







详细教程见B站UP——Nenly同学
作者整合的知识库:https://nenly.notion.site/nenly/017c3341c8b84a7ebb4c2cb16f36e28f?v=8d3885a8404b4f27a998d03b23a87f19
本博文仅作为学习记录
基础部分
AI绘图的过程与原理
-
过程即为(Diffusion-Generate),简单一幅图表达
训练:图片 → 潜空间(latent space)压缩 → 对比式语言-文字预训练(CLIP,Contrastive Language-Image Pretraining)实现内容匹配 → 借助GAN提高学习准确度 …

Stable-Diffusion(SD)
参考博文:SD本地安装部署
-
Stable-Diffusion:一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。GitHub开源地址:https://github.com/Stability-AI/stablediffusion
-
stable-diffusion-webui:基于 Stable Diffusion 的基础应用,利用 gradio 搭建出的交互程序。 我们需要部署的就是stable-diffusion-webui。GitHub开源地址:https://github.com/AUTOMATIC111
B站UP(@秋葉aaaki)做的整合包:https://www.bilibili.com/video/BV1iM4y1y7oA
Text-to-Image和参数设置
正面promot后添加:
(masterpiece:1.2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2), drawing, paintbrush,
反向promot汇总:
NSFW,(worst quality:2),(low quality:2),( normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),
以上提示词广泛适用于二次元风格,可以考虑搭配不同模型使用!
好用的生成提示词网站:
- http://www.atoolbox.net/【还有一些好用其它在线工具】
- https://ai.dawnmark.cn/
-
“魔咒”

通用模板:

给某个词套上(),权重会*1.1,以此类推,n个()嵌套即为1.1^n。如(sunny)、((sunny));
或者通过(sunny:1.5)直接定义它的权重

注意:权重不要设置过高/过低。
1±0.5最佳
不知道如何描述时,可以使用Image-to-Image的反推提示词功能(DeepBooru的速度和准确度占优势)

其中,CLIP全称为Contrastive Language-Image Pre-Training(对比性语言-图像预训练模型),是 OpenAI 在2021 年初开源的一个用文本作为监督信号来做预训练的模型,可以缓解/解决以上问题。能在无任何微调的情况下(zero-shot ),在 ImageNet 数据集上的分类表现超 ResNets-50 微调后的效果。 -
SD参数设置
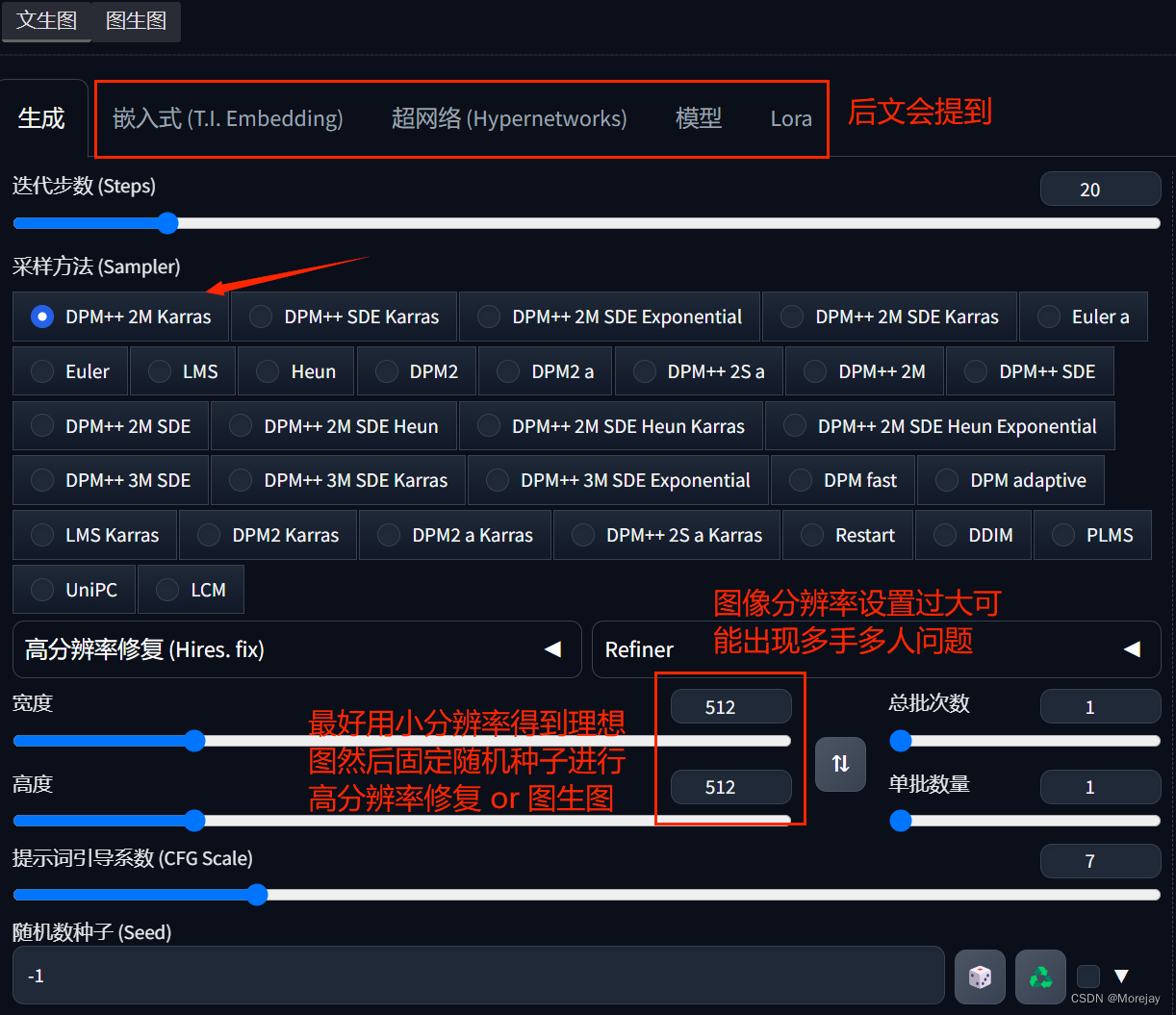
Image-to-Image入门
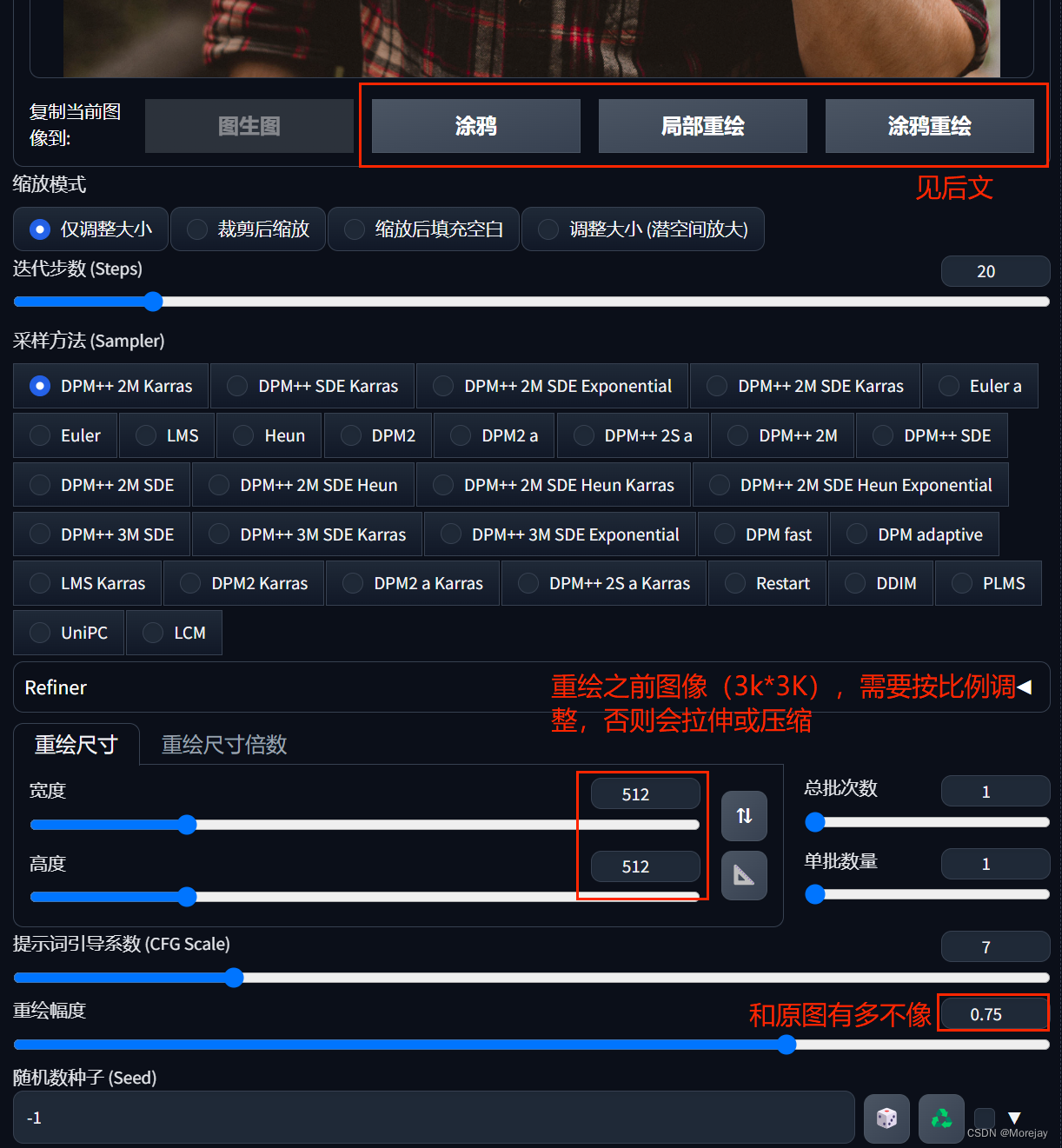
需要注意:
- 重绘幅度(Denoising)——过高与原图无联系,过低看不出效果(
0.5±0.1最佳)- 图像宽高——尽量保持与原图一致或者与原图一致的比例(若原图过大可能导致显存OOM);否则会按照
缩放模式选项重绘图像尺寸。- 随机种子——想要在一副较为满意的图上使用Promot微调,设置随机种子避免“抽卡”式生成。
模型概念、应用及来源
模型主要分为几种:
- 基础的Stable Diffusion模型(一般有
.ckpt和.safetensor格式) - VAE(Variational Auto Encoder):负责将加噪后的潜空间数据转化为正常图像(可以理解为加“滤镜”,影响画面的色彩质感)
- 此外,还有用于画面微调的
hypernetwork,优化画风的Embeddings和固定人物角色特征的LoRA(Low-Rank Adaptation)


- 二次元类
- 真实类
- deliberate,精细全面的写实风,XpucT
- LOFI,精致的照片级人像专精
- Realistic Vison,写实人像,SG_161222
- 2.5D类
- NeverEnding Dream,适合将二次元人物“三次元化”,Lykon【该作者的DreamShaper也很出名】
- Protogen x3.4(Photorealism),优秀的照片效果和创意发挥空间,darkstorm2150
- 国风3 GuoFeng3,实现“文化输出”的精致国风模型,xiaolxl
图像修复和放大算法
为什么需要这个步骤?
比如生成一张2.5D或者真实类的图像,放大后的质感、纹理细节都不行。原因在于SD的分辨率设置太低(设置太高显存会OOM),AI没有足够多的操作空间让图像细节栩栩如生。

-
高分辨率修复(Text-to-Image)



-
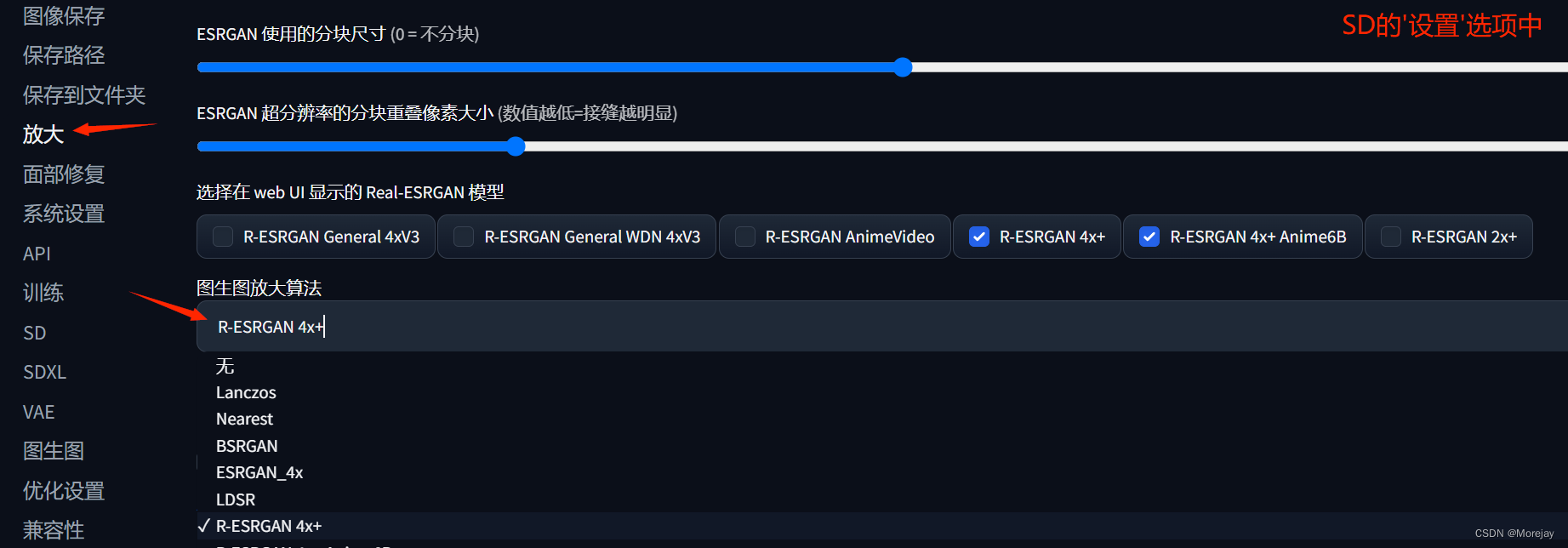
Upscale脚本(图生图放大)
适用于图生图的普遍细节优化,但细节较为“不可控”。(分几块画然后拼在一起)
优势:- 可以突破显存限制获得更大分辨率的图像(最高可达4倍宽高)
- 画面精细度高,对细节的丰富效果出色
缺陷:
- 分割重绘的过程较为不可控(语义误导和分界线割裂)
- 操作频繁且相对不直观
- 偶尔“加戏”出现预料之外的元素
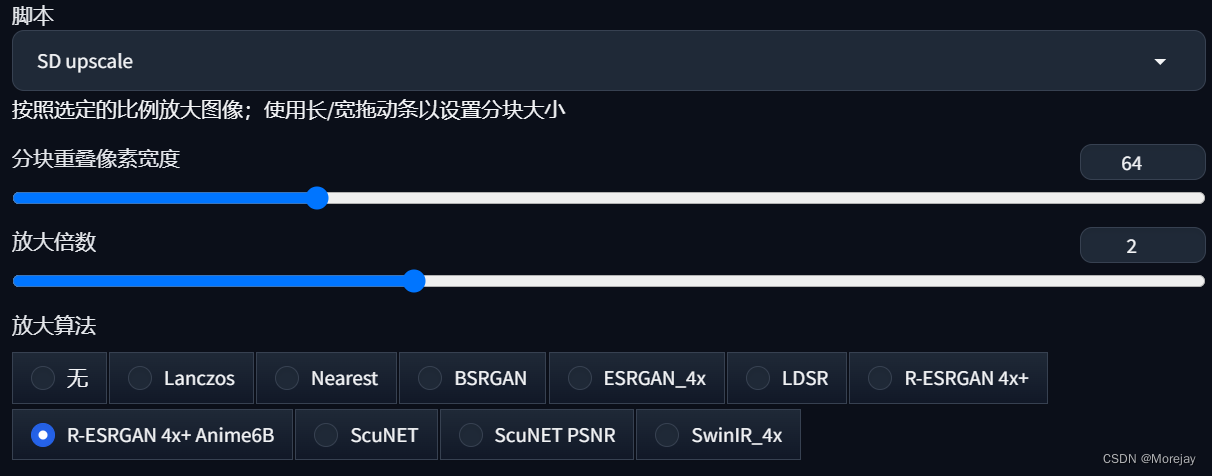
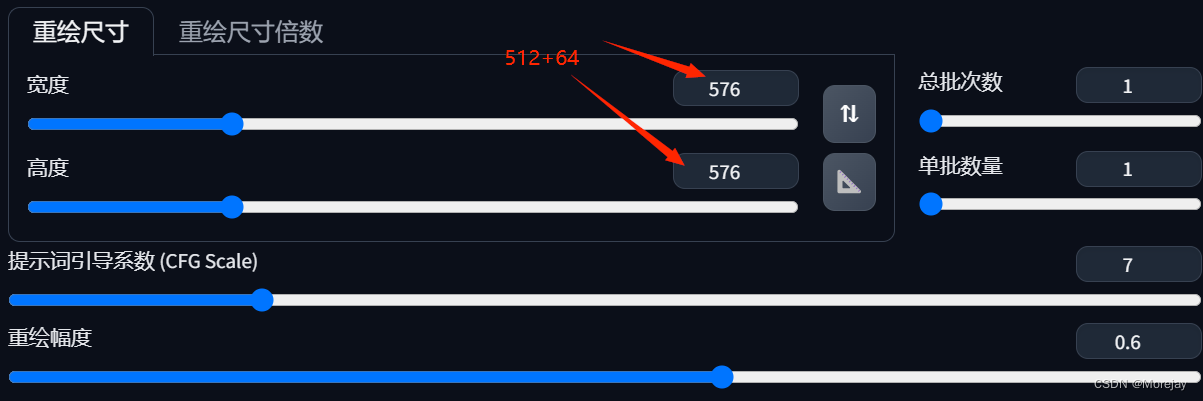
注意:如果物体(人脸、身体)恰好处在分界线上,有概率产生不和谐的图像。
解决方法:降低重绘幅度(denosing [0.3 ~ 0.5])或者增大图块重叠像素(32 → 64/128)
其实可以通过将原图再Image-to-Image,并调整分辨率的方式重新生成
-
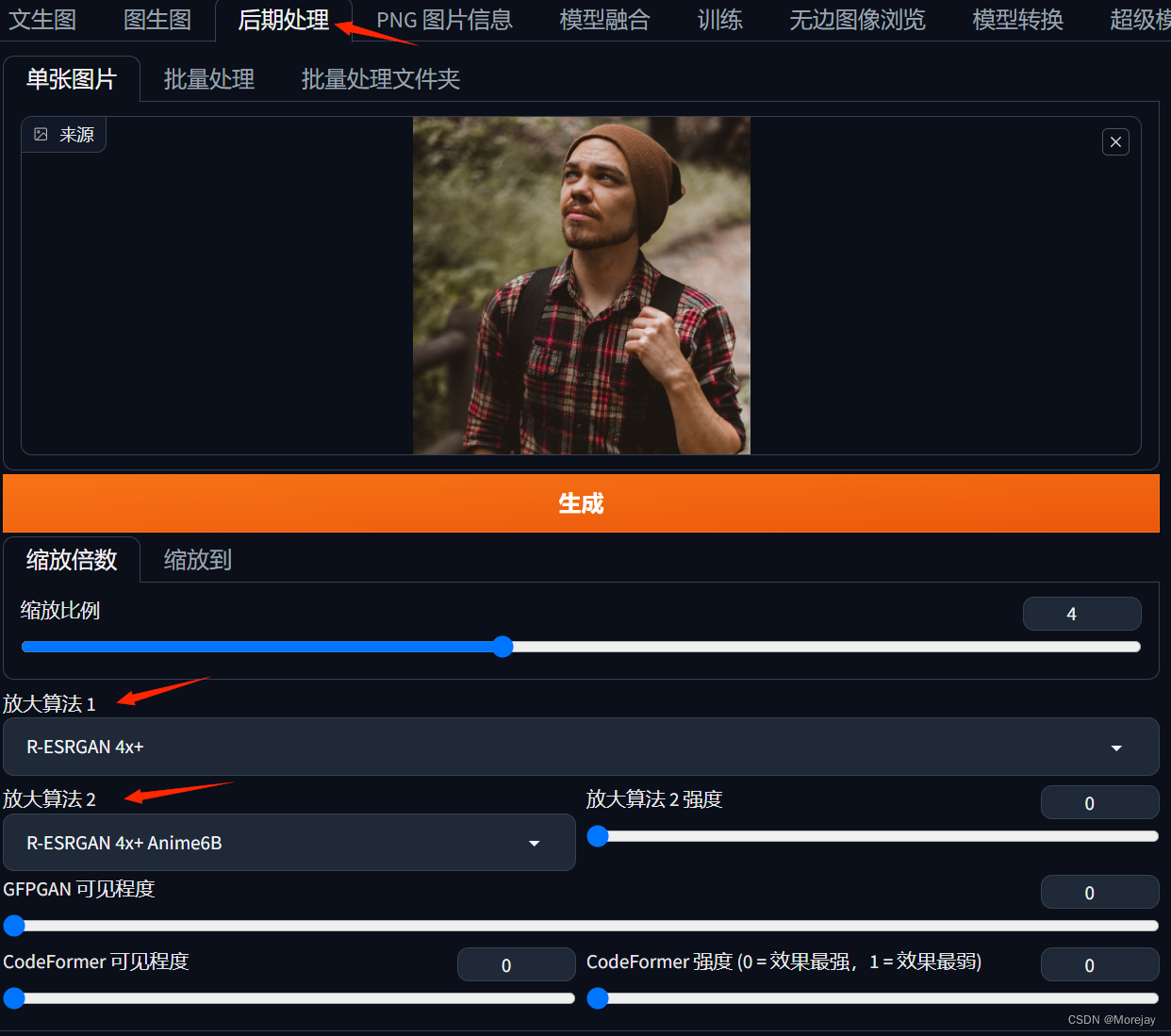
后期处理——图片放大算法
用于对生成后的图像进行处理(重绘幅度为0的高清修复)
AI绘画进阶模型

-
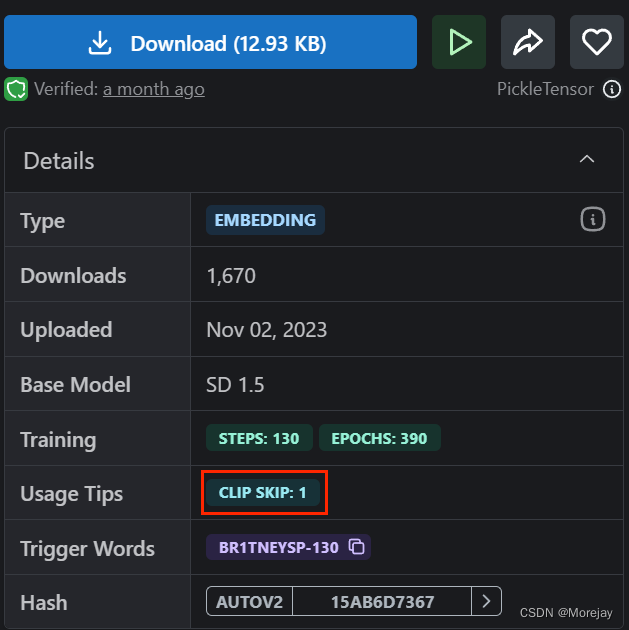
Embeddings
比较常用的游戏任务设计三视图:CharTurner
一般很小,KB级别,权重文件放在
embeddings目录下。checkpoint——字典;embeddings——书签。
使用时加入对应“魔咒”即可
C站排名靠前的几个embeddings,记录AIGC的一些“痛点”,避免出现类似问题。
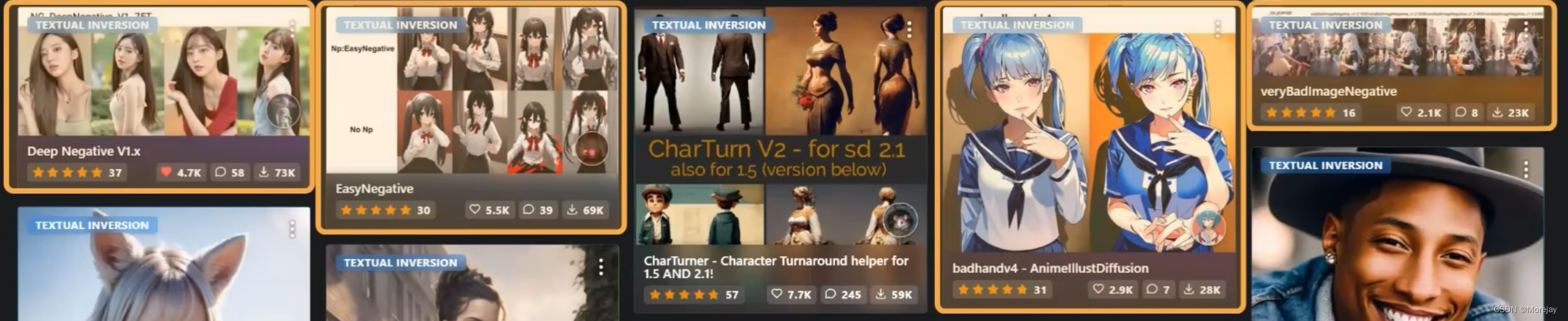
使用CharTurner的效果图
## 正向prompt
a character turnaround of a (corneo_dva) wearing blue mecha bodysuit,(CharTurnerV2:1.2),(multiple views of the same character with the same clothes:1.2),((character sheet)),(model sheet),((turnaround)),(reference sheet),
masterpiece,best quality,1 girl,brown hair,brown eyes,smile,standing,dynamic pose,outdoors,city background,corneo_dva,
(blue:1.4) bodysuit,long hair,pilot suit,solo,facepaint,headphones,gun,holding weapon,swept bangs,clothes writing,bunny print,breasts,animal print,bracer,white gloves,shoulder pads,high collar,
white footwear,pink lips,handgun,skin tight,light smile,
为了避免画风崩坏或者画手问题,在负面prompt加入EasyNegativeV2

- LoRA
LoRA的作用在于帮助你向AI传递、描述某一个特征准确、主体清晰的形象。因此C站有各种人物角色特定的LoRA模型。
MB级别,前文类比embeddings——书签,那么LoRA——彩页(详细记录对象的定义、特点及呈现方式等)
对比图:
从左到右依次为 1. LoRA、2. Embedding、3. 两者都无

- Hypernetwork
一般用于改善生成图像的整体风格(画风),比
checkpoint定义的画风更为精细
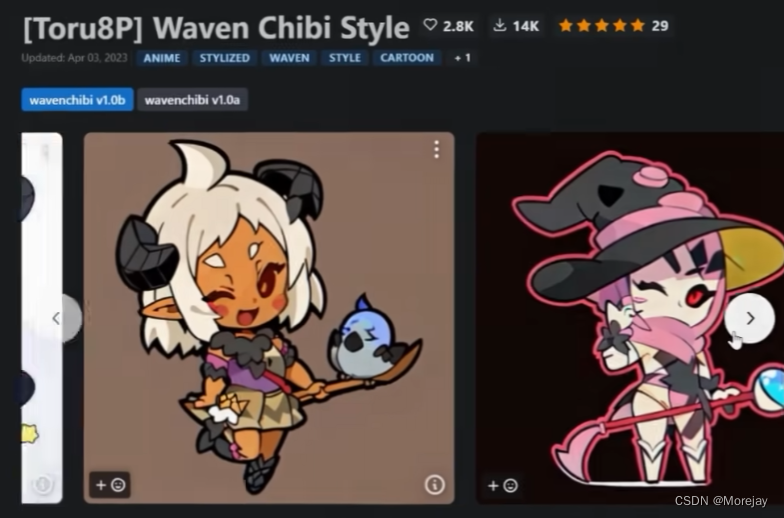
如何使用?
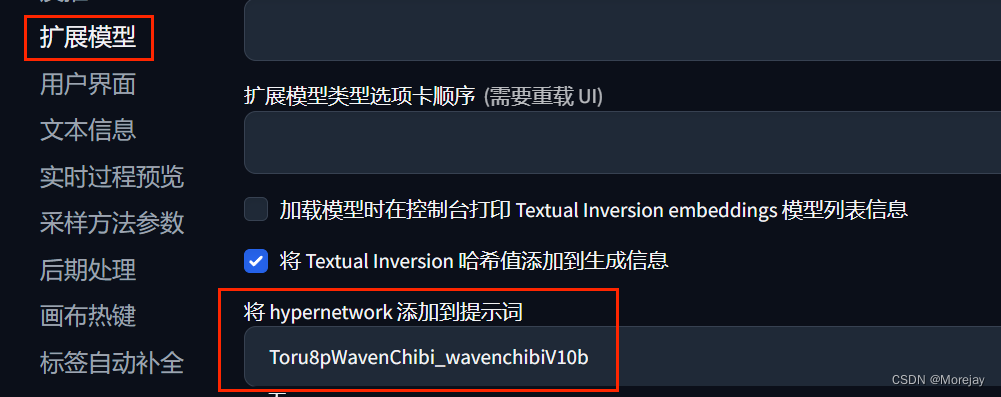
正向prompt:
masterpiece,best quality,1 girl,brown hair,brown eyes,smile,standing,dynamic pose,
(blue:1.4) bodysuit,long hair,pilot suit,solo,facepaint,headphones,gun,holding weapon,swept bangs,clothes writing,bunny print,breasts,animal print,bracer,white gloves,shoulder pads,high collar,
white footwear,pink lips,handgun,skin tight,light smile,
# 影响画风的主要prompt
chibi,(pink background:1.5),cute,kawaii,<lora:dVaOverwatch_v3:1>,
效果图:
左为使用Embedding和LoRa,右为不使用

局部重绘
一张图像局部整体符合条件,但是局部不佳(比如四肢错位、手异常), 通过局部重绘解决该问题。

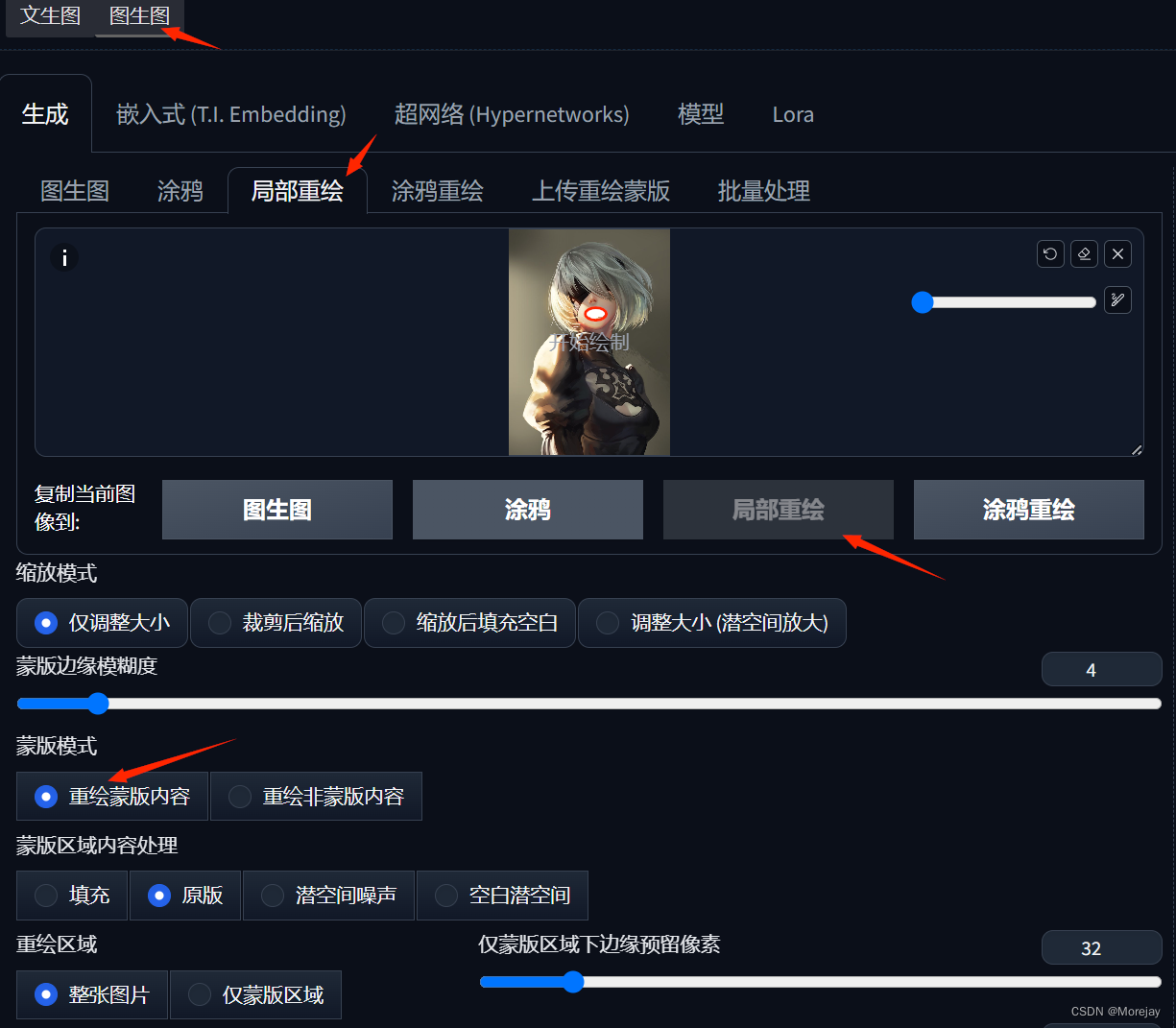
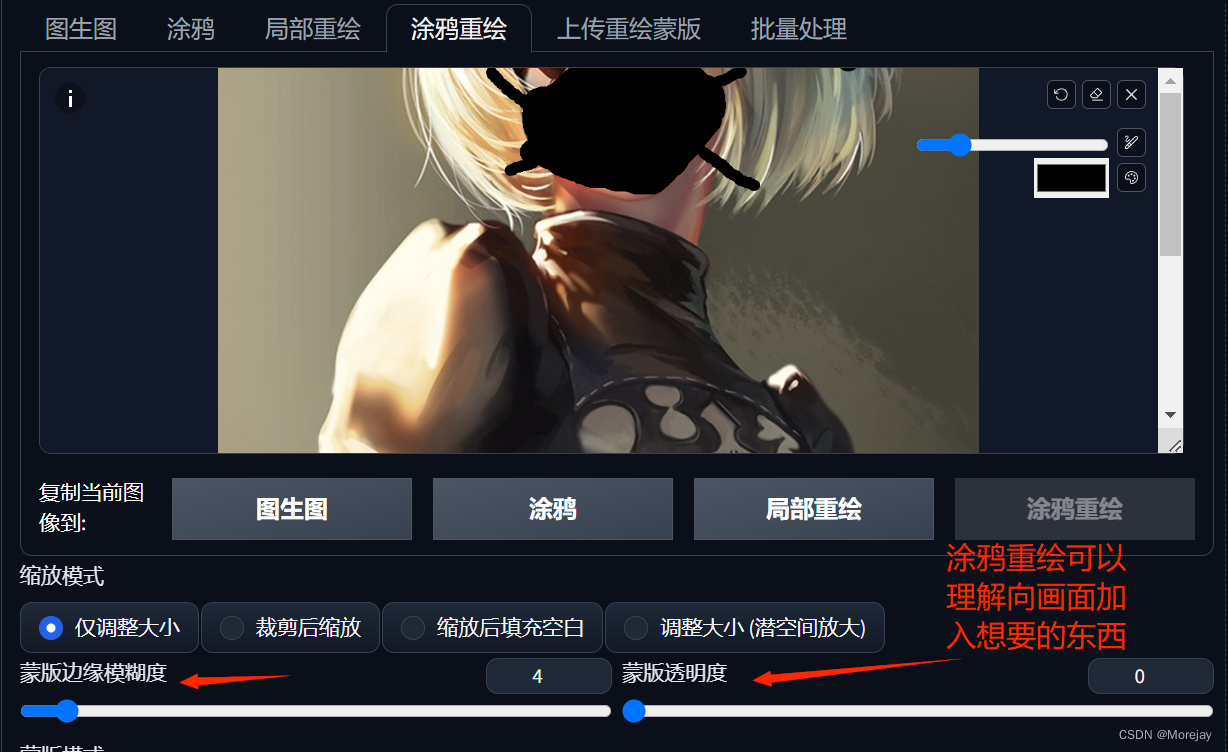
涂鸦重绘
正向提示词要加入
(blue face mask with heart sign:1.2)
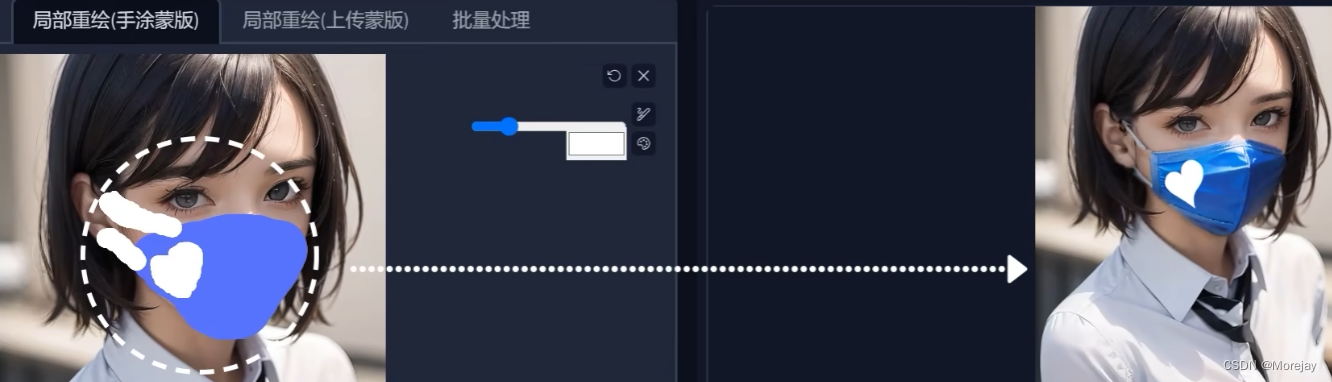
上传重绘蒙版功能最好使用PS,得到黑白对比色的蒙版图像。
或者使用Segment Anything插件。
扩展插件
扩展查阅地址:
https://github.com/AUTOMATIC1111/stable-diffusion-webui-extensions/blob/extensions/index.json
-
中文语言包
搜索:zh(取消勾选本地化/Localization的筛选)
仓库地址:https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans -
图库浏览器
搜索:image browser
仓库地址:https://github.com/AlUlkesh/stable-diffusion-webui-images-browser -
提示词补全
搜索:tag complete
仓库地址:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete -
提示词反推
搜索:tagger
仓库地址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger -
Ultimate Upscale脚本
搜索:ultimate upscale
仓库地址:https://github.com/Coyote-A/ultimate-upscale-for-automatic1111 -
Local Latent Couple
搜索:llul
仓库地址:https://github.com/hnmr293/sd-webui-llul -
Cutoff
搜索:cut off
仓库地址:https://github.com/hnmr293/sd-webui-cutoff -
Infinite Zoom
搜索:Infinite Zoom
仓库地址:https://github.com/v8hid/infinite-zoom-automatic1111-webui
LoRA
最早由微软团队提出,用于解决大语言模型的训练问题。
论文阅读:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
与DreamBooth的差异:https://zhuanlan.zhihu.com/p/694921070
对于需要添加特定元素的图片:

ControlNet入门
基本原理
膜拜大佬
- 论文:Adding Conditional Control to Text-to-Image Diffusion Models
- 项目地址:https://github.com/lllyasviel/ControlNet
博客解读:ControlNet原理+代码解析
安装与使用
安装好之后,文生图界面出现选项卡:
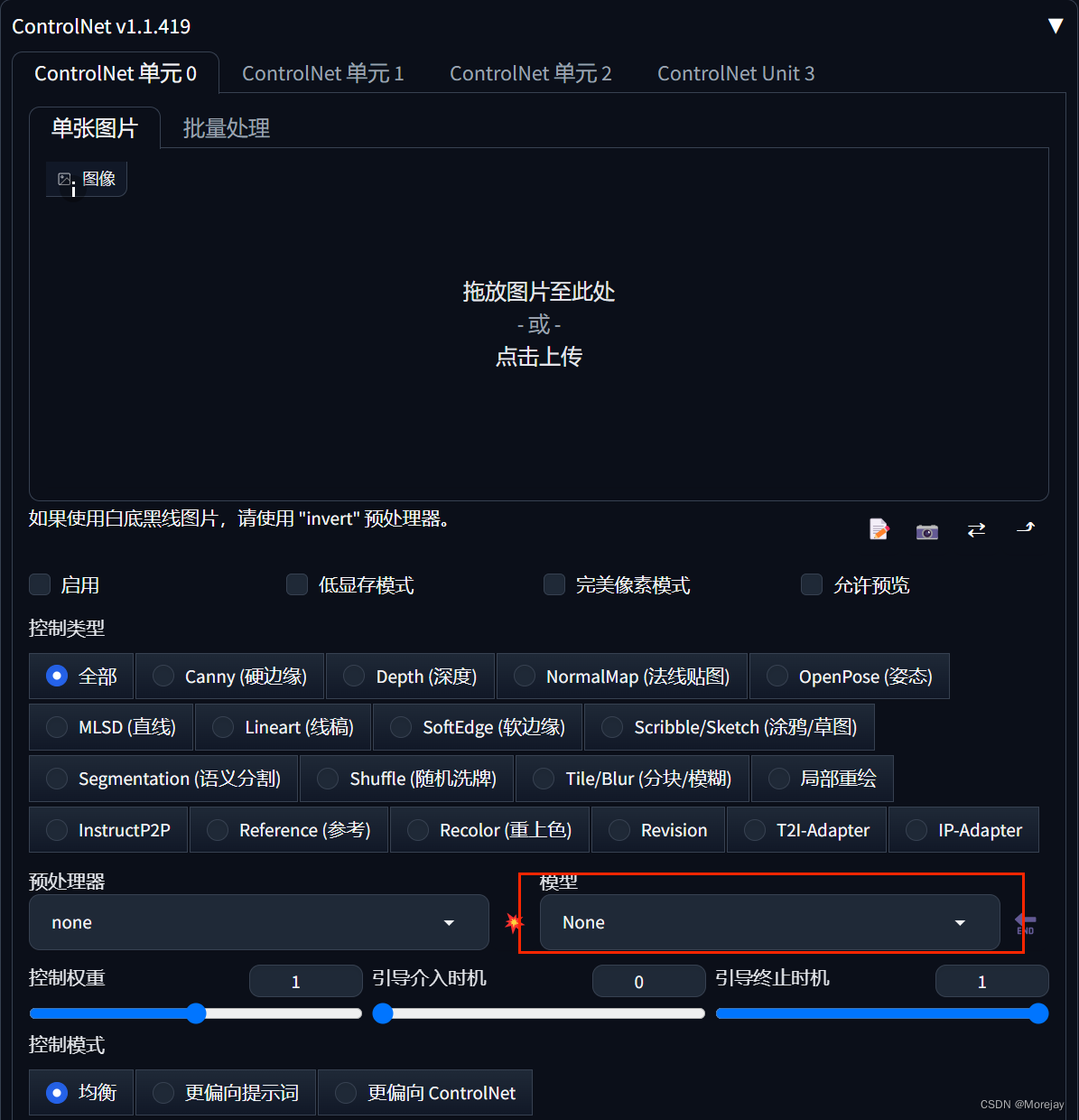
需要下载模型!
五大模型

模型安装位置:
注意:.pth权重文件与配置文件.yaml成对出现,同样的命名
实操示例
# prompt
sfw,absurdres,1girl,mature female,ocean,smile,naval_uniform,
# negative prompt
nsfw,(worst quality:1.2),(low quality1.2),(lowres),monochrome,greyscale,multiple views,extra limb,animal ears,pointy ears,(EasyNegativeV2),ng_deepnegative_v1_75t,
使用相同的提示词,一次生成多张,可以看到,姿势不同

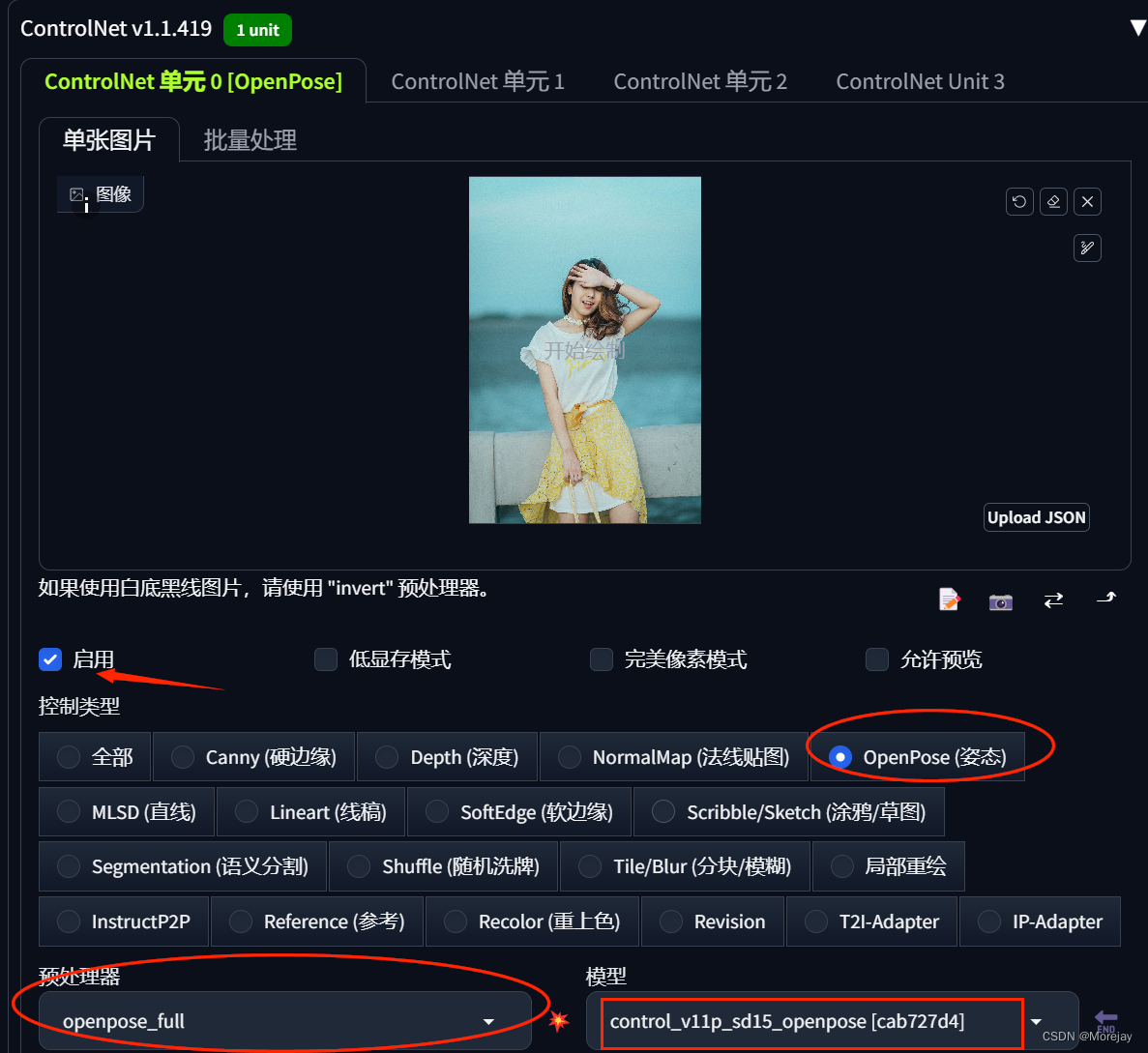
借助ControlNet,使用openpose,按照下面的模板图片可以生成固定姿势的图像

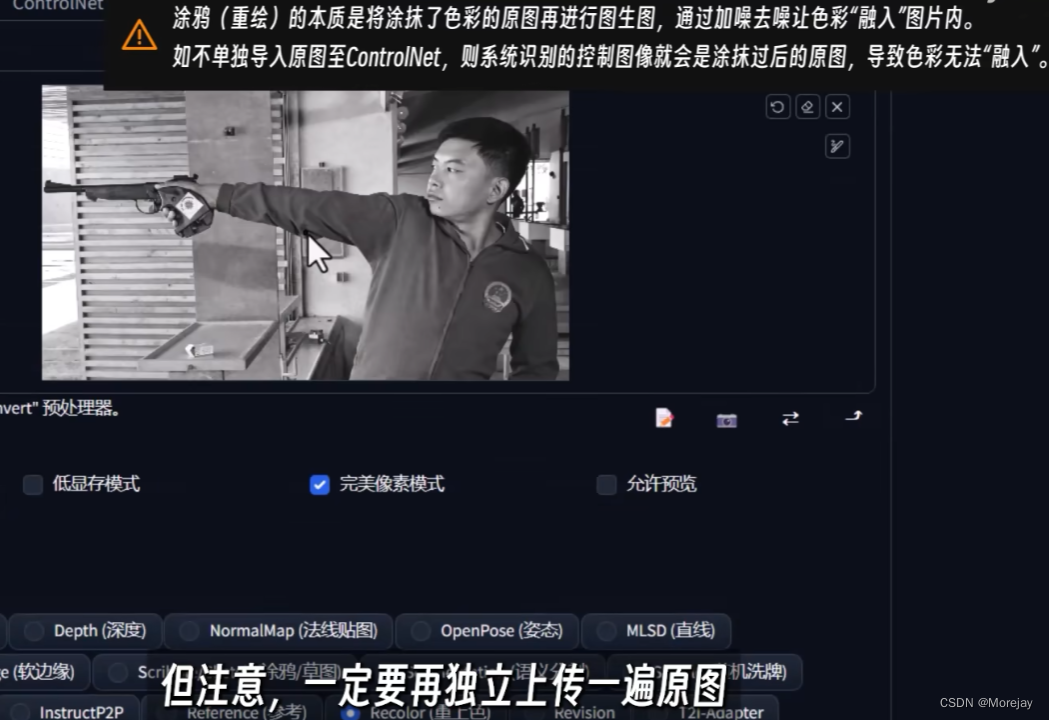
注意:开启ControlNet需要经过额外的一次图片处理过程,比如这个示例中需要先运行openpose提取关键点骨架,还要对图片进行预处理。因此在“启用”选项旁提供了“低显存模式”。
关于“完美像素模式”,它可以自动计算预处理器产出的图像最适合的分辨率,避免因为尺寸不合导致的图像模糊变形。
结果图:

参数解释:
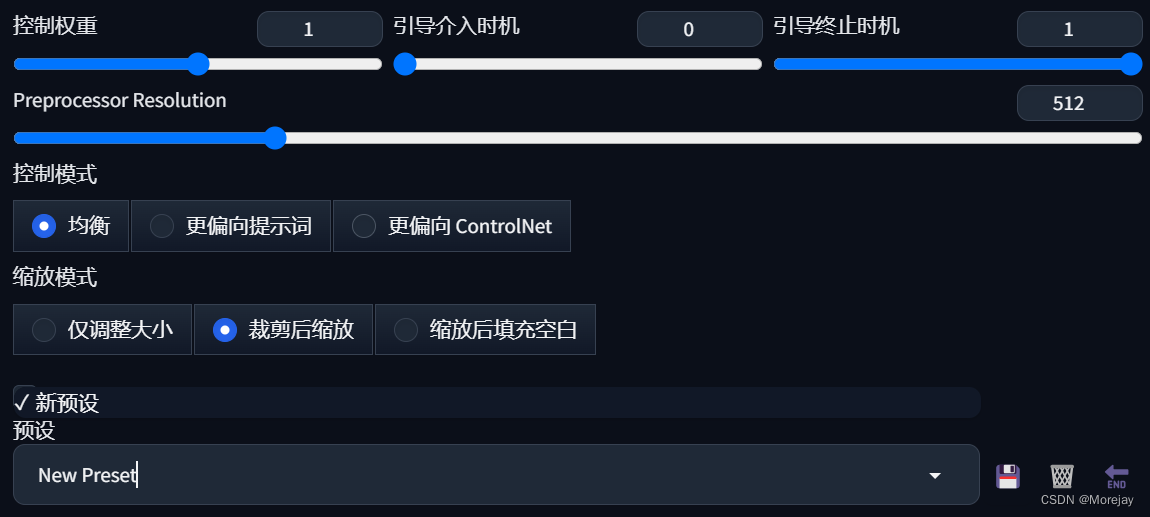
- 控制权重:一般维持默认1不变
- 引导接入/终止时机:在图像扩散中什么时候加入ControlNet的条件影响?默认0和1表示从头到尾生效。可以略微增大接入时机(赋予图像更多自由度)
- 控制模式:prompt与ControlNet的倾向
- 缩放模式:在导入图片和生成图像尺寸不匹配时起作用
“爆炸”图标:
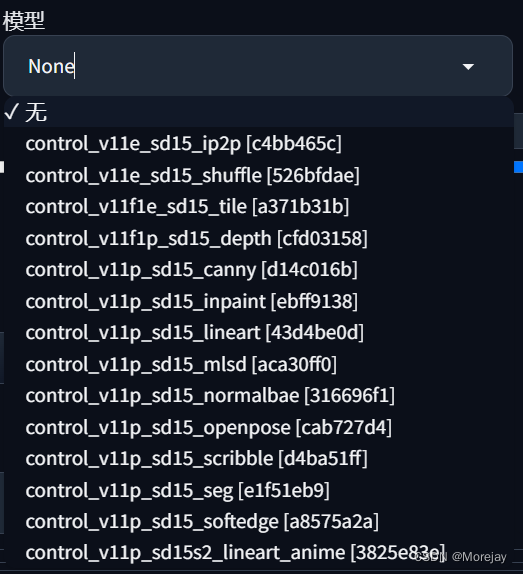
预览预处理结果,生成关键点骨架图,可以将其保存到本地,像使用正常图片一样(不过不用再使用预处理器了,此时可以将“预处理器”设置为None)
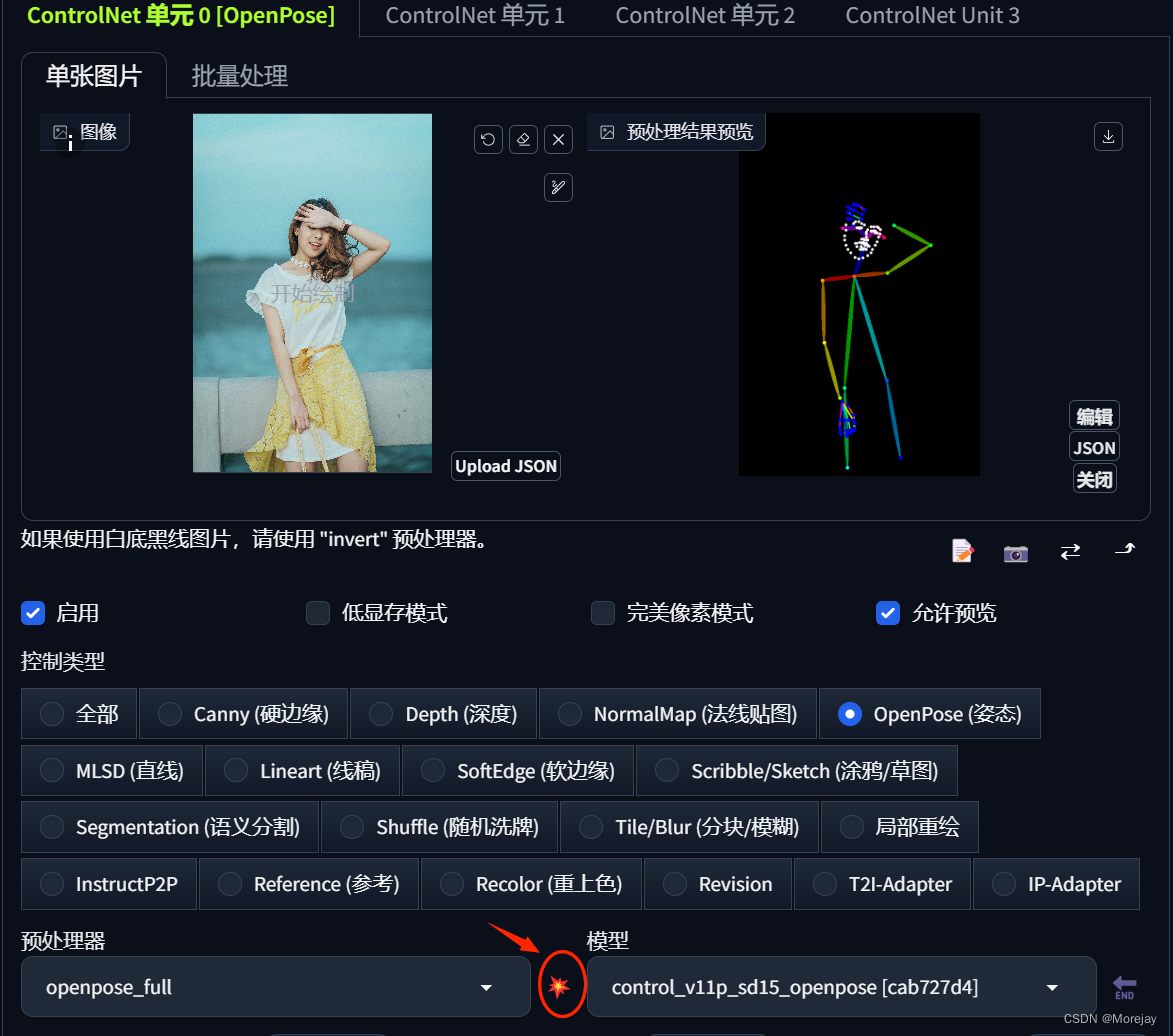
结果图存在的问题:模板图的手放在脸前,生成图的手都是在后面
可以尝试Depth解决(以下图的手臂交叉为例)
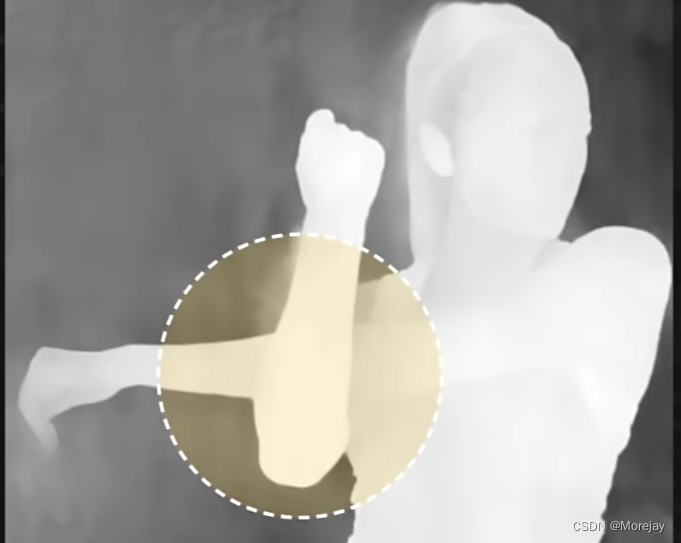
- Depth还可以用来解决建筑设计的场景纵深问题
- Canny用于提取图像的精细边缘,还原细节;同样地,为线稿上色也是Canny的一个方向
- Scribble用于把涂鸦或者随手勾勒得线条转变为艺术画作,本质上还是基于(Canny和Depth等)
多重ControlNet


使用多重ControlNet解决手不出现在人物脸前的问题:

注意:多重ControlNet对显存要求更高!
进阶部分
在前面的基础部分,介绍了AI绘图的过程和原理,我们学会了Text2Img、Img2Img生成图像,了解到SD的几个模型概念以及微调方式,为了让Web-UI功能更加完善,我们还使用了多个插件扩展;关于LoRA和ControlNet的使用,我们也通过实际操作有所了解。
下面,介绍一些关于SD的一些进阶应用,用于扩展自己的知识面。
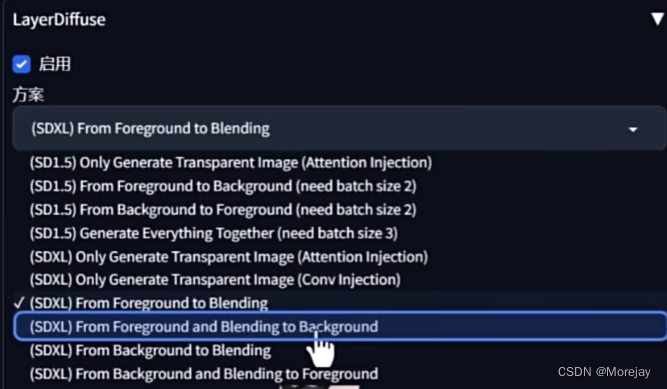
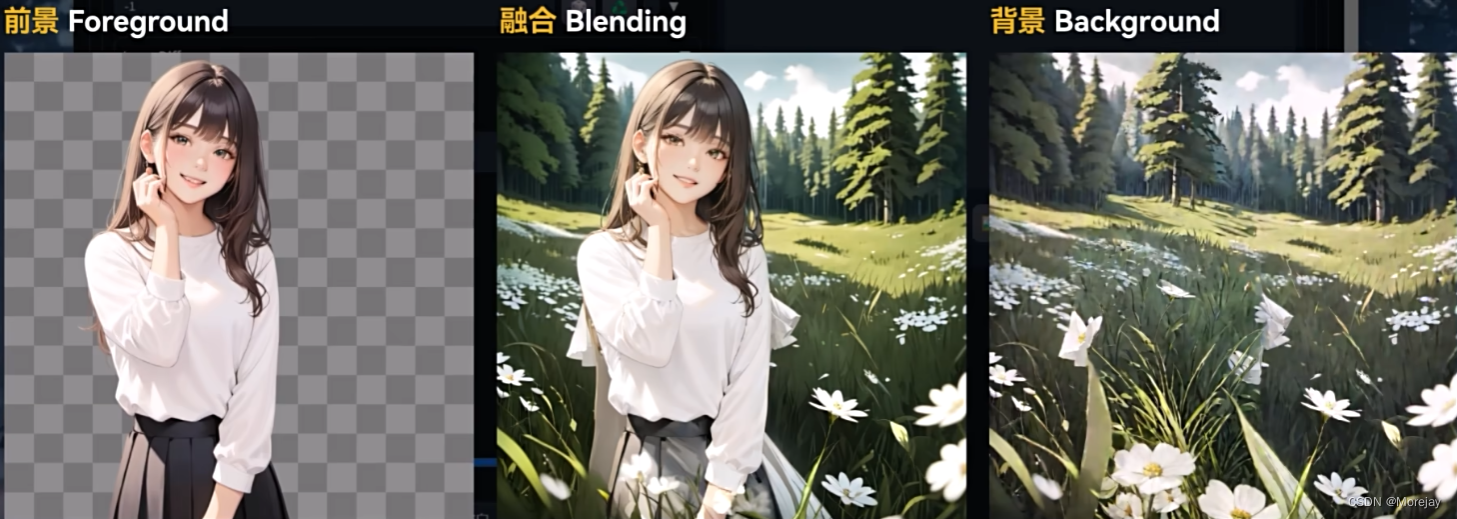
Layer Diffusion
主要是为了解决SD生成的图像无法分离主体,往往需要繁重的后期工作对其进行拆解,得到一张张透明背景的主体PNG图像。在生成阶段就将透明通道的信息加入运算。

作者是ControlNet的大佬(Lvmin Zhang)
安装步骤
-
通过源代码安装(无Web-UI)

-
通过Web-UI“扩展”界面安装

可以生成半透明(玻璃的透视效果)的物体图片!!
更换前景背景可以更方便
Tailed Diffusion
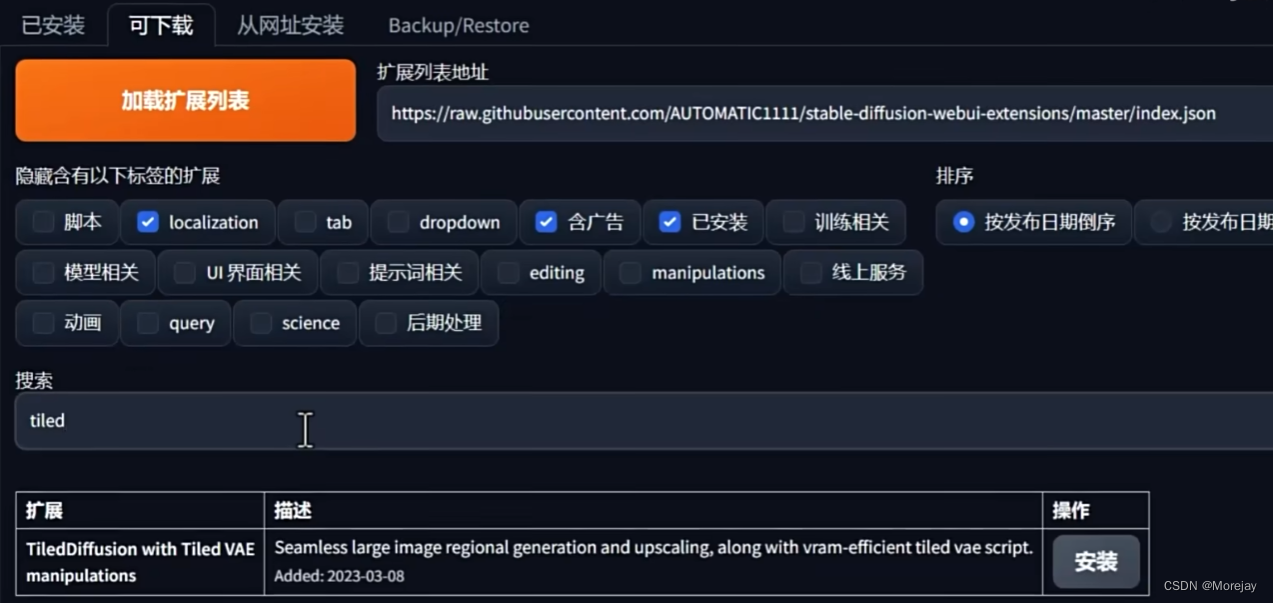
低显存出4K+分辨率图片的工具,效果相比较SD Upscale算法效果更好,效率更高。
扩展安装
秋叶的整合包默认已经安装好了
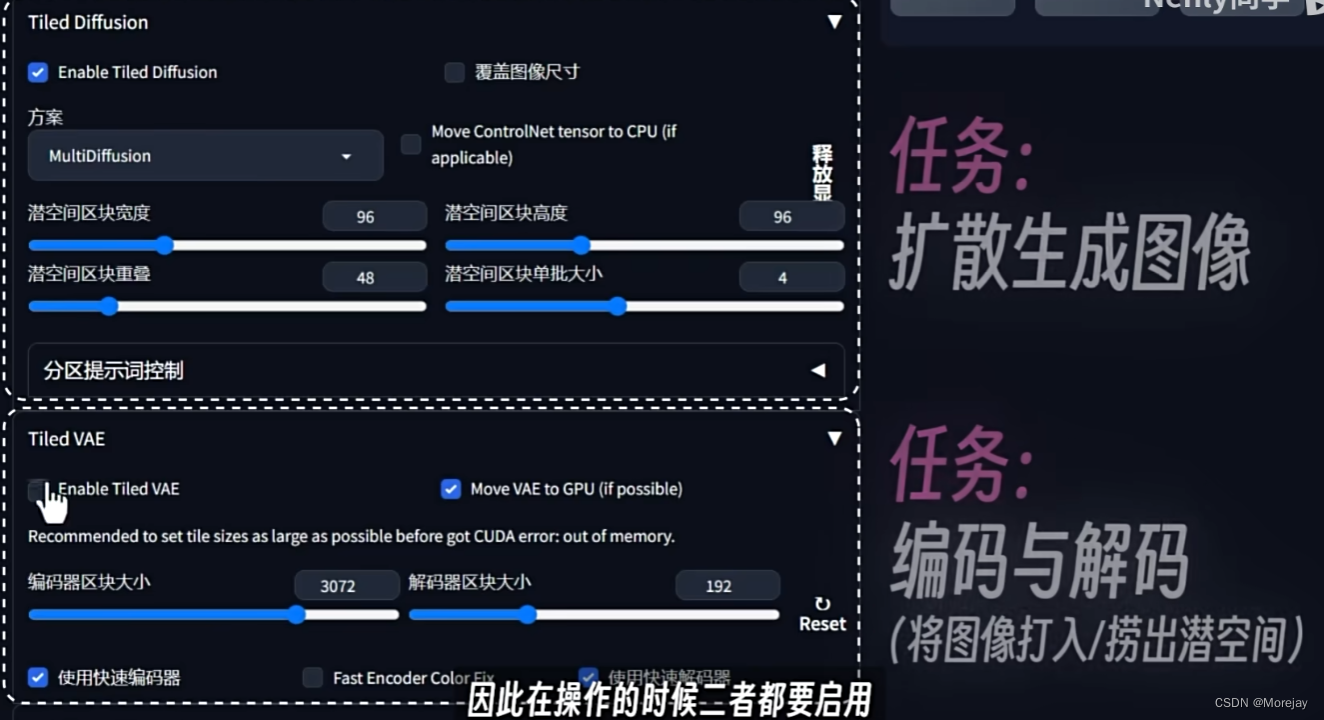
使用
将生成的低分辨率图像发送到图生图
分辨率设置方案:
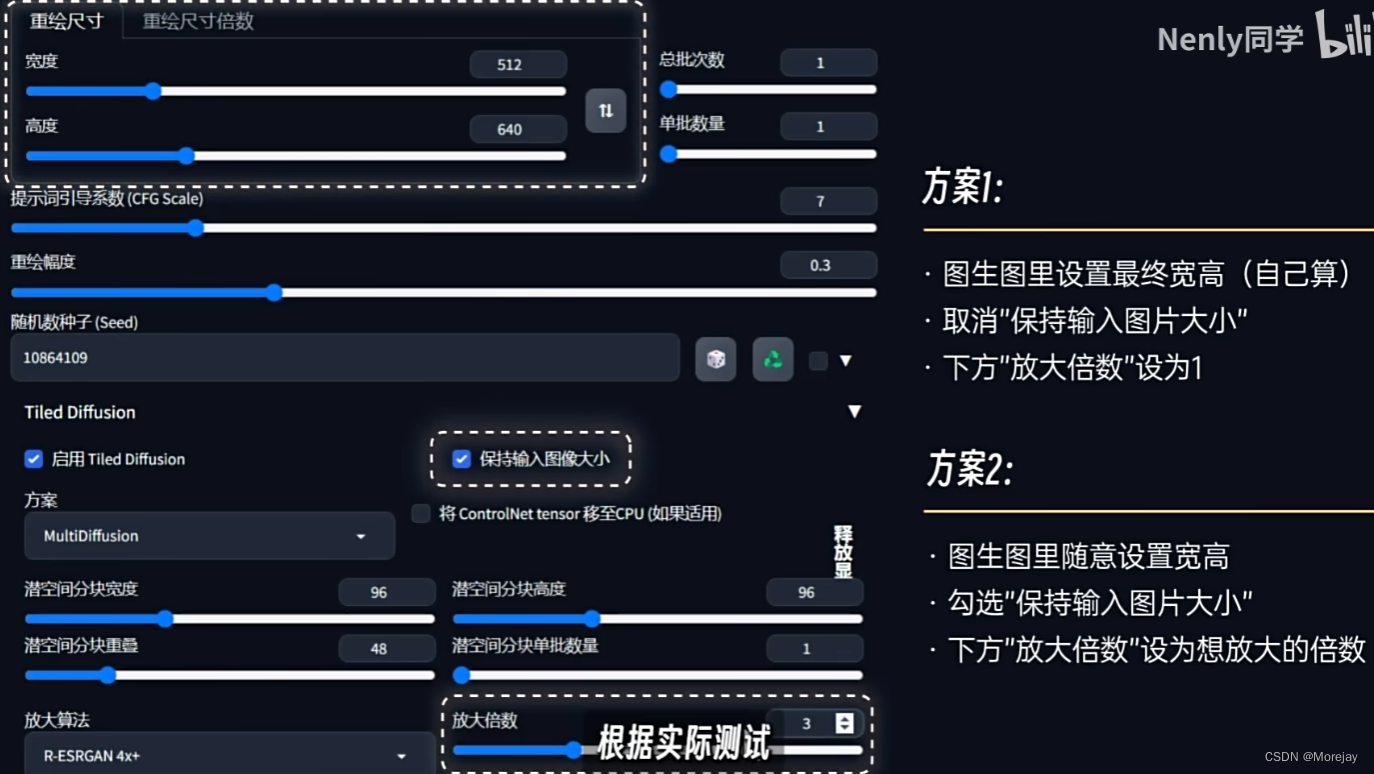
这里设置了放大算法和放大倍数(仅放大的话,重绘幅度最好设置为0.3)
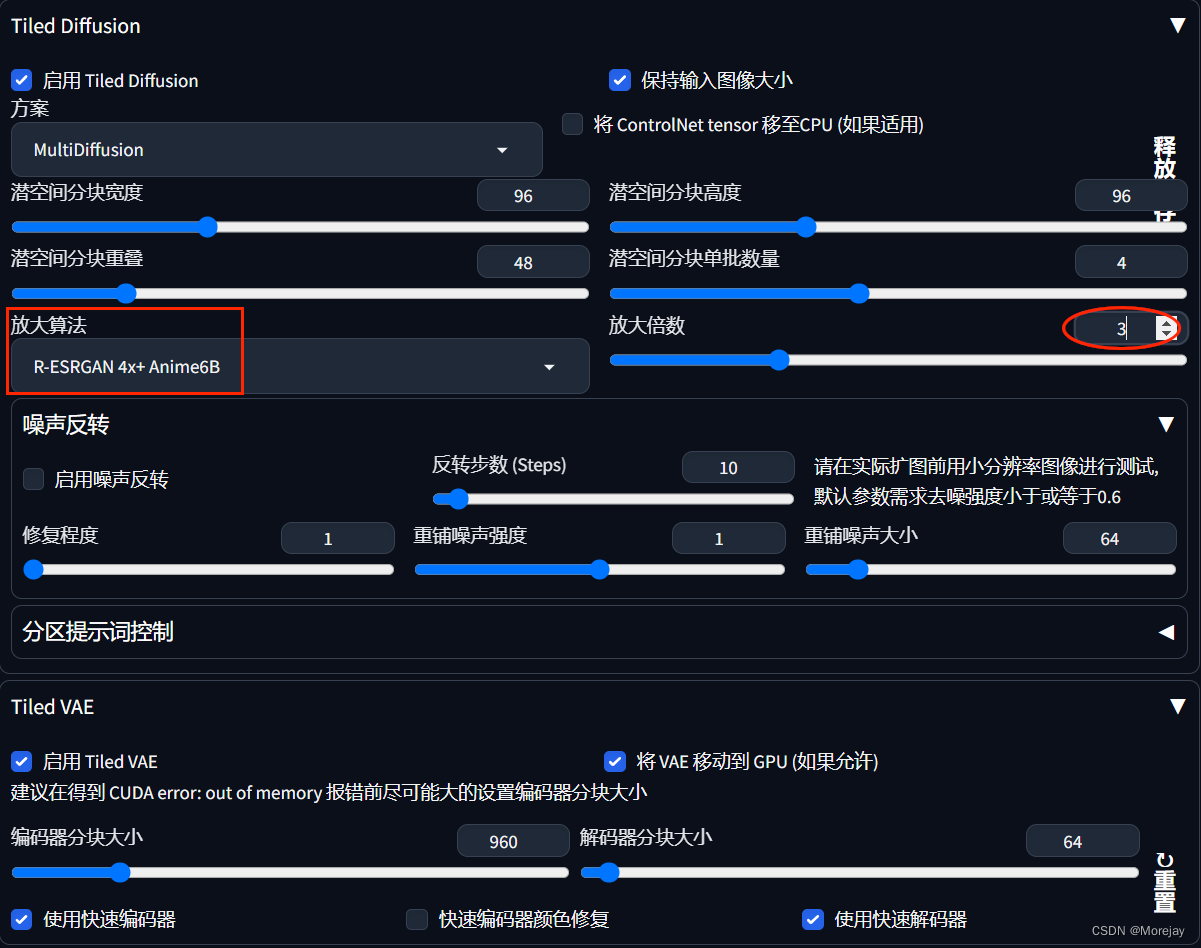
推荐参数设置

高分辨率(4K以上推荐开启,设置在0.5)

关于ControlNet Tile


使用方法
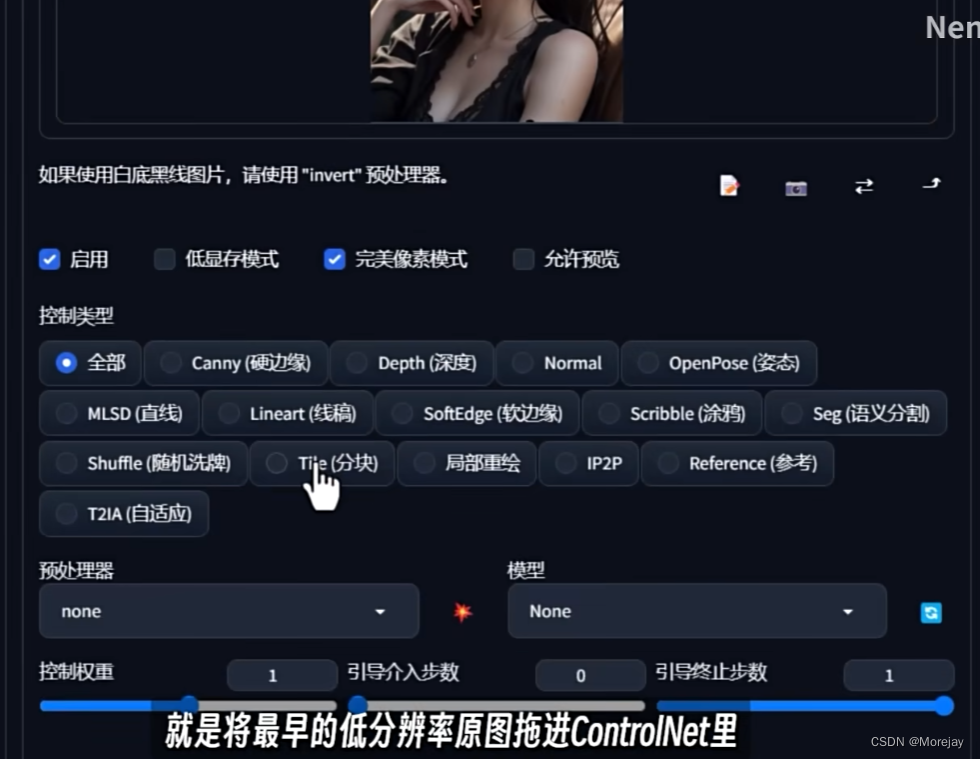
勾选Tile,切换预处理器和模型
AI二维码/艺术字/光影光效生成
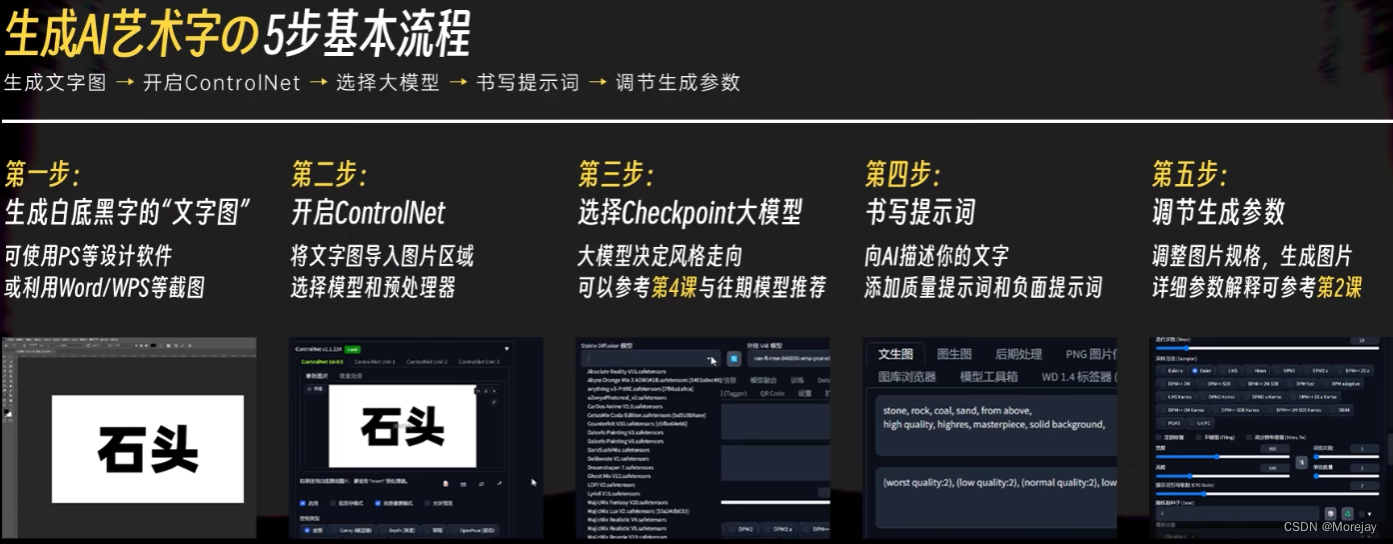
Depth效果较好
光影光效
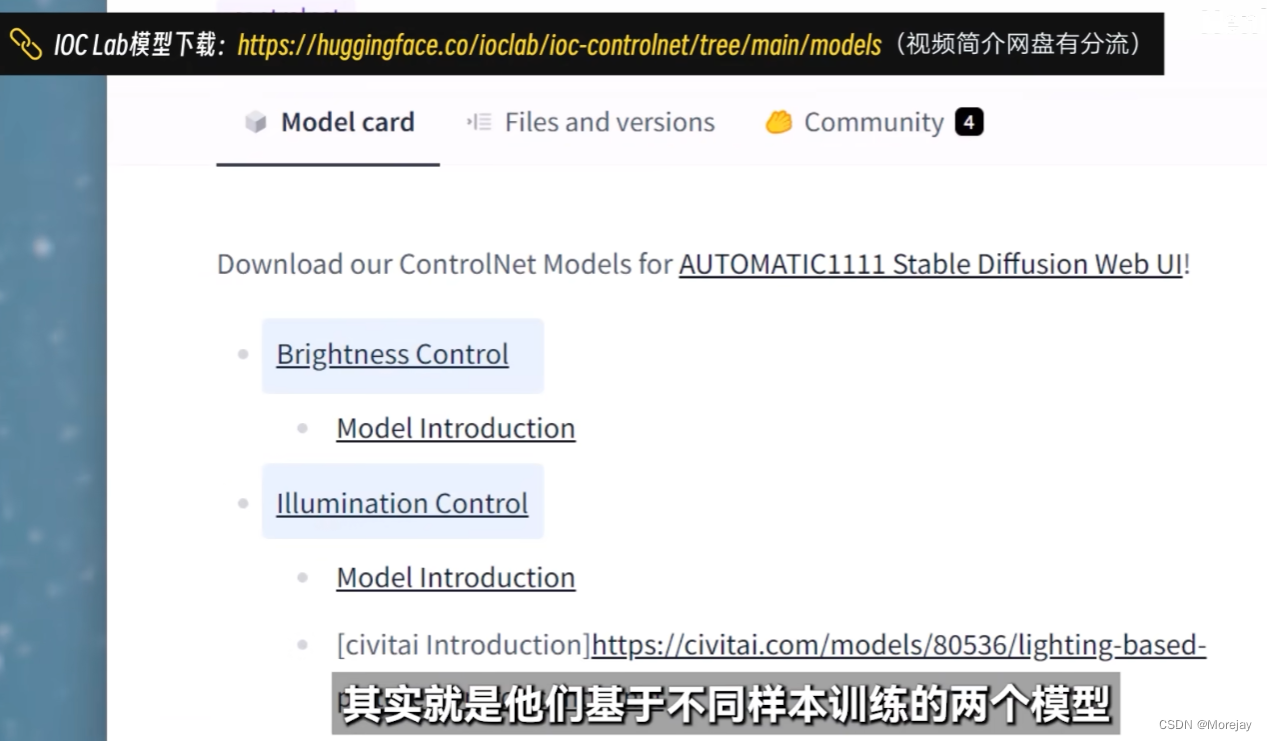
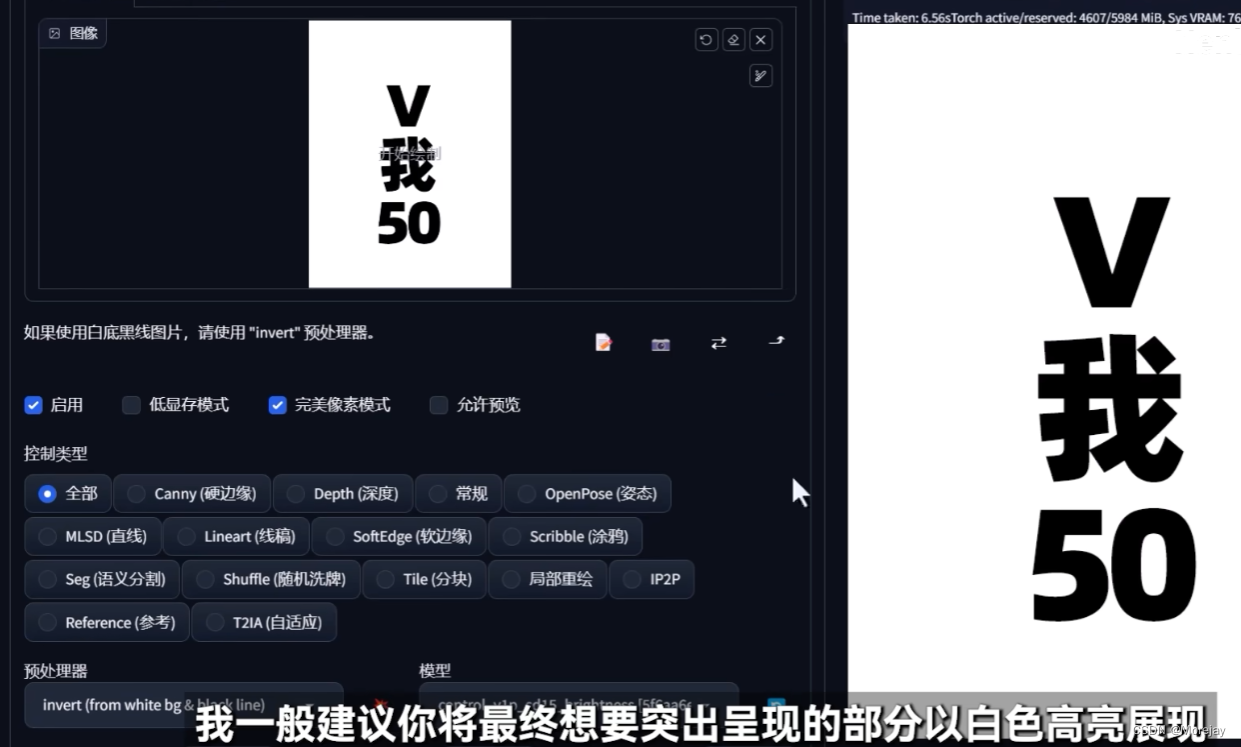
这里使用了Invert预处理器翻转黑白
二维码
网页链接转QR Code在线工具:https://cli.im/url
IP-Adapter
给角色换装(也可以通过特定的服饰LoRA实现)
项目地址:https://github.com/tencent-ailab/IP-Adapter
论文阅读:IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
借助Lineart的线条固定产品结构,再通过IP-Adapter一类的方法改造产品的配色、风格。
模型推荐与ADetailer插件

作者majicMix
LoRA:DreamShaper与ArtrAnime
绘制半身或者全身照(人物距离镜头较远),脸部会模糊不清,手部细节质量较差(这些对于整个画面影响不大,占比小,因此高清修复使用SD扩散会增加崩坏可能)
ADetailer通过算法(如YOLO)识别到人物的脸部,然后单独重绘这片区域,在拼接回去(本质上类似局部重绘)。


安装流程与其他扩展的安装方法一致,不再赘述
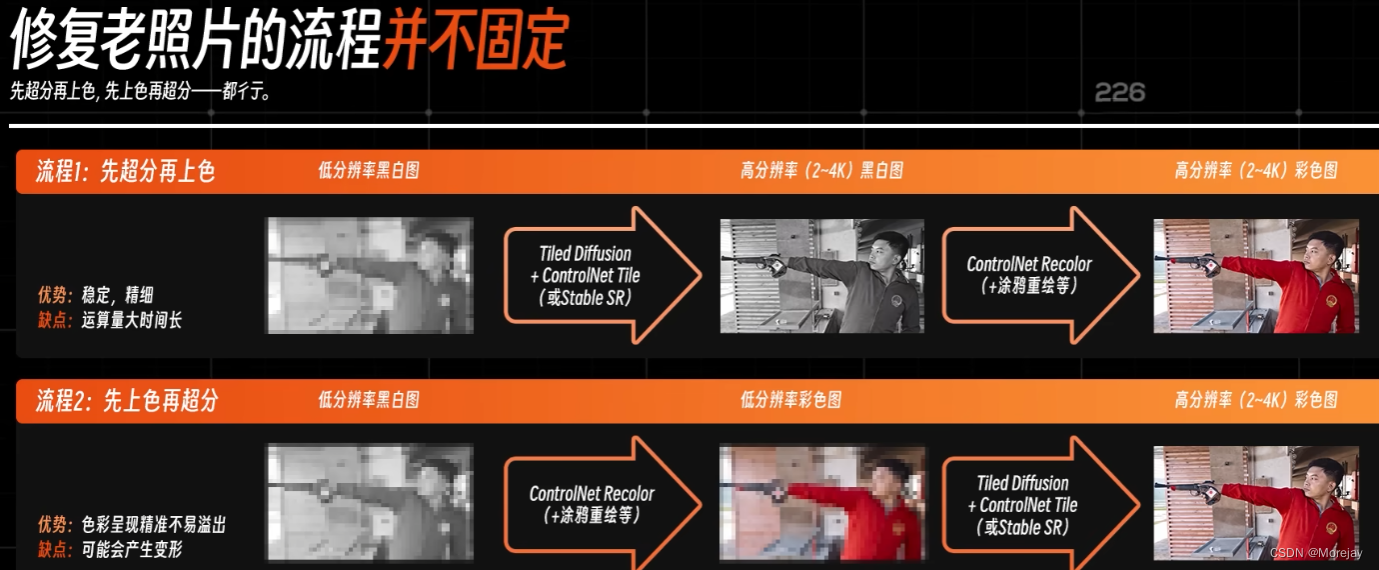
老照片修复
关于低分辨率放大
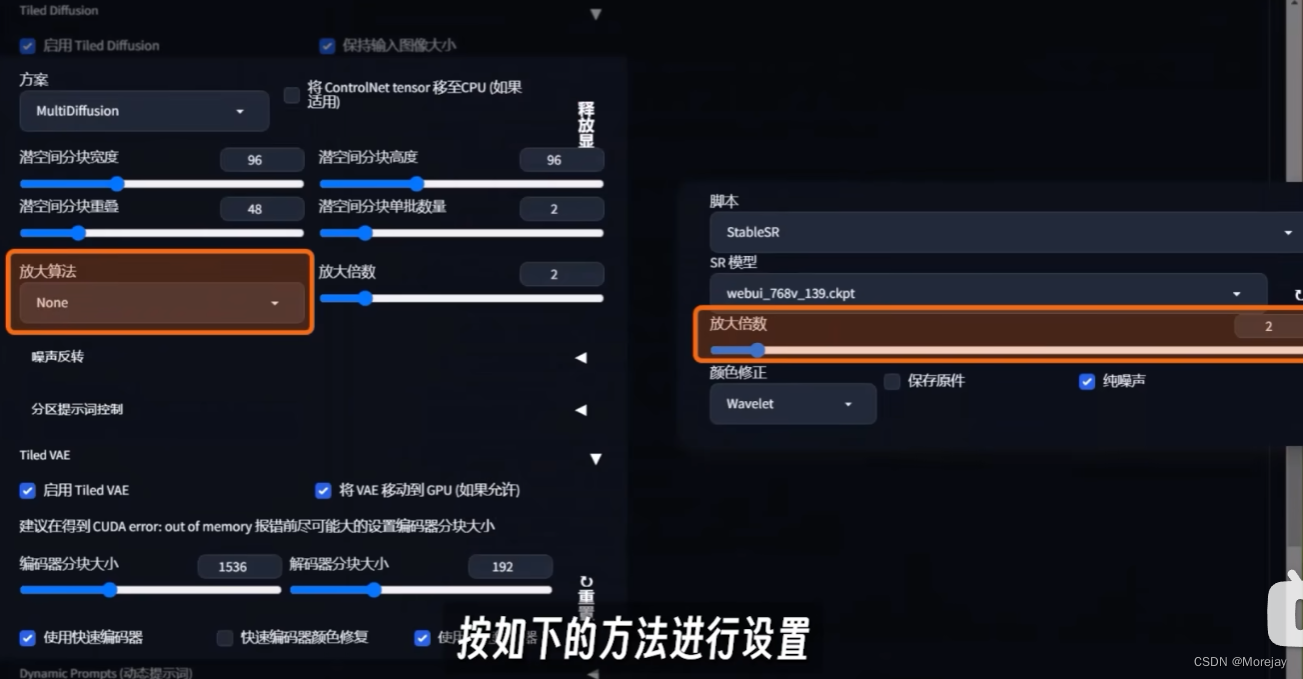
可以采用前文的Tiled Diffusion和ControlNet Tile方法,或者采用真实图片超分算法。
关于真实图片超分算法(修复人像),StableSR是一个不错的选择
StableSR效果图:

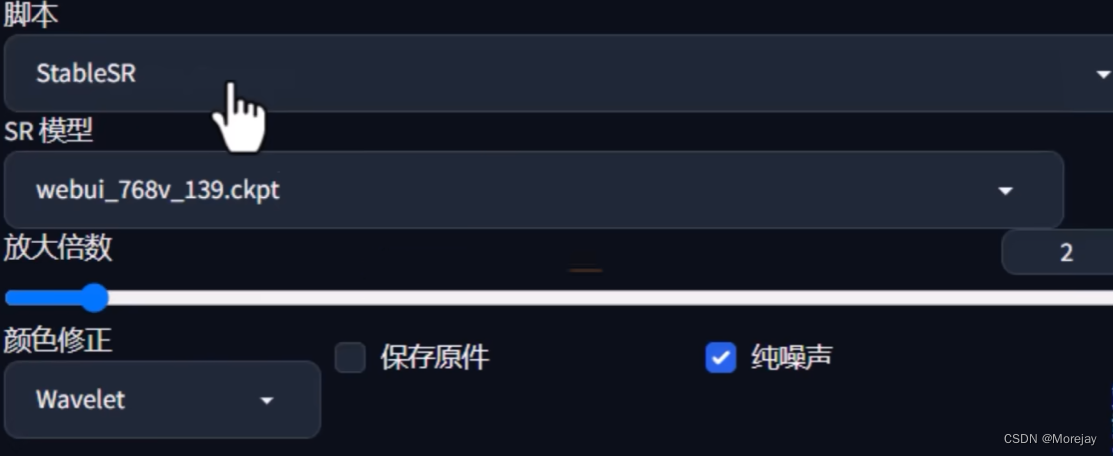
结合Tiled Diffusion与StableSR的方式
关于后期处理修复
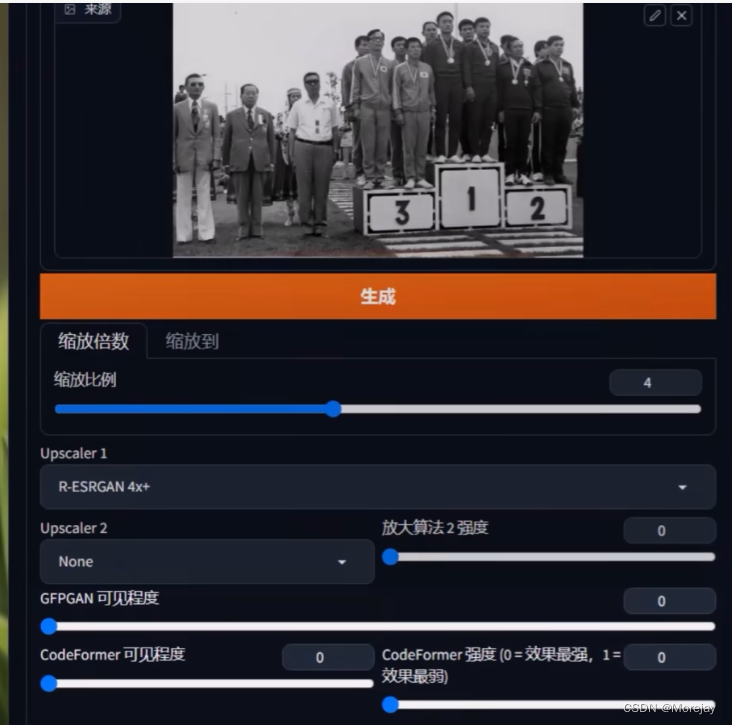
CodeFormer和GFPGAN可用于修复扭曲的面部,可以同时开启,设置在0.5左右
关于照片上色
可以使用ControlNet Recolor(v1.1.4更新)
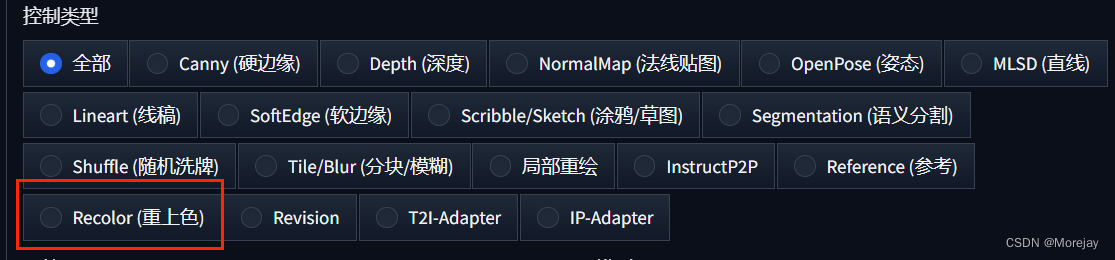
总结
LoRA训练
训练脚本代码:https://github.com/kohya-ss/sd-scripts
基于sd-scripts的GUI界面:https://github.com/bmaltais/kohya_ss
手动安装
按照kohya_ss仓库的Windows安装教程配置环境
- CUDA(v11.8):https://developer.nvidia.com/cuda-11-8-0-download-archive
- cuDNN(9.2.1):从support-matrix可以查看版本支持,然后从cuDNN官网安装当前最新版本(v9.2.1,支持CUDA 11.8)
pip设置aliyun镜像:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
运行
setup.bat或者setup-3.10.bat经历下面几个安装文件:
kohya_ss目录下:
- requirements_pytorch_windows.txt
- requirements_windows.txt
- requirements.txt
kohya_ss/sd-scripts目录下:
- requirements.txt
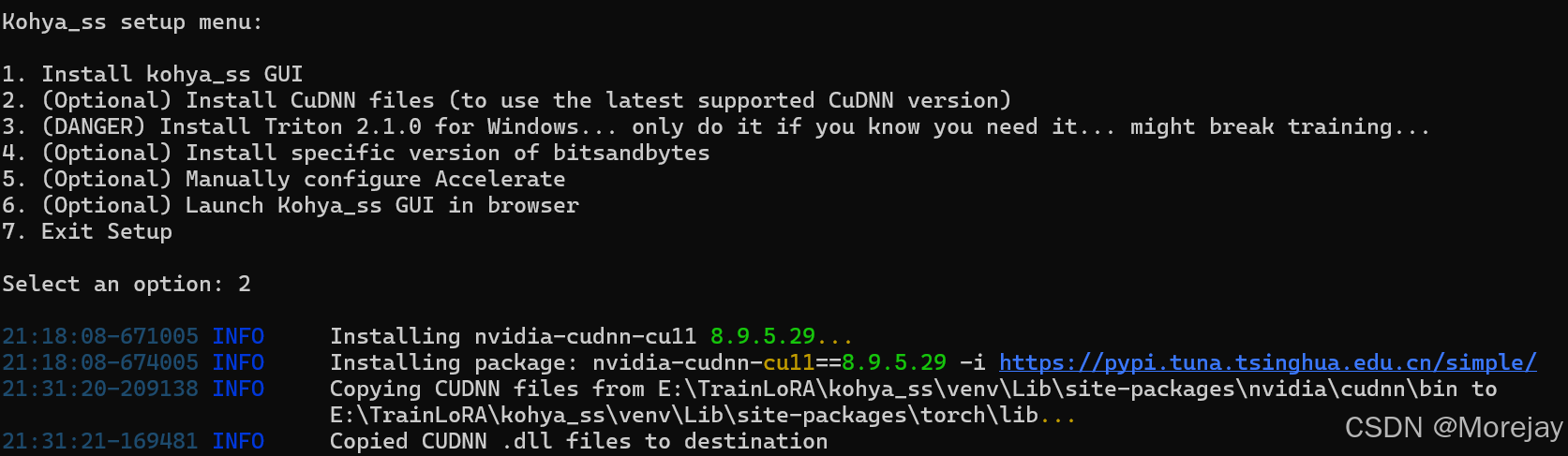
关于2. (Optional) Install CuDNN files (to use the latest supported CuDNN version)
需要更改kohya_ss/setup目录下的setup_common.py,为其加上镜像网站:

中文GUI启动(创建gui_zh_CN.bat)
@echo off
call gui.bat --language zh-CN --inbrowser --headless
echo 完成
pause
endlocal
整合包安装
如果希望使用较为纯正的Kohya GUI页面,可以考虑使用@独立研究员-星空 老师提供的原版整合包:
视频地址:https://www.bilibili.com/video/BV1H8411d7nG/
其他两位Up主基于Kohya_SS(SD Script)开发的“同款”训练器:
@秋葉Aaaki 的SD-Trainer:
项目主页:https://github.com/Akegarasu/lora-scripts
视频地址:https://www.bilibili.com/video/BV1AL411q7Ub
@朱尼酱 的赛博丹炉:
视频地址:https://www.bilibili.com/video/BV1zu411W7LW/
训练步骤
-
准备训练集
训练集应尽量涵盖训练对象的“多样化样本”
如训练一个游戏角色的LoRA:官方立绘图(不同角度)、游戏建模截图、少量还原二创图。单个角色的风格训练以20~30张图像为宜。
-
图片预处理
-
裁剪(可以使用Web-UI的后期处理功能)——焦点剪裁(以目标“脸”为中心)
-
打标(两种方法:Web-UI的后期处理、WD标签器)
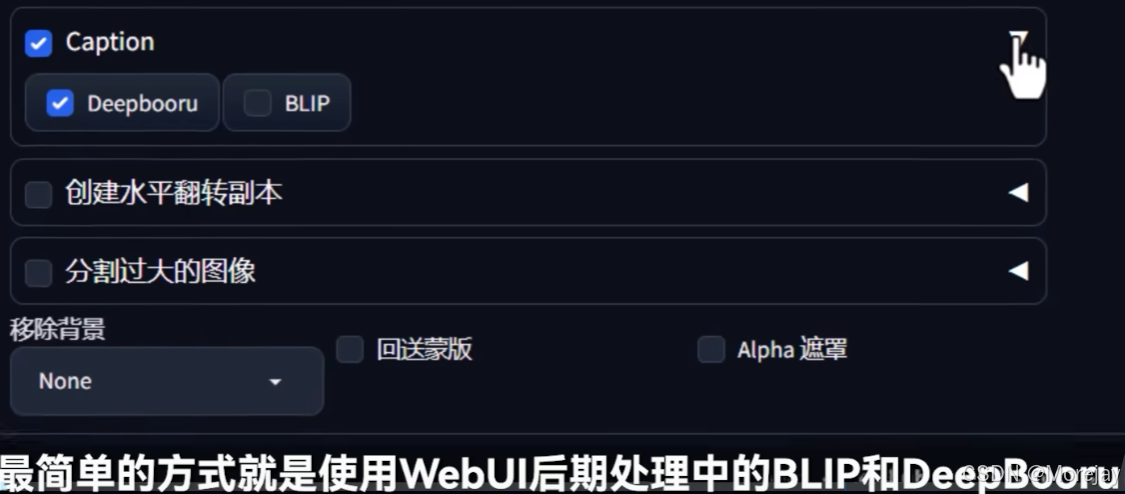
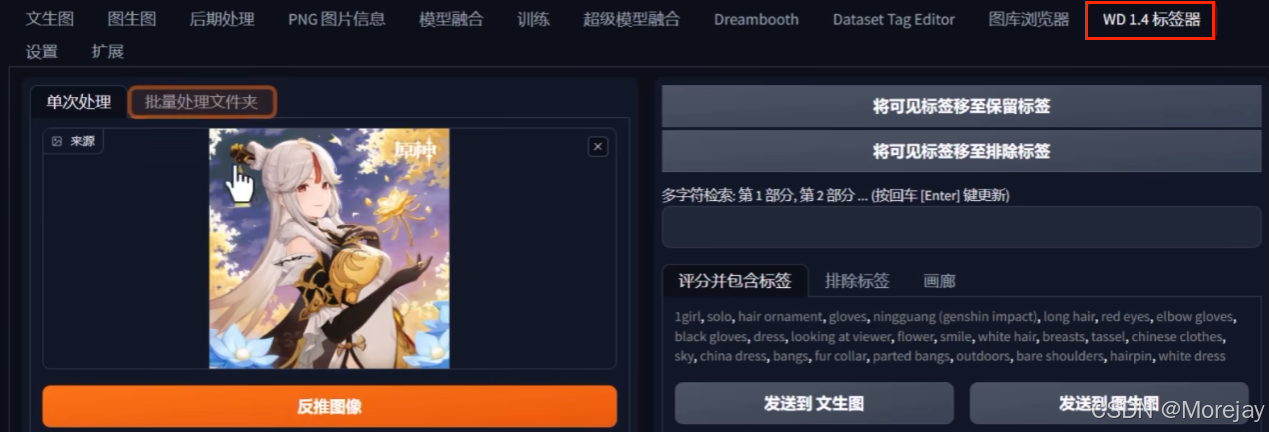
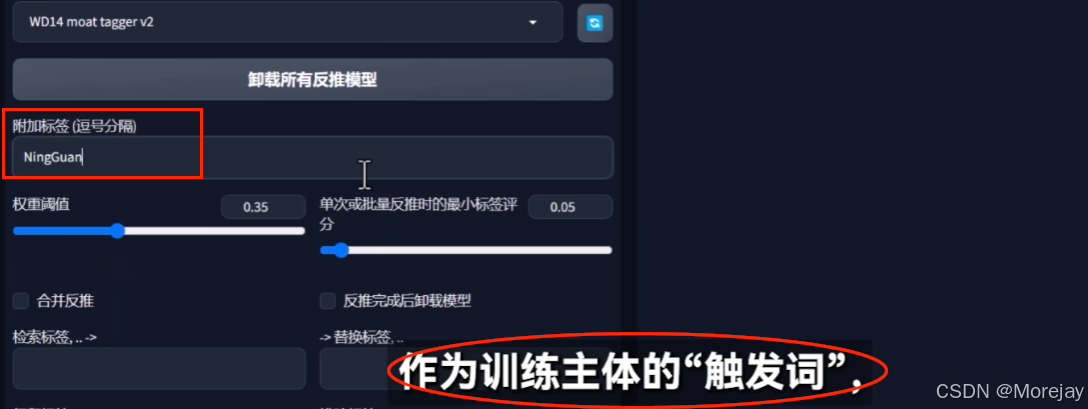
-
-
训练

底模选择

文件夹创建
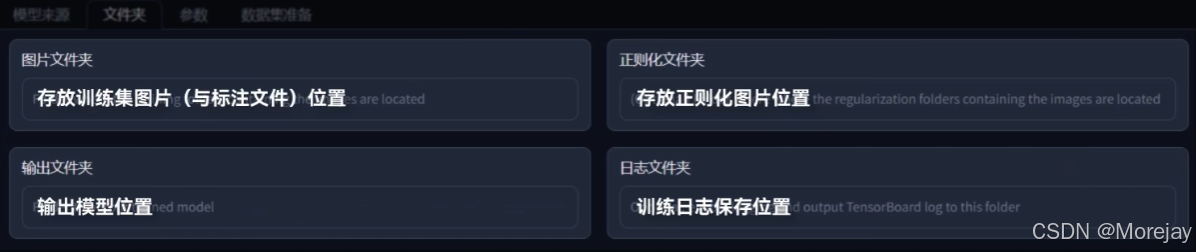
处理好的训练集图像存放位置(创建一个新文件夹):
"6_Tifa"中的6表示训练集图像重复训练的次数(影响步数计算和学习效果,二次元图像一般设置5 ~ 10,三次元考虑10 ~ 30之间)

训练时,训练集路径为…\TrainLora\images,而不是…\TrainLora\images\6_Tifa
训练开始
一个epoch = 图像数量 × step (比如33张图,repeat为6,则33×6=198 )
参数使用了预设的iA3-Prodigy-sd15

问题总结
OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14' is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
解决办法:
从https://huggingface.co/openai/clip-vit-large-patch14/tree/main 下载文件
备选:
git clone https://www.modelscope.cn/AI-ModelScope/clip-vit-large-patch14.git
修改安装目录(以秋叶整合包为例)下 \repositories\stable-diffusion-stability-ai\ldm\modules\encoders\modules.py中的路径地址(最好使用绝对路径)

还有一处(不确定要不要改):repositories\generative-models\sgm\modules\encoders\modules.py 350行处
找到 …\kohya_ss\sd-scripts\library\train_util.py 这个文件的的4228行,将
original_path = V2_STABLE_DIFFUSION_PATH if args.v2 else TOKENIZER_PATH
修改为
original_path = V2_STABLE_DIFFUSION_PATH if args.v2 else "path/to/clip-vit-large-patch14"
结果展示
大模型使用Astranime,同样的prompt测试
# prompt
1girl,solo,long hair,breasts,gloves,thighhighs,skirt,suspenders,fingerless gloves,crop top,earrings,navel,red footwear,jewelry,black thighhighs,black hair,tank top,midriff,large breasts,elbow gloves,suspender skirt,black skirt,cleavage,clenched hand,low-tied long hair,arm guards,elbow pads,zettai ryouiki,red eyes,bangs,bare shoulders,black gloves,gradient,lips,shirt,boots,white tank top,leg up,gradient background,very long hair,pleated skirt,fighting stance,standing on one leg,grey background,brown eyes,sports bra,collarbone,standing,
(masterpiece:1.2),best quality,masterpiece,highres,original,extremely detailed wallpaper,perfect lighting,(extremely detailed CG:1.2),drawing,paintbrush,
# negative prompt
NSFW,(worst quality:2),(low quality:2),( normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),
不使用LoRa

使用训练得到的LoRA
Tifa,<lora:Character-Tifa_33imgs:0.8>,

参数设置
首先,了解一下LyCORIS:Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion(LoRA除常规方法外的秩自适应实现)
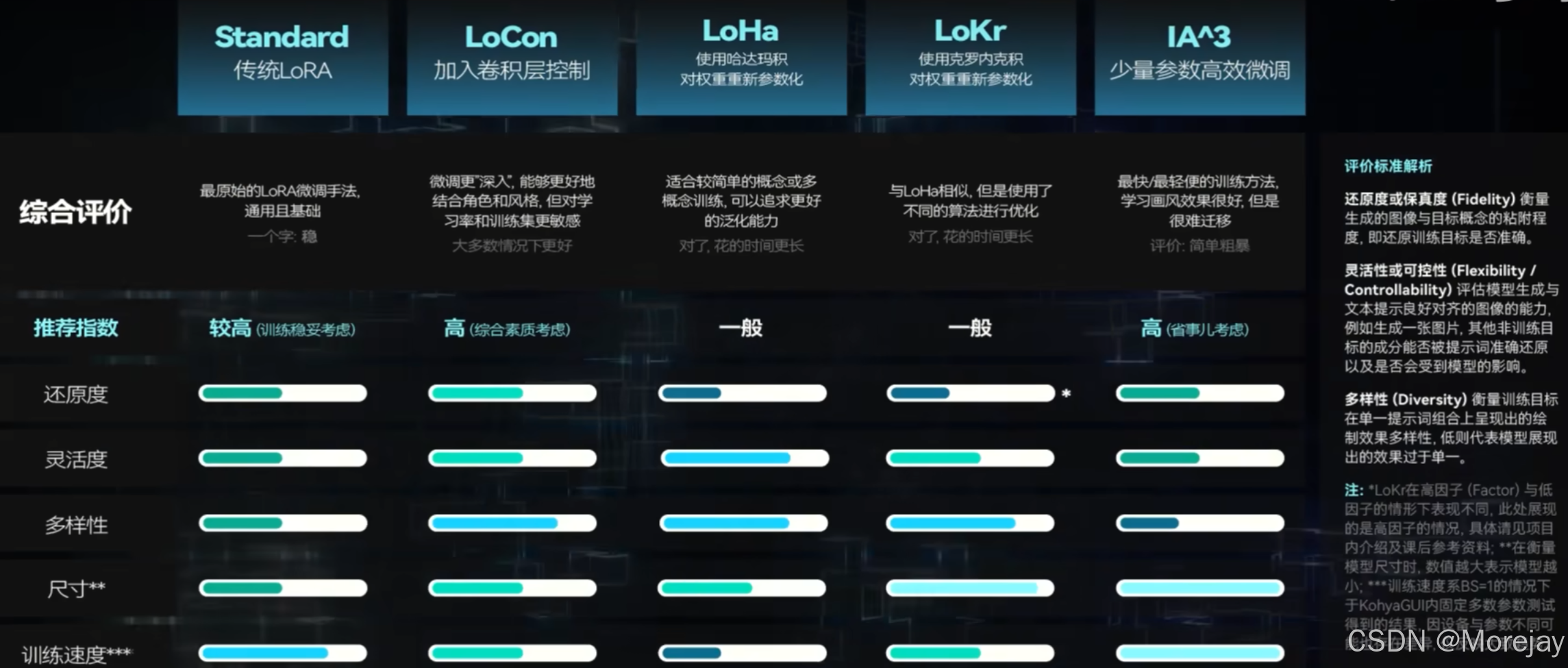
这里的IA^3即为上节训练使用的预设iA3-Prodigy-sd15中的训练方法。
此外还包括Native fine-tuning (aka dreambooth),作者还在引入新的GLoRA and GLoKr.
注:LoHa、LoKr更擅长训练画风且面对多概念训练时更有优势。
基础参数
epoch、step等决定训练时间的参数(1 epoch = 图片数 × 重复次数)。
batch size 根据显存大小自行调整,可以加快训练;而且较大的batch size对于模型训练有帮助(除非batch size增大了10倍以上,否则没必要调整学习率)。
lr(learning rate):一般设置

优化器
AdamW(lr:1e-4) 或者 lion(理论上比AdamW优秀,lr:7e-5,适合较大的Batch Size) 或者 Prodigy(无参数自适应学习率,学习率设置为1,即无需再考虑设置lr)
影响LoRA大小的参数
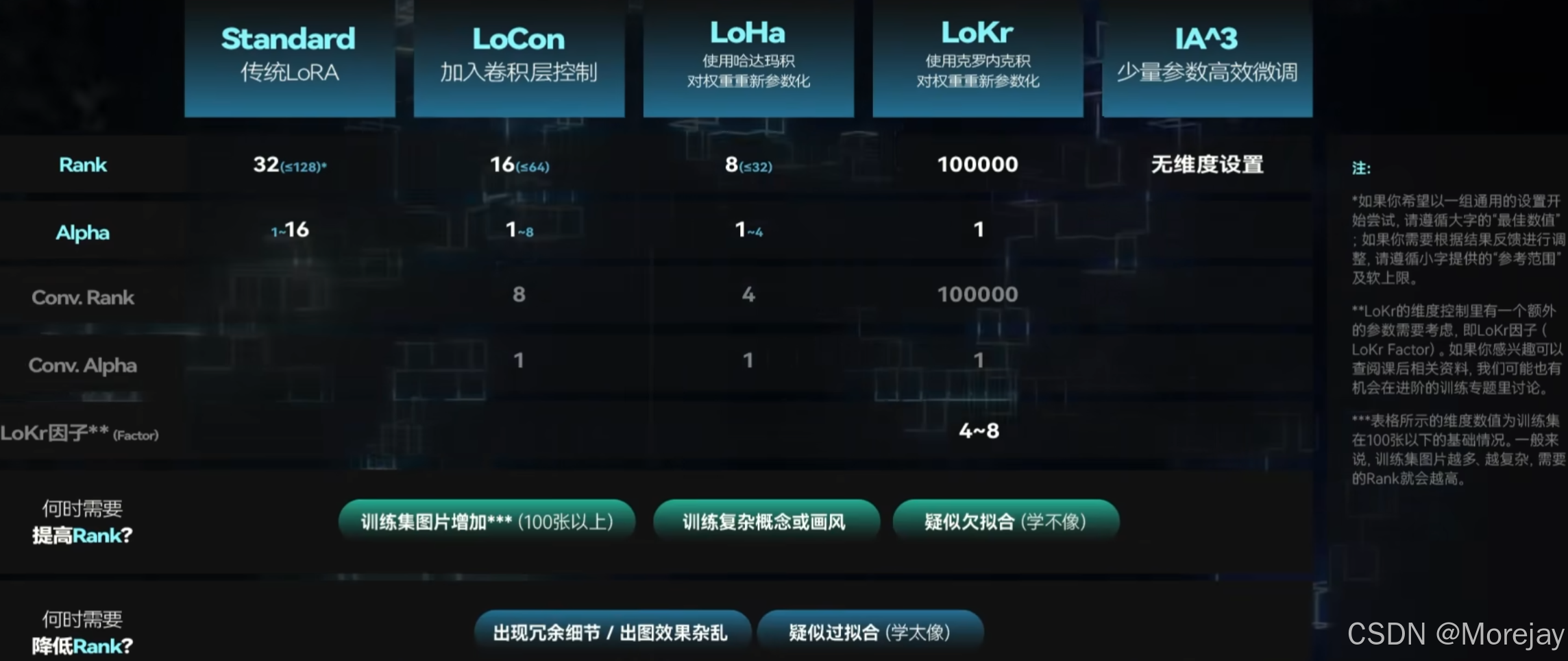
Network Rank

Rank值越高,从原始矩阵里抽出的行列越多,微调的数据量越大(容纳更为复杂的概念)
直接影响训练得到的LoRA模型大小以及训练使用的显存。
- 最大为128,此时LoRA模型约为144MB。(较高的Rank【>=64】一般用来训练较为复杂的画风、三次元物品和形象等对细节要求较高的场景)
- 最小值设置为8,对应几MB模型大小。(【<=32】二次元画风,或者训练对象复杂程度较低时)
高Rank值训练二次元人物LoRA时,往往会产生过拟合现象(生成的图像在背景和无关的细节方面过于接近训练图像,甚至影响到底模的画风)。训练推荐从低Rank开始尝试
比如LoCon(传统LoRA)的维度一般 <=64,LoHa一般 <=32
Network Alpha

一个用于调节LoRA对原模型权重影响作用的参数
Alpha和Rank的比值等于使用LoRA时的“减弱权重”程度
Alpha一般不超过Rank,越接近Rank则LoRA对原模型的影响程度越小,温和做法,设置Alpha为Rank值得一半,也可以设置Alpha为1,代表不减弱LoRA的权重。
性能相关参数
关于精度选项(推荐fp16)

xFormers交叉注意力


调整策略
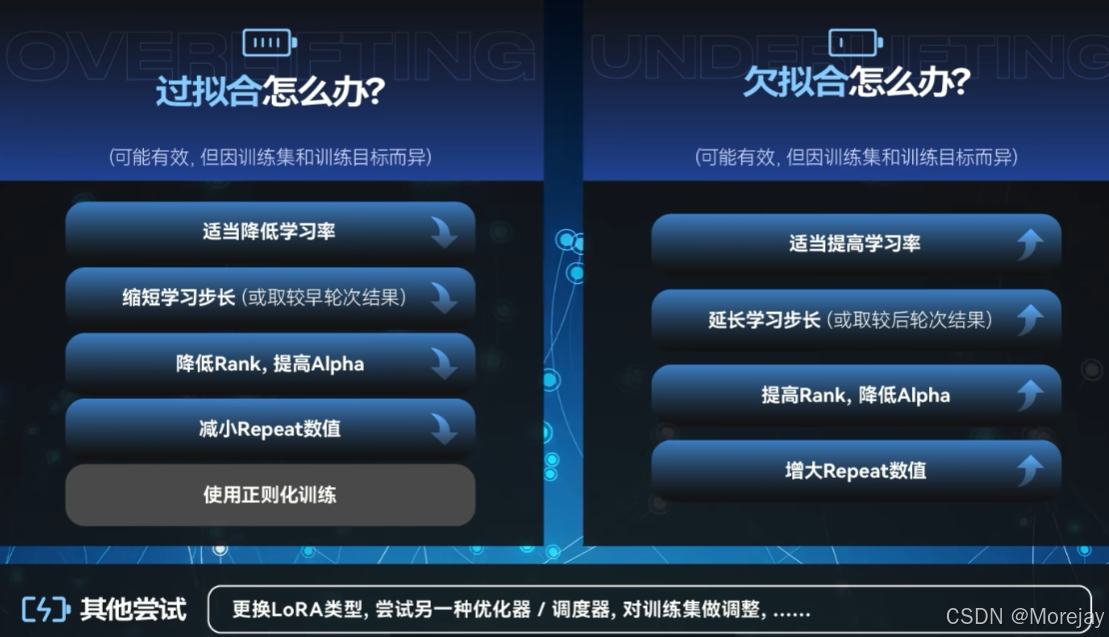
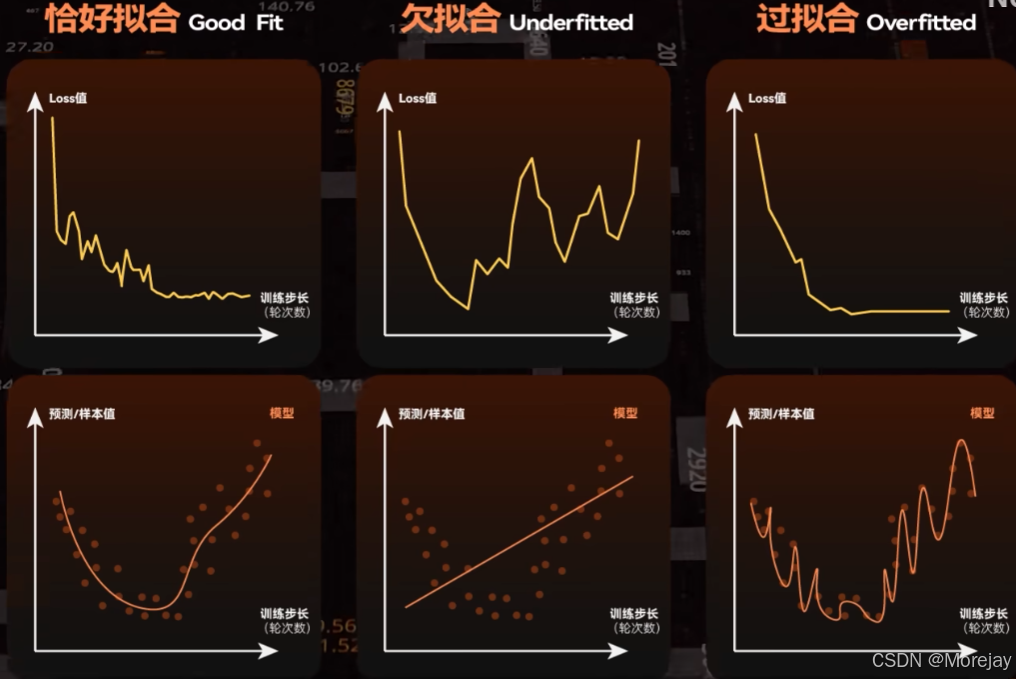
loss=Nan 是一个危险的信号,代表有些参数的值被设置到了极端情况(一般是lr设置过大导致的)
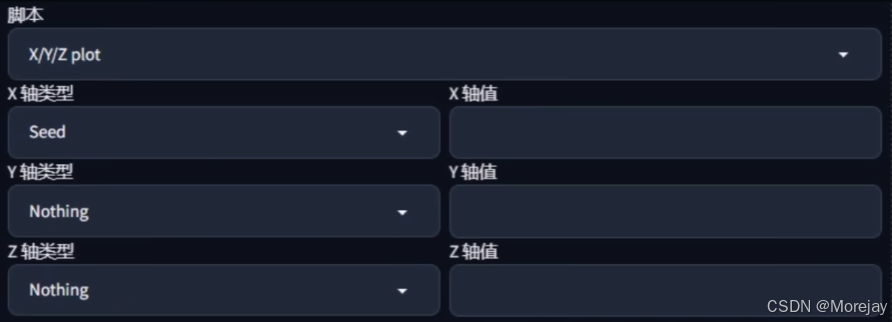
XYZ 绘图对比(脚本)
如何对比不同Epoch得到的Lora模型效果?
首先,统一LoRA模型的文件名格式(最终模型改为0000006)

然后,提示词框加载第一个LoRA模型

使用提示词搜索/替换(Prompt S/R)【“-0000001” ~ "-0000006"表示要替换的尾缀】


也可以通过这种方式,对比LoRA模型的不同权重(得到适合的值)


数据集处理
十分重要的一环
关于训练集图像尺寸
当训练集图像尺寸未统一时(太多的Buckets会影响训练速度和质量,因此最好再裁剪时分为固定的512 × 512分辨率)

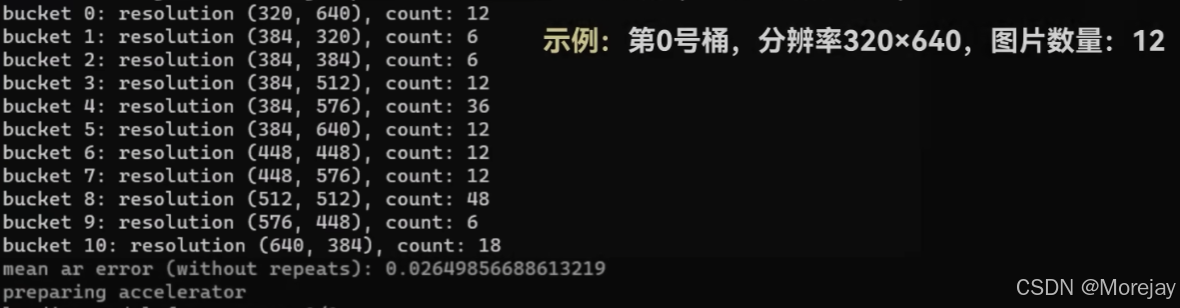
关于打标
前面介绍了使用WD 1.4标签器反推,但是标签并不是越多,越准确越好的
越希望AI学习的东西越不能出现在标签里
如果只输入LoRA和触发词,不做其它额外描述,发现有时生成的图像根本不像。


标注文件做了详细描述
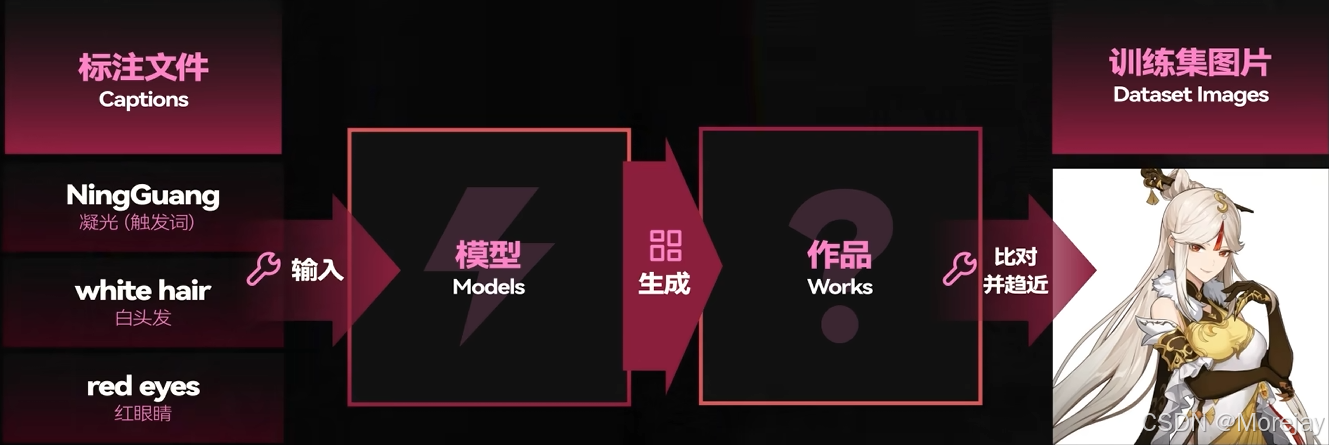
这也就造成了学习时需要这些特征描述,才能生成比较像的图像

因此缺少特征描述时,会生成不像的图

标签需要清洗修正,把所有希望LoRA固定下来的特征对象从标签中剔除,让AI把握“要领”
dataset tag editor扩展安装
整体审核(删除 与对象特征明显不符的 & 与角色联系密切的特征)
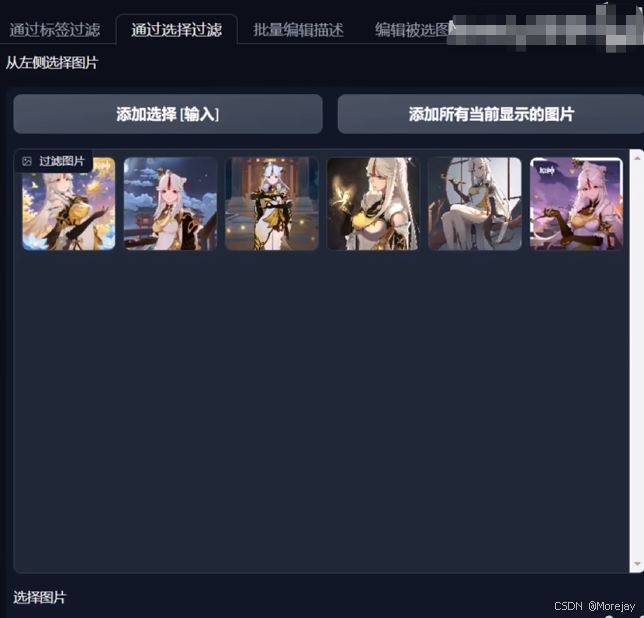
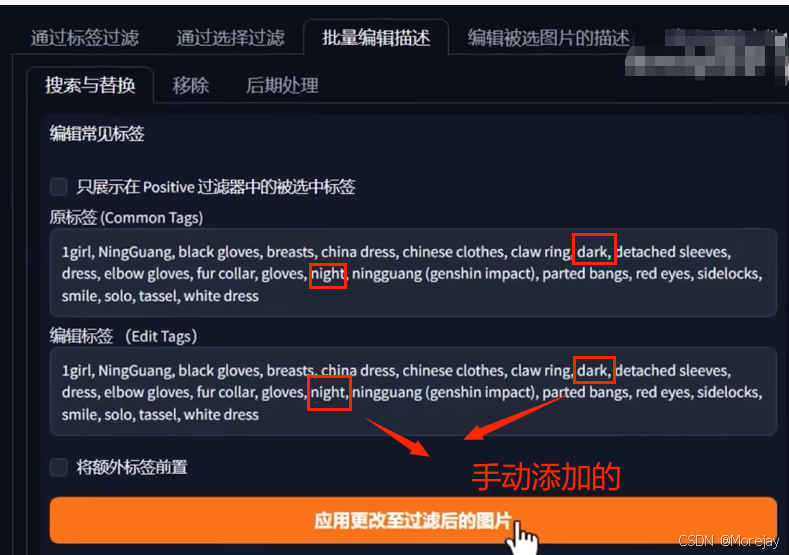
批量选择与过滤
ComfyUI
节点式界面,工作流(workflow)是特色。
类似UE(Unreal Engine)
安装
- 官方代码库(附安装流程):https://github.com/comfyanonymous/ComfyUI
- 秋叶整合包:https://www.bilibili.com/video/BV1Ew411776J/
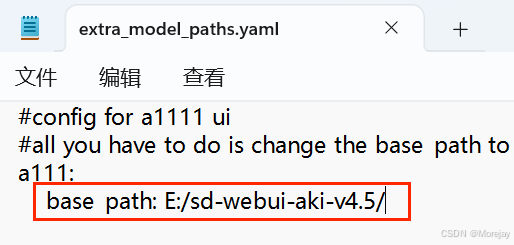
ComfyUI与WebUI的项目结构类似。ComfyUI还考虑到与WebUI“数据互通”的问题:
将该文件扩展名修改为
.yaml,并添加webui的根目录路径:

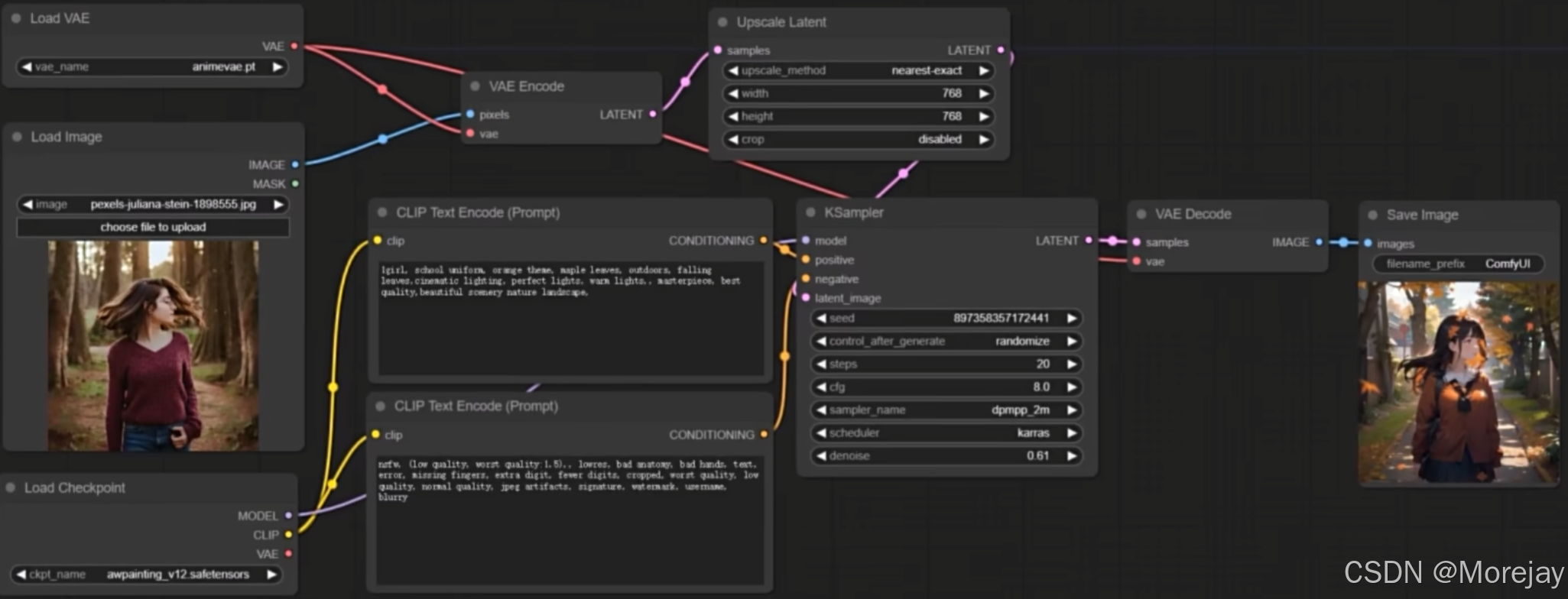
图生图基本工作流
使用LoRA
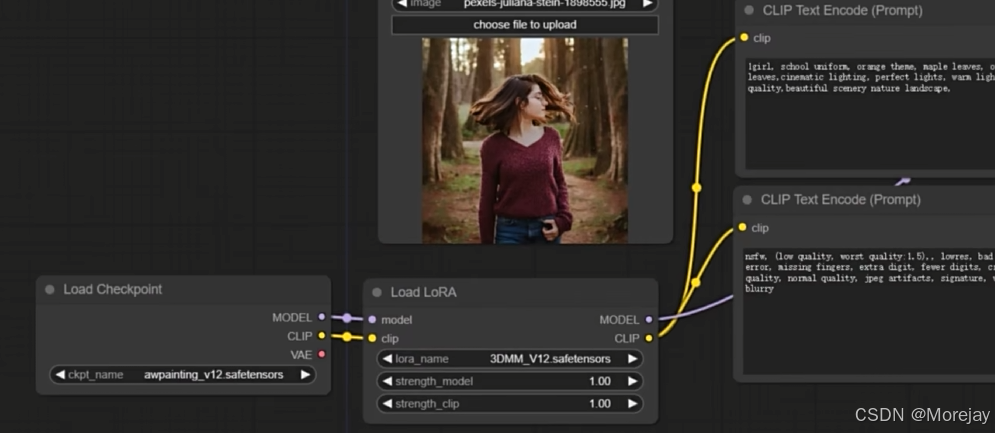
各种工作流网站
-
ComfyUI官方示范:https://comfyanonymous.github.io/ComfyUI_examples/
-
别人的基础工作流示范:
-
工作流分享网站:https://comfyworkflows.com/
-
Civitai也有不少工作流分享
加载工作流

自定义节点
法①:通过git clone或者下载压缩包的方式将源代码复制到E:\sd-ComfyUI-aki-v1.3\custom_nodes目录,再次启动ComfyUI即可。
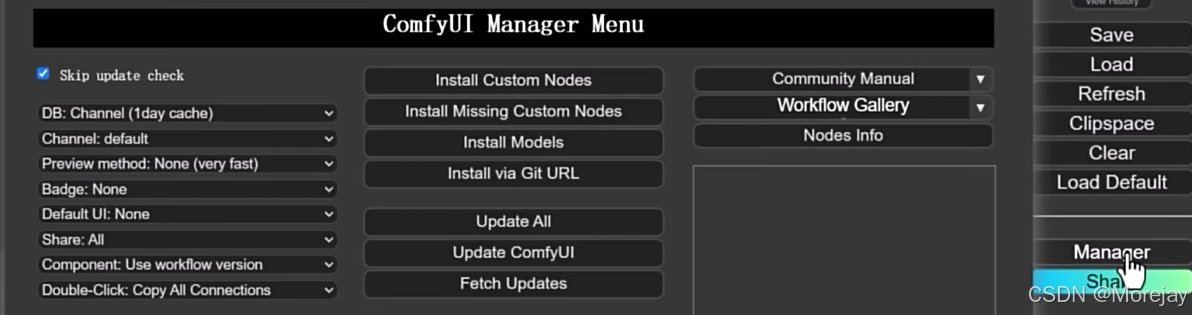
法②:使用节点管理工具——ComfyUI-Manager:https://github.com/ltdrdata/ComfyUI-Manager


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









