









本文记录使用 ms-Swift 框架 对 DeepSeekR1 蒸馏系列模型(7B、14B)在 A100(40GB)* 1 服务器上部署过程与测试结果。
框架:ms-swift
部署方法可选:vLLM、LMDeploy
加速方式:flash_attn
支持openai接口格式:是
模型:DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B
环境准备
本文基础环境如下:
----------------
x86_64
ubuntu 22.04 or centos 7
gpu: A100(40GB) * 1
python 3.10
cuda 12.2
----------------
本文默认已配置好以上 cuda、anaconda 环境,如未配置请先自行安装。
-
cuda
- 驱动安装详细教程:服务器显卡驱动与 CUDA 安装秘籍
- 显卡与驱动版本对应查询
PCI devices (ucw.cz) - 安装驱动
Official Drivers | NVIDIA - 安装 CUDA
CUDA Toolkit Archive | NVIDIA Developer
依赖安装
创建虚拟环境
-
新建虚拟环境
- -n DeepSeekR1:指定要创建的虚拟环境的名称为 DeepSeekR1。
- python=3.10:指定虚拟环境中 Python 的版本为 3.10。
- -y:在创建环境过程中自动确认所有提示,无需手动输入 yes。
- -c:用于指定 conda 源。这里指定了清华大学的主源和自由源。
- --override-channels 临时禁用默认源,仅使用你指定的源
conda create -n DeepSeekR1 python=3.10 -y --override-channels -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
-
激活环境
创建完成后,你可以使用以下命令来激活并验证虚拟环境:
# 激活虚拟环境 conda activate DeepSeekR1 # 查看 Python 版本 python --version如果输出的 Python 版本为 3.10,则说明虚拟环境创建成功。
模块安装
-
首先 pip 换源加速下载并安装依赖包
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ pip install --upgrade pip
-
安装所需模块
直接复制,快速安装
也可以分开一个一个安
pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
-
检查安装是否成功
python -c "import torch; print(torch.cuda.is_available())"输出True 这说明 GPU版本的pytorch安装成功
模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 local_dir为模型的下载路径。
新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', local_dir='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', revision='master')
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-14B', local_dir='deepseek-ai/DeepSeek-R1-Distill-Qwen-14B', revision='master')
然后在终端中输入 python model_download.py 执行下载,这里需要耐心等待一段时间直到模型下载完成。
注意:记得修改 local_dir 为你的模型下载路径
部署测试
- 运行部署命令
CUDA_VISIBLE_DEVICES=1 swift deploy \
--model /home/mnivl/apps/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
--max_model_len 8192 \
--host 0.0.0.0 \
--port 10040 \
--attn_impl flash_attn \
--infer_backend vllm
基础参数
--host: 默认为'0.0.0.0'.
--port: 默认为8000.
--api_key: 默认为None, 即不对请求进行api_key验证.
--ssl_keyfile: 默认为None.
--ssl_certfile: 默认为None.
--verbose: 是否对请求内容进行打印, 默认为True.
--log_interval: 对统计信息进行打印的间隔, 单位为秒. 默认为10. 如果设置为0, 表示不打印统计信息.
--attn_impl: [flash_attn,sdpa,eager,None] 注意力机制的实现方式
- flash_attn 利用 Flash Attention 的高效特性,提升模型的推理速度,同时减少内存占用
更多参数:swift 命令行参数
--infer_backend {vllm,pt,lmdeploy} 推理框架选用
vllm
参考文档: OpenAI-Compatible Server — vLLM
--gpu_memory_utilization: 初始化vllm引擎EngineArgs的参数, 默认为0.9. 该参数只有在使用vllm时才生效. VLLM推理加速和部署可以查看VLLM推理加速与部署.
--tensor_parallel_size: 初始化vllm引擎EngineArgs的参数, 默认为1. 该参数只有在使用vllm时才生效.
--max_num_seqs: 初始化vllm引擎EngineArgs的参数, 默认为256. 该参数只有在使用vllm时才生效.
--max_model_len: 覆盖模型的max_model_len, 默认为None. 该参数只有在使用vllm时才生效.
--disable_custom_all_reduce: 是否禁用自定义的all-reduce kernel, 而回退到NCCL. 默认为True, 这与vLLM的默认值不同.
--enforce_eager: vllm使用pytorch eager模式还是建立cuda graph. 默认为False. 设置为True可以节约显存, 但会影响效率.
--limit_mm_per_prompt: 控制vllm使用多图, 默认为None. 例如传入--limit_mm_per_prompt '{"image": 10, "video": 5}'.
--vllm_enable_lora: 默认为False. 是否开启vllm对lora的支持. 具体可以查看VLLM & LoRA.
--vllm_max_lora_rank: 默认为16. vllm对于lora支持的参数
--cache-max-entry-count 控制kv缓存占用剩余显存的最大比例。默认的比例为0.8
最终 显存占用 = 模型权重占用 + kv缓存占用
kv缓存占用 = (总显存 - 模型权重占用) * cache-max-entry-count
lmdeploy
参考文档: inference pipeline — lmdeploy
--tp: tensor并行, 用于初始化lmdeploy引擎的参数, 默认值为1.
--cache-max-entry-count 控制kv缓存占用剩余显存的最大比例。默认的比例为0.8
最终 显存占用 = 模型权重占用 + kv缓存占用
kv缓存占用 = (总显存 - 模型权重占用) * cache-max-entry-count
--quant_policy: Key-Value Cache量化, 初始化lmdeploy引擎的参数, 默认值为0, 你可以设置为4, 8.
--vision_batch_size: 初始化lmdeploy引擎的参数, 默认值为1. 该参数只有在使用多模态模型时生效.
- 通过 curl 命令查看当前的模型列表
curl http://localhost:10040/v1/models
得到的返回值如下所示
{
"data": [
{
"id": "DeepSeek-R1-Distill-Qwen-14B",
"object": "model",
"created": 1738832400,
"owned_by": "swift"
}
],
"object": "list"
}
- curl 对话测试
curl http://localhost:10040/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-14B",
"messages": [
{"role": "user", "content": "地心说为什么是真的"}
],
"stream": true
}'
-
显存占用
实际占用 = 权重占用 +kv cache占用

并发测试
| 设备 | 模型 | 上下文 | 并发 | 循环次数 | 速率(tokens/s) | 显存(GB) | 请求超时个数 |
|---|---|---|---|---|---|---|---|
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-7B | 2048 | 16 | 2 | 945.2 | 36.9a | 0 |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-7B | 4096 | 16 | 2 | 744.6 | 37.2 | 0 |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-7B | 8192 | 16 | 2 | 885.0 | 37.2 | 0 |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-7B | 8192 | 32 | 3 | 1490.2 | 38.1 | 1 |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-7B | 8192 | 1 | 1 | 47.9 | 38.1 | 0 |
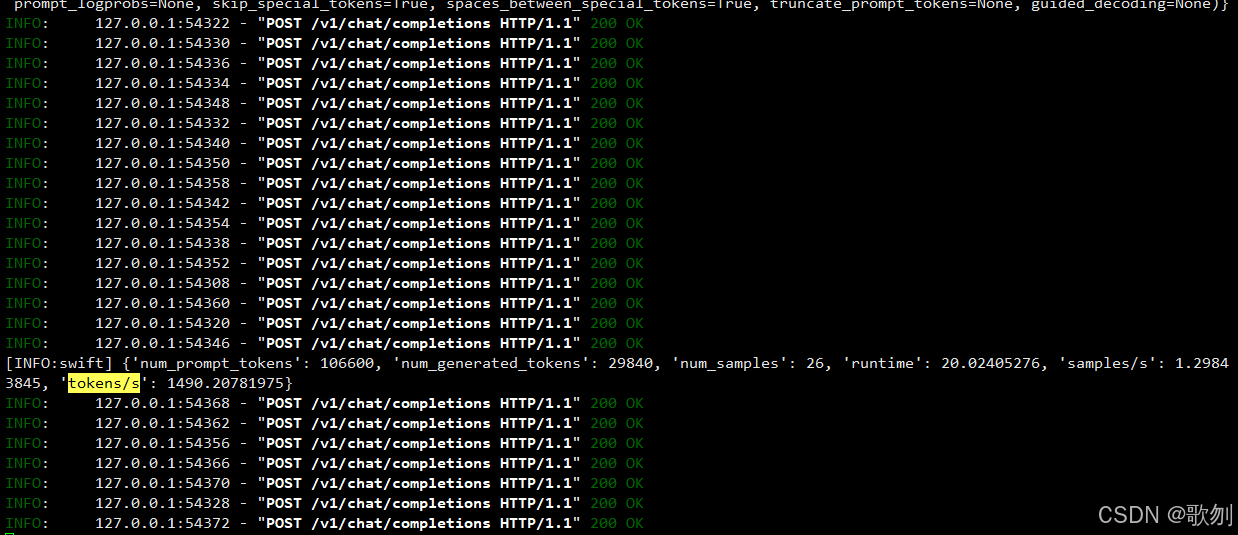
![]()
| 设备 | 模型 | 上下文 | 并发 | 循环次数 | 速率(tokens/s) | 显存(GB) | 请求超时个数 | flash_attn 加速 |
|---|---|---|---|---|---|---|---|---|
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 2048 | 16 | 2 | 586.8 | 37.6 | 0 | False |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 4096 | 16 | 2 | 370.5 | 38.0 | 17 | False |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 8192 | 16 | 2 | 285.3 | 38.1 | 24 | False |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 8192 | 1 | 1 | 38.3 | 38.1 | 0 | False |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 4096 | 16 | 2 | 454.9 | 38.6 | 15 | True |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 8192 | 16 | 2 | 242.5 | 38.6 | 23 | True |
| A100(40GB) * 1 | DeepSeek-R1-Distill-Qwen-14B | 8192 | 1 | 1 | 48.4 | 37.9 | 0 | True |
请求 timeout=60s
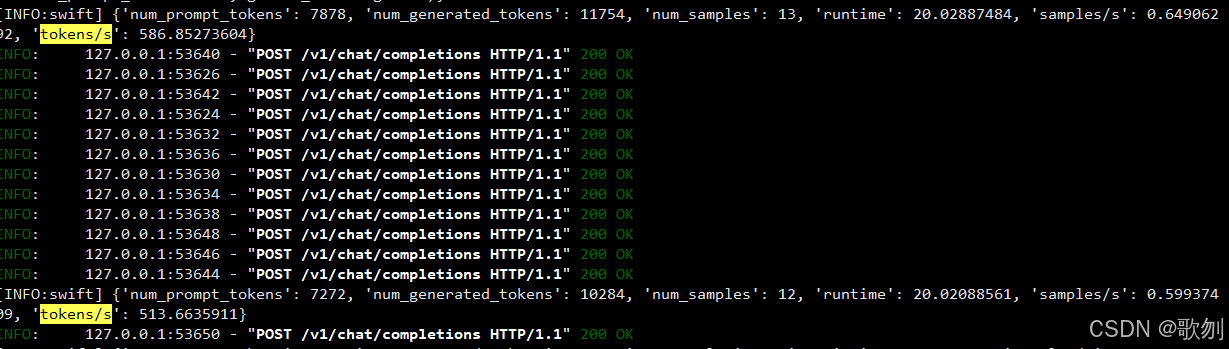

过程可能出现的报错
模块安装错误
pip._vendor.urllib3.exceptions.ReadTimeoutError
packages/pip/vendor/urllib3/response.py", line 443, in _error_catcher raise ReadTimeoutError(self.pool, None, "Read timed out.")
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='mirrors.aliyun.com',
- pip install 包下载时, 会自动下载相关依赖,过程可能会很久,导致超时。
解决:直接重新执行pip install xxx 下载命令即可,pip cache 缓存会保留已经下好的依赖包
pip install deepspeed==0.14.* -U
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Collecting deepspeed==0.14.*
Using cached https://mirrors.aliyun.com/pypi/packages/85/b1/4f2e80eb76058122ba4a405feff1bf07af084ab5cf282aeecd19b0a3c46a/deepspeed-0.14.5.tar.gz (1.4 MB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [23 lines of output]
[2025-02-07 15:05:20,937] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-02-07 15:05:21,630] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/setup.py", line 39, in <module>
from op_builder import get_default_compute_capabilities, OpBuilder
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/op_builder/__init__.py", line 18, in <module>
import deepspeed.ops.op_builder # noqa: F401 # type: ignore
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/deepspeed/__init__.py", line 25, in <module>
from . import ops
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/deepspeed/ops/__init__.py", line 15, in <module>
from ..git_version_info import compatible_ops as __compatible_ops__
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/deepspeed/git_version_info.py", line 29, in <module>
op_compatible = builder.is_compatible()
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/op_builder/fp_quantizer.py", line 35, in is_compatible
sys_cuda_major, _ = installed_cuda_version()
File "/tmp/pip-install-vmn2un79/deepspeed_dcca99b6cf834ce0aeba0165144d68f8/op_builder/builder.py", line 51, in installed_cuda_version
raise MissingCUDAException("CUDA_HOME does not exist, unable to compile CUDA op(s)")
op_builder.builder.MissingCUDAException: CUDA_HOME does not exist, unable to compile CUDA op(s)
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-devel package with yum
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
- 和cuda环境有关系,但是问题不太大
-
这里是编译安装失败,所以可以直接去下载编译好的 .whl 文件来安装
-
在这里找到对应版本的 deepspeed .whl 模块包安装即可
也可下载我下好的版本:
deepspeed-0.14.3-py3-none-any.whl -
将whl文件上传到服务器后,执行
pip install deepspeed-0.14.3-py3-none-any.whl
程序运行报错
ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0
ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla V100-PCIE-32GB GPU has compute capability 7.0. You can use float16 instead by explicitly setting thedtype flag in CLI, for example: --dtype=half.
- 数据类型不兼容:bfloat16(Brain Floating Point 16)是一种 16 位的浮点数数据类型,它在一些新的 GPU 架构上(计算能力至少为 8.0)被支持,用于加速深度学习训练和推理。而 Tesla V100 GPU 计算能力为 7.0,不支持 bfloat16。
解决办法
- 使用 float16 替代 bfloat16
错误信息中已经给出了提示,可以使用 float16 替代 bfloat16。具体做法是在命令行中显式设置 dtype 标志。
from vllm import LLM
....
# 初始化 vLLM 推理引擎
llm = LLM(model=model, ..., dtype="float16")
python -m vllm.entrypoints.openai.api_server \
--model /home/mnivl/apps/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
.... \
--dtype float16
ImportError: libGL.so.1
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
不知道为什么swift在推理语言模型时,使用vllm方式推理时,会调用openGL图像库
所以,如果不想麻烦,可以直接在推理和部署的指令中去除vllm选项即可
去除 --infer_backend vllm
改为 --infer_backend lmdeploy
模型指标
DeepSeek-R1 训练技术论文链接: DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1 · GitHub
- 使用 DeepSeek-R1 生成的推理数据,微调了研究界广泛使用的几个密集模型。评估结果表明,蒸馏的较小密集模型在基准上表现非常出色。开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、14B、8B、14B、32B 和 70B 。
- 魔搭社区
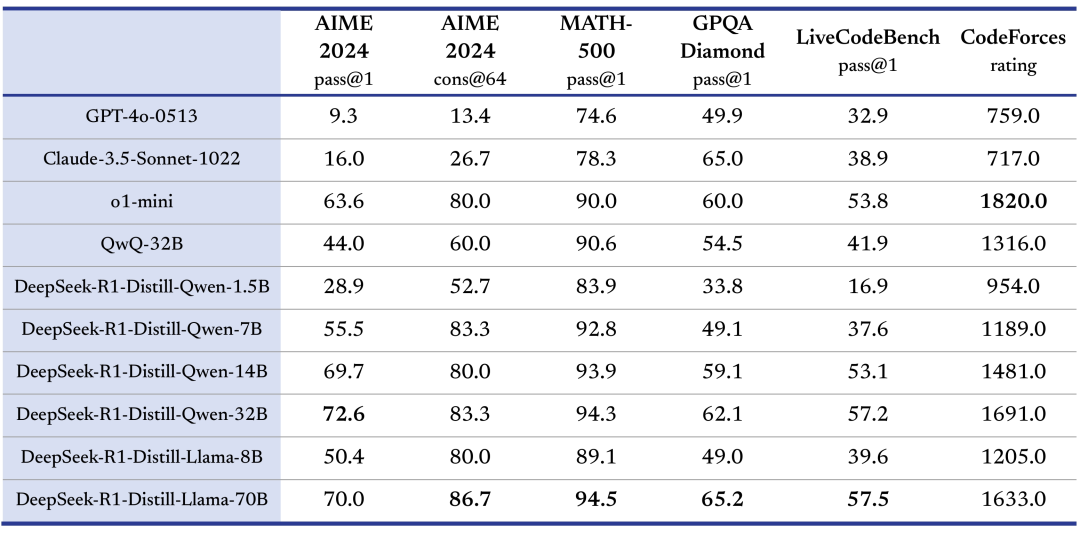
DeepSeek-R1 Models
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 314B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 314B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
ms-swift 特性
🍲 ms-swift是魔搭社区提供的大模型与多模态大模型微调部署框架,现已支持450+大模型与150+多模态大模型的训练(预训练、微调、人类对齐)、推理、评测、量化与部署。其中大模型包括:Qwen2.5、InternLM3、GLM4、Llama3.3、Mistral、DeepSeek-R1、Yi1.5、TeleChat2、Baichuan2、Gemma2等模型,多模态大模型包括:Qwen2.5-VL、Qwen2-Audio、Llama3.2-Vision、Llava、InternVL2.5、MiniCPM-V-2.6、GLM4v、Xcomposer2.5、Yi-VL、DeepSeek-VL2、Phi3.5-Vision、GOT-OCR2等模型。
🍔 除此之外,ms-swift汇集了最新的训练技术,包括LoRA、QLoRA、Llama-Pro、LongLoRA、GaLore、Q-GaLore、LoRA+、LISA、DoRA、FourierFt、ReFT、UnSloth、和Liger等。ms-swift支持使用vLLM和LMDeploy对推理、评测和部署模块进行加速,并支持使用GPTQ、AWQ、BNB等技术对大模型和多模态大模型进行量化。为了帮助研究者和开发者更轻松地微调和应用大模型,ms-swift还提供了基于Gradio的Web-UI界面及丰富的最佳实践。
为什么选择ms-swift?
- 🍎 模型类型:支持450+纯文本大模型、150+多模态大模型,All-to-All全模态模型的训练到部署全流程。
- 数据集类型:内置150+预训练、微调、人类对齐、多模态等各种类型的数据集,并支持自定义数据集。
- 硬件支持:CPU、RTX系列、T4/V100、A10/A100/H100、Ascend NPU等。
- 🍊 轻量训练:支持了LoRA、QLoRA、DoRA、LoRA+、ReFT、RS-LoRA、LLaMAPro、Adapter、GaLore、Q-Galore、LISA、UnSloth、Liger-Kernel等轻量微调方式。
- 分布式训练:支持分布式数据并行(DDP)、device_map简易模型并行、DeepSpeed ZeRO2 ZeRO3、FSDP等分布式训练技术。
- 量化训练:支持对BNB、AWQ、GPTQ、AQLM、HQQ、EETQ量化模型进行训练。
- RLHF训练:支持纯文本大模型和多模态大模型的DPO、CPO、SimPO、ORPO、KTO、RM、PPO等人类对齐训练方法。
- 🍓 多模态训练:支持对图像、视频和语音不同模态模型进行训练,支持VQA、Caption、OCR、Grounding任务的训练。
- 界面训练:以界面的方式提供训练、推理、评测、量化的能力,完成大模型的全链路。
- 插件化与拓展:支持自定义模型和数据集拓展,支持对loss、metric、trainer、loss-scale、callback、optimizer等组件进行自定义。
- 🍉 工具箱能力:不仅提供大模型和多模态大模型的训练支持,还涵盖其推理、评测、量化和部署全流程。
- 推理加速:支持PyTorch、vLLM、LmDeploy推理加速引擎,并提供OpenAI接口,为推理、部署和评测模块提供加速。
- 模型评测:以EvalScope作为评测后端,支持100+评测数据集对纯文本和多模态模型进行评测。
- 模型量化:支持AWQ、GPTQ和BNB的量化导出,导出的模型支持使用vLLM/LmDeploy推理加速,并支持继续训练。
新功能
-
数据集模块重构。数据集加载速度提升2-20倍,encode速度提升2-4倍,支持streaming模式
- 移除了dataset_name机制,采用dataset_id、dataset_dir、dataset_path方式指定数据集
- 使用--dataset_num_proc支持多进程加速处理
- 使用--streaming支持流式加载hub端和本地数据集
- 支持--packing命令以获得更稳定的训练效率
- 指定--dataset <dataset_dir>支持本地加载开源数据集
-
对模型进行了重构:
- 移除了model_type机制,使用--model <model_id>/<model_path>来训练和推理
- 若是新模型,直接使用--model <model_id>/<model_path> --template xxx --model_type xxx,无需书写python脚本进行模型注册
本文档列举3.x版本和2.x版本的BreakChange。开发者在使用时应当注意这些不同。
参数差异
- model_type的含义发生了变化。3.0版本只需要指定--model,model_type仅当模型为SWIFT不支持模型时才需要额外指定
- sft_type更名为train_type
- model_id_or_path更名为model
- template_type更名为template
- quantization_bit更名为quant_bits
- check_model_is_latest更名为check_model
- batch_size更名为per_device_train_batch_size,沿用了transformers的命名规则
- eval_batch_size更名为per_device_eval_batch_size,沿用了transformers的命名规则
- tuner_backend移除了swift选项
- use_flash_attn更名为attn_impl
- bnb_4bit_comp_dtype更名为bnb_4bit_compute_dtype
- 移除了train_dataset_sample和val_dataset_sample
- dtype更名为torch_dtype,同时选项名称从bf16变更为标准的bfloat16,fp16变更为float16,fp32变更为float32
- 移除了eval_human选项
- dataset选项移除了HF::使用方式,使用新增的--use_hf控制下载和上传
- 移除了do_sample选项,使用temperature进行控制
- add_output_dir_suffix更名为add_version
- 移除了eval_token,使用api_key支持
- target_modules(lora_target_modules)的ALL改为了all-linear,含义相同
- deepspeed的配置更改为default-zero2->zero2, default-zero3->zero3
- infer/deploy/export移除了--ckpt_dir参数,使用--model, --adapters进行控制
支持的模型
| 模型类型 | 模型标识 |
|---|---|
| DeepSeek 系列 | deepseek, deepseek_coder, deepseek_vl, deepseek_janus, deepseek_v2_5, deepseek_r1, deepseek_vl2, deepseek_janus_pro |
| Emu3 系列 | emu3_gen, emu3_chat |
| Gemma 系列 | gemma, paligemma |
| ChatGLM 系列 | chatglm2 |
| GLM 系列 | glm4v, glm4, glm_edge_v |
| CodeGeeX 系列 | codegeex4 |
| LongWriter 系列 | longwriter_llama |
| CogAgent 系列 | cogagent_chat, cogagent_vqa |
| CogVLM 系列 | cogvlm, cogvlm2, cogvlm2_video |
| Llama 系列 | llama, llama3, llama3_2, llama3_2_vision, llama3_1_omni |
| Qwen 系列 | qwen, qwen2_5, qwen2_5_math, qwen2_5_math_prm, qwen_vl, qwen_audio, qwen2_audio, qwen2_vl, qwen2_5_vl |
| Qvq 系列 | qvq |
| Ovis 系列 | ovis1_6, ovis1_6_llama3 |
| Marco 系列 | marco_o1 |
| Got OCR 系列 | got_ocr2 |
| Idefics 系列 | idefics3 |
| InternLM 系列 | internlm, internlm2, internlm2_reward |
| XComposer 系列 | ixcomposer2, xcomposer2_5, xcomposer2_4khd |
| Florence 系列 | florence |
| Phi 系列 | phi3, phi4, phi3_vision |
| InternVL 系列 | internvl, internvl_phi3, internvl2, internvl2_phi3, internvl2_5 |
| Llava 系列 | llava1_5_hf, llava_next_video_hf, llava1_6_mistral_hf, llava1_6_vicuna_hf, llava1_6_yi_hf, llama3_llava_next_hf, llava_next_qwen_hf, llava_onevision_hf, llava_llama3_1_hf, llava_llama3_hf, llava1_6_mistral, llava1_6_yi, llama3_llava_next, llava_next_qwen |
| Default 系列 | default |
| ModelScope Agent 系列 | modelscope_agent |
| Baichuan 系列 | baichuan |
| Numina 系列 | numina |
| Mistral 系列 | mistral_nemo |
| Xverse 系列 | xverse |
| Yuan 系列 | yuan |
| Ziya 系列 | ziya |
| Skywork 系列 | skywork, skywork_o1 |
| Bluelm 系列 | bluelm |
| CodeFuse 系列 | codefuse_codellama, codefuse |
| Zephyr 系列 | zephyr |
| Sus 系列 | sus |
| Orion 系列 | orion |
| Telechat 系列 | telechat, telechat2 |
| Dbrx 系列 | dbrx |
| Mengzi 系列 | mengzi |
| C4AI 系列 | c4ai |
| WizardLM 系列 | wizardlm2, wizardlm2_moe |
| Atom 系列 | atom |
| Aya 系列 | aya |
| Megrez 系列 | megrez, megrez_omni |
| Minicpm 系列 | minicpm, minicpmv, minicpmv2_5, minicpmv2_6, minicpmo2_6 |
| Minimax 系列 | minimax, minimax_vl |
| Molmo 系列 | molmo |
| Mplug Owl 系列 | mplug_owl2, mplug_owl3, mplug_owl3_241101 |
| Doc Owl 系列 | doc_owl2 |
| OpenBuddy 系列 | openbuddy, openbuddy2 |
| Pixtral 系列 | pixtral |
| Valley 系列 | valley |
| Yi 系列 | yi_coder, yi_vl |
引用借鉴
- ReleaseNote 3.0 — swift 3.1.0.dev0 文档
- GitHub - modelscope/ms-swift: Use PEFT or Full-parameter to finetune 450+ LLMs (Qwen2.5, InternLM3, GLM4, Llama3.3, Mistral, Yi1.5, Baichuan2, DeepSeek-R1, ...) and 150+ MLLMs (Qwen2.5-VL, Qwen2-Audio, Llama3.2-Vision, Llava, InternVL2.5, MiniCPM-V-2.6, GLM4v, Xcomposer2.5, Yi-VL, DeepSeek-VL2, Phi3.5-Vision, GOT-OCR2, ...).
- 命令行参数 — swift 3.1.0.dev0 文档


















 6034
6034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











