DSN 0x03 /* Device Serial Number */
#define PCI_EXT_CAP_ID_PWR 0x04 /* Power Budgeting */
#define PCI_EXT_CAP_ID_RCLD 0x05 /* Root Complex Link Declaration */
#define PCI_EXT_CAP_ID_RCILC 0x06 /* Root Complex Internal Link Control */
#define PCI_EXT_CAP_ID_RCEC 0x07 /* Root Complex Event Collector */
#define PCI_EXT_CAP_ID_MFVC 0x08 /* Multi-Function VC Capability */
#define PCI_EXT_CAP_ID_VC9 0x09 /* same as _VC */
#define PCI_EXT_CAP_ID_RCRB 0x0A /* Root Complex RB? */
#define PCI_EXT_CAP_ID_VNDR 0x0B /* Vendor-Specific */
#define PCI_EXT_CAP_ID_CAC 0x0C /* Config Access - obsolete */
#define PCI_EXT_CAP_ID_ACS 0x0D /* Access Control Services */
#define PCI_EXT_CAP_ID_ARI 0x0E /* Alternate Routing ID */
#define PCI_EXT_CAP_ID_ATS 0x0F /* Address Translation Services */
#define PCI_EXT_CAP_ID_SRIOV 0x10 /* Single Root I/O Virtualization */
#define PCI_EXT_CAP_ID_MRIOV 0x11 /* Multi Root I/O Virtualization */
#define PCI_EXT_CAP_ID_MCAST 0x12 /* Multicast */
#define PCI_EXT_CAP_ID_PRI 0x13 /* Page Request Interface */
#define PCI_EXT_CAP_ID_AMD_XXX 0x14 /* Reserved for AMD */
#define PCI_EXT_CAP_ID_REBAR 0x15 /* Resizable BAR */
#define PCI_EXT_CAP_ID_DPA 0x16 /* Dynamic Power Allocation */
#define PCI_EXT_CAP_ID_TPH 0x17 /* TPH Requester */
#define PCI_EXT_CAP_ID_LTR 0x18 /* Latency Tolerance Reporting */
#define PCI_EXT_CAP_ID_SECPCI 0x19 /* Secondary PCIe Capability */
#define PCI_EXT_CAP_ID_PMUX 0x1A /* Protocol Multiplexing */
#define PCI_EXT_CAP_ID_PASID 0x1B /* Process Address Space ID */
#define PCI_EXT_CAP_ID_DPC 0x1D /* Downstream Port Containment */
#define PCI_EXT_CAP_ID_L1SS 0x1E /* L1 PM Substates */
#define PCI_EXT_CAP_ID_PTM 0x1F /* Precision Time Measurement */
#define PCI_EXT_CAP_ID_MAX PCI_EXT_CAP_ID_PTM
#define PCI_EXT_CAP_DSN_SIZEOF 12
#define PCI_EXT_CAP_MCAST_ENDPOINT_SIZEOF 40
配置空间访问
前面说每个 PCIe 设备都有一个配置空间,但其实每个 PCIe 设备至少有 1 个配置空间。
一个PCIe 设备,它可能具有多个功能( function ),比如既能当硬盘,还能当网卡。
每个功能对应一个独立的配置空间。
在一个 PCIe 拓扑结构里,一条总线下面可以挂几个设备,而每个设备可以具有几个功能,如下所示:

因此,在整个 PCIe 系统中,只要知道了 Bus+Device+Function,就能找到对应的 Function。
寻址基本单元是功能( function ),它的 ID 就由 Bus+Device+Function 组成 ( BDF )。
一个PCIe 系统,可以最多有 256 条 Bus,每条 Bus 上可以挂最多 32 个 Device,而每个Device 最多又能实现 8 个 Function,而每个 Function 对应着 4KB 的配置空间。
上电的时候,这些配置空间都是需要映射到 Host 的内存空间,因此,需要占用内存空间是:256*32*8*4KB =256MB。
完成映射后,CPU 发出的地址如果落在范围内,根据对应的 BDF 就可以访问到对应 EP 的配置空间了。Linux 内核中的 MCFG 实现读 / 写分别对应函数 pci_read_config_byte/word/dword 和 pci_write_config_byte/word/dword,
EXPORT_SYMBOL(pci_bus_read_config_byte);
EXPORT_SYMBOL(pci_bus_read_config_word);
EXPORT_SYMBOL(pci_bus_read_config_dword);
EXPORT_SYMBOL(pci_bus_write_config_byte);
EXPORT_SYMBOL(pci_bus_write_config_word);
EXPORT_SYMBOL(pci_bus_write_config_dword);
系统软件是如何读取 Configuration 空间呢?
不能通过 BAR 中的地址,为什么?
别忘了 BAR 是在 Configuration 中的,你首先要读取 Configuration,才能得到 BAR。系统软件想访问哪个 Configuration,只需指定相应 Function 对应的内存空间地址,RC 发现这个地址是Configuration 映射空间,就会产生相应的 Configuration Read TLP 去获得相应 Function 的Configuration。
再回想一下前面介绍的 Configuration Read TLP 的 Header 格式:

Bus Number + Device + Function 就唯一决定了目标设备;
Ext Reg Number + Register Number 相当于配置空间的偏移。
找到了设备,然后指定了配置空间的偏移,就能找到具体想访问的配置空间的某个位置。
强调一下,只有 RC 才能发起 Configuration 的访问请求,其他设备是不允许对别的设备进行 Configuration 读写的。
数据链路层
参考这里 15
数据链路层位于事务层的下一层,其作用有:
- 保证
TLP在数据总线上的正常传输,并使用握手协议(Ack / Nak)和重传(Retry)机制来保证数据传输的一致性和完整性。
一个
TLP源于发送端的事务层,途径发送端的数据链路层和物理层、接收端的物理层和数据链路层,终于接收端的事务层。
- 发送端的数据链路层,接收其事务层传来的
TLP,为每个TLP加上Sequence Number(序列号)和LCRC(Link CRC),而后转交物理层。- 接收端的数据链路层,接收其物理层传来的
TLP,检测CRC和序列号。
如果有问题,会拒绝接收该TLP,不会传至其事务层,并通知发送端重传;
如果没问题,去除Sequence Number和LCRC,而后转交事务层,并通知发送端TLP已正确接收。
TLP流量控制。- 电源管理功能。

DLLP( Data Link Layer Packet,数据链路层的数据包 )源于发送端的数据链路层,终于接收端的数据链路层。因此,处于高层的事务层是感知不到它的存在的。
- 发送端的数据链路层生成
DLLP,交由发送端的物理层,发送端的物理层加起始(SDP)和结束标志(GEN 1/2加END,GEN3则没有 ),然后传输给对方; - 接收端的物理层对
DLLP掐头去尾,交由接收端的数据链路层,接收端的数据链路层对DLLP进行校验。不管正确与否,DLLP都终于这层。
一个
TLP可以翻山越岭( 经过若干个Switch),从一个设备传输到相隔很远的设备。
与TLP传输不同,DLLP不需要包含路由信息(由谁发起、发送至哪里),因为DLLP的传输仅限于相邻的两个端口。
数据链路层主要有四大类型 DLLP:
- 确保
TLP传输的一致性和完整性的DLLP:ACK / NAK; - 流控相关的
DLLP; - 电源管理相关的
DLLP; - 厂家自定义
DLLP
不同类型的 DLLP 格式相同,内容不一样。
ACK / NAK 协议

- 发送端的数据链路层为将要发送的
TLP加上Sequence Number和LCRC,在TLP被接收端正确收到之前,它会一直保持在一个Replay Buffer中。 - 接收端的数据链路层收到
TLP后做CRC校验和Sequence Number检查:
- 如果没有问题,
TLP接收端会生成和发送ACKDLLP,TLP发送端接收到ACK后知道TLP被正确接收,而后从Replay Buffer中清除。TLP接收端会去掉Sequence Number和LCRC并把TLP交由接收端事务层。 - 如果检测到问题,
TLP接收端会生成和发送NAKDLLP,TLP发送端收到NAK后知道TLP出错,会重新发送Replay Buffer中的TLP给到对方。
TLP 传输出错往往是瞬态的,重传基本能保证 TLP 传输正确。
TLP 流控(流量控制,Flow Control)
Flow Control 即流量控制,这一概念起源于网络通信中。
PCIe 总线采用 Flow Control 的目的是,保证发送端的 PCIe 设备永远不会发送接收端的 PCIe 设备不能接收的 TLP(事务层包),换句话说,发送端在发送前可以通过 Flow Control 机制知道接收端能否接收即将发送的 TLP。
PCI 总线中,并没有 Flow Control 这样的机制,因此发送端并不知道当前时刻接收端能否接收对应的 TLP。因此,发送端只能先尝试发送直至对方接收,期间可能会被插入多个等待周期(接收设备尚未就绪等原因),甚至是重发( Retries )等。这会在一定程度上影响通信效率。
PCIe Spec 规定,PCIe 设备的每一个端口( Ports )都必须支持 Flow Control 机制,在发送TLP 之前,Flow Control 必须先检查接收端口是否有足够的 Buffer 空间来接收这个 TLP。当PCIe 设备支持多个 VC( Virtual Channel )时,Flow Control 机制可以显著地提高总线的传输效率。
PCIe Spec 规定,每个 PCIe 端口最多支持 8 个 VC,并且每个 VC 的 Flow Control Buffer 是完全独立的。也就是说,某一个 VC 的 Flow Control Buffer 满了,并不会影响其他的 VC 的通信。
Flow Control 机制是通过相邻两个端口( Ports )的数据链路层之间发送 DLLP( Flow Control DLLPs )来实现的。也就是说 Flow Control 是一种点到点( Point to Point )的方式,而非端到端( End to End )。在进行初始化的时候,接收端需要向发送端报告(reports)其 Buffer 的大小,在正常运行状态(Run-time)时,会周期性地通过 Flow Control DLLPs 来告知发送端,接收端的各个 Buffer 的大小。
需要注意的是,虽然 Flow Control DLLP 只在相邻的数据链路层之间传输,但是相关的 Buffer 和计数器( FC Counter )确是在事务层( Transaction Layer )的,即事务层参与了 Flow Control机制的管理。如下图所示:

电源管理
暂时略过。
物理层
参考这里 16

先回顾一下 PCIe 的 Layer 的分层结构,如上所示。
PCIe 的三层,从上到下,依次为事务层、数据链路层和物理层。每层都有自己的数据包定义:
- 事务层产生
TLP,用以传输应用层或命令层(事务层的上层)的数据,经过数据链路层和物理层传输给接收方; - 数据链路层产生
DLLP,用以ACK / NAK、流控制和电源管理,经过物理层传输到对方; - 物理层,不仅仅为上层
TLP和DLLP做嫁衣,也有自己的用于管理链路的数据包Ordered Sets(OS),比如链路训练(Link Training)、改变链路电源状态等。
PCIe 中的物理层主要完成编解码( 8b/10b for Gen1 & Gen2,128b/130b for Gen3 and later)、扰码与解扰码、串并转换、差分发送与接收、链路训练等功能。
其中链路训练主要通过物理层包 Ordered Sets 来实现。

物理层分为两个部分——逻辑子层和电气子层,如上图所示。
电气子层方面,PCIe 采用串行总线传输数据,使用的是差分信号,即用两根信号线上的电平差表示 0 或 1。与单端信号传输相比,差分信号抗干扰能力强,可以用更快的速度进行数据传输,从而提供更宽的带宽。
假设用2个信号线上电平差表示
0和1,差值大于0,表示1,反之表示0。
如果传输过程中存在干扰,2个信号线上加了近乎同样大小的干扰电平,若二者相减,差之几乎不变,并不会影响信号传输。
假设用单端信号传输,就很容易受感染。比如,0~1 V表示0,1~3 V表示1。一个本来是0.8 V的电压,加入干扰,变成1.5 V,则从0变为1,则数据出错。
PCIe 物理层实现了一对收发差分对,因此可以实现全双工的通信方式。
需要注意的是,PCIe Spec 只是规定了物理层需要实现的功能、性能与参数等,至于如何实现这些却并没有明确的说明。也就是说,厂商可以根据自己的需要和实际情况,来设计 PCIe 的物理层。
逻辑子层
下面将以 Mindshare 书中的例子来简要的介绍 PCIe 的物理层逻辑部分,可能会与其他的厂商的设备的物理层实现方式有所差异,但是设计的目标和最终的功能是基本一致的。
- 发送端
物理层逻辑子层的发送端部分的结构图如下图所示:

在进行 8b/10b 编码之前,Mux 会对来自数据链路层的数据中插入一些内容,如用于标记包边界或者 Ordered Sets 的控制字符和数据字符。为了区分这些字符,Mux 为其对应上一个 D/K# 位( Data or Kontrol )。
注:图中还包含了
Gen3的一些实现,不过这里只介绍Gen1&Gen2,并不会介绍Gen3。如果大家感兴趣的,可以去阅读Mindshare的书籍或者参考PCIeGen3的Spec。
Byte Striping 将来自 Mux 的并行数据按照一定的规则分配到各个 Lane 上去。随后进行扰码( Scrambler )、8b / 10b 编码、串行化( Serializer ),然后是差分发送对。
其中扰码器( Scrambler )是基于伪随机码( Pesudo-Random )的异或逻辑( XOR ),由于是伪随机码,所以只要发送端和接收端采用相同的算法和种子,接收端便可以轻松地恢复出数据。
但是,如果发送端和接收端由于某些原因导致其节拍不一致了,此时便会产生错误,因此 Gen1 和 Gen2 的扰码器( Scrambler )会周期性地被复位。
- 接收端
物理层逻辑子层的接收端部分的结构图如下图所示:

由于 PCIe 采用的是一种 Embeded Clock(借助 8b / 10b )机制,因此接收端在接收到数据流时,首先要从中恢复出时钟信号,这正是通过 CDR 逻辑来实现的。
如上图所示,接收端的逻辑基本上都是与发送端相对应的相反的操作。
PCIe Reset
参考这里 17
PCIe Spec 中跟 Reset 相关的术语有 Cold Reset、Warm Reset、Hot Reset、Conventional Reset、Functional Level Reset、Fundamental Reset、Non-Fundamental Reset。
这些 Reset 之间是从属关系。
种类
总线规定了两个复位方式,如上图所示:
Conventional Reset
Fundamental Reset
Fundamental Reset是基于边带信号PEREST#的,包括Cold和Warm Reset方式,可以用PCIe将设备中绝大多数内部寄存器和内部状态都恢复成初始值。Non-Fundamental Reset。
Hot Reset方式。
Functional Level Reset
其中Functional Level Reset是PCIe Spec V2.0加入的功能,因此一般把另外三种复位统称为传统的复位方式(Conventional Reset)。
参考这里 18
Acold resetis a fundamental reset that takes place after power is applied to a PCIe device. There appears to be no standard way of triggering a cold reset, save for turning the system off and back on again. On my machines, the /sys/bus/pci/slots directory is empty.
Awarm resetis a fundamental reset that is triggered without disconnecting power from the device. There appears to be no standard way of triggering a warm reset.
Ahot resetis a conventional reset that is triggered across a PCI express link. A hot reset is triggered either when a link is forced into electrical idle or by sending TS1 and TS2 ordered sets with the hot reset bit set. Software can initiate a hot reset by setting and then clearing the secondary bus reset bit in the bridge control register in the PCI configuration space of the bridge port upstream of the device.
Afunction-level reset(FLR) is a reset that affects only a single function of a PCI express device. It must not reset the entire PCIe device. Implementing function-level resets is not required by the PCIe specification. A function-level reset is initiated by setting the initiate function-level reset bit in the function’s device control register in the PCI express capability structure in the PCI configuration space.
功能、实现方式及对设备的影响
Fundamental Reset
功能及对设备的影响
Fundamental Reset 由硬件自动处理,会复位整个 PCIe 设备,初始化所有与状态机相关的硬件逻辑,端口状态以及配置空间中的配置寄存器等等。
但是,也有一个例外,就是 Sticky(不受复位影响)的概念。这里指的不受复位影响的前提是,PCIe 设备的电源并未被完全切断。Sticky 这一功能有助于系统定位错误与分析错误起因。
这些
Field在Debug时会非常有用,特别是那些需要Reset Link的情况,如果在Link Reset后还能保存之前的错误状态,这对FW以及上层应用来说是很有用的。
Fundamental Reset 一般发生在整个系统 Reset 的时候(比如重启电脑),但也可以针对某个设备做 Fundamental Reset。
Fundamental Reset 有两种,
Cold Reset
指的是因为主电源断开后重新连接导致的复位。需要注意的是,即使主电源断开了,如果PCIe设备仍有辅助电源Vaux为其供电,该复位仍不会影响到Sticky的bits。Warm Reset
可选的,指的是在不关闭主电源的情况下,由系统触发产生的复位,比如改变系统的电源管理状态可能会触发,PCIe协议没有定义具体如何触发Warm Reset,而是把决定权都交给系统。
实现方式
PCIe Spec 允许两种实现 Fundamental Reset 的方式:
- 直接通过边带信号
PERST#(PCI Express Reset); - 不使用边带信号
PERST#,PCIe设备在主电源被切断时,自行产生一个复位信号。
PERST#

如果这块 PCIe 设备支持 PERST# 信号:
- 一个系统上电时,主电源稳定后会有
Power Good信号; ICH(IO控制器集线器)发PERST#信号给下方悬挂的PCIe Endpoint设备- 如果系统重启,
Power Good的信号变化会触发PERST#的ASSERT和DEASSERT,就可以实现PCIe设备的Cold Reset; - 如果系统可以提供
Power Good信号以外的方法触发PERST#,就可以实现Warm Reset,PERST#信号会发送给所有的PCIe设备,设备可以选择这个信号,也可以选择不理;
复位信号
如果这块 PCIe 设备不支持 PERST# 信号:
- 一个系统上电后会自动进入
Fundamental Reset; - 必须能自己触发
Fundamental Reset,比如,侦测到3.3 V后就触发Reset(当设备发现供电超过其标准电压时必须触发Reset)。
Non-Fundamental Reset
实现
Hot Reset 是一种 In-band 复位,其并不使用边带信号。
PCIe 设备通过向其链路( Link )相邻的设备发送数个 TS1 Ordered Set(其中第五个字符的bit0 为 1 ),如下图所示。这些 TS1 OS 在所有的通道( Lane )上同时发送,并持续 2 ms 左右。

- 如果
Switch的Upstream端口收到了Warm Reset,则会将其广播至所有的Downstream端口,并复位其自己。 - 如果
PCIe设备的Downstream端口接收到Warm Reset,则只需要复位其自己即可。
当PCIe设备接收到Warm Reset后,LTSSM会进入Recovery and Hot Reset状态,然后返回值Detect状态,并重新开始链路初始化训练。其该PCIe设备的所有状态机,硬件逻辑,端口状态和配置空间中的寄存器(除了Sticky bits)都将被初始化值默认状态。
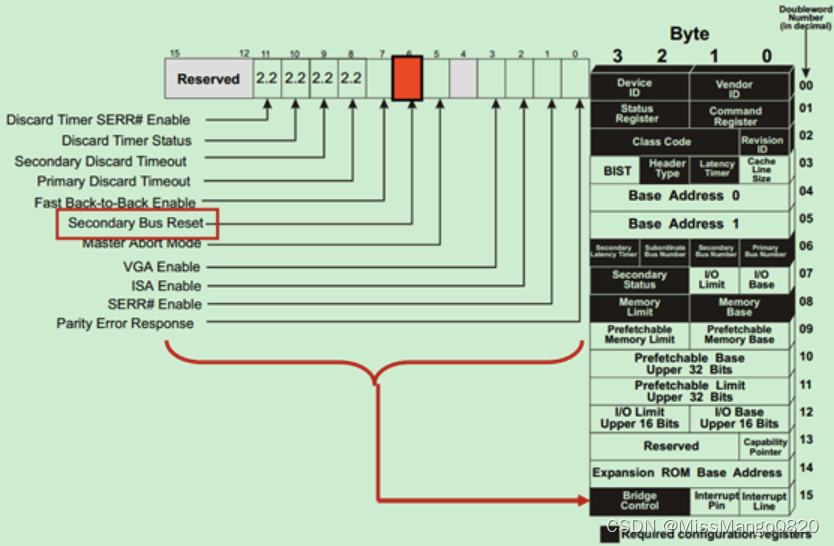
软件可以通过向桥设备的,特定端口的配置空间中的二级总线复位( Secondary Bus Reset )bit先写 0 再写 1,来产生热复位,如下图所示:

需要注意的是,如果软件设置的是 Switch 的 Upstream 端口的二级总线复位 bit,则该 Switch 会往其所有的 Downstream 端口广播 Hot Reset 信号。
而 PCIe-to-PCI 桥则会将接收到的热复位信号转换为 PRST# 置位,发送给 PCI 设备。
二级总线复位( Secondary Bus Reset )bit 在配置空间的位置如下图所示:
PCIe Spec 还允许软件禁止某个链路( Link ),强制使其进入电气空闲状态( Electrical Idle )。如果将某个链路禁止,则该链路所有的下游 PCIe 设备都将收到链路禁止信号(通过TS1 OS,如下图所示),

Functional Level Reset
参考这里 19
PCIe 总线自 V2.0 加入了功能层复位( Function Level Reset,FLR)的功能。该功能主要针对的是支持多个功能的 PCIe 设备( Multi-Fun PCIe Device ),可以实现只对特定的 Function 复位,而其他的 Function 不受影响。
当然,该功能是可选的,并非强制的,软件可以通过查询配置空间中的设备功能寄存器( Device Capability Register )来查询该 PCIe 设备是否支持 FLR。如下图所示:

并可以通过设备控制寄存器( Device Control Register )中的将 Initiate Function Level Reset bit 置1 ,如下所示,来产生 FLR。

功能及对设备的影响
FLR 只复位对应 Function 的内部状态和寄存器(使其暂时不变化,Making it quiescent ),但是不影响以下寄存器:
Sticky bits
Cold Reset和Warm Reset也不可以复位它们。
HWInit类型的寄存器
在
PCIe设备中,有效配置寄存器的属性为HWInit,这些寄存器的值由芯片的配置引脚决定,其在上电复位后从EEPROM中获取。
Cold Reset和Warm Reset缺可以复位这些寄存器,并从EEPROM中重新获取数据。
- 链路专用寄存器,比如
Captured Power,ASPM Control、Max Payload Size以及VC等寄存器)。 LTSSM状态
实现方式
PCIe Spec 明确 FLR 的完成时间应在 100 ms 以内。
-
FLR开始前: - 把
Command Register清空 - 软件在启动
FLR前应注意是否还有没完成的CplD。
如果有,等这些CplD完成( 轮询Device Status Register的bit5直到被clear,说明已无未完成的CplD)再开始FLR,或者,启动FLR后等100 ms再初始化这个Function。
这个情况如果没处理好,可能会导致
Data Corruption—— 前一批事务要求的数据因FLR的影响被误传给了后一批事务。
-
确保其他软件在
FLR期间不会访问这个Function -
FLR进行中: -
该
Function对外无法使用 -
不保留之前的任何可以被读取的信息(比如内部的
Memory需要被清零或者改写 ) -
回复要求
FLR的Cfg Request,并开始FLR -
对于发进来的
TLP回复Unexpected Completion或者直接丢弃 -
FLR应该在100 ms内完成,但其后的初始化还需要一些时间。在初始化过程中如果收到Cfg Request,可以回复Configuration Retry Status。 -
FLR完成后: -
从
FLR退出后,在20 ms内开始Link Training -
软件给
Link充分的时间完成Link Training和初始化,至少要等上100 ms才能开始发送Cfg Request。如果等了100 ms开始发Cfg Request,但设备还没初始化完成,设备会回复Configuration Retry Status。这时RC可以选择重发Cfg Request或者上报CPU说设备还未准备好。 -
设备最多可以有
1 s时间来重新配置Function并Enable,之后必须能正常工作,否则System / RC则可以认为设备挂了。
PCIe Max Payload Size 和 Max Read Request Size
参考这里 20
PCIe Max Payload Size 和 PCIe Max Read Request Size 都在 Device Control Register 里,分别由 bit[14:12] 和 bit[7:5] 控制,如下所示:

PCIe Max Payload Size
概念
PCIe 设备是以 TLP 的形式发送报文的,而 PCIe Max Payload Size ( 简称 MPS ) 决定了 PCIe 设备实际使用的 TLP 能够传输的最大字节数。
MPS 的大小是由 PCIe 链路两端的设备协商决定的。PCIe 协议允许一个最大的 Payload 可达 4 KB,但是规定在整个传输路径上的所有设备都必须使用相同的 MPS 设置,同时不能超过该路径上任何一个设备的 MPS 能力值。即,MPS Capability 高的设备要迁就低的设备。
例如,将一块
PCIeSSD插入到一块老掉牙的主板(MPS128 Byte)上,无论SSD的Payload Size再大,都是没用的。
接收端必须能处理跟 MPS 设定大小相同的 TLP 数据包。
发送端不允许创建超过 MPS 设定的 TLP 数据包。
以主板上的 PCIe RC 和 PCIe SSD 为例,它们各自在 Device Capability Register 中声明自己支持的各种 MPS,OS 的 PCIe 驱动侦测到它们各自的能力值并挑选最低的那个设置到两者的 Device Control Register 中。
PCIe SSD 自身的 MPS Capability 则是在其 PCIe core 初始化阶段设置的,
作用
MPS 的大小影响 PCIe 设备的传输效率。
- 对于比较大的数据量,如果
MPS设置比较小,那么数据只能被分割成多个TLP进行发送,势必会影响PCIe链路带宽的利用率。
MPS的值也不是越大越好,一方面MPS设置的越大,硬件处理数据包所需的内存和逻辑量也随之增加; 另一方面,MPS的值是一个自协商的结果,当前市场上支持较大MPS值的PCIe Endpoint设备不常见,所以没有必要设置本端的MPS值太大。 - 不合理的
MPS设置会导致数据通信时上报Malformed TLP错误。RC设备在与EP设备对接时,对端的EP设备的MPS可能各不相同,需要RC端去适配EP端的mps, 如果EP设备接收的TLP数据长度超过了它的MPS配置,该设备就会认为该TLP非法。
查询
使用 lspci 查询 MPS,比如使用 lspci -s 00:02.0 -vvv | grep DevCtl: -C 2 查询 02:00.0 的设备的 MPS 1

查出来 MPS 的大小为 128 bytes。
设置
设置方法参考这里 20,但有时候设置会不生效,这个也是和硬件支持的能力相关联的。
内核实现
MPS 配置类型
在 linux 内核中,当前有 4 种配置 MPS 的类型,定义在 include/linux/pci.h 21 中,
enum pcie_bus_config_types {
PCIE_BUS_TUNE_OFF, /* Don't touch MPS at all */
PCIE_BUS_SAFE, /* Use largest MPS boot-time devices support */
PCIE_BUS_PERFORMANCE, /* Use MPS and MRRS for best performance */
PCIE_BUS_PEER2PEER, /* Set MPS = 128 for all devices */
};
| 类型 | 说明 |
|---|---|
PCIE_BUS_TUNE_OFF | 不对 PCIe MPS ( Max Payload Size) 进行调整,而是使用 BIOS 配置好的默认值。 |
PCIE_BUS_SAFE | 将每个设备的 MPS 都设为 Root Complex 下所有设备支持的 MPS 中的最大值。 指的是设置最小的那个设备的 MPS 为所有设备的 MPS。 |
PCIE_BUS_PERFORMANCE | 将设备的 MPS 设为其上级总线允许的最大 MPS,同时将 MRRS ( Max Read Request Size ) 设为能支持的最大值 (但不能大于设备或总线所支持的 MPS 值) |
PCIE_BUS_PEER2PEER | 所有的设备的 MPS 都设置为 128 B,以确保支持所有设备之间的点对点DMA,同时也能保证热插入 ( hot-added ) 设备能够正常工作,但代价是可能会造成性能损失。 |
内核在启动的 cmdline 中可以配置 pci_bus_config,如:
pci=pcie_bus_perf
内核配置 MPS
结合代码分析 linux 中 MPS 的配置, 以及看 MPS 是怎么生效的:
void pcie_bus_configure_settings(struct pci_bus *bus)
{
u8 smpss = 0;
if (!bus->self)
return;
if (!pci_is_pcie(bus->self))
return;
/*
* FIXME - Peer to peer DMA is possible, though the endpoint would need
* to be aware of the MPS of the destination. To work around this,
* simply force the MPS of the entire system to the smallest possible.
*/
if (pcie_bus_config == PCIE_BUS_PEER2PEER) ------- (1)
smpss = 0;
if (pcie_bus_config == PCIE_BUS_SAFE) {
smpss = bus->self->pcie_mpss;
pcie_find_smpss(bus->self, &smpss); ------- (2)
pci_walk_bus(bus, pcie_find_smpss, &smpss);
}
pcie_bus_configure_set(bus->self, &smpss); -------- (3)
pci_walk_bus(bus, pcie_bus_configure_set, &smpss);
}
(1) 当 pcie_bus_config 是 PCIE_BUS_PEER2PEER 时,设置 smpss 的值为 0, 最终通过pcie_write_mps(dev, 128 << smpss) 写到配置空间里,所以 peer2peer 的配置下,mps 被固定 128 B。
(2) 当 pcie_bus_config 是 PCIE_BUS_SAFE 时,pcie_find_smpss() 会被调用,该函数的作用是寻找一个最小的 mps,如下所示:
static int pcie_find_smpss(struct pci_dev *dev, void *data)
{
u8 *smpss = data;
if (*smpss > dev->pcie_mpss)
*smpss = dev->pcie_mpss;
return 0;
}
(3) pcie_bus_configure_set 会将 mps 设置写进配置空间, 会对 pci_bus_perf 做特殊处理,在pci_bus_perf 配置下: 会对每一个非根节点取本身和父节点的 mps 的较小值作为自己的 mps。
同时 pci_bus_perf 配置下也会对 pcie_write_mrrs() 进行调用, 将 MRRS 设为各个节点能支持的最大值 ( 但不能大于设备或总线所支持的 MPS 值 )。
结合 Document 和代码分析,最终我们可以得出 MPS 的配置规则如下图所示:
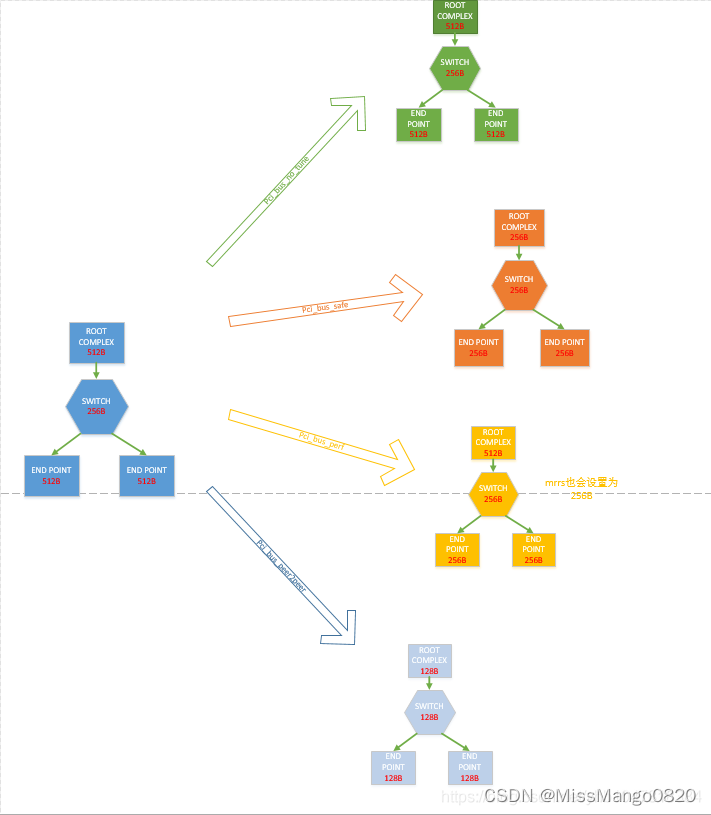
| 类型 | 说明 | 图例颜色 |
|---|---|---|
PCIE_BUS_TUNE_OFF | 不对 PCIe MPS ( Max Payload Size) 进行调整,而是使用 BIOS 配置好的默认值。 | 绿色 |
PCIE_BUS_SAFE | 将每个设备的 MPS 都设为 Root Complex 下所有设备支持的 MPS 中的最大值。 指的是设置最小的那个设备的 MPS 为所有设备的 MPS。 | 橙色,即所有的设备的mps设置为 256 B |
PCIE_BUS_PERFORMANCE | 将设备的 MPS 设为其上级总线允许的最大 MPS,同时将 MRRS ( Max Read Request Size ) 设为能支持的最大值 (但不能大于设备或总线所支持的 MPS 值) | 黄色,除了根节点以外,比较自己设备的 MPS 和父节点的 MPS, 选择较小的那一个设为自己的 MPS,所以除了 RC 的 MPS, 其他节点的 MPS 都设置为 256 B, 此时,还需要更新各个节点 MRRS 的大小,保证 MRRS 的值不大于自身的 MPS 的值。 |
PCIE_BUS_PEER2PEER | 所有的设备的 MPS 都设置为 128 B,以确保支持所有设备之间的点对点DMA,同时也能保证热插入 ( hot-added ) 设备能够正常工作,但代价是可能会造成性能损失。 | 蓝色,保证DMA 的通信,所有设备的 MPS 设为 128 B。 |
PCIe Max Read Request Size
概念
PCIe Max Read Request Size(MRRS)表示每一个读请求所能够读到的最大字节数。
当 PCIe 设备发送 Memory Read 请求 TLP 时,该 TLP 所请求的数据的大小不能超过 MRRS 的值。
作用
MRRS 和 MPS 并没有直接的联系,但是有时候会有间接影响。
举个例子,一个典型的 PCIe 拓扑结构, 中间的红色数字 MPS 的值。假设发起一个 Memory Read TLP 请求操作,

根据上文的分析,这种情况下,RC 和 EP 的通信会失败,因为他们的 MPS 的值不相等。
但是如果设置各个节点的 MRRS 的值为 128 B,那么虽然 RC 设备的 MPS 为 256 B,但是实际能够传输的大小却受到 MRRS 的影响,变成 128 B,这种情况下,实际上传输的 TLP 报文最终是 128 B,可以满足各节点 MPS 一致的条件,可以传输成功。
MRRS 的值不能设置的太小,
- 如果
MRRS设置太小,会影响实际TLP的MPS。 - 如果我们设定
MRRS为128 B,我们读64 KB数据时,就需要发送512( 64KB / 128 B = 512 ) 次读请求,这样的话,就增加了很多额外的开销,对数据传输速率也是一种伤害,所以,为了提高特别是大Block Sizedata的传输效率,尽量把MRRS设的大一点,用更少的次数传递更多的数据。
但是 MRRS 也不能设置过大.
- 在
PCIe链路中,我们不能一直发送TLP,而是需要接受端有足够的接受空间之后,才能继续发送TLP,buffer空间太大的话对于EP的设备而言是比较苛刻的,所以在实际的设计中,也会对MRRS的大小进行限制。
查询
使用 lspci 查询 MRRS,比如使用 lspci -s 00:02.0 -vvv | grep maxReadReq 查询 02:00.0 的设备的 MRRS 1

查出来 MRRS 的大小为 512 B。
PCIe 链路性能损耗
-
Encode和Decode(编解码损耗)
8 / 10 转换,或者128 / 130 转换,即对数据重新编码,以保证链路上实际传输时1和0的总体比例相当,且不要过多连续的1和0,同时把时钟信息嵌入数据流,避免高频时钟信号产生EMI的问题。
对于8 / 10 转换,会带来20%的性能损耗,因为为了传输1个byte数据需 10个bit。
对于128 / 130 转换,这部分的性能损耗可忽略不计。 -
TLPPacketOverhead(数据包的额外开销)
每个Payload在先后经过事务层、数据链路层和物理层时会加上大概20 ~ 30bytes的额外开销,以保证传输的一致性和完整性。 -
Traffic Overhead(为了补偿时钟偏差而做的Skip带来的损耗)
PCIeSpec规定每两个TLP之间加入Skip来做时钟偏差补偿。 -
Link Protocol Overhead(即ACK/NAK带来的开销)
需要通过ACK / NAK的发送来告诉TLP发送端TLP的接收情况。这个ACK / NAK的发送会占用带宽。
ACK / NAK的发送需要一个平衡:
- 允许接收端接收多个
TLP后再发一个ACK给发送端确认,以减少ACK发送的数量; - 不能允许过多
TLP的连续发送才发送ACK进行确认,因为发送端的Replay buffer是有限的,一旦满了则后续的TLP无法再发送。
Flow control(流量控制带来的开销)
UpdateFC的DLLP被用以告知发送端是否可以发TLP,防止接收端receive buffer超额。这个UpdateFC的发送会占用带宽。
UpdateFC的发送需要一个平衡:
- 允许接收端以较低的频率发送
UpdateFC给发送端,以减少对带宽的占用; - 发送
UpdateFC的频率较低意味着对接收端的receive buffer的要求更高。
,
System Parameters(系统数据包通信时为了满足必要的格式带来的损耗)
MPS,MRRS和RCB(Read Completion Boundary)
PCIe 链路训练、枚举扫描、配置BAR
参考这里 22
一般来说,当系统上电后,
-
链路训练
链路训练完成后进入Gen 1模式。但如果双方支持更高的速率,则立即进行Gen 2 / 3 / 4速率的训练。
当链路训练状态机再次进入L0状态,链路训练完成。 -
枚举扫描
host会自动查询PCIe设备枚举以获取总线拓扑结构。PCIe的配置读TLP报文中包含响应设备的bus_number、function_number以及device_number。因此PCIe设备需要知道自己的bus_number是多少。
当总线上存在多种PCIe设备时,主机host会依照深度优先的算法对全部的设备树上的PCIe设备进行枚举查询,统称PCIe设备枚举。
除一些特殊系统外,普通的系统只会在开机阶段进行设备的扫描,启动成功后,即枚举过程结束后,即使插入一个PCIe设备,系统也不会再去识别它。
枚举扫描过程中,CPU会通过配置读TLP读取PCIe配置空间的的verdor id和头标类型寄存器以及其他配置寄存器,此时PCIe返回的读返回TLP报文中complete_id(bus_number、function_number、device_number)为全0,因此此时PCIe还不知道自己的BDF。
CPU完成对PCIe的配置读后,会发起配置写TLP,此时PCIe接受到CPU发来的配第一次置写TLP,会从TLP中解析出bus_number字段存下来。随后的配置读TLP返回中,就会使用bus_number、和function_number和device_number拼接成complete_id。 -
PCIeBAR配置
枚举扫描完成后,会配置基地址寄存器,给PCIe分配地址空间。通过对BA0/1、BAR2/3等基地址寄存器先进行写全32’hffff_ffff,得到信息确认PCIe想申请32bit地址还是64bit地址以及获得的地址空间,从而分配基地址。
完成基地址配置后,就可以通过MemoryTLP读写进行寄存器的访问了。
PCIe 枚举扫描
参考这里 23
当总线上存在多种 PCIe 设备时,主机 host 启动后是怎么找到并认出它们谁是谁的呢?
—— Host 会依照深度优先的算法对全部的设备树上的 PCIe 设备进行枚举查询,统称 PCIe 设备枚举。
其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
一个 PCI Bridge 设备只能新开一条 PCI Bus 总线,PCI Bus 总线上又可以连接 PCI Bridge 设备,继而又新开 PCI Bus 总线。同时,PCI 扫描采用深度优先算法,因此先扫描到的 PCI Bus 总线,就优先编号。
枚举过程中 Host 通过配置读事物包来获取下游设备的信息,通过配置写事物包对下游设备进行设置。
枚举扫描过程
以下面的例子为例对 PCIe 设备枚举过程进行说明:

PCI Host Bridge扫描Bus 0上的设备(在一个处理器系统中,一般将Root Complex中与Host Bridge相连接的PCI总线命名为PCI Bus 0),系统首先会忽略Bus 0上的EP等不会挂接PCI Bridge的设备,Bridge 1和Bridge 2。
主桥发现Bridge 1后,将Bridge1下面的PCI Bus定为Bus 1,系统将初始化Bridge 1的配置空间,并将该桥的Primary Bus Number和Secondary Bus Number寄存器分别设置成0和1,以表明Bridge 1的上游总线是0,下游总线是1,由于还无法确定Bridge 1下挂载设备的具体情况,系统先暂时将Subordinate Bus Number设为0xFF,如上所示。

2. 系统开始扫描 Bus 1,将会发现 Bridge 3,并发现这是一个 Switch 设备。系统将 Bridge 3 下面的 PCI Bus 定为 Bus 2,并将该桥的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 1 和 2,和上一步一样暂时把 Bridge 3 的 Subordinate Bus Number 设为 0xFF,如上所示。

3. 系统继续扫描 Bus 2,将会发现 Bridge 4。继续扫描,系统会发现 Bridge 4 下面挂载的NVMe SSD 设备,系统将 Bridge 4 下面的 PCI Bus 定为 Bus 3,并将该桥的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 2 和 3,因为 Bus 3 下面挂的是端点设备(叶子节点),下面不会再有下游总线了,因此 Bridge 4 的 Subordinate Bus Number 的值可以确定为 3。

4. 完成 Bus 3 的扫描后,系统返回到 Bus 2 继续扫描,会发现 Bridge 5。继续扫描,系统会发现下面挂载的 NIC 设备,系统将 Bridge 5 下面的 PCI Bus 设置为 Bus 4,并将该桥的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 2 和 4,因为 NIC 同样是端点设备,Bridge 5 的 Subordinate Bus Number 的值可以确定为 4。

5. 除了 Bridge 4 和 Bridge 5 以外,Bus 2 下面没有其他设备了,因此返回到 Bridge 3,Bus 4是找到的挂载在这个 Bridge 下的最后一个 Bus 号,因此将 Bridge 3 的 Subordinate Bus Number 设置为 4。Bridge 3 的下游设备都已经扫描完毕,继续向上返回到 Bridge 1,同样将 Bridge 1 的 Subordinate Bus Number 设置为 4。

6. 系统返回到 Bus 0 继续扫描,会发现 Bridge 2,系统将 Bridge 2 下面的 PCI Bus 定为 Bus 5。并将 Bridge 2 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 0 和 5, Graphics card 也是端点设备,因此 Bridge 2 的 Subordinate Bus Number 的值可以确定为 5。
至此,挂在 PCIe 总线上的所有设备都被扫描到,枚举过程结束,Host 通过这一过程获得了一个完整的 PCIe 设备拓扑结构。
系统上电以后,Host 会自动完成上述的设备枚举过程。除一些专有系统外,普通系统只会在开机阶段进行设备的扫描,启动成功后(枚举过程结束),即使插入一个 PCIe 设备,系统也不会再去识别它。
Linux 与 PCIe 设备树
PCIe 的树形拓扑结构为:PCI Bridge(包括 HOST 主桥)下面可以延伸出一条 PCI Bus,PCI 总线上面挂着 PCIe 设备和 PCI Bridge。
我们可以通过 /sys/class/pci_bus/ 目录查看 linux 系统下有多少条 PCI 总线,如下所示:
[root@localhost ~]# ls /sys/class/pci_bus/
0000:00 0000:01 0000:02 0000:03 0000:04 0000:05 0000:06 0000:07 0000:08 0000:09
由上面的输出结果可得知一共有 10 条 pci bus 总线,开头的 0000:00 就是 Host Bridge 下的第一条总线了。
我们也可以通过 /sys/bus/pci/devices/ 目录查看 linux 系统下有多少个 PCIe 设备(以及相应的设备号 BDF),如下所示:
[root@localhost ~]# ls /sys/bus/pci/devices/
0000:00:00.0 0000:00:03.0 0000:00:19.0 0000:00:1c.0 0000:00:1f.0 0000:01:00.0 0000:02:0c.0 0000:04:00.0
0000:00:01.0 0000:00:14.0 0000:00:1a.0 0000:00:1c.1 0000:00:1f.3 0000:02:04.0 0000:02:10.0 0000:09:00.0
0000:00:02.0 0000:00:16.0 0000:00:1b.0 0000:00:1d.0 0000:00:1f.5 0000:02:08.0 0000:02:14.0
通过 lspci -tv 命令,我们可以获得当前 linux 系统下的 PCIe tree,如下所示:
[root@localhost ~]# lspci -tv
-[0000:00]-+-00.0 Intel Corporation 4th Gen Core Processor DRAM Controller
+-01.0-[01-07]----00.0-[02-07]--+-04.0-[03]--
| +-08.0-[04]----00.0 Device 1ded:1020
| +-0c.0-[05]--
| +-10.0-[06]--
| \-14.0-[07]--
+-02.0 Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor Integrated Graphics Controller
+-03.0 Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor HD Audio Controller
+-14.0 Intel Corporation 8 Series/C220 Series Chipset Family USB xHCI
+-16.0 Intel Corporation 8 Series/C220 Series Chipset Family MEI Controller #1
+-19.0 Intel Corporation Ethernet Connection I217-LM
+-1a.0 Intel Corporation 8 Series/C220 Series Chipset Family USB EHCI #2
+-1b.0 Intel Corporation 8 Series/C220 Series Chipset High Definition Audio Controller
+-1c.0-[08]--
+-1c.1-[09]----00.0 Intel Corporation I210 Gigabit Network Connection
+-1d.0 Intel Corporation 8 Series/C220 Series Chipset Family USB EHCI #1
+-1f.0 Intel Corporation C220 Series Chipset Family H81 Express LPC Controller
+-1f.3 Intel Corporation 8 Series/C220 Series Chipset Family SMBus Controller
\-1f.5 Intel Corporation 8 Series/C220 Series Chipset Family 2-port SATA Controller 2 [IDE mode]
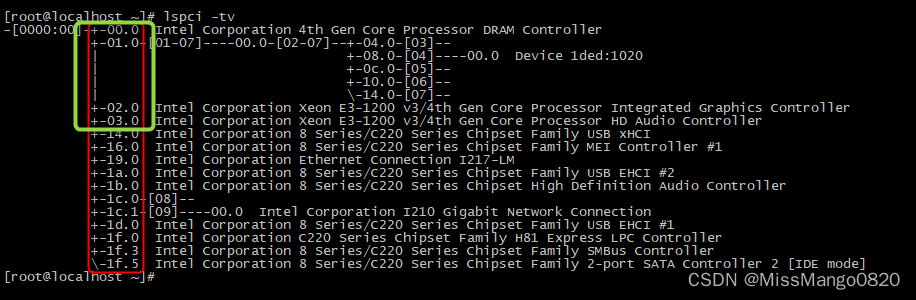
如上图,红色方框中的就是 Host Bridge Bus 0 上的 PCIe 设备,包括 PCIe EP 设备和 PCI Bridge 设备。
绿色方框中的 [00~03].0 ,其中 01.0 之后还有树形结构,所以 01.0 就是 PCI Bridge 设备了。
同时可以知道,PCI Bridge 下面会有新开的 PCI Bus 总线,±01.0-[01-07] 后面的 [01-07] 就是 01.0 PCI Bridge 下面挂接的 PCI Bus 总线了。
而 [00~03].0 中的另外 3 个设备下面没有树形结构,也没有后接 [ ] ,因此就是普通的 PCI 终端设备,即 0000:00:00.0,0000:00:01.0,0000:00:02.0,0000:00:03.0,如下图所示:

为了验证我们的结论,我们通过命令查看 0000:00:00.0,0000:00:01.0,0000:00:02.0,0000:00:03.0 对应的设备信息,如下所示:
[root@localhost platform] lspci -s 0000:00:00.0 -v # 0000:00:00.0 为 DRAM 控制器
00:00.0 Host bridge: Intel Corporation 4th Gen Core Processor DRAM Controller (rev 06)
Subsystem: Intel Corporation 4th Gen Core Processor DRAM Controller
Flags: bus master, fast devsel, latency 0
Capabilities: [e0] Vendor Specific Information: Len=0c <?>
Kernel driver in use: hsw_uncore
[root@localhost platform] lspci -s 0000:00:01.0 -v # 0000:00:01.0 为 pci 桥设备
00:01.0 PCI bridge: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor PCI Express x16 Controller (rev 06) (prog-if 00 [Normal decode])
Flags: bus master, fast devsel, latency 0, IRQ 24
Bus: primary=00, secondary=01, subordinate=07, sec-latency=0
Memory behind bridge: f0000000-f41fffff
Capabilities: [88] Subsystem: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor PCI Express x16 Controller
Capabilities: [80] Power Management version 3
Capabilities: [90] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [a0] Express Root Port (Slot+), MSI 00
Capabilities: [100] Virtual Channel
Capabilities: [140] Root Complex Link
Kernel driver in use: pcieport
Kernel modules: shpchp
[root@localhost platform] lspci -s 0000:00:02.0 -v # 0000:00:02.0 为 VGA控制器
00:02.0 VGA compatible controller: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor Integrated Graphics Controller (rev 06) (prog-if 00 [VGA controller])
Subsystem: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor Integrated Graphics Controller
Flags: bus master, fast devsel, latency 0, IRQ 40
Memory at f4400000 (64-bit, non-prefetchable) [size=4M]
Memory at e0000000 (64-bit, prefetchable) [size=256M]
I/O ports at f000 [size=64]
Expansion ROM at <unassigned> [disabled]
Capabilities: [90] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [d0] Power Management version 2
Capabilities: [a4] PCI Advanced Features
Kernel driver in use: i915
Kernel modules: i915
[root@localhost platform] lspci -s 0000:00:03.0 -v # 0000:00:03.0 为音频设备
00:03.0 Audio device: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor HD Audio Controller (rev 06)
Subsystem: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor HD Audio Controller
Flags: bus master, fast devsel, latency 0, IRQ 43
Memory at f4934000 (64-bit, non-prefetchable) [size=16K]
Capabilities: [50] Power Management version 2
Capabilities: [60] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [70] Express Root Complex Integrated Endpoint, MSI 00
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
可以看到,0000:00:01.0 确实是 PCI Bridge 设备,其他三个为普通 PCI EP 设备。
我们可以进一步验证,1c.0 和 1c.1 是 PCI Bridge 设备,其中 1c.0 下面挂接 Bus 08 总线, 1c.1 下面挂接 Bus 09 总线, 09 总线下面还有一个 PCI 设备:0000:09:00.0,如下所示:


为了验证我们的结论,我们通过命令查看这几个设备的信息:
[root@localhost platform] lspci -s 0000:00:1c.0 -v # 0000:00:1c.0 为 pci 桥设备
00:1c.0 PCI bridge: Intel Corporation 8 Series/C220 Series Chipset Family PCI Express Root Port #1 (rev d5) (prog-if 00 [Normal decode])
Flags: bus master, fast devsel, latency 0, IRQ 25
Bus: primary=00, secondary=08, subordinate=08, sec-latency=0
I/O behind bridge: 00002000-00002fff
Memory behind bridge: df200000-df3fffff
Prefetchable memory behind bridge: 00000000df400000-00000000df5fffff
Capabilities: [40] Express Root Port (Slot+), MSI 00
Capabilities: [80] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [90] Subsystem: Intel Corporation 8 Series/C220 Series Chipset Family PCI Express Root Port #1
Capabilities: [a0] Power Management version 3
Kernel driver in use: pcieport
Kernel modules: shpchp
[root@localhost platform] lspci -s 0000:00:1c.1 -v # 0000:00:1c.1 为 pci 桥设备
00:1c.1 PCI bridge: Intel Corporation 8 Series/C220 Series Chipset Family PCI Express Root Port #2 (rev d5) (prog-if 00 [Normal decode])
Flags: bus master, fast devsel, latency 0, IRQ 26
Bus: primary=00, secondary=09, subordinate=09, sec-latency=0
I/O behind bridge: 0000e000-0000efff
Memory behind bridge: f4800000-f48fffff
Capabilities: [40] Express Root Port (Slot+), MSI 00
Capabilities: [80] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [90] Subsystem: Intel Corporation 8 Series/C220 Series Chipset Family PCI Express Root Port #2
Capabilities: [a0] Power Management version 3
Kernel driver in use: pcieport
Kernel modules: shpchp
[root@localhost platform] lspci -s 0000:09:00.0 -v # 0000:09:00.0 为 以太网控制器
09:00.0 Ethernet controller: Intel Corporation I210 Gigabit Network Connection (rev 03)
Subsystem: DFI Inc Device 100a
Flags: bus master, fast devsel, latency 0, IRQ 17
Memory at f4800000 (32-bit, non-prefetchable) [size=512K]
I/O ports at e000 [size=32]
Memory at f4880000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [40] Power Management version 3
Capabilities: [50] MSI: Enable- Count=1/1 Maskable+ 64bit+
Capabilities: [70] MSI-X: Enable+ Count=5 Masked-
Capabilities: [a0] Express Endpoint, MSI 00
Capabilities: [100] Advanced Error Reporting
Capabilities: [140] Device Serial Number 00-01-29-ff-ff-97-f7-48
Capabilities: [1a0] Transaction Processing Hints
Kernel driver in use: igb
Kernel modules: igb
再次回到 PCIe tree 的结构图,如下所示:
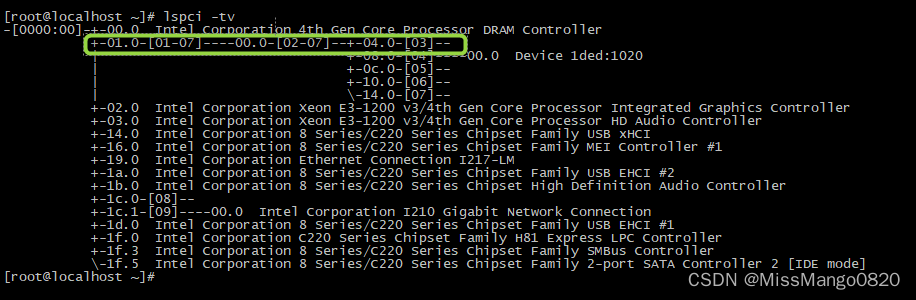
我们可以留意到,±01.0-[01-07]----00.0-[02-07]–±04.0-[03]-- 这一长串中,
±01.0-[01-07] 代表 0000:00 总线上的 0000:00:01.0 设备挂接 [01-07] 七条总线,其中 01 总线是与 0000:00:01.0 PCI 设备相连接的总线;
[01-07]----00.0-[02-07],01 总线下的设备 0000:01:00.0 又是一个 PCI Bridge 设备,下面挂接 [02-07] 六条总线,其中 02 总线是与 0000:01:00.0 设备相连接的总线;
同理,02 总线下面挂接的都是 PCI Bridge 设备,PCI Bridge 设备再新开新的 PCI 总线。可以看到,02 总线上的设备 0000:02:08.0 挂接着 04 总线,04 总线上还挂接着 0000:04:00.0 PCI 设备。
系统上电以后,Host 会自动完成上述的设备枚举过程。除一些专有系统外,普通系统只会在开机阶段进行设备的扫描。
当我们安装一个 PCIe 设备驱动后,可以在 /sys/bus/pci/drivers 目录下找到我们安装的 PCIe 设备驱动模块,如下所示:
[root@localhost ~] ls /sys/bus/pci/drivers
agpgart-intel ata_generic ehci-pci i915 lpc_ich ohci-pci pci-stub snd_hda_intel xhci_hcd
agpgart-sis ata_piix hsw_uncore igb mei_me pata_acpi serial uhci_hcd
agpgart-via e1000e i801_smbus ioapic mlx5_core pcieport shpchp xen-platform-pci
[root@localhost platform] insmod nsa_dma.ko # 安装驱动模块
[root@localhost platform] ls /sys/bus/pci/drivers # 多出 nsa_dma 驱动模块
agpgart-intel ata_generic ehci-pci i915 lpc_ich nsa_dma pcieport shpchp xen-platform-pci
agpgart-sis ata_piix hsw_uncore igb mei_me ohci-pci pci-stub snd_hda_intel xhci_hcd
agpgart-via e1000e i801_smbus ioapic mlx5_core pata_acpi serial uhci_hcd
[root@localhost platform]# ls /sys/bus/pci/devices/ # PCIe设备数量不变,因为只会在开机阶段进行PCIe设备扫描
0000:00:00.0 0000:00:03.0 0000:00:19.0 0000:00:1c.0 0000:00:1f.0 0000:01:00.0 0000:02:0c.0 0000:04:00.0
0000:00:01.0 0000:00:14.0 0000:00:1a.0 0000:00:1c.1 0000:00:1f.3 0000:02:04.0 0000:02:10.0 0000:09:00.0
0000:00:02.0 0000:00:16.0 0000:00:1b.0 0000:00:1d.0 0000:00:1f.5 0000:02:08.0 0000:02:14.0
对于
nvme设备,同时显示其BDF与PCIe设备号的方法,可参考这里 24,使用readlink -f /sys/class/nvme/nvme*
PCIe 供电
从 OS 层面上,简单的 reboot 等命令属于软重启 25‘ 26,并不会对 PCIe Card 的供电进行上下电。但是可以通过以下命令来移除 PCIe 设备后再重新从 PCIe Bus 加载它以在不需要重启 PC 的前提下利用 Linux 内核对 PCIe 设备进行上下电 27’ 18。
echo "1" > /sys/bus/pci/devices/DDDD\:BB\:DD.F/remove
sleep 1
echo "1" > /sys/bus/pci/rescan
工具
lspci 其实是一个开源工具 pciutils 28 的命令,对应命令还有 setpci(用于读写 PCIe 配置寄存器)。
如果你的系统中找不到这个命令,可以执行 yum install pciutils 进行在线安装。
如果需要离线安装,工具官网或者内核官网也可以下载到源码,阅读分析这些源码对于开发 PCIe 相关内容有极大的帮助。
而 Windows 下,有一个很久没有更新的工具,叫 pcitree 29。
只能运行于
win7以及之前的windows版本。详情参照user guide。
lspci
-
lspci -tv
查看PCI设备拓扑结构

-
lspci -s [b:d: f]
查看PCI设备详细信息

-
lspci -s [b:d:f] -x
PCI标准配置头空间-x

-
lspci -s [b:d:f] -xxx
PCI Capbility配置空间-xxx

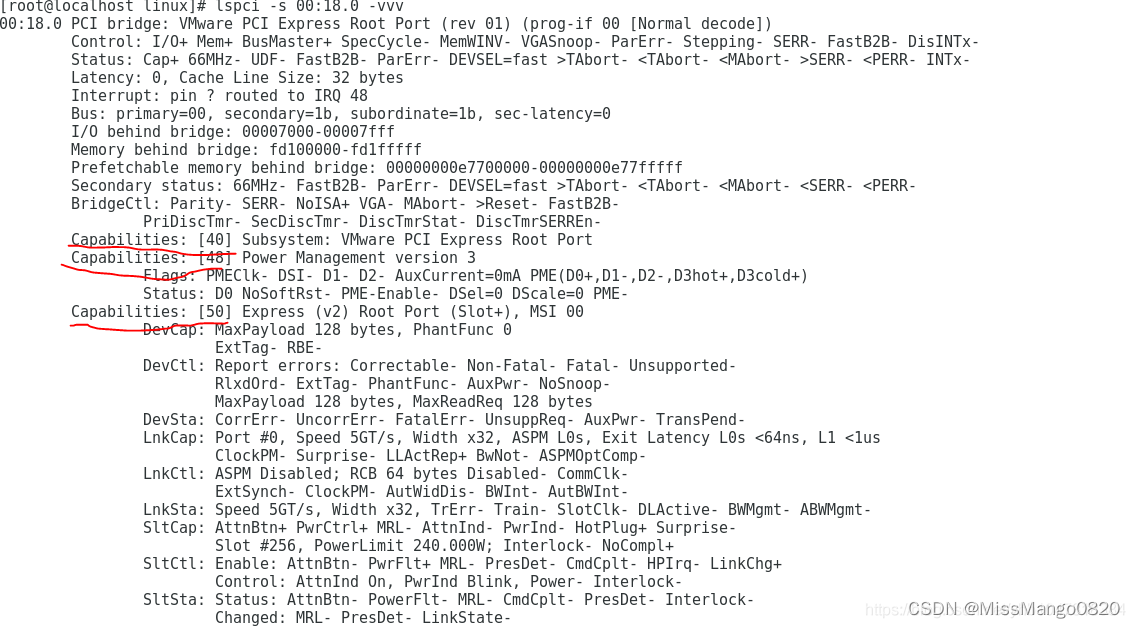
红色框框中的第一列对应具体的偏移,第二列对应的是设备的 Capability id, 第三列对应的是 Next Capability id 的偏移。
所以 40: 0d 48 表示偏移 0x40 的位置的 Capability id 是 0xd( SSVID ); 它指向的下一个capability 位于 0x48 处,偏移 0x48 的位置的 Capability id 是 0x1 (即 power management ); 它指向的下一个 capabity 位于 0x50 处,偏移 0x50 的位置的 Capability id 是 0x10 ( MSI );它指向的下一个 Capability 位于 0x8c 处, 偏移 0x8c 的位置的 Capability id 为 0x0,查找结束。
得到的结果是可以与 lspci 的结果对应的:
-
lspci -s [b:d:f] -xxxx
PCIe扩展配置空间-xxxx
setpci
可以用 setpci 命令修改配置空间。语法如下,
setpci -s 00:00.0 0x地址.L=0x值
修改设备地址的数值,一次修改 4 个字节。
示例
1.
举个例子 30, 上面有提到往 PCI 设备的 BAR 寄存器写全 1 可以计算 BAR 空间的大小需求。
- 通过
setpci --dumpregs可以查看寄存器偏移,如下所示,
[root@localhost ~] setpci --dumpregs
cap pos w name
00 W VENDOR_ID
02 W DEVICE_ID
04 W COMMAND
06 W STATUS
08 B REVISION
09 B CLASS_PROG
0a W CLASS_DEVICE
0c B CACHE_LINE_SIZE
0d B LATENCY_TIMER
0e B HEADER_TYPE
0f B BIST
10 L BASE_ADDRESS_0
14 L BASE_ADDRESS_1
18 L BASE_ADDRESS_2
1c L BASE_ADDRESS_3
20 L BASE_ADDRESS_4
24 L BASE_ADDRESS_5
...
由上面的输出内容可以知道 BAR0 的偏移是 0x10。
- 使用
lspci -s [b:d:f] -x查看目标设备的PCIe配置头空间,如下所示:
[root@localhost ~] lspci -s 02:01.0 -x
02:01.0 Ethernet controller: Intel Corporation 82545EM Gigabit Ethernet Controller (Copper) (rev 01)
00: 86 80 0f 10 17 01 30 02 01 00 00 02 10 00 00 00
10: 04 00 5c fd 00 00 00 00 04 00 ff fd 00 00 00 00
20: 01 20 00 00 00 00 00 00 00 00 00 00 ad 15 50 07
30: 00 00 00 00 dc 00 00 00 00 00 00 00 07 01 ff 00
由上面的输出内容可以知道 BAR0 的值为 fd5c0004。
-
通过
setpci命令写BAR0地址全F,

刚开始的BAR0的值为fd5c0004, 写过全F后,由上面的输出内容可以知道BAR0的值为fffe0004。 -
由
BAR0的值前后变化可知最低位可写入的bit是18( 低4bit不算bar地址,是特殊标记)。如下所示,

所以 BAR0 的空间大小是 2^18 = 256K。
参考链接
mark
command not found: lspci, in macOS 11.4
【转】PCIe资料总结
PCIe链路训练
深入PCI与PCIe之一:硬件篇















 2287
2287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









