









Fence
1 前言
在Linux Kernel共享同步机制中,dma-fence扮演着重要角色,GPU的Render操作可能涉及到对多个buffer的引用,而共享buffer的存在难以确保这些buffer不被其它驱动程序占用,因此使用dma-fence向各共享设备来sync buffer状态以防止deadlock产生。在Android中资源同步框架称之为Android Sync Framework,主要用于处理跨硬件场景,如CPU、GPU、HWC之间的buffer资源同步,同样也依赖于kernel中共享机制dma-fence。本文对fence概念及流程进行一个总结,以方便后续的debug。
参考文章:
翻译:Mainline Explicit Fencing
Android中的GraphicBuffer同步机制-Fence
简图记录-android fence机制
Bringing Android explicit fencing to the mainline
dma-fence: dma-buf synchronization
Synchronization Framework
2 Implicit Fence与Explicit Fence
Kernel buffer 共享同步机制以kernel space是否将同步信息给user space分为Implicit Fence与Explicit Fence,下图展示了两种Fence机制的体现过程。

左边为Implicit Fence,该种形式fence只在kernel space中传输,Compositior只能等待A、B两块buffer完成绘制渲染,才能将两者合成至Buffer C拿去送显,而一旦A、B两块Buffer中有一块没有完成渲染,就会导致Jank,发生冻屏。右边为Explicit Fence,在创建Buffer的同时,创建一个fence,并将fence sync给Compositior,待A、B其中某一个Buffer实现渲染,Compositor就能够开始合成,从而避免Implicit Fence所带来的Jank事件。Android Sync Framework就是在AOSP上Explicit Fence上的实现方案。

Explicit Fence是一种生产者-消费者模型,对比到以GPU渲染的系统中,GPU这一侧就是生产者,Display就是消费者。在以timeline为横向时间轴上,GPU渲染完成会将fence signal,再sync给正在wait fence的display,display拿到fence后完成buffer读取上屏显示。上屏显示后,就会将buffer的描述符给到GPU,GPU开始wait fence,等待Display显示完成,swapBuffer时,将Buffer fence给signal,并sync给GPU,GPU再开始渲染。整个一个过程既能确保一定的pipeline,又能确保buffer一致性。
3 Android Sync Framework
Fence的实现可以由硬件实现(Graphic driver),也可以由软件实现(Android kernel中的sw_sync),而归根结底都是在内核态完成的。在fence中,有三个重要的概念:sync_timeline、sync_pt、 sync_fence,了解清楚这个三个概念,对于fence怎么起作用的也能基本清楚了。
3.1 Sync Timeline
(1)单调递增计数器
(2)使用在每一个驱动上下文之中(如 GL 上下文、屏幕控制器或 2D 位块传送器)
Sync Timeline对应时间轴,会记录针对特定硬件提交给内核的作业数量,如customer每使用完一个buffer就会timeline++
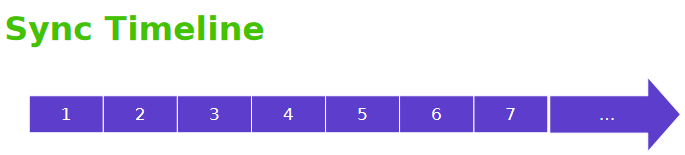
3.2 Sync Point
(1)为sync_timeline 上的特定点的值,意为同步时间点。
(2)有三种状态:Active(刚创建时状态)、Signal(图像消费方不再需要缓冲区)、Error
sync_pt以tree形式挂载在sync_timeline上,告诉SF这个时间点之前都需要进行同步。
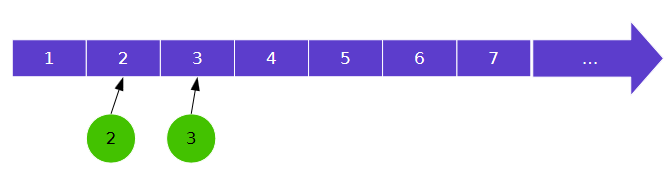
3.3 Sync Fence
(1)本质为linux file
(2)一系列sync_pt的集合,一个sync_pt只属于一个sync_fence,一个sync_fence可以包含来自不同各sync_timeline的sync_pt,且fence可以合并。这句话的理解需要对sync_timeline的创建有一定认识,前面说过sync_time使用在每一个驱动上下文之中,意味着每一个driver想要读写buffer,必须创建一个自己的sync_timeline,这导致对于同一buffer在不同driver上的sync_pt不一致,跟不同driver拿到的fd不一致相同,而其中某一个driver想要读写这块buffer,必须等待fence singal,意味着其它所有的drivers必须singal pt,所以sync_fence必须包含这些drivers的sync_timeline上的sync_pt,组成一个集合。

理解了上面的概念,对于fence可以合并就不足为奇了,下图展示了merge后的fence。

3.4 Fence初始化
刚刚有提到fence跟fd有相同之处,其实在内核初始化fence时,就为每一个fence绑定了一个fd,通过fd来实现user与kernel之间的转移。例如:Display拿到将要显示的buffer时,就会创建fence和与之对应的fd,并将fd给到生产者,由生产者来监听fd,看fence是否被signal。内核初始化sync_timeline是比较简单的(基于kernel 4.14),大致的过程如下(具体代码分析将在下一章展开),sync_timeline以链式结构展开,其中包含一个树形结构以添加sync_pt,同时为每个sync_pt去get dma-fence,并绑定fd。Producer与Consumer通过fd来wait fence。

4 Fence在Android中的体现
fence用于GraphicBuffer的同步在“Android中的GraphicBuffer同步机制-Fence”中写的非常好,我这里只做一个总结,并结合systrace来体验这个过程。
Android显示过程总结起来就是“APP UI绘制buffer -> 将buffer交由GPU完成渲染 -> 由SurfaceFlinger控制合成 -> 交由Display上屏显示”的过程,这一整个过程中,都会涉及到同一块GraphicBuffer的操作,因此需要为GraphicBuffer添加上Fence来完成同步。这一阶段涉及BufferQueue流程与合成流程,这不是本文的重点,不作过多分析,在后续文章中也只会提及涉及fence操作相关的部分。但为了便于理解接下来的部分,这里先对合成流程与fence时机做一个简单说明。GraphicBuffer是由App端作为生产者进行绘制,然后放入到BufferQueue,等待消费者来完成渲染与合成,并最终将buffer放入HWC的Layer list中的。虽说Buffer最终的去处一致,但若Buffer需GPU合成,还是会多一个BufferQueue的流程。

4.1 fence的流转
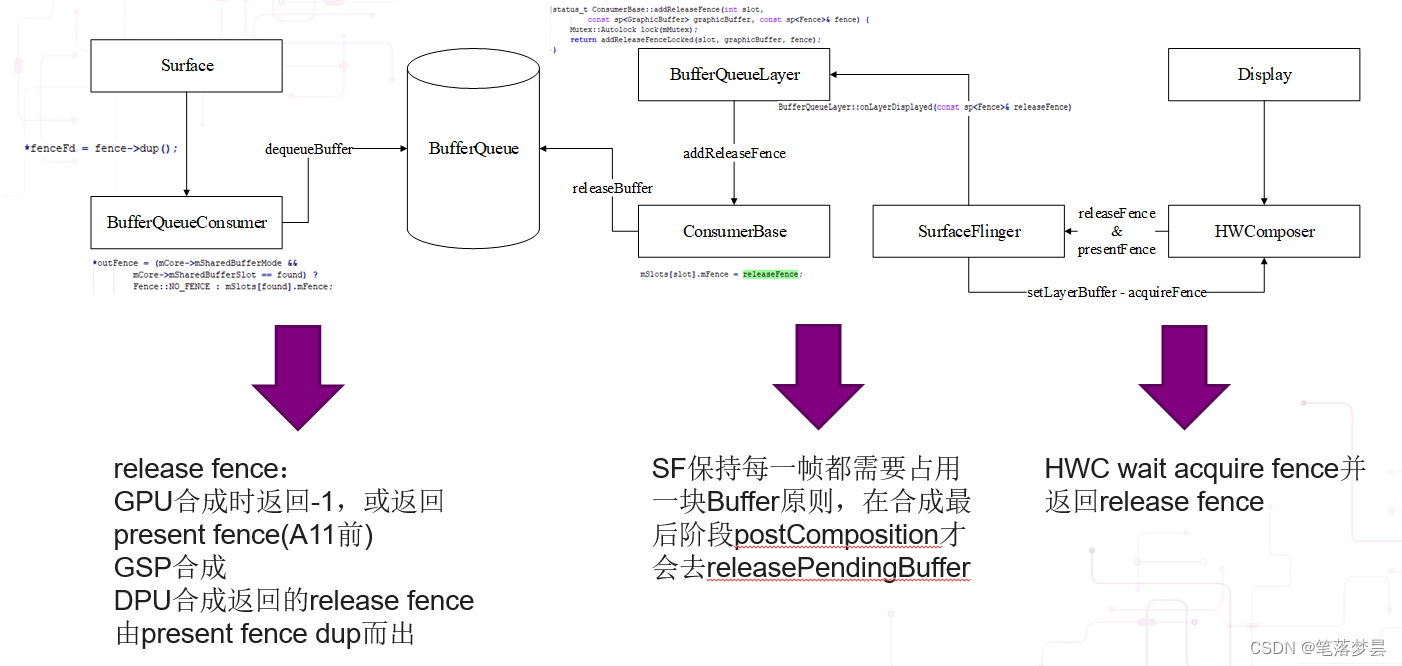
4.2 Systrace中Fence的体现
acquire fence:
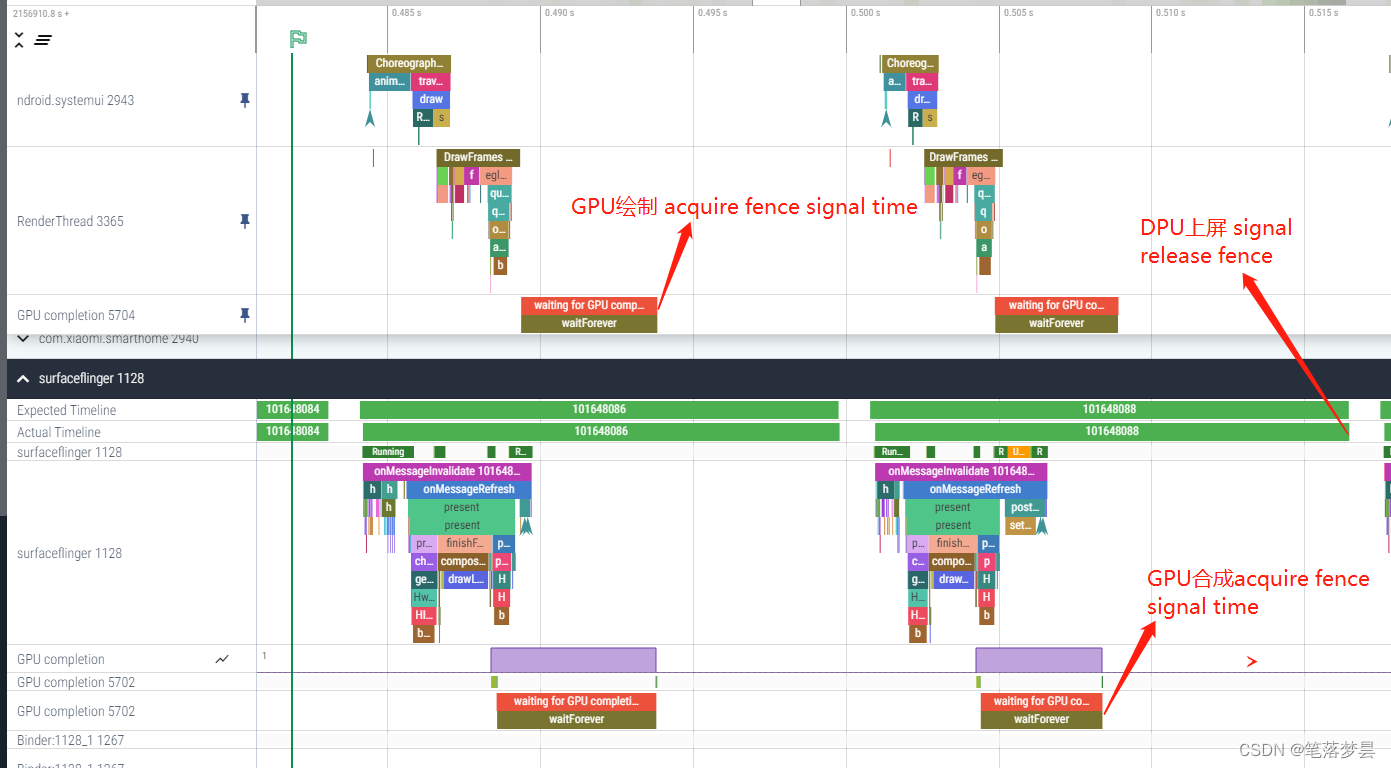
release buffer:

5 Debug Fence
在工作中,需要进行fence debug的场景多见于显示异常,如花屏、闪屏等,这有可能是fence错乱导致,通过可以在BufferQueue中dequeueBuffer或acquireBuffer、HWC侧每一层Layer的validate或present强等fence看问题是否消失,或辅助利用ioctl读出buffer物理地址,看是否同时读写同一块buffer数据。















 3925
3925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









