







目录
例2 :计算文档里都有哪些单词及这些单词在不同文档中的TF-IDF值
1.贝叶斯定理
(1)概率:事件A发生的可能性被称为A发生的概率,用P(A)来表示;
(2)针对事件A、B同时发生的概率,可以用P(AB)/P(A∩B)来表示:
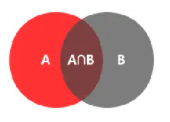
(3)条件概率:
P(A|B):表示事件B发生的前提下,事件A发生的概率,公式如下:
P(B|A):表示事件A发生的前提下,事件B发生的概率,公式如下:
结合上述两个公式,即可得出:
即贝叶斯公式:

2.贝叶斯分类
在分类任务中,我们可以把贝叶斯定理换一个更清楚的形式:
P(类别|特征)=P(特征|类别)*P(类别)/P(特征)
例1:求水果糖来自一号碗的概率
有两个碗,第一个碗中装有30个水果糖和10个巧克力糖,第二个碗中装有 20 个水果糖和 20 个巧克力糖,现在随机选择一个碗,从中取出一颗糖,发现是水果糖。

(1)先验概率:
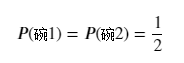
P(水果糖)=(30+20)/(30+10+20+20)=5/8
(2)从碗1拿到水果糖的似然概率:
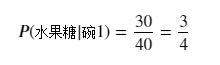
(3)拿到水果糖来自碗1的后验概率是:

例2:广告邮件自动识别
假设采集到了 10000 个邮件样本,其中有 4000 封邮件被认定为广告邮件、6000 封被认定为正常邮件。这 4000 封广告邮件中,出现“红包”关键词的有 1000 封 ,而在 6000 封正常邮件中仅有 6 封包含“红包”这个词。
(1)先验概率:
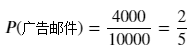
![]()
P("出现红包")=(1000+6)/(4000+6000) =1006/10000
(2)似然概率:
a.广告邮件中出现 “红包” 关键词的似然概率:
![]()
b.正常邮件中出现“红包”关键词的似然概率:
![]()
(3)后验概率:
a.出现“红包”的正常邮件:

b.出现“红包”的广告邮件:

根据计算结果, P(广告邮件|出现“红包”)远远大于P(正常邮件|出现“红包”),故该邮件为广告邮件。
测试代码:
# 广告邮件的数量
ad_number = 4000
# 正常邮件的数量
normal_number = 6000
# 所有广告邮件中,出现 “红包” 关键词的邮件的数量
ad_hongbao_number = 1000
# 所有正常邮件中,出现 “红包” 关键词的邮件的数量
normal_hongbao_number = 6
print('广告邮件的数量:%s,正常邮件的数量:%s'%(ad_number, normal_number))
print('所有广告邮件中出现 “红包” 关键词的邮件的数量:', ad_hongbao_number)
print('所有正常邮件中出现 “红包” 关键词的邮件的数量:', normal_hongbao_number)# 用户收到广告邮件的先验概率为
P_ad = ad_number / (ad_number + normal_number)
print("用户收到广告邮件的先验概率为 P(广告邮件) = " + str(P_ad))
# 用户收到正常邮件的先验概率为
P_normal = normal_number / (ad_number + normal_number)
print("用户收到正常邮件的先验概率为 P(正常邮件) = " + str(P_normal)) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









