







文章目录
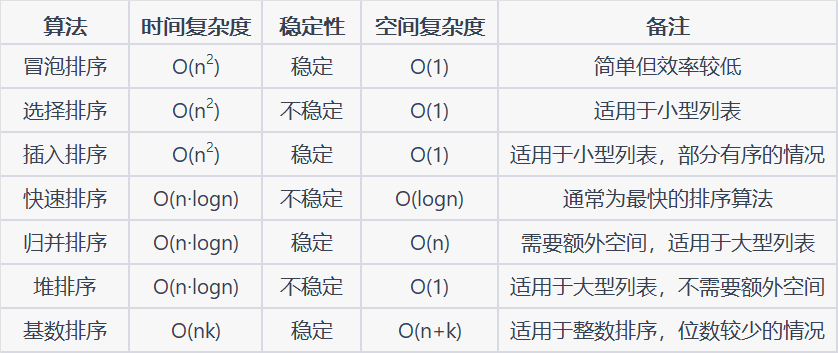
1 冒泡排序 O ( N 2 ) O(N^2) O(N2)(与数据状况无关)
外层循环:n个数需要冒n-1个泡上去,剩下的一个必然是最小的。所以外层循环执行n-1轮
内层循环:比大小,第1个泡需要比n-1次,第2个泡,比较n-2次…
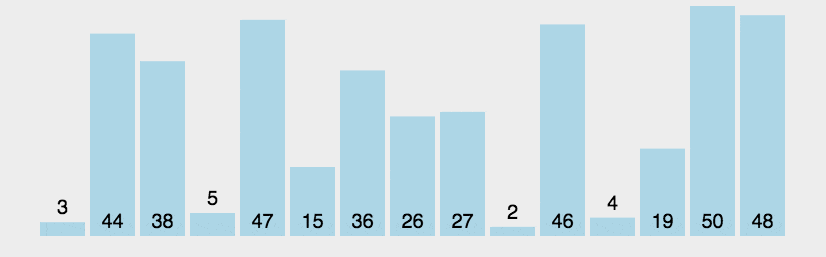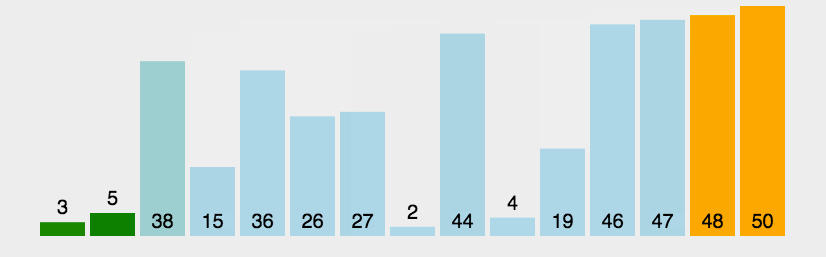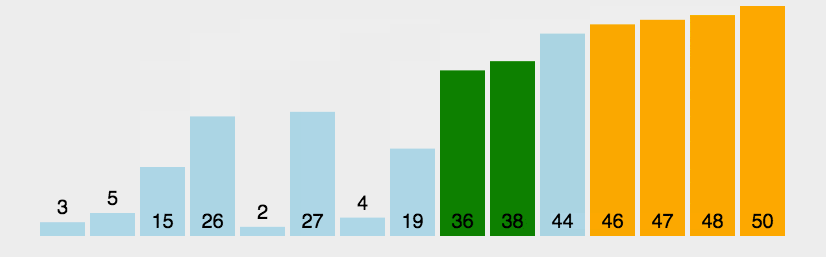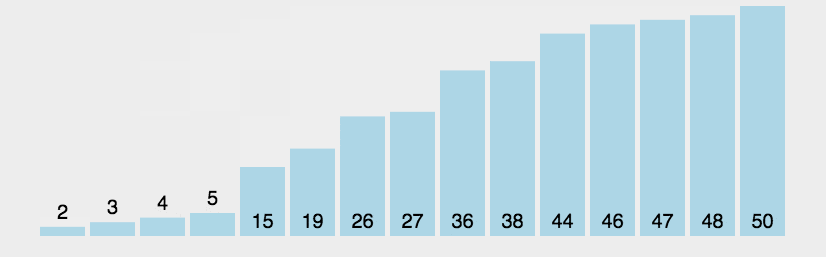
#incldue <vector>
#include <utility>
void bubbleSort(std::vector<int>& arr)
{
for (int i = 0; i < arr.size() - 1; i++) {
for (int j = 0; j < arr.size() - 1 - i; j++) {
if (arr[j] > arr[j+1]) { // 相邻元素两两对比
std::swap(arr[j], arr[j+1]);
}
}
}
}
2 选择排序 O ( N 2 ) O(N^2) O(N2)(与数据状况无关)
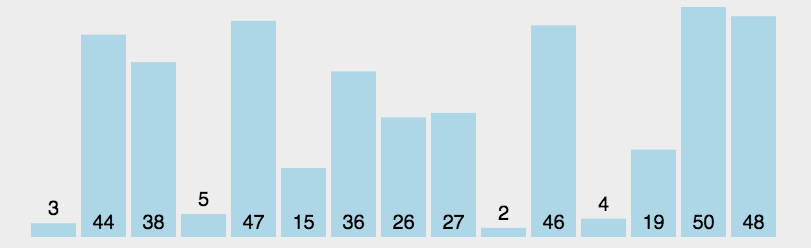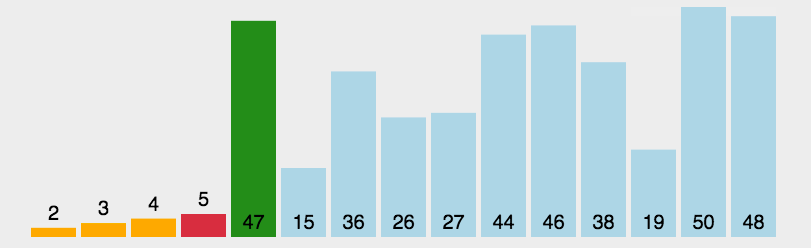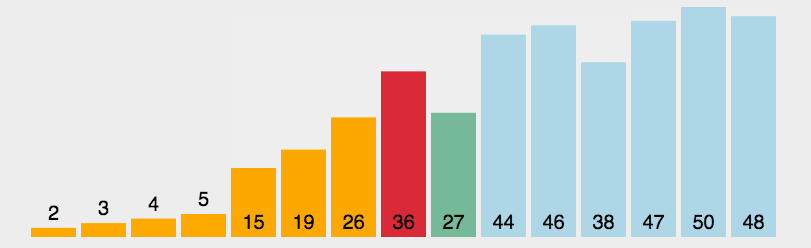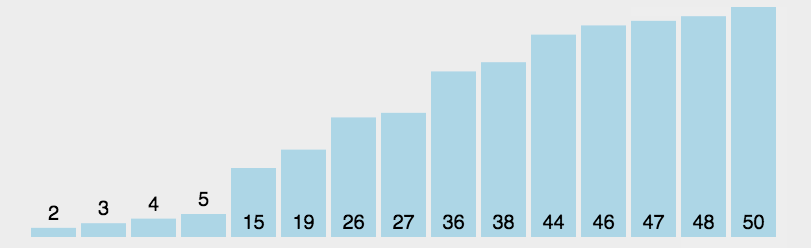
选择: 每次从待排序序列中选择最小的一个放在已排序序列的后一个位置
#include <vector>
#include <utility>
void selectionSort(std::vector<int>& arr){
int len = arr.size();
if (arr.empty() || len < 2) return;
for (int i = 0; i < len -1; i++) { // len -1 位置不用再选了,没得选
int minIndex = i;
for (int j = i + 1; j < len; j++) { // 在[i+1,len-1]上寻找最小值的下标
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
std::swap(arr[minIndex], arr[i]);
}
}
3 插入排序 O ( N 2 ) O(N^2) O(N2)(与数据状况相关)
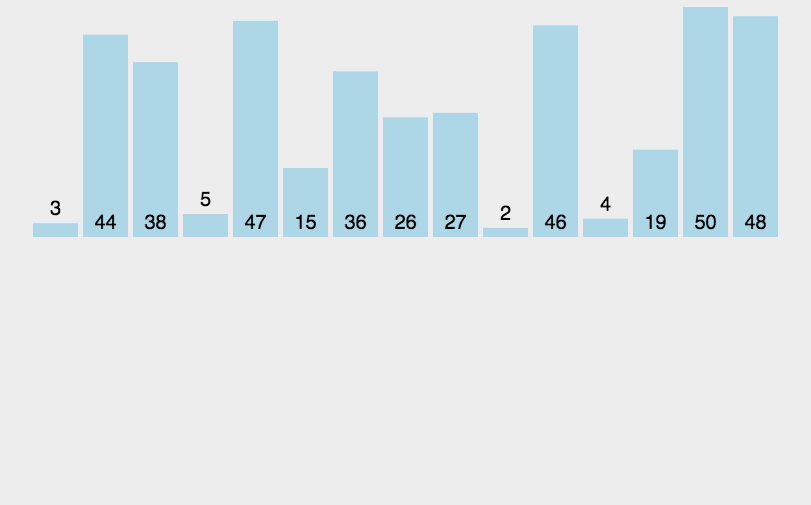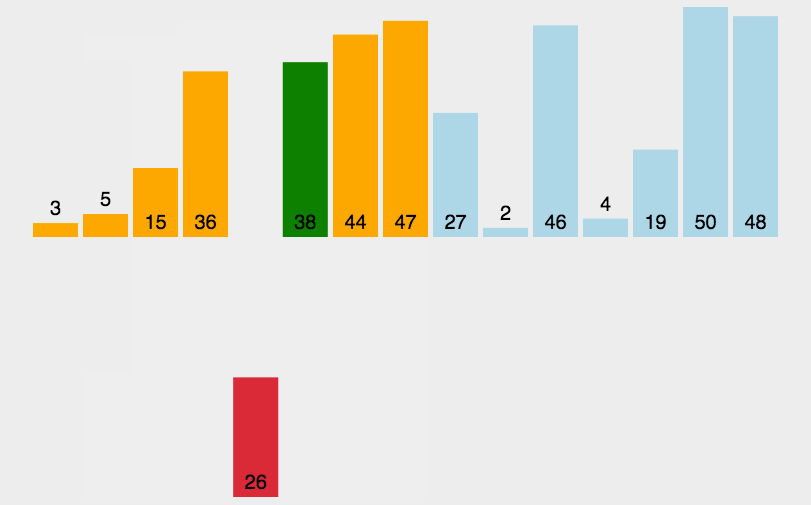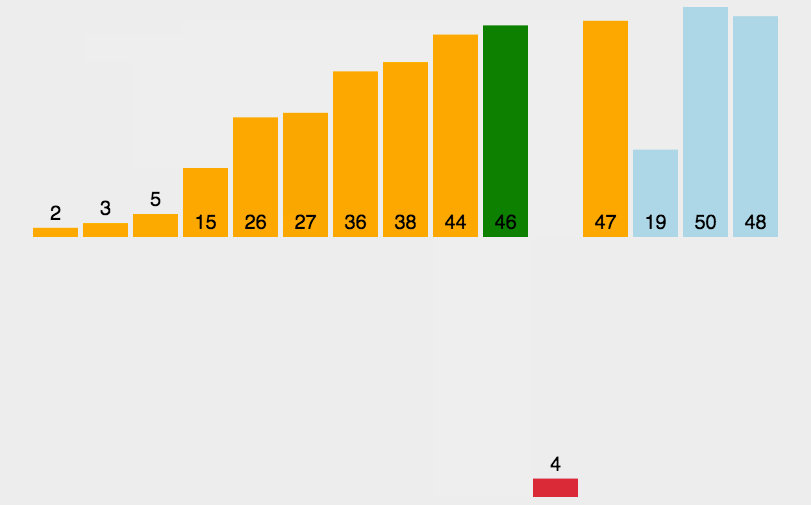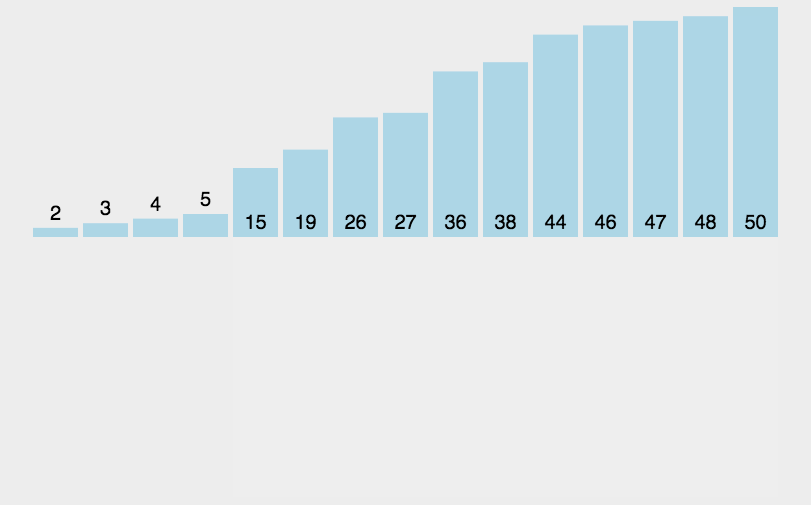
原理类似于对扑克牌手牌进行排序的过程。将未排序的元素逐个插入到已排序部分的合适位置。
逻辑顺序为先做到0~0有序, 然后0~1有序, 0~2 … 0~n-1有序
算法流程为:
- 从第一个元素开始,该元素可以认为已经被排序。
- 从未排序部分取第一个值,插入到已排序部分的适当位置。这个位置的选取方式为:把当前未排序值与左邻值对比,如果更小则交换位置。直到遇到边界或不比左邻值小则结束。(内循环:找适当位置插入)
- 重复步骤2,直到所有元素都被插入到已排序序列中。(外循环:遍历每个未排序的数)
这个不像冒泡排序和选择排序是固定操作(数据状况无关)。插入排序中,如果给的就是有序的,那就外层每层循环做一次比较就完成了,所以会是O(N), 但我们说时间复杂度都是 worst case 所以还是 O ( N 2 ) O(N^2) O(N2)
#include <vector>
#include <utility>
void insertionSort(std::vector<int>& arr)
{
int len = arr.size();
if (arr.empty() || len < 2) return;
// 0~0已经有序了
for (int i = 1; i < len; i++){ // 0~i做到有序
// 把当前值(j+1)对比左邻值(j),比他小则交换,不满足循环条件则说明找到合适位置了
for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--){
std::swap(arr[j+1], arr[j]);
}
}
}
在内层循环中,我们将当前元素 arr[j + 1] 与其左邻元素 arr[j] 进行比较,更小则换位,直到找到合适的插入位置。
循环结束(找到合适的位置)条件为:达到左边界 or 当前值比左邻值大
继续往下看建议先掌握 二分查找和基础递归
4 归并排序 O ( N l o g N ) O(NlogN) O(NlogN)(数据状况无关)
它的核心思想是将待排序的序列不断划分成更小的子序列,直到每个子序列只有一个元素,然后再将这些子序列两两合并,直到最终整个序列有序。
下面是归并排序的一般步骤:
- 分割:将待排序的序列从中间位置分割成两个子序列,不断递归地将每个子序列继续分割,直到每个子序列只剩下一个元素。
- 合并:将两个有序的子序列合并成一个有序序列。从两个子序列的第一个元素开始比较,将较小的元素放入临时数组中,并将对应子序列的索引向后移动一位,直到其中一个子序列的元素全部放入临时数组中。然后将另一个子序列的剩余元素直接放入临时数组中。
- 重复合并:重复进行合并操作,直到所有子序列都合并为一个有序序列。
始终都是 O(NlogN) 的时间复杂度,与数据无关。虽然相对前面的冒泡、选择、插入排序更快,但是空间复杂度为O(N)
#include <vector>
#include <utility>
// 第二阶段:merge阶段时,L~M 和 M~R 之间的数必然有序
void merge(std::vector<int>& arr, int L, int M, int R)
{
std::vector help(R - L + 1);
int i = 0; // 临时数组的起始索引
int p1 = L; // 左半部分的起始索引
int p2 = M + 1; // 右半部分的起始索引
//外排序,把两个子数组中的元素从小到大放到help数组
while (p1 <= M && p2 <= R){
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
// 如果左边部分还有剩的,全部依次加到help的末尾
while (p1 <= M){
help[i++] = arr[p1++];
}
// 同理如果右边还有剩的
while (p2 <= R){
help[i++] = arr[p2++];
}
// 结束,把临时数组的内容覆盖到原数组中
for (i = 0; i < R - L + 1; i++){
arr[L + i] = help[i]; // 注意arr从L位置开始写入的
}
}
// 第一阶段拆分
void mergeSort(std::vector<int>& arr, int L, int R)
{
if (L == R) return; // 拆分完毕,不能再拆了
int mid = L + ((R - L) >> 1);
mergeSort(arr, L, mid);
mergeSort(arr, mid+1, R);
merge(arr, L, mid, R);
}
时间复杂度(参考2.1 master公式)
- T ( N ) = 2 ⋅ T ( N 2 ) + O ( N ) T(N) = 2·T(\frac{N}{2})+O(N) T(N)=2⋅T(2N)+O(N)
- a = 2; b = 2; d = 1
- l o g a b = 1 = d log_ab=1=d logab=1=d,所以时间复杂度为 O ( N ⋅ l o g N ) O(N·logN) O(N⋅logN)
空间复杂度: O ( N ) O(N) O(N) 。因为每次merge的时候开辟一块空间,大小为N
4.1 扩展:求数组小和
题目:在一个数组中,每一个数左边比当前数小的数累加起来,叫做这个数组的小和。求一个数组的小和。
例子:[1,3,4,2,5]
1左边比1小的数,无
3左边比3小的数,1
4左边比4小的数,1、3
2左边比2小的数,1
5左边比5小的数,1、3、4、2
所以小和为1+1+3+1+1+3+4+2=16
要求时间复杂度O(NlogN),空间复杂度O(N)
- 如果每个位置的元素都遍历一遍左边所有元素,找出比它小的数,求和,很简单就能得到结果,时间复杂度为 O ( N 2 ) O(N^2) O(N2)
- 转变思维:不是找左边有多少比当前位置的数更小的数,然后求和,而是统计右边有多少个比当前位置的数更大的数,当前数就该累加多少次,而这个过程在归并排序中的外排序中就可以做到。
- 归并排序过程中,从下往上看,每次合并两个有序数组时,就能知道每个数的当前比他大的数有多少个,然后累加,归并排序结束,则小和也计算结束
具体讲解视频精准空降,比看文字可好多了
#include <iostream>
#include <vector>
// 左右两组合并
long long merge(std::vector<int>& arr, int left, int mid, int right)
{
std::vector<int> temp(right - left + 1); // 临时数组用于存储合并后的结果
int i = 0; // 临时数组的起始索引
int p1 = left; // 左半部分的起始索引
int p2 = mid + 1; // 右半部分的起始索引
long long count = 0; // 记录小和的累加和
while (p1 <= mid && p2 <= right) {
// 只有在左组比右组小时产生小和
count += arr[p1] < arr[p2] ? (right - p2 + 1) * arr[p1] : 0;
help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= mid) temp[i++] = arr[p1++];
while (p2 <= right) temp[i++] = arr[p2++];
// 将临时数组的结果复制回原数组
for (i = 0; i < R - L + 1; i++) {
arr[left + i] = temp[i];
}
return count;
}
long long process(std::vector<int>& arr, int left, int right)
{
if (left >= right) {
return 0;
}
int mid = left + ((right - left) >> 1);
long long leftCount = process(arr, left, mid); // 左半部分的小和
long long rightCount = process(arr, mid + 1, right); // 右半部分的小和
long long mergeCount = merge(arr, left, mid, right); // 左右侧merge过程中产生的小和
return leftCount + rightCount + mergeCount; // 总的小和
}
long long calculateSmallSum(std::vector<int>& arr)
{
if (arr == nullptr || arr.size() < 2)
return 0;
return process(arr, 0, arr.size() - 1);
}
int main()
{
std::vector<int> arr = {3, 1, 4, 2, 5};
long long smallSum = calculateSmallSum(arr);
std::cout << "Small Sum: " << smallSum << std::endl;
return 0;
}
4.2 扩展:求数组中逆序对的数量
一个数组为3,2,4,5,0,则逆序对为{(3,2), (3,0), (2,0), (4,0), (5,0)}5对。
这个题与4.1完全等效。4.1求的是右边有多少个数比当前元素大,而这里需要求的是右边
有多少个数比当前数更小。右边有多少个小的数,就能跟当前数组成多少个逆序对。
5 快速排序 O ( N l o g N ) O(NlogN) O(NlogN)
3.0版本快排,随机选择中枢值,并放到数组末尾。后面的流程与正常快排相同。比较详细的文章请参考这里
#include <iostream>
#include <vector>
#include <random> // 包含随机数生成器的头文件
#include <utility>
// 随机选择中枢元素
int selectPivot(std::vector<int>& arr, int low, int high)
{
// 创建一个随机数引擎
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(low, high); // 创建一个分布,指定范围
int randomIndex = dis(gen); // 生成一个随机索引
std::swap(arr[randomIndex], arr[high]); // 将中枢元素放在数组末尾
return arr[high];
}
// 快速排序函数
void quickSort(std::vector<int>& arr, int low, int high)
{
if (low < high) {
// 选取枢轴元素----如果是基础快排,这里直接选择第1个或最后一个作为中枢即可
int pivot = selectPivot(arr, low, high);
// 将小于枢轴的元素放在数组的前面,大于枢轴的元素放在数组后面
int i = low - 1; // i充当一个指针,指向数组的前面部分
for (int j = low; j < high; ++j) {
if (arr[j] < pivot) {
++i;
std::swap(arr[i], arr[j]);
}
}
// 最后才将枢轴元素放在正确的位置,i+1左边的数都比i位置小,i+1右边的都比它大
std::swap(arr[i + 1], arr[high]);
// 递归地对枢轴左侧和右侧的子数组进行排序
quickSort(arr, low, i);
quickSort(arr, i + 2, high);
}
}
6 堆排序 O ( N l o g N ) O(NlogN) O(NlogN)
更详细的讲解,请参考此文章
堆结构本身比堆排序的意义更加重大
堆的性质:
- 是一棵完全二叉树
- 每个节点的值都大于或等于其子节点的值,为大根堆;反之为小根堆。构建大根堆的时间复杂度为O(N)
- 一般用数组来表示。数组下标与堆的逻辑对应关系
- 位置 i i i 的左孩子节点: 2 i + 1 2i+1 2i+1
- 位置 i i i 的右孩子节点: 2 i + 2 2i+2 2i+2
- 位置 i i i 的父节点: i − 1 2 \Large\frac{i-1}{2} 2i−1
- 优先级队列不是队列,是堆
大根堆(可不看)
- 只能保证每个节点是以该节点为根的二叉树的最大值,其下所有节点并没有任何顺序可言(左子树和右子树的数没啥关系)。
- 主要应用是快速获取一堆数中的最大值。因为大根堆确保根节点是整个堆中的最大值,所以可以在常数时间内(O(1))获取堆中的最大元素。应用包括但不限于:
- 优先队列:在优先队列中,每个元素都有一个相关的优先级,而大根堆允许高优先级的元素优先出队。所以优先级队列不是队列,是堆
- 堆排序:堆排序是一种基于大根堆的排序算法。它使用大根堆来不断取出最大值并将其放入已排序的部分,从而实现排序。
- Top K 问题:寻找一堆数中的前 K 个最大值或最小值是一个常见的问题,大根堆可以帮助高效解决这类问题。
- 滑动窗口问题:需要在一个移动的窗口内快速找到最大值或最小值,大根堆可以帮助高效地维护窗口内的元素,并快速获取最大值或最小值。
堆结构的两个操作
- heapInsert: 在已有的大根堆中插入一个新的元素,从下往上冒。注意新的元素在大根堆范围的紧后一个位置索引(比如大根堆是0~9号索引,则待插入元素应该放置在10号索引位置)
void heapInsert(std::vector<int>& arr, int index) { while (arr[index] > arr[(index - 1) / 2]{ swap(arr[index], arr[(index-1) / 2]); index = (index - 1) / 2; } } - heapify: 将一个以 index 为根节点的子树或子堆调整为最大堆,通过不断调用这个函数,可以将整个数组转换为最大堆
void heapify(std::vector<int>& arr, int index, int heapSize) { int largest = index; int left = 2 * index + 1; // 左孩子下标 while (left < heapSize){ // 两个孩子中较大的,下标给largest,注意判断右孩子不能越界,=heapSize是越界 largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left; // 父和孩子比较 largest = arr[largest] > arr[index] ? largest : index; if (largest == index) break; swap(arr[largest],arr[index]); index = largest; left = index * 2 + 1; }这段代码复杂度为 l o g N logN logN(完全二叉树层数: c e i l ( l o g 2 ( N ) + 1 ) ceil(log2(N) + 1) ceil(log2(N)+1))
堆排序步骤
-
先把数组构建为大根堆
- 思路1:从0到N-1由前到后逐步构建大根堆,相当于每次在已有大根堆范围新增一个数,调用heapInsert()从下晚上找合适的位置插入,向后扩大堆的范围。构建完毕后,heapSize应该等于数组长度
- 思路2(更快一点):循环每次都将堆的范围逐步向前扩展,同时将当前循环迭代中选择的数组元素作为新的根节点,然后调用 heapify()进行堆的调整。视频地址
-
然后,把数组0位置(根节点)的数与数组末尾的数做交换,这里就提取到了第一个最大值。然后将堆的范围缩小1,即heapSize–。heapSize用于表示堆的范围,必须用一个变量存储
-
对根节点执行heapify(),重新构建大根堆
-
重复2、3步骤即可升序排好!
void heapInsert(std::vector<int>& arr, int index); // 如果用法2则不需要这个函数
void heapify(std::vector<int>& arr, int index, int heapSize);
// 堆排序函数
void heapSort(std::vector<int>& arr)
{
if (arr.size() < 2)
return;
// 1.构建大根堆(法1),每次把堆边界后一个位置的数插入堆中(从下往上冒)
for (int i = 0; i < arr.size(); i++){ // O(N)
heapInsert(arr, i); // O(logN)
}
// 1.构建大根堆(法2),从后往前,新元素作为根节点,调用heapify从上往下找位置放
for (int i = arr.size() - 1; i >= 0; i--){
heapify(arr, i, arr.size());
}
// 2.提出根节点最大值(与数组最后一个元素交换),并缩小堆的边界
int heapSize = arr.size(); // 这个变量必须有,作为堆的边界
std::swap(arr[0], arr[--heapSize];
// 3.重新构建大根堆,除了新来的根节点,下面的子树都还是满足大顶堆的
while(heapSize > 0){ // O(N)
heapify(arr, 0, heapSize);
std::swap(arr[0], arr[--heapSize]);
}
}
6.1 扩展:小范围排序 N l o g K NlogK NlogK
题目: 已知一个几乎有序的数组,几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离可以不超过k,并且k相对于数组来说比较小。请选择一个合适的排序算法针对这个数据进行排序。
解题思路:
- 整个数组的最小值肯定在(0,k-1)范围,在该范围构建小根堆。把堆顶(最小值)弹出放在数组位置0上,跟堆排序类似,把紧后位置k上的数放到小根堆的堆顶
- 调整位置,重新构建小根堆。然后第二小的数会出现在堆顶,再把堆顶放在数组的位置1 上
- 反复操作,如此弹出堆顶的顺序就是数组排好序的顺序。
- 建堆阶段:O(K)
- 插入元素阶段:从下标为k的元素开始,将它们插入到小根堆中。O(logK),因为小根堆的高度是 logK。由于需要插入 N-K 个元素,所以这个阶段的时间复杂度是 O((N-K)logK)。
- 因为K相对N来说足够小,因此忽略不计,直接看做 N l o g K NlogK NlogK
#include <vector>
#include <queue>
#include <algorithm> //std::min
void sortedArrDistanceLessK(std::vector<int> arr, int k)
{
// 默认小根堆,即参数3默认为std::less<T>
std::priority_queue<int, std::vector<int>, std::less<int>> minHeap;
// 构建 O(K)
int index = 0;
for (; index < std::min(arr.size(), k); index++){
minHeap.push(arr[index]);
}
int i = 0;
for (; index < arr.size(); i++; index++){
minHeap.push(arr[index]);// 把数组中,堆范围后的一个元素压入,内部会自动找位置插入
arr[i] = minHeap.top(); // 拿到堆顶元素
minHeap.pop(); // 弹出堆顶元素后,会自动重新构建大根堆
}
// 弹出剩余的元素
while (!minHeap.empty()){
arr[i++] = minHeap.top();
minHeap.pop(); // 注意这里pop操作之后会自动调整数据布局,以满足大根堆性质
}
}
7 基数排序 O ( N ) O(N) O(N)
前面介绍的都是基于比较的排序,而这里则是不基于比较的。
计数排序(很少用):对一定范围内的整数进行排序。它的基本思想是通过统计每个元素出现的次数(需要辅助数组,长度与待排序数组的数值域范围相同),然后根据计数结果将元素按顺序放回原数组,从而实现排序。不适用于范围很大甚至没有范围的排序,因为需要的辅助数组太大了。
基数排序: 必须有进制,比计数排序好,不需要那么多辅助空间。具体讲解视频跳转链接,文字说明在代码部分的后面
#include <vector>
#include <algorithm>
#include <cmath> // pow()
// 最大值的位数
int maxbits(std::vector<int> arr)
{
int max = *std::max_element(arr.begin(), arr.end());
int bits = 0;
while (max != 0){
max /= 10; // 取个位数
bits++;
}
return bits;
}
// 获取数字 num 的第 bit 位数字
int getDigit(int num, int bit) {
// 比如1423 n
return (num / static_cast<int>(std::pow(10, bit - 1))) % 10;
}
void radixSort(std::vector<int> arr, int L, int R, int maxBits)
{
cosnt int base = 10; // 基数为10,即按十进制进行排序
int i = 0, j = 0;
// 桶的长度和原数组长度相同
int n = arr.size();
std::vector<int> tmpArr(n);
// 这个bit是当前十进制位
for (int bit = 1; bit <= maxBits; bit++){// 有多少位就进出多少次
std::vector<int> count(base, 0);
// 统计当前bit位上为0~9的的数分别有多少个
for (i = 0; i <= R; i++) {
j = getDigit(num, bit);
count[j]++;
}
// 将 count 数组变为存放每个数字应该放置的位置索引(看说明1)
// 下标0~9分别表示<=当前下标数的元素个数
// 比如count[5],表示数组中所有数,在当前bit位上的数<=5的个数
for (i = 1; i < base; i++) {
count[i] += count[i - 1];
}
// 原数组的数按当前位进行一次排序,放入临时数组,从右往左遍历原数组(看说明2)
for (int i = n - 1; i >= 0; i--) {
j = getDigit(arr[i], bit);
tmpArr[count[j] - 1] = arr[i];
count[j]--;
}
// 将排好序的临时数组tmpArr拷贝回原数组 arr
//std::copy(tmpArr.begin(), tmpArr.end(), arr.begin() + L);
for (i = L, j = 0; i <= R; i++, j++){
arr[i] = tmpArr[j];
}
}
}
// 仅用于非负数排序
void radixSort(std::vector<int> arr)
{
if (arr.size() < 2)
return;
radixSort(arr, 0, arr.size() - 1, maxbits(arr)); // 重载版本的sort
}
说明1: 计算每个数字在排序后应该放在哪个位置,说白了就是对原数组针对当前bit位做一次排序,里每个元素代表了该数字在排序后的位置的右边界索引(排名)。
说明2: 通常基数排序算法是自右向左的,学术上称之为“最低位优先(Least significant digital,LSD)”,能保证基数排序是稳定的,高位优先也能保证稳定,但写起来非常麻烦。
举例说明(结合代码看): 当对数组 { 170, 045, 075, 090, 802,0 24, 002, 066 } 进行基数排序时,数组中最大的数字是 802,它有3位。
- 初始状态下,count 数组初始化为全零:
count: { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 } - 第一轮排序(个位):
- 统计个位数字出现的次数:
count: { 2, 2, 0, 1, 2, 1, 0, 0, 0, 0 } - 转换为每个数字应该放置的位置索引:
count: { 2, 4, 4, 5, 7, 8, 8, 8, 8, 8 } - 排序结果:
arr: { 170, 90, 802, 2, 24, 45, 75, 66 }
- 统计个位数字出现的次数:
- 第二轮排序(十位):
- 统计十位数字出现的次数:
count: { 0, 2, 0, 0, 1, 0, 1, 2, 1, 1 } - 转换为每个数字应该放置的位置索引:
count: { 0, 2, 2, 2, 3, 3, 4, 6, 7, 8 } - 排序结果:
arr: { 802, 2, 24, 45, 66, 170, 75, 90 }
- 统计十位数字出现的次数:
- 第三轮排序(百位):
- 统计百位数字出现的次数:
count: { 6, 1, 0, 0, 0, 0, 0, 0, 1, 0 } - 转换为每个数字应该放置的位置索引:
count: { 6, 7, 7, 7, 7, 7, 7, 7, 8, 0 } - 排序结果:
arr: { 2, 24, 45, 66, 75, 90, 170, 802 }
- 统计百位数字出现的次数:
在每一轮排序中,count 数组统计了当前位上数字出现的次数,并转换为每个数字在排序后的位置索引。然后,根据 count 数组的统计结果,将原数组中的元素按照当前位的值放入临时数组 tmpArr中。最后,将排好序的 tmpArr拷贝回原数组 arr,完成一轮排序。在所有位都排序完毕后,数组 arr 就是有序的。

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











