








前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学业升学和工作就业的先行者!
【优惠信息】 • 新专栏订阅前500名享9.9元优惠 • 订阅量破500后价格上涨至19.9元 • 订阅本专栏可免费加入粉丝福利群,享受:
- 所有问题解答
-专属福利领取欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!

一、分组卷积的基础原理
1. 传统卷积的瓶颈与挑战
在深度神经网络中,传统卷积层通过跨通道的全局交互提取特征,但其计算复杂度与参数量随通道数呈二次增长。比如输入有 256 个通道,输出 512 个通道时,每个输出通道都需要和所有输入通道 “互动”,这会导致参数量和计算量变得非常大,导致:
- 计算效率低下:GPU显存占用高,训练推理耗时
- 特征冗余:不同通道的特征提取缺乏结构化差异
- 过拟合风险:参数规模增长快于数据规模时容易过拟合
2. 分组卷积的核心机制与数学表达
分组卷积就像把一个大团队分成多个小团队,每个小团队只负责一部分工作。具体来说:
分组处理:把输入通道和输出通道分成若干组(比如分成 4 组),每组独立进行卷积操作。比如输入 256 个通道分成 4 组,每组 64 个通道;输出 512 个通道也分成 4 组,每组 128 个通道。
独立计算:每个小组的卷积核只处理自己组内的输入通道,生成对应的输出通道,组与组之间不交叉。
结果合并:最后把各个小组的输出结果合并,得到最终的特征图。
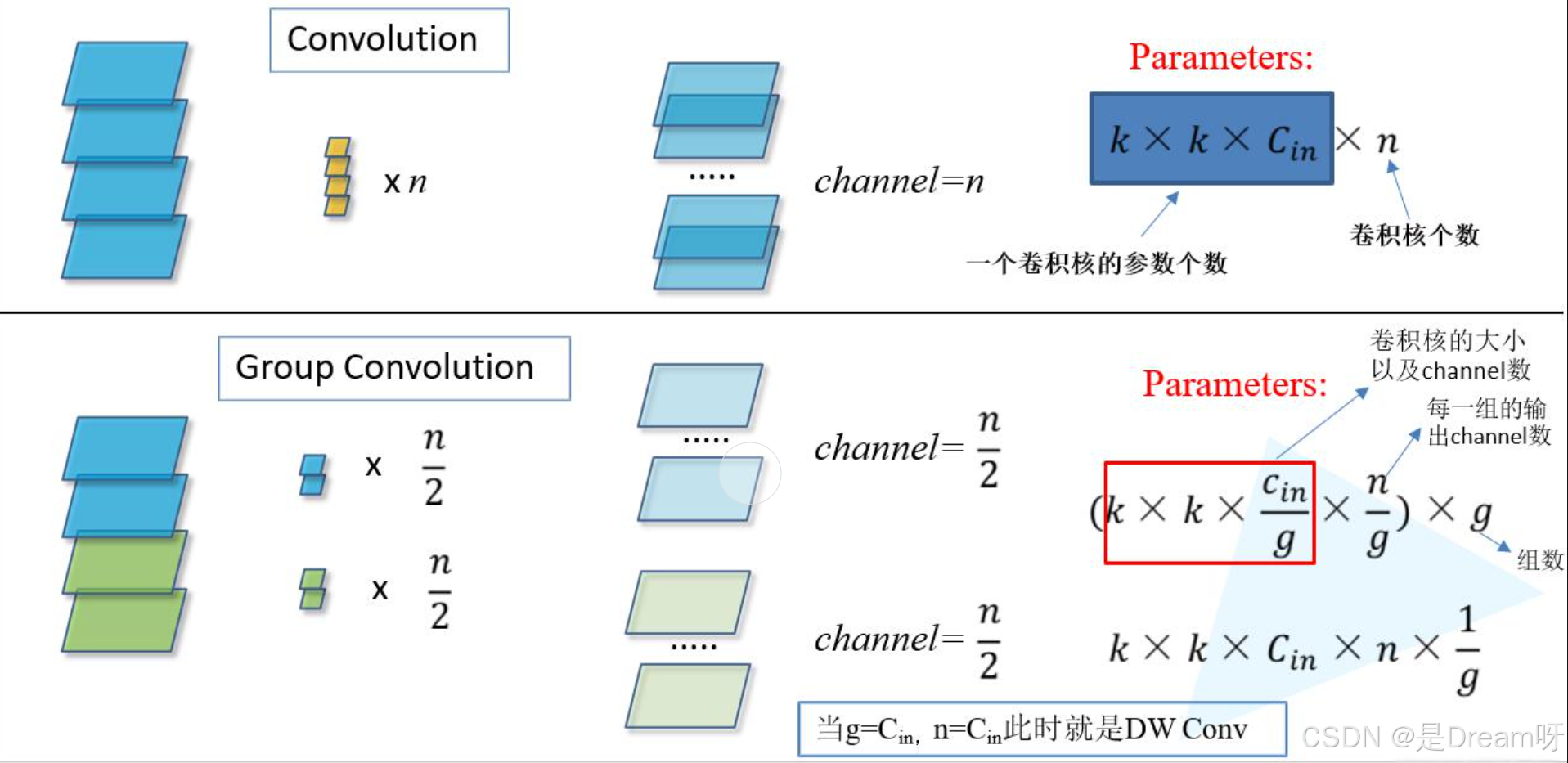
3. 分组卷积的技术优势
- 轻量化设计:通过通道分组显著降低计算复杂度,适配移动端设备
- 特征多样性:各组独立学习互补特征,避免不同通道间的冗余计算
- 隐式正则化:分组约束迫使模型学习更具判别性的局部特征,提升泛化能力
二、ResNext架构设计
1. 架构总览
ResNext在ResNet残差连接的基础上引入基数(Cardinality) 作为新维度,通过增加分组数 (G) 而非单纯扩大通道/深度,实现“宽度-深度-基数”的平衡。核心创新点:
- 同质化多分支结构:每个残差块包含 (G) 个并行的分组卷积路径
- 瓶颈层优化:结合1x1卷积进行通道降维/升维,进一步减少计算量
- 残差连接增强:跨分支特征聚合后通过残差连接保持梯度流通
2. 核心模块
2.1 基础单元
每个分支执行“降维-卷积-升维”的标准瓶颈操作:
# 单个分组卷积分支(以2D卷积为例)
nn.Sequential(
nn.Conv2d(in_channels, bottleneck_channels, 1, bias=False), # 降维
nn.BatchNorm2d(bottleneck_channels),
nn.ReLU(inplace=True),
nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size,
stride, padding, groups=G, bias=False), # 分组卷积
nn.BatchNorm2d(bottleneck_channels),
nn.ReLU(inplace=True),
nn.Conv2d(bottleneck_channels, out_channels, 1, bias=False), # 升维
nn.BatchNorm2d(out_channels)
)
- 降维因子:通常设为4(如256→64→256),进一步降低计算量
- 分组卷积层:显式指定
groups=G,实现通道分组计算
2.2 并行结构
ResNext Block将 (G) 个分支的输出沿通道维度拼接(或逐元素相加),这种设计使每个分支专注于局部通道组的特征提取,最终通过聚合获得全局感知能力。
2.3 残差连接
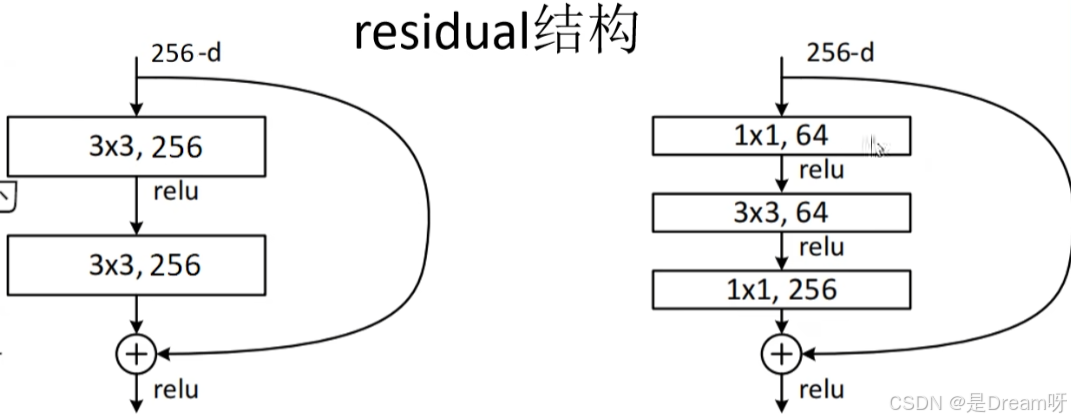
与ResNet一致,通过Shortcut路径处理维度匹配问题:
- 当输入输出通道数或分辨率不同时,采用1x1卷积或跨步卷积进行调整
- 避免梯度消失,支持深层网络训练
3. 网络层级结构
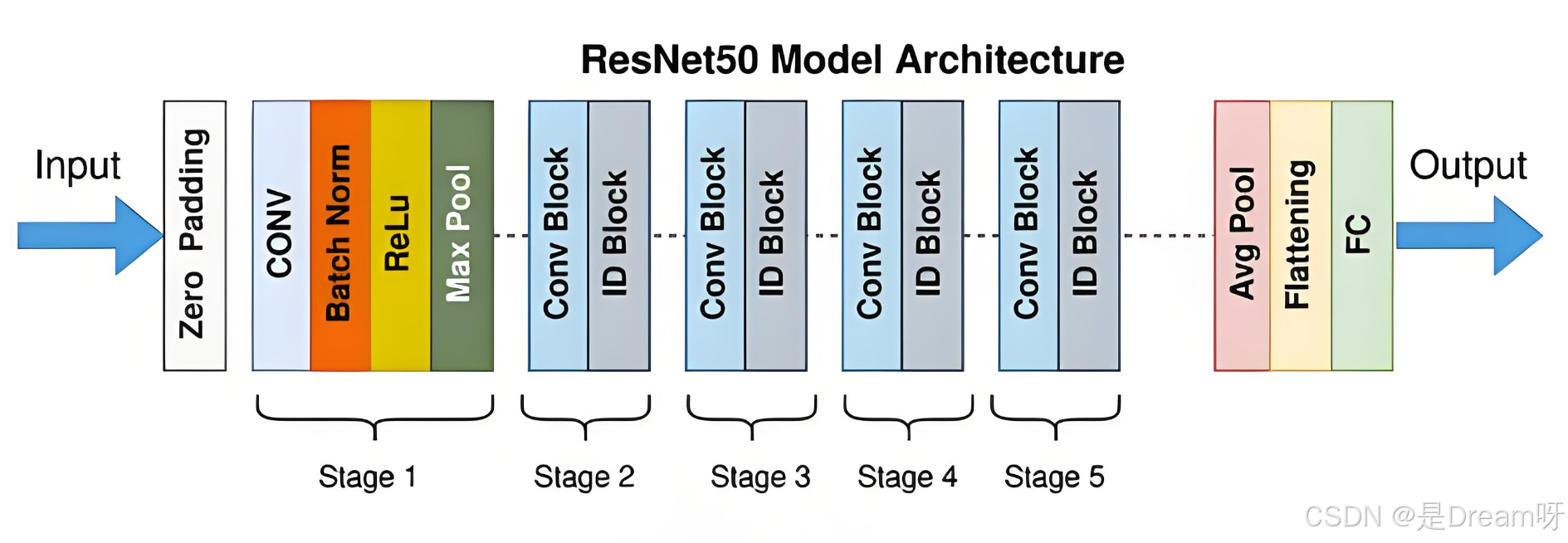
以典型的ImageNet分类架构为例,ResNext-50的层级配置如下:
| 阶段 | 输入尺寸 | 分组数 (G) | 通道数变化 | 模块数量 | 操作类型 |
|---|---|---|---|---|---|
| 输入层 | (224×224×1) | - | 3→64 | 1 | 7x7卷积+最大池化 |
| 残差层1 | (56× 56 × 64) | 32 | 64→256 | 3 | ResNext Block |
| 残差层2 | (28 ×28 ×256) | 32 | 256→512 | 4 | ResNext Block |
| 残差层3 | (14 ×14 ×512) | 32 | 512→1024 | 6 | ResNext Block |
| 残差层4 | (7 × 7×1024) | 32 | 1024→2048 | 3 | ResNext Block |
| 输出层 | (1 × 1× 2048) | - | 全局平均池化+全连接 | 1 | 分类预测 |
关键设计原则:
- 随着网络加深,通道数按比例增加(每次翻倍),空间尺寸减半
- 分组数 (G) 保持恒定,聚焦于基数对性能的影响
- 瓶颈通道数固定为输出通道的1/4,平衡计算效率与特征表达
三、代码实现深度解析
1. 分组卷积层的PyTorch实现
import torch
import torch.nn as nn
class GroupedConvolution(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1):
super(GroupedConvolution, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size,
stride, padding, groups=in_channels, bias=False)
self.conv2 = nn.Conv2d(in_channels, out_channels, 1, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv1(x) # 分组内卷积(通道不交叉)
x = self.conv2(x) # 跨组通道整合
x = self.bn(x)
return self.relu(x)
- 分组内卷积:通过
groups=in_channels实现每个输入通道独立卷积(等效于深度可分离卷积的深度层) - 跨组整合:1x1卷积实现组间信息交互,避免分组导致的特征隔离
2. ResNext Block的完整实现
class ResNextBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, groups=32, bottleneck_ratio=4):
super(ResNextBlock, self).__init__()
bottleneck_channels = out_channels // bottleneck_ratio
self.groups = groups
# 主路径:G个并行分支
self.group_convs = nn.ModuleList([
nn.Sequential(
nn.Conv2d(in_channels, bottleneck_channels, 1, bias=False),
nn.BatchNorm2d(bottleneck_channels),
nn.ReLU(inplace=True),
nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size,
stride, (kernel_size//2), groups=1, bias=False), # 组内卷积
nn.BatchNorm2d(bottleneck_channels),
nn.ReLU(inplace=True),
nn.Conv2d(bottleneck_channels, out_channels, 1, bias=False)
) for _ in range(groups)
])
# Shortcut路径
self.shortcut = nn.Sequential()
if in_channels != out_channels or stride != 1:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# 并行分支计算
group_outputs = [conv(x) for conv in self.group_convs]
main_path = sum(group_outputs) # 等价于通道拼接后逐元素相加
# 残差连接
shortcut_path = self.shortcut(x)
return nn.ReLU(inplace=True)(main_path + shortcut_path)
-
层级设计:
- 每层通过
Block实现,通道数按1→64→128→256→512增长,每次翻倍 - 序列维度(如时间步/图像高度)通过
stride=2的卷积逐层减半(128→64→32→16→8)
- 每层通过
-
自适应池化:
AdaptiveAvgPool2d((1, train_shape[-1])):无论输入序列长度如何,池化后序列维度为1,特征维度(如9)保持不变,适配不同长度的输入(如时间序列的不同时间步)
-
全连接层:
- 输入维度为
512 * 特征维度(如512*9),将多维特征展平为向量,映射到类别数(如10类)
- 输入维度为
3. 分组卷积与深度可分离卷积对比
| 指标 | 分组卷积(Grouped Conv) | 深度可分离卷积(Depthwise Separable Conv) |
|---|---|---|
| 分组方式 | 输入/输出通道等分组 | 输入通道分组(单通道卷积+点卷积) |
| 组间交互 | 需1x1卷积显式整合 | 点卷积(1x1)隐式整合 |
| 参数量压缩比 | (1/G) | (1/C_out + 1/C_in) |
| 特征多样性 | 高(多组独立特征) | 中(单通道处理后整合) |
| 典型应用 | ResNext、SqueezeNet | MobileNet、Xception |
四、UCI-HAR数据集实战结果
ResNet 靠增加层数和通道数提升性能,而 ResNext 通过增加 “基数”(分组数),用更高效的方式提升效果,同等性能下模型更轻便。残差连接保留了 ResNet 的优势,即使网络很深,也能通过跨层连接保持梯度传递,训练更容易收敛。下面,我们以UCI-HAR数据集为例,展示ResNext的实际应用及其结果。
UCI-HAR 数据集由加州大学尔湾分校实验团队构建,是行为识别领域的经典基准数据集。其数据采集依托三星 Galaxy S2 智能手机内置的加速度计与陀螺仪传感器,以 50Hz 的采样频率记录人体运动特征。该数据集包含 30 名年龄在 19-48 岁的受试者,通过腰部佩戴设备完成六种日常活动:步行、上楼、下楼、静坐、站立和静躺。本研究采用滑动窗口技术对原始数据进行预处理,设置窗口长度为 128 个采样点,滑动步长 64 个采样点(即 50% 的窗口重叠率),最终形成 748,406 个样本单元。

1.训练结果
基于空洞卷积的模型在PAMAP2数据集上的性能如下表所示:
| Metric | Value |
| Parameters | 1,007,686 |
| FLOPs | 104.65 M |
| Inference Time | 6.53 ms |
| Val Accuracy | 0.9946 |
| Test Accuracy | 0.9883 |
| Accuracy | 0.9883 |
| Precision | 0.9886 |
| Recall | 0.9883 |
| F1-score | 0.9884 |
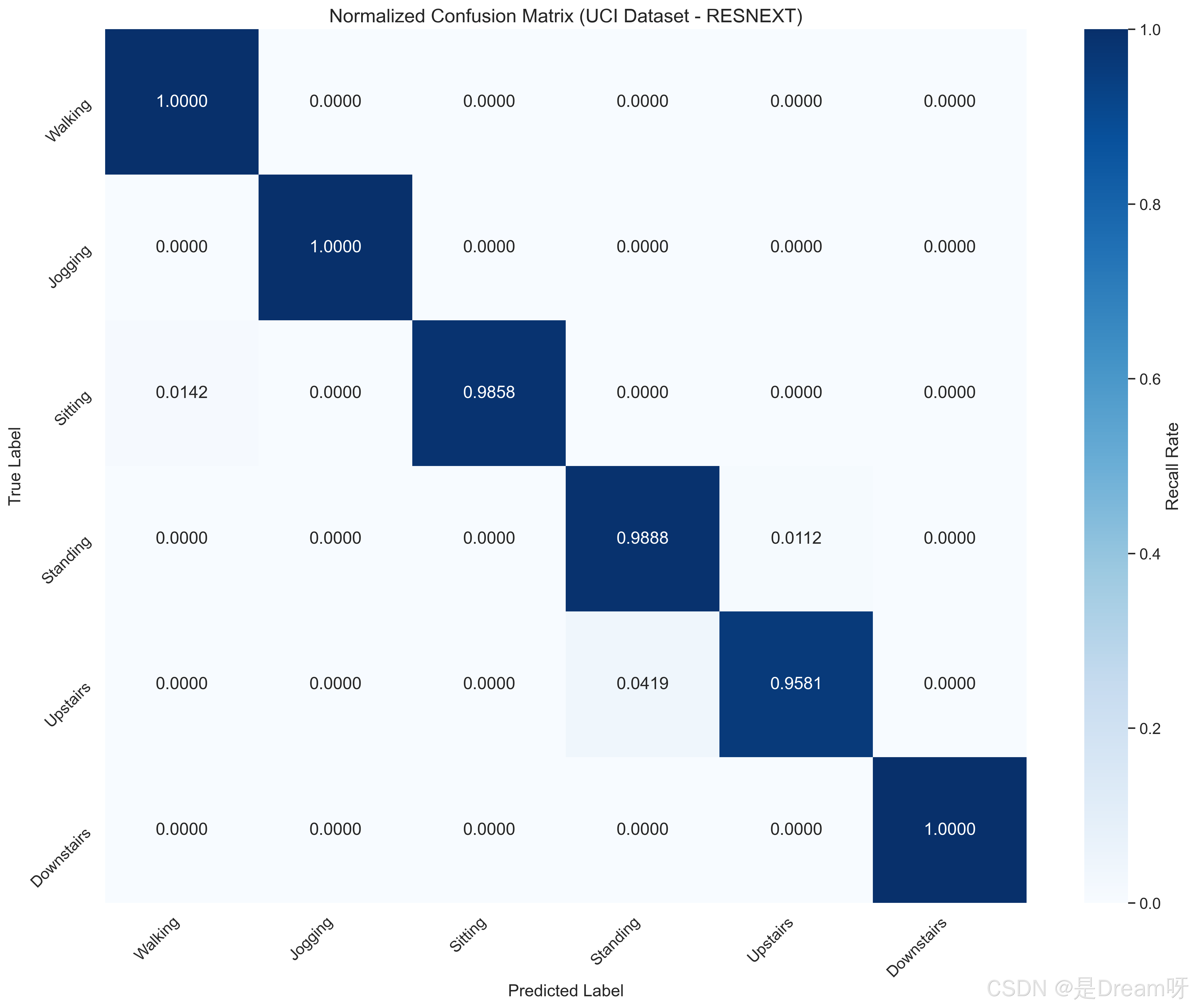
2.每个类别的准确率
每个类别的准确率:
Walking: 1.0000
Jogging: 1.0000
Sitting: 0.9858
Standing: 0.9888
Upstairs: 0.9581
Downstairs: 1.0000
模型在简单动作(如 Walking、Downstairs)上表现优异,准确率接近 1;对静态或相似动作(如 Sitting、Standing)的区分准确率超过 0.98,体现了分组卷积对结构化特征的高效提取能力。对于空间动作幅度较大的 Upstairs,准确率稍低,可能与时间序列维度的特征对齐精度有关。
3.混淆矩阵图及准确率和损失曲线图
ResNext 在 UCI数据集上的分类性能通过标准化混淆矩阵可视化,矩阵行代表真实标签,列代表预测标签:
训练过程中,ResNext 的训练集与验证集指标表现如下:

训练损失在 50 个 epoch 内降至 0.05 以下,验证损失同步下降,最终稳定在 0.06 左右,表明模型收敛充分且泛化能力强。
总结
ResNext 通过分组卷积与残差连接的结合,通过结构化设计,让模型在有限资源下实现更高效的特征学习,尤其在时序行为识别任务中展现出对结构化数据的强大建模能力,这一思想将继续启发后续的轻量化网络设计。实验结果表明,模型在简单动作上实现了接近完美的分类,对相似动作的区分能力也优于传统卷积架构。
文末送书
参与方式
免费包邮送三本! Dream送书活动——第六十一期:《巧用DeepSeek快速搞定数据分析》、《Revit+Navitworks项目实践》
参与方式:
1.点赞收藏文章
2.在评论区留言:人生苦短,我用Python!(多可评论三条)
3.随机抽取3位免费送出!
4.截止时间: 2025-04-30
上期中奖名单:糜加诚和钟鸿森、m0_74568892、思维交错
本期推荐1:《巧用DeepSeek快速搞定数据分析》《巧用DeepSeek快速搞定数据分析》
数据分析重构指南:覆盖数据采集→清洗→建模→可视化等8大核心环节全流程解析,50多种高效方法+200多行业级代码片段即改即用+15种数据难题秒级解决方案,助你在AI驱动的数据科学中攀登巅峰。

京东:https://item.jd.com/14995198.html
1.全栈:覆盖数据采集→清洗→建模→可视化8大核心环节全流程解析。
2.极速:解锁15种数据难题秒级解决方案,效率提升300%。
3.智能:深度集成20+前沿AI算法,实现数据分析自动化跃迁。
4.实战:200+行业级代码片段即改即用,涵盖金融、电商、社交等6大领域。
5.突破:首度公开DeepSeek在时序预测、图像分析、文本挖掘等5大创新应用。
内容简介
本书是一本关于数据分析与DeepSeek应用的实用指南,旨在帮助读者了解数据分析的基础知识及如何利用DeepSeek进行高效的数据处理和分析。随着大数据时代的到来,数据分析已经成为现代企业和行业发展的关键驱动力,本书正是为了满足这一市场需求而诞生。
本书共分为8章,涵盖了从数据分析基础知识、常见的统计学方法,到使用DeepSeek进行数据准备、数据清洗、特征提取、数据可视化、回归分析与预测建模、分类与聚类分析及深度学习和大数据分析等全面的内容。各章节详细介绍了如何运用DeepSeek在数据分析过程中解决实际问题,并提供了丰富的实例以帮助读者快速掌握相关技能。
本书适合数据分析师、数据科学家、研究人员、企业管理者、学生及对数据分析和人工智能技术感兴趣的广大读者阅读。通过阅读本书,读者将掌握数据分析的核心概念和方法,并学会如何运用DeepSeek为数据分析工作带来更高的效率和价值。
本期推荐2:《Revit+Navitworks项目实践》《Revit+Navitworks项目实践》
解锁新版Revit+Navisworks,打造高效建筑设计,用于实际项目!

京东:https://item.jd.com/14415945.html
1.全流程BIM实战指南:从基础建模到施工模拟,完整覆盖BIM设计与施工的全流程,轻松应对从设计到落地的每一个环节。
2.真实项目驱动,学以致用:案例源自实际工程项目,紧密结合行业需求,不仅学习理论知识,更可以直接应用于实际项目。
3.从建模到施工,深度解析:详细讲解Revit和Navisworks的软件操作,全面提升BIM实战能力。
4.手把手教学,可操作性强:步骤清晰、讲解详细,让读者在动手实践中快速掌握软件技术,轻松上手。
5.解决工程痛点,提升效率:通过模型校审、碰撞检查、动画模拟等功能,提前发现设计问题,优化施工流程,减少工程返工,显著提升项目效率与质量。
内容简介
本书以 Revit+Navisworks 为软件平台,以项目需求为指引,将软件功能和真实案例进行融合以用于实际。
本书由一个完整的工程项目为主线,结合大量的可操作性实例,全面而深入地阐述了 Revit 2024 从基础建模到模型应用的全过程 BIM 应用。包括规划体量、创建各类建筑图元构件、效果图渲染、后期虚拟漫游、模型校审、碰撞检查、动画模拟、施工模拟等由BIM 设计到施工的全部过程。全书共有 13 章,前 7 章分别介绍各个版块的建模命令;第 8章介绍了基于 Revit 的渲染工作;第 9~13 章详细描述了 Navisworks 在项目中如何实现模型校审、碰撞检查、施工模拟等一系列工作。讲解清晰,实例丰富,避免了枯燥的理论,使读者可以有效地掌握软件技术,从而应用实际项目。
本书结构清晰,案例操作步骤详细,语言通俗易懂。所有案例均为实际工程案例,更加贴合实际工作需要,且都具有相当高的技术含量,实用性强,便于读者学以致用。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











