







之前的博文写了如何使YOLOv5在检测到目标后进行声音告警提示,本次的博文是对其进行界面上的优化,让其更加方便易用,距离产品更近了一步。
主要参考了这位大佬的代码,并根据自己的需要,进行了添入语音告警的改进。
大佬的展示视频链接在这:YOLOv5检测界面-PyQt5实现
大佬的源码在这:源码github
我在这里做了搬运,感谢各位有开源分享精神的大佬,让更多人的学习之路变得轻松容易
注:我的YOLOv5检测算法是基于YOLOv5的6.1版本,而且是s模型,由此进行模型的训练,得到训练权重;如果不是6.1版本YOLOv5,在运行我这一套东西的时候,可能会出现各种各样的程序报错。包括上一篇我写的博文用的YOLOv5也是6.1版本的:如何使YOLOv5在检测到目标后进行声音告警提示?
一、界面效果展示
因为使用YOLOv5算法自带的检测结果保存功能,保存下来的视频文件没有声音。所以我使用QQ录屏把效果都录下来了,在实验室录得,背景有点嘈杂。
检测界面效果展示
二、进行的改进
1、首先在main.py文件中加入语音告警代码,添加位置如下:
①在此位置加入这三行代码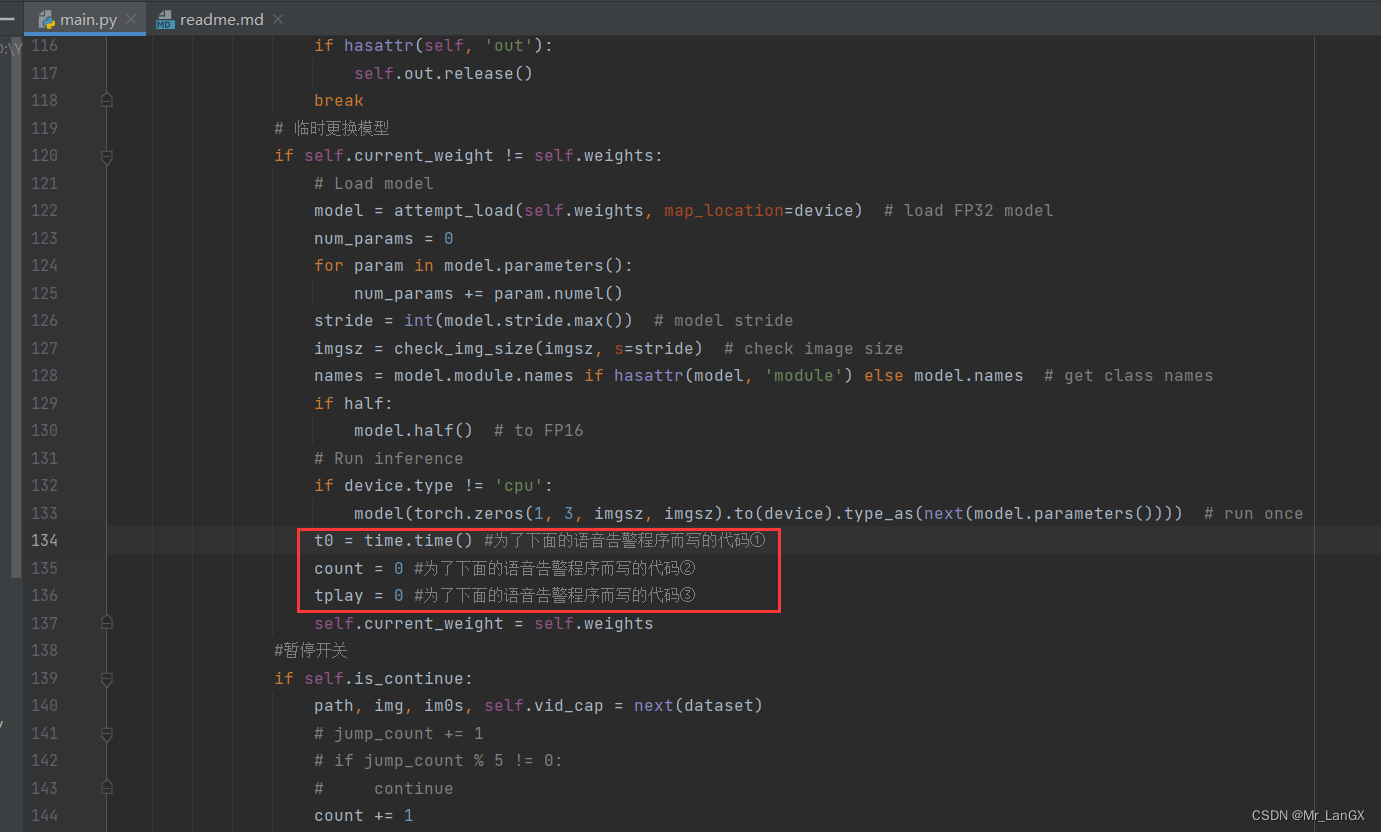
代码如下:
t0 = time.time()
count = 0
tplay = 0
②在此位置加入如下代码
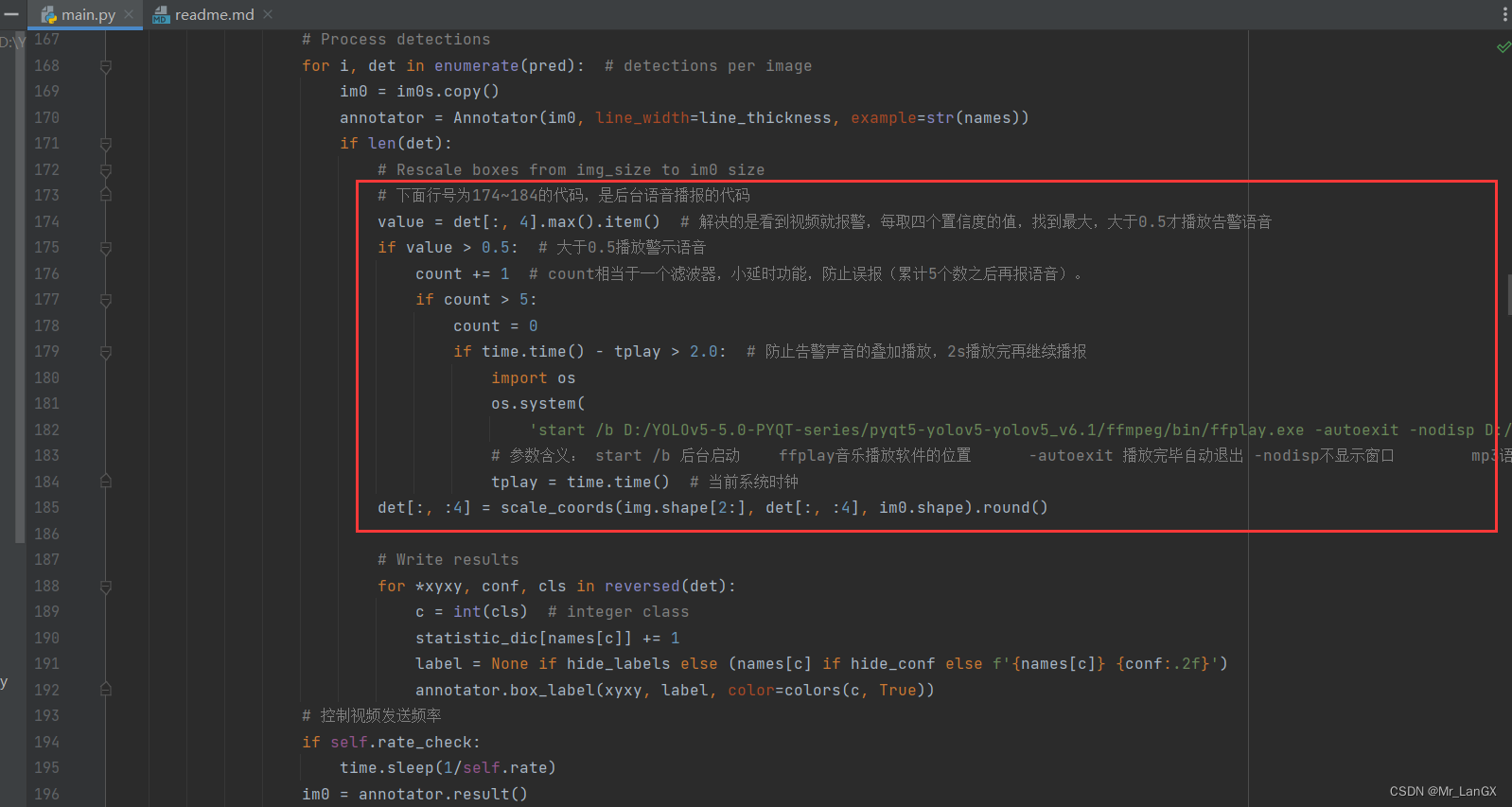
代码如下:
value = det[:, 4].max().item() # 解决的是看到视频就报警,每取四个置信度的值,找到最大,大于0.5才播放告警语音
if value > 0.5: # 大于0.5播放警示语音
count += 1 # count相当于一个滤波器,小延时功能,防止误报(累计5个数之后再报语音)。
if count > 5:
count = 0
if time.time() - tplay > 2.0: # 防止告警声音的叠加播放,2s播放完再继续播报
import os
os.system('start /b D:/YOLOv5-5.0-PYQT-series/pyqt5-yolov5-yolov5_v6.1/ffmpeg/bin/ffplay.exe -autoexit -nodisp D:/YOLOv5-5.0-PYQT-series/pyqt5-yolov5-yolov5_v6.1/Smoking-warning.mp3') # 音乐播放函数
# 参数含义: start /b 后台启动 ffplay音乐播放软件的位置 -autoexit 播放完毕自动退出 -nodisp不显示窗口 mp3语音的位置
tplay = time.time()
③ 一个重要的细节,很多人没注意到
以上两部代码添加完成后,运行main.py程序,出来的界面在切换检测模式时会出现卡顿问题(比如,由检测视频切换成摄像头实时检测,出现报错卡顿问题),报错为:local variable ‘tplay’ referenced before assignment 在函数内部更改全局变量就会出现此错误。
具体解决方法可以私信询问哈!
④ 关于文件名字及路径
不要用中文!不要用中文!不要用中文!
全部改为英文命名你该项目的所有文件夹。
文件路径中出现中文会报错:can‘t open/read file: check file path/integrity
**解决办法:**修改路径名称,中文绝对不出现,有时候英文大写也不可以。
代码改进完成后就可以运行程序啦
三、未来展望
还可以将以上大佬开源的项目以及我对项目的改进打包成一个文件,以.exe可执行程序运行。
这样的好处是 1.项目移植到其他电脑设备上后,不需要再重新配置YOLOv5检测算法所需的支持环境(众所周知支持环境的配置问题就是一道坎),打包exe后,点开文件就能用;2.更便于进行展示,不需要看着一堆代码,在IDE编辑器上点击运行,换句话说打包成.exe文件后,更像一个产品了(给甲方看项目效果的时候,总不能让他们看着一堆代码在运行吧,看起来不正式),而且还有一定的保密效果,其他人看不到你的代码了,无法轻易的复制(当然,逆向破解肯定也能搞出来,没有百分百的保密)。
目前已经实现exe打包,但是文件有点大
整体效果与上述视频里的一模一样。
















 4448
4448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











