







 超级会员免费看
超级会员免费看
今天给大家介绍一下,有需要的伙伴可以自己再深入的学习一下。
"jiebaR"最早是Python中处理分词的组件,目前已有大神将该包分布到了R语言中。“jiebaR"包是R语言中处理中文分词的包,它:1.同时支持简体、繁体中文;2.支持自定义词库,设置词频、词性;3.速度快,比其他分词包提速几倍以上;4.安装简单,不像其他包还需要搭载环境。简单介绍完了,大家一起来看看用法。
一、使用[]号分词
在[]中直接输入要分词的对象即可,不过在jiebaR中,所有的对象均需要使用worker函数初始化一下,这步的作用是建立分词引擎。
library(jiebaR)R=worker()R1<-R["R语言与医学生致力于R语言代码知识的分享!"]R1
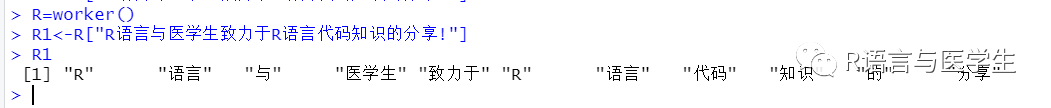
二、使用<=号进行分词
R=worker()R<="R语言与医学生致力于R语言代码知识的分享!"

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 4033
4033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











