







ControlNet: TL;DR
ControlNet 是在 Lvmin Zhang 和 Maneesh Agrawala 的 Adding Conditional Control to Text-to-Image Diffusion Models 中引入的。 它引入了一个框架,允许支持各种空间环境,这些环境可以作为Diffusion模型(如 Stable Diffusion)的Additional conditionings。
训练 ControlNet 由以下步骤组成:(每一种新的condition都需要重新训练一个新的 ControlNet 权重副本)
-
复制 Diffusion 模型的预训练参数,例如 Stable Diffusion 的Latent UNet(称为“
trainable copy”),同时单独维护原始的预训练参数(“locked copy”): locked 的参数副本可以保留从大型数据集中学到的大量先验知识,而 trainable 参数副本则用于学习特定于任务的方面。 -
参数的 trainable 和 locked 副本通过“
zero convolution”层连接,这些层作为 ControlNet 框架的一部分进行了优化,从0 逐步增长参数值,确保开始时没有随机的噪音会干扰finetuning。这是一种训练技巧,用于在训练新condition时保留冻结模型已经学习的语义。
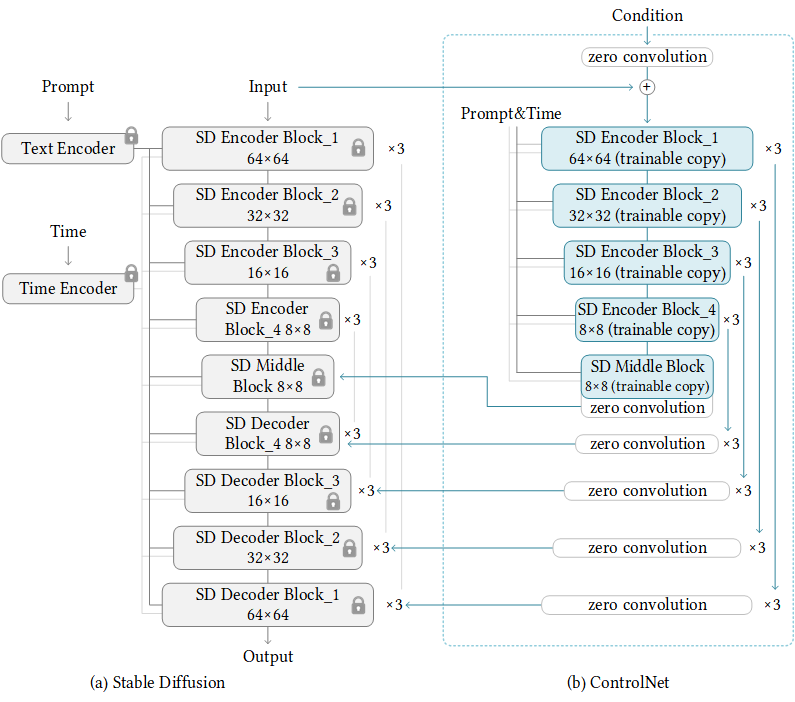
推理时,需要Pre-trained的SD扩散模型权重和Finetune过的 ControlNet 权重。与仅使用原始 Stable Diffusion 模型相比,将 Stable Diffusion v1-5 与 ControlNet 检查点一起使用需要大约 7 亿个参数,这使得 ControlNet 在推理时需要的内存成本更高。在使用不同的condition时,只需切换 ControlNet 参数。这使得在一个应用程序中部署多个 ControlNet 权重变得相当简单。
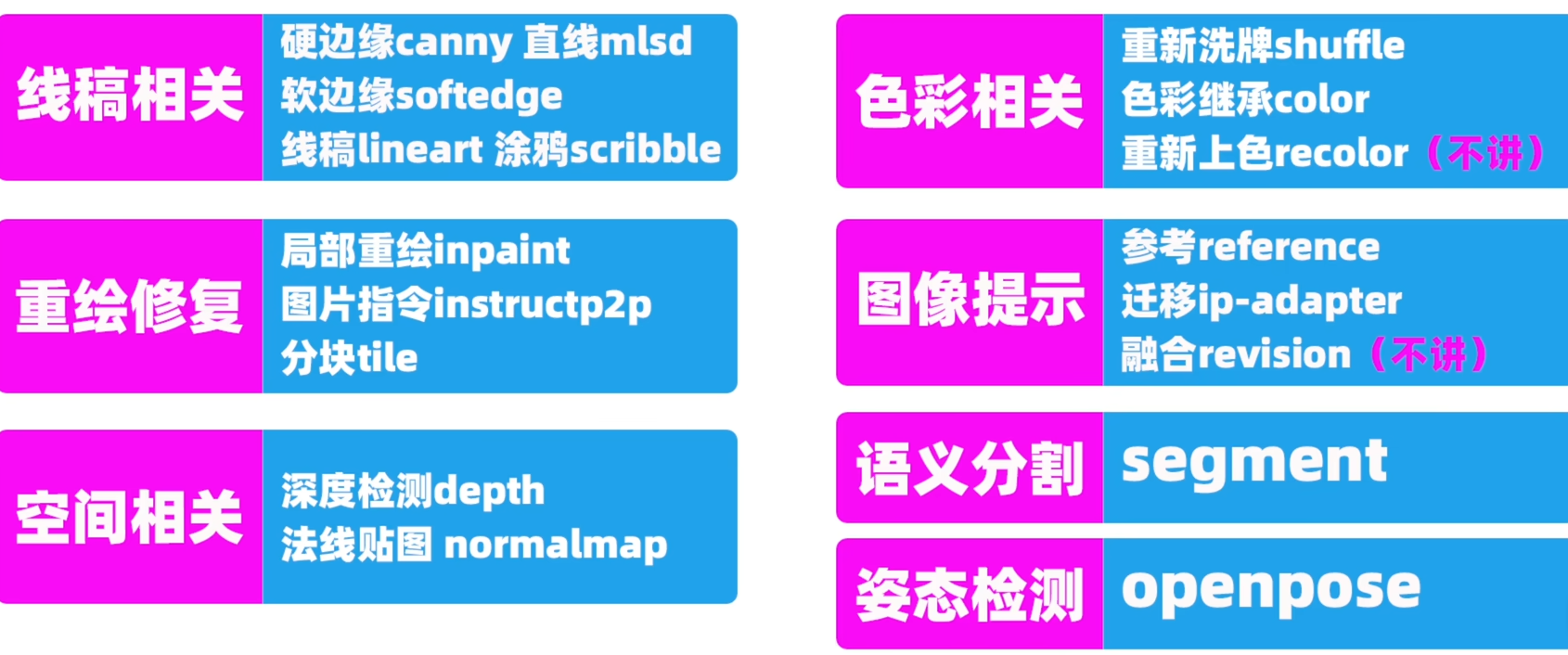
Control Type
Canny、Depth、Openpose、Normal、Seg、Scribble、Mlsd、Hed等15类:
-
首先是最重要的线稿lineart:
预处理器用于提取线稿图lineart image的模型(分为通用和动漫);线稿模型就是线稿controlnet的权重(分为通用和动漫)。注意:【动漫预处理器(得到的图像会有小方格) + 通用线稿模型(通用controlnet不能很好处理小方格)】效果不好。
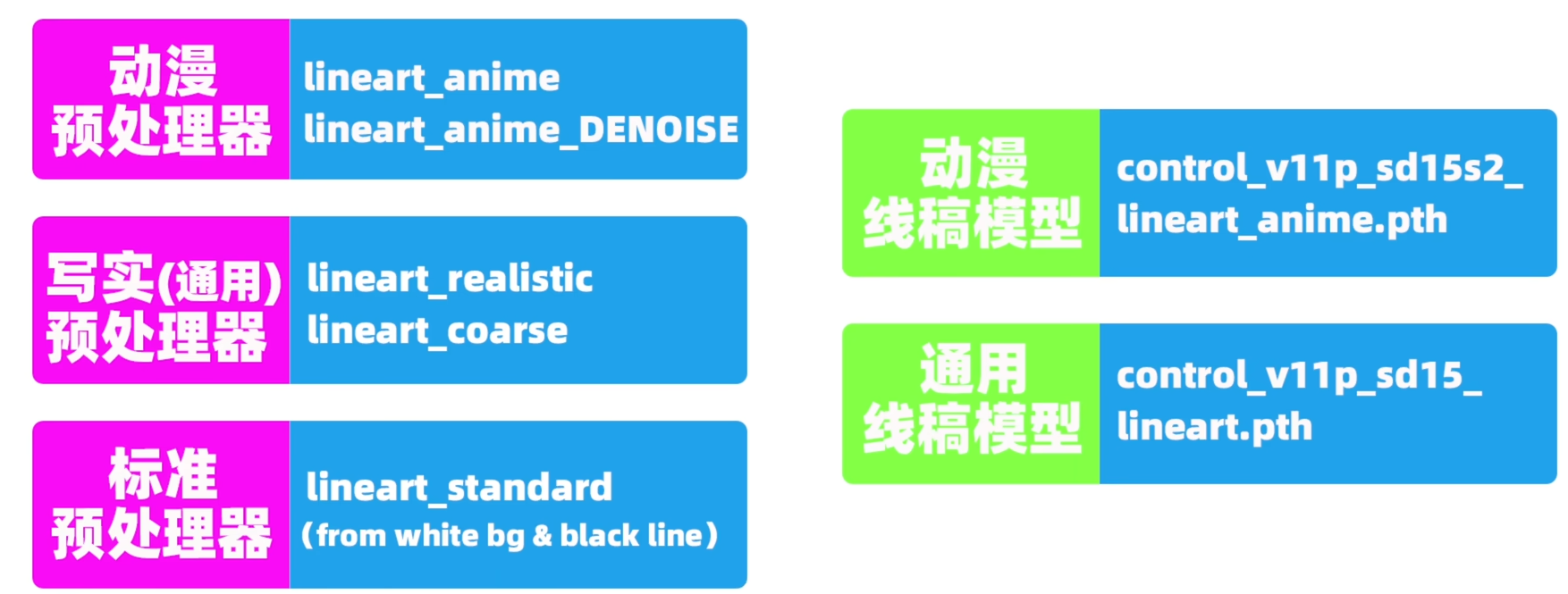
首先介绍通用线稿预处理器:lineart_realistic和lineart_coarse可以提取各种类型图像的lineart,如2D动画、3D真人、3D动画(即2.5D)



然后是动漫线稿预处理器:lineart_anime和lineart_anime_denosise,其中denosise指降噪后的线稿图,可以让prompt有更多的发挥空间。

-
边缘线Canny:
controlnet='lllyasviel/sd-controlnet-canny',黑色背景上有白边的单色图像。

-
深度图Depth:
lllyasviel/sd-controlnet-depth,灰度图像,黑色表示深部区域,白色表示浅层区域。
-
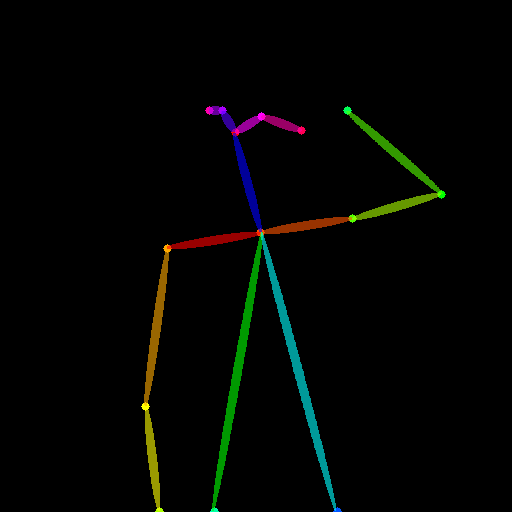
骨骼图像Opse:
controlnet='fusing/stable-diffusion-v1-5-controlnet-openpose'或lllyasviel/sd-controlnet-openpose
-
软边缘线HED:
lllyasviel/sd-controlnet-hed,在黑色背景上具有白色柔和边缘的单色图像。

- 法线贴图Normal Map:
lllyasviel/sd-controlnet-normal

- M-LSD 线:
lllyasviel/sd-controlnet-mlsd,仅由黑色背景上的白色直线组成的单色图像。

- 语义分割seg:
lllyasviel/sd-controlnet-seg

- 人类涂鸦scribble:
lllyasviel/sd-controlnet-scribble

StableDiffusionControlNetPipeline
StableDiffusionControlNetPipeline像其他 diffuser pipeline 一样,可以从huggingface加载预训练权重。
在命令行安装必要的库:
# diffusers依赖
pip install -q diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
# 处理不同condition的依赖
pip install -q opencv-contrib-python
pip install -q controlnet_aux
1. Canny ControlNet
1.1 模型与数据加载
加载图像
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image

调用cv2的Canny算法提取edge图像作为condition
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image

用torch.dtype=torch.float16半精度(half-precision)加载SD(runwaylml/stable-diffusion-v1-5)和ControlNet-Cnney(lllyasviel/sd-controlnet-canny),实现更快的 Inference。controlnet='lllyasviel/sd-controlnet-canny'
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
# 分布加载StableDiffusion和ControlNet 组成 StableDiffusionControlNetPipeline
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
使用当前最快的Noise Scheduler UniPCMultistepScheduler,减少Inference steps from 50 to 20
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
使用pipe的enable_model_cpu_offload函数实现GPU的自动加载管理,无需手动to("cuda"):因为在推理过程中,模型(如SD)需要多个按顺序运行的模型组件。 在使用 ControlNet 进行 Stable Diffusion 的情况下,我们首先使用 CLIP 文本编码器,然后是 unet 和 controlnet,然后是 VAE 解码器,最后运行safechecker。 大多数组件在推理过程中只运行一次,因此不需要一直占用 GPU 内存。通过启用智能的enable_model_cpu_offload,我们确保 每个组件只在需要时加载到 GPU 中,这样我们就可以显着节省内存消耗。
pipe.enable_model_cpu_offload()
利用 FlashAttention/xformers 注意力层加速(如果没有配置xformers就跳过)
pipe.enable_xformers_memory_efficient_attention()
1.2 模型推理
分别测试加和不加prompt后缀的生成结果:
- prompt 的文本提示应该尽可能地清晰、具体、简洁地描述想要生成的图像,避免模糊、冗长、矛盾的表述。文本提示可以从主体描述、环境氛围、艺术类别、艺术风格、材质、构图、视角、光照、色调等等方面来解构,也可以使用表情符号、角色名、场景名等来增加表现力。
- prompt 的后缀参数可以影响图像生成的质量、分辨率等。不同参数之间要用,隔开。
normal_image = pipe(
["Trump"],
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"],
generator=generator[0],
num_inference_steps=20,
)

# positive prompt后缀
good_image = pipe(
["Trump, best quality, extremely detailed"],
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"],
generator=generator[0],
num_inference_steps=20,
)

1.3 DreamBooth微调
还可以用DreamBooth来 fine-tune ControlNet模型 :加载StableDiffusionPipeline(在Mr Potato Head人物subject上DreamBooth微调过的StableDiffusion)和ControlNet(前面一模一样的canny的controlnet)组成StableDiffusionControlNetPipeline

model_id = "sd-dreambooth-library/mr-potato-head"
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, # StableDiffusionPipeline的model_id
controlnet=controlnet, # ControlNetModel实例
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention() # 如果没有装xformers注释掉即可
推理
generator = torch.manual_seed(2)
prompt = "a photo of sks mr potato head, best quality, extremely detailed"
output = pipe(
prompt,
canny_image,
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
generator=generator,
num_inference_steps=20,
)

2. Pose ControlNet
2.1 数据和模型加载
加载瑜伽数据
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://hf.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)

调用controlnet_aux的OpenposeDetector提取图片中的pose
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
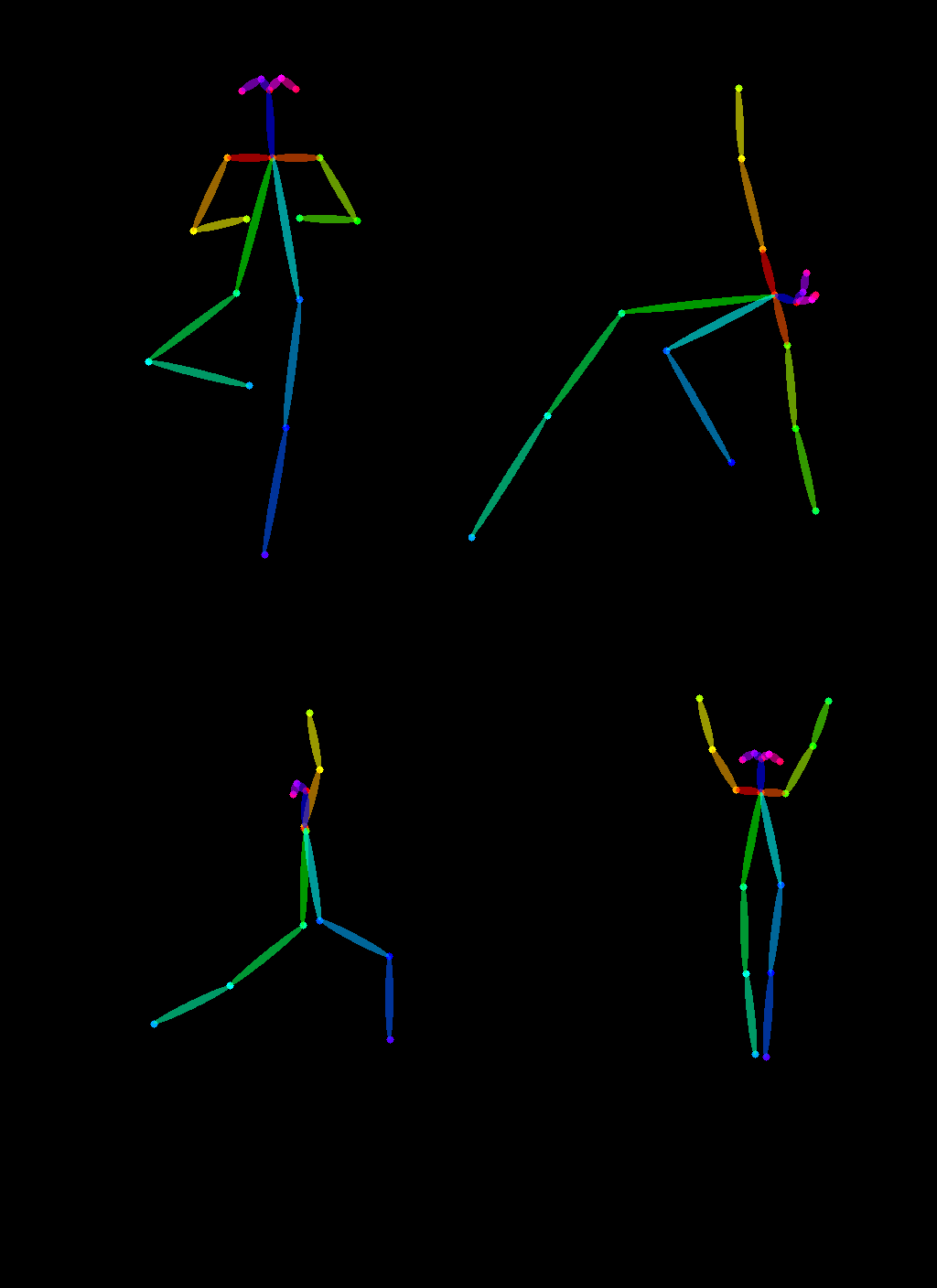
加载StableDiffusionControlNetPipeline,controlnet ='fusing/stable-diffusion-v1-5-controlnet-openpose'
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention() # 如果没有装xformers注释掉即可
2.2 模型推理
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)

ControlNet 源码解析
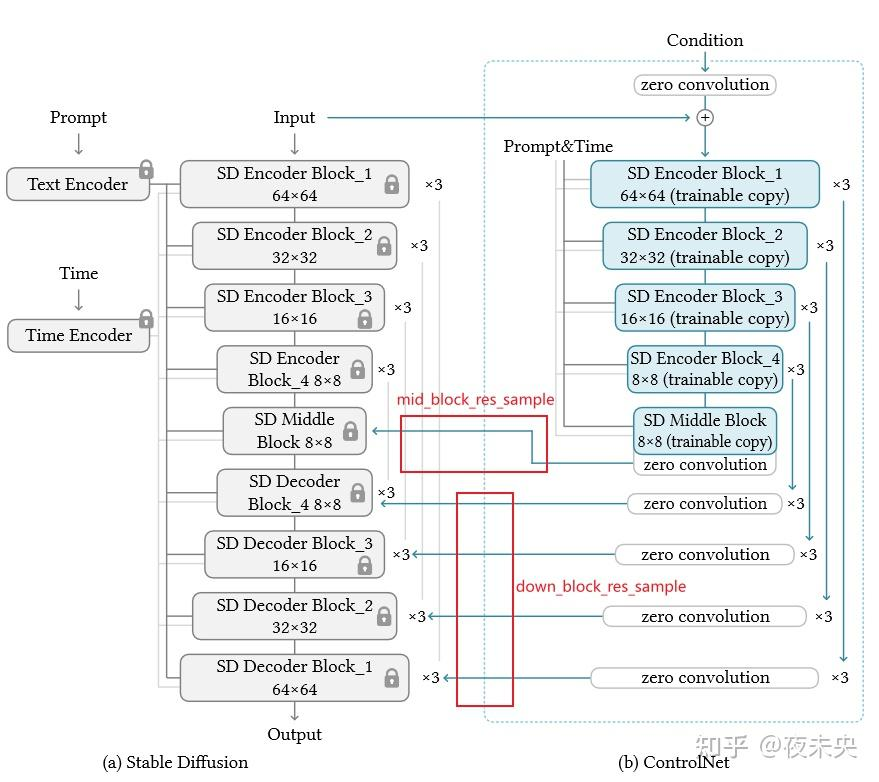
整个StableDiffusionControlNetPipeline包含
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
image_encoder: CLIPVisionModelWithProjection = None,
这些组件完整的流程在StableDiffusionControlNetPipeline的__call__函数中,其中最关键的2个:左边的UNet2DConditionModel是SD中UNet2D的改进,右边的ControlNetModel用于提取condition_images的特征插入左边的UNet中。
StableDiffusionControlNetPipeline类的call方法
根据prompt和image和ip_adapter_image的引导,生成新的图像。
输入:prompt、ip_adapter_image(reference_image)、image(condition_image),输出:output_image。
编码 prompt
IP-Adapter的关键设计是分离文本特征和图像特征的交叉注意层的解耦交叉注意机制。实现image_prompt。
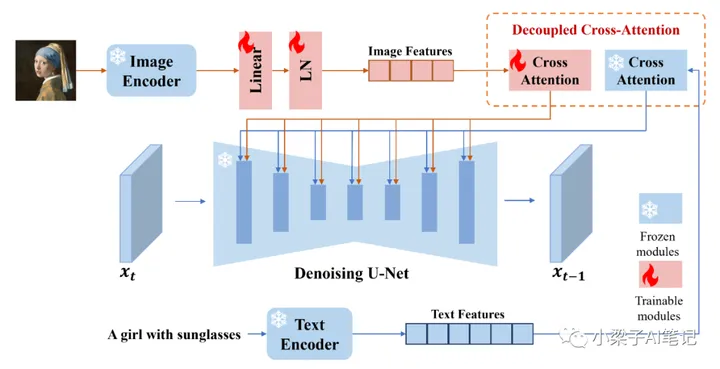
采取classifier_free_guidance策略,构造text_embedding和image_embedding,用于后续UNet的cross attention作为KV:
- 对于
text_prompt(prompt),用CLIP text encoder编码文本提示后,与negative_prompt_embeds进行concat,得到prompt_embeds; - 如果有
image_prompt(ip_adapter_image),用CLIP image encoder编码参考图片后,与negative_prompt_embeds进行concat,得到image_embeds。
# 3. Encode input prompt
text_encoder_lora_scale = (
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
)
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
self.do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
clip_skip=self.clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if self.do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
if ip_adapter_image is not None:
image_embeds, negative_image_embeds = self.encode_image(ip_adapter_image, device, num_images_per_prompt)
if self.do_classifier_free_guidance:
image_embeds = torch.cat([negative_image_embeds, image_embeds])
预处理condition image、timesteps、latents
Prepare image:进入VAE前将image转化为tensor,设置长宽等。
Prepare timesteps:设置timestep
Prepare latent variables:如果传入预计算好的latents直接用;否则随机初始 latents tensor,shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)。
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
image = self.prepare_image(
image=image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
height, width = image.shape[-2:]
elif isinstance(controlnet, MultiControlNetModel):
images = []
for image_ in image:
image_ = self.prepare_image(
image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=self.do_classifier_free_guidance,
guess_mode=guess_mode,
)
images.append(image_)
image = images
height, width = image[0].shape[-2:]
else:
assert False
# 5. Prepare timesteps
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
self._num_timesteps = len(timesteps)
# 6. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
循环去噪(controlnet输出与unet结合)
- 对于
ControlNetModel类,不用CFG,输入的 latents 是control_model只包含1份latents,同理输入的controlnet_prompt_embeds也去掉了negative prompt。- 推理过程只需要输入
latents(control_model_input)、text_embedding(controlnet_prompt_embeds)、condition_image(image);而不需要referenece_image(ip_adapter_image) - 输出
down_block_res_samples和mid_block_res_sample,对应下图中不同分辨率的feature,用于插入主干的UNet中。
- 推理过程只需要输入
因为ControlNetModel类做非CFG,它的输出shape是UNet2DConditionModel类的一半,因此在插入UNet2DConditionModel类之前,需要将shape相同的纯0的feature与down_block_res_samples和mid_block_res_sample进行concat。
- 对于
UNet2DConditionModel类,做CFG,输入的 latents 是latent_model_input包含2份latents。- 推理过程只需要输入
latents(latent_model_input)、text_embedding(prompt_embeds)、image_embedding(added_cond_kwargs,即ip_adapter_image)、以及ControlNet的输出(down_block_res_samples和mid_block_res_sample); - 输出
noise_pred。然后执行CFG,然后去噪 x t → x t − 1 x_t \to x_{t-1} xt→xt−1
- 推理过程只需要输入
最后使用VAE解码latents得到image。
# 8. Denoising loop
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and self.do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and self.do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
timestep_cond=timestep_cond,
cross_attention_kwargs=self.cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
added_cond_kwargs=added_cond_kwargs, # image embedding
return_dict=False,
)[0]
# perform guidance
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[0]
ControlNetModel类
- 输入
latents(sample),text_embedding(encoder_hidden_states)、condition_image(controlnet_cond)
def forward(
self,
sample: torch.FloatTensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
controlnet_cond: torch.FloatTensor,
conditioning_scale: float = 1.0,
class_labels: Optional[torch.Tensor] = None,
timestep_cond: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guess_mode: bool = False,
return_dict: bool = True,
) -> Union[ControlNetOutput, Tuple[Tuple[torch.FloatTensor, ...], torch.FloatTensor]]:
- 构造 time emebdding( time_emebd + class_emebd + text_emebd ),它首先将timestep转换为time_embedding。如果有classs embedding,则还会将class label转换为class_embedding,并将其添加到time_embedding中。此外,如果配置中指定了其他类型的嵌入(如text_embedding),则还会将text_embedding并添加到time_embedding中。最后,所有这些embedding向量被
concat在一起并返回。
# 1. time
timesteps = timestep
if not torch.is_tensor(timesteps):
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
# This would be a good case for the `match` statement (Python 3.10+)
is_mps = sample.device.type == "mps"
if isinstance(timestep, float):
dtype = torch.float32 if is_mps else torch.float64
else:
dtype = torch.int32 if is_mps else torch.int64
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
elif len(timesteps.shape) == 0:
timesteps = timesteps[None].to(sample.device)
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
timesteps = timesteps.expand(sample.shape[0])
t_emb = self.time_proj(timesteps)
# timesteps does not contain any weights and will always return f32 tensors
# but time_embedding might actually be running in fp16. so we need to cast here.
# there might be better ways to encapsulate this.
t_emb = t_emb.to(dtype=sample.dtype)
emb = self.time_embedding(t_emb, timestep_cond)
aug_emb = None
if self.class_embedding is not None:
if class_labels is None:
raise ValueError("class_labels should be provided when num_class_embeds > 0")
if self.config.class_embed_type == "timestep":
class_labels = self.time_proj(class_labels)
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
emb = emb + class_emb
if self.config.addition_embed_type is not None:
if self.config.addition_embed_type == "text":
aug_emb = self.add_embedding(encoder_hidden_states)
elif self.config.addition_embed_type == "text_time":
if "text_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
)
text_embeds = added_cond_kwargs.get("text_embeds")
if "time_ids" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
)
time_ids = added_cond_kwargs.get("time_ids")
time_embeds = self.add_time_proj(time_ids.flatten())
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
add_embeds = add_embeds.to(emb.dtype)
aug_emb = self.add_embedding(add_embeds)
emb = emb + aug_emb if aug_emb is not None else emb
- 预处理 condition image,使用
ControlNetConditioningEmbedding编码condition image然后与sample加在一起。因为Stable Diffusion使用类似于VQ-GAN的预处理方法,将整个512×512图像数据集转换为更小的64×64“latents”以进行稳定训练。这要求使用ControlNets将基于图像的条件转换为64×64的特征空间,以匹配卷积大小。ControlNetConditioningEmbedding使用一个由四个卷积层组成,其核大小为4×4,步幅为2×2(由ReLU激活,通道数为16、32、64、128,使用高斯权重初始化,并与完整模型一起进行训练),来将condition图像编码为与sample对应的特征。最后一层为zero conv,self.conv_out = zero_module(nn.Conv2d(256, 320, kernel_size=3, padding=1))。
# 2. pre-process
sample = self.conv_in(sample)
controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
sample = sample + controlnet_cond
zero_module将卷积层权重置零,即为论文当中的零卷积。
# down
output_channel = block_out_channels[0] # 32
controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
controlnet_block = zero_module(controlnet_block) # 权重置零
self.controlnet_down_blocks.append(controlnet_block)
def zero_module(module):
for p in module.parameters():
nn.init.zeros_(p)
return module
- 执行down block:从SD复制过来的DownBlock,执行每层时保留对应的sample(latents) 到
down_block_res_samples中
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
- 执行mid block:从SD复制过来的MidBlock,不用专门保存sample就是。
# 4. mid
if self.mid_block is not None:
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
sample = self.mid_block(
sample,
emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
)
else:
sample = self.mid_block(sample, emb)
- 使用controlnet_block 中的 zero_conv对每层特征进行处理:将经过
ControlNetModel的down_block然后经过zero convolution的结果,全部保存在controlnet_down_block_res_samples当中,再保存到down_block_res_samples中。Middle Block经过zero convolution输出保存在mid_block_res_sample当中。
# 5. Control net blocks
controlnet_down_block_res_samples = ()
for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
down_block_res_sample = controlnet_block(down_block_res_sample)
controlnet_down_block_res_samples = controlnet_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = controlnet_down_block_res_samples
mid_block_res_sample = self.controlnet_mid_block(sample)
- 多condition合并和缩放:对于
MultiControlNetModel的推理过程,在有多个 condition_image 情况下,down_block_res_samples 以及 mid_block_res_sample 则为所有类型的 condition_image 输出加和。
# 6. scaling
if guess_mode and not self.config.global_pool_conditions:
scales = torch.logspace(-1, 0, len(down_block_res_samples) + 1, device=sample.device) # 0.1 to 1.0
scales = scales * conditioning_scale
down_block_res_samples = [sample * scale for sample, scale in zip(down_block_res_samples, scales)]
mid_block_res_sample = mid_block_res_sample * scales[-1] # last one
else:
down_block_res_samples = [sample * conditioning_scale for sample in down_block_res_samples]
mid_block_res_sample = mid_block_res_sample * conditioning_scale
if self.config.global_pool_conditions:
down_block_res_samples = [
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in down_block_res_samples
]
mid_block_res_sample = torch.mean(mid_block_res_sample, dim=(2, 3), keepdim=True)
if not return_dict:
return (down_block_res_samples, mid_block_res_sample)
return ControlNetOutput(
down_block_res_samples=down_block_res_samples, mid_block_res_sample=mid_block_res_sample
)
UNet2DConditionModel类
将ControlNet与Unet输出进行相加。
CrossAttnDownBlock2D 的实现,controlnet 对残差使用求和处理,而非张量拼接。
- 输入:
latents(sample)、text_embedding(encoder_hidden_states)、image_embedding(added_cond_kwargs)、ControlNet的输出特征(down_block_additional_residuals, mid_block_additional_residual)
def forward(
self,
sample: torch.FloatTensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
class_labels: Optional[torch.Tensor] = None,
timestep_cond: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
: Optional[torch.Tensor] = None,
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[UNet2DConditionOutput, Tuple]:
- 构造复合time_embedding:对
time_emb、class_emb、text_emb、image_emb进行concat
# 1. time
timesteps = timestep
if not torch.is_tensor(timesteps):
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
# This would be a good case for the `match` statement (Python 3.10+)
is_mps = sample.device.type == "mps"
if isinstance(timestep, float):
dtype = torch.float32 if is_mps else torch.float64
else:
dtype = torch.int32 if is_mps else torch.int64
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
elif len(timesteps.shape) == 0:
timesteps = timesteps[None].to(sample.device)
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
timesteps = timesteps.expand(sample.shape[0])
t_emb = self.time_proj(timesteps)
# `Timesteps` does not contain any weights and will always return f32 tensors
# but time_embedding might actually be running in fp16. so we need to cast here.
# there might be better ways to encapsulate this.
t_emb = t_emb.to(dtype=sample.dtype)
emb = self.time_embedding(t_emb, timestep_cond)
aug_emb = None
if self.class_embedding is not None:
if class_labels is None:
raise ValueError("class_labels should be provided when num_class_embeds > 0")
if self.config.class_embed_type == "timestep":
class_labels = self.time_proj(class_labels)
# `Timesteps` does not contain any weights and will always return f32 tensors
# there might be better ways to encapsulate this.
class_labels = class_labels.to(dtype=sample.dtype)
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
if self.config.class_embeddings_concat:
emb = torch.cat([emb, class_emb], dim=-1)
else:
emb = emb + class_emb
if self.config.addition_embed_type == "text":
aug_emb = self.add_embedding(encoder_hidden_states)
elif self.config.addition_embed_type == "text_image":
# Kandinsky 2.1 - style
if "image_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
)
image_embs = added_cond_kwargs.get("image_embeds")
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
aug_emb = self.add_embedding(text_embs, image_embs)
elif self.config.addition_embed_type == "text_time":
# SDXL - style
if "text_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
)
text_embeds = added_cond_kwargs.get("text_embeds")
if "time_ids" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
)
time_ids = added_cond_kwargs.get("time_ids")
time_embeds = self.add_time_proj(time_ids.flatten())
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
add_embeds = add_embeds.to(emb.dtype)
aug_emb = self.add_embedding(add_embeds)
elif self.config.addition_embed_type == "image":
# Kandinsky 2.2 - style
if "image_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
)
image_embs = added_cond_kwargs.get("image_embeds")
aug_emb = self.add_embedding(image_embs)
elif self.config.addition_embed_type == "image_hint":
# Kandinsky 2.2 - style
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
)
image_embs = added_cond_kwargs.get("image_embeds")
hint = added_cond_kwargs.get("hint")
aug_emb, hint = self.add_embedding(image_embs, hint)
sample = torch.cat([sample, hint], dim=1)
emb = emb + aug_emb if aug_emb is not None else emb
if self.time_embed_act is not None:
emb = self.time_embed_act(emb)
- 构造KV(encoder_hidden_states):可以选择使用
text_proj、text_image_proj、image_proj、ip_image_proj四种模式,使用text_prompt(text_embedding)和reference_image(image_embedding)来构造KV。
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
# Kadinsky 2.1 - style
if "image_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
)
image_embeds = added_cond_kwargs.get("image_embeds")
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
# Kandinsky 2.2 - style
if "image_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
)
image_embeds = added_cond_kwargs.get("image_embeds")
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "ip_image_proj":
if "image_embeds" not in added_cond_kwargs:
raise ValueError(
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'ip_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
)
image_embeds = added_cond_kwargs.get("image_embeds")
image_embeds = self.encoder_hid_proj(image_embeds).to(encoder_hidden_states.dtype)
encoder_hidden_states = torch.cat([encoder_hidden_states, image_embeds], dim=1)
- 处理latents:
# 2. pre-process
sample = self.conv_in(sample)
- 执行down block:正常保存UNet的
down_block_res_samples,最后将每层UNet的feature和ControlNetModel的feature直接相加,而不是concat!!
# 3. down
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
**additional_residuals,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale)
down_block_res_samples += res_samples
if is_controlnet:
new_down_block_res_samples = ()
for down_block_res_sample, down_block_additional_residual in zip(
down_block_res_samples, down_block_additional_residuals
):
down_block_res_sample = down_block_res_sample + down_block_additional_residual
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = new_down_block_res_samples
- 执行mid block:也是一样,最后
UNet的feature和ControlNetModel的feature直接相加,而不是concat!!
# 4. mid
if self.mid_block is not None:
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
sample = self.mid_block(
sample,
emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = self.mid_block(sample, emb)
# To support T2I-Adapter-XL
if (
is_adapter
and len(down_intrablock_additional_residuals) > 0
and sample.shape == down_intrablock_additional_residuals[0].shape
):
sample += down_intrablock_additional_residuals.pop(0)
if is_controlnet:
sample = sample + mid_block_additional_residual
- 执行up block:正常SD的up block
# 5. up
for i, upsample_block in enumerate(self.up_blocks):
is_final_block = i == len(self.up_blocks) - 1
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
# if we have not reached the final block and need to forward the
# upsample size, we do it here
if not is_final_block and forward_upsample_size:
upsample_size = down_block_res_samples[-1].shape[2:]
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
upsample_size=upsample_size,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
upsample_size=upsample_size,
scale=lora_scale,
)
- 后处理:最后过一些conv和norm就输出
pred noise
# 6. post-process
if self.conv_norm_out:
sample = self.conv_norm_out(sample)
sample = self.conv_act(sample)
sample = self.conv_out(sample)



















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











