







前言
博主时年大三,平日使用C++者十之八九,python基本不会,深度学习完全不会。周末回不了学校的晚上在网吧通宵学习三元组损失,最终提前两周完成模型构建。废话一大堆,博主的意思是连我都能2周完成的事,再加上这篇详细无比的笔记相信谁都能快速上手facenet人脸识别项目!自信点,一周秒了!
前置知识
在上手写代码之前,首先要知道我们要写的是什么东西。博主完成的是基于facenet模型的牛脸识别项目,虽然facenet模型是一个人脸识别模型,但是你可以用它完成各种各样的识别任务,花啊牛啊羊啊什么都行,只是在原来的基础上做一些细微的调整而已。
什么是facenet?facenet算法是由谷歌公司提出的人脸识别模型,facenet算法=MTCNN模型+facenet模型。注意本篇文章没有使用到MTCNN模型,因为MTCNN模型的功能是在图片中找到对象并裁剪对齐得到正脸图像,也就是图像的预处理过程,facenet模型的输入就是这个MTCNN模型的输出。为什么不用?因为在下文的数据集构建中博主手动完成了这个任务,可以说我就是人肉MTCNN模型,截图就截了整整两天,真是这辈子没见过这么多牛。

facenet是怎么实现人脸识别的?原理是facenet把面部图片变成一个高维特征向量。这一步相当于编码,即每一个输入X都有一个Y,如同函数一对一的映射关系。众所周知,向量是可以计算距离的,facenet就是基于欧几里得距离来实现识别的,同一个人脸图像的空间距离比较小,不同人脸图像的空间距离比较大。举个例子,你有100个不同人脸,把这一百个人脸全部经过facenet模型后得到了100个高维向量,这一步是你的训练过程,让模型认识这一百个人。当你进行识别时,输入你想识别的人的图片,模型就会得到一个新的向量,还要设定一个阈值,接着计算这个向量与其他向量的最小距离,当最小距离大于阈值时模型则认为不认识这个人。否则模型找出和此向量距离最小的向量的标签比如为B,模型认为这个人就是B。
facenet有什么特点?这里就要提到facenet模型最关键的一点了:三元组损失(Triplet loss)。可以说只要使用了三元组损失函数的模型都是facenet模型。对三元组损失的了解至关重要,是整个模型的核心部分,三元组损失详解请看这里(一定要看明白看懂!这一步决不能偷懒!)
facenet长什么样?

①batch是模型的输入,因为facenet是使用三元组损失的模型,所以这里的输入应该是三元组,即一个组里有两张同一个人/牛的图片和另一个人/牛的图片。batch有一个参数一般叫做batch_size,即一次输入的大小,当设置batch_size=5时表示一次给模型输入5个三元组让模型学习。
②deep architecture是facenet的主干特征提取网络。这里博主在学习时被困扰了很久,其实非常简单:把facenet想象成一个电脑,deep architecture就是这个电脑的显卡,你可以为你的电脑选择不同型号的显卡,如resnet50,resnet18,Inception_v3等等,不同的显卡都能完成任务,都是通过卷积神经网络来提取图像的特征的,什么卷积神经网络?详解在这里(要明白卷积层、池化层、激活函数、全连接层的含义),不同模型只是在构建上有些不同。博主的项目选择的是resnet50。resnet残差网络非常厉害,它解决了梯度消失或梯度爆炸问题,但博主发现好像了不了解都对这里的项目实践影响不大,还是很推荐看看,链接在这里。
③L2代表的是L2范数。不要被这个陌生的名字吓到,其实这就是高中学向量那一章学的向量归一化。前面我们提到了facenet模型是把输入的图片变成一个高维特征向量,可以是128维、256维或者其他维度。L2这一步就是得到的这个高维特征向量进的模!把向量的长度变为1。还没想起来?看这个:![]() ,比如我们有一个向量(1,2,2),那么它的模就是1+2*2+2*2=9再开根为3,这个向量的L2范数就为3,归一化把向量每一个元素除以L2范数的结果为(1/3,2/3,2/3),这时此向量的长度就为1了。
,比如我们有一个向量(1,2,2),那么它的模就是1+2*2+2*2=9再开根为3,这个向量的L2范数就为3,归一化把向量每一个元素除以L2范数的结果为(1/3,2/3,2/3),这时此向量的长度就为1了。
④embedding就是得到的高维特征向量了。很好理解,每日一词embed v.嵌入。相当于把这个图像嵌入进模型中,注意embedding是经过上述L2范数归一化后的向量,也就是说embedding长度为1 ,即embedding中的128个(假设设置大小为128)元素的平方和为1。
⑤Triplet Loss想必就不用多说了,就是上文链接详细了解过后的三元组损失。这里还有一个问题不知道读者注意到没有,高维向量是128维或更高维度,但是长度才为1。什么问题?三元损失值太小了!想想:假设每一个元素大小为0.1,那么一个元素的平方才为0.01,128个这样的元素长度都有1.28了,但实际长度为1,也就是说128维向量的每一个值平均大小还不到0.1。更别说计算三元组损失时还要将两个向量距离相减,最后的损失值可想而知小的可怜。
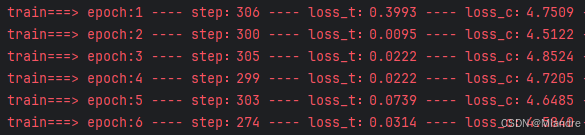
可以看到博主这里实际的运行结果,这里的loss_t代表的就是三元组损失,大点的才0.3几,小的甚至才0.0095。损失太小有什么影响?facenet模型是根据损失更新参数的,如果这个损失太小,那么模型参数更新就太小,甚至反向传播时就完全没了(这就是之前提到的梯度消失),也就是说模型什么都没有改变,那么不管你的训练数据再多你的模型还是草包一个。怎么解决这个问题?构建模型时会讲到。
写!代!码!
前置知识终于讲完了!现在我相信读者已经掌握了理论知识,到了最艰难的一步:动手
下面的文件中所需的头文件如果缺少可直接复制粘贴给GPT问应该下载什么包然后在终端pip install即可。
博主在学习时也是跟着B站大佬的教程一步一步照葫芦画瓢学习的,原视频链接在这里
一、制作数据集
巧妇难为无米之炊,首先第一步构建数据集,炒菜之前你得先有菜吧?这是整个项目最无聊最枯燥的部分。前面博主提到了这个项目没有用到MTCNN模型提取牛正脸图片,而是自己一张一张截图截出来的。截图的时候要注意,像牛羊这样带角的动物,截图时要把角也包含进去,毕竟角也是很重要的面部特征。结果图如下:



我们创建一个文件夹,文件夹名字不能有中文,不然后面模型无法读取中文路径。然后我们给每个牛截出至少三张脸部图片(三元组要求同类别至少要两张图像),然后给同一头牛的图像命名为X-XX.jpg。比如第一头牛第三张图片就分别命名为1-1.jpg,1-2.jpg,1-3.jpg。最后博主做了200头牛的面部数据一共627张图像,当然数据集是越多越好。如下图:

当你完成了这一步枯燥的准备后我们就可以正式开始构建项目了!
PyCharm,启动!
首先新建项目,将你准备好的数据集文件夹放到你的项目里。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









