







Faster RCNN系列回顾
1、RCNN
步骤:
- 一张图像使用(Selective Search方法)生成1~2K个候选区域
- 对于每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
非极大值抑制剔除重叠建议框:
- 计算proposal和GT的IOU,寻找得分最高的proposal
- 计算其他proposal和该proposal的iou值
- 删除所有iou值大于给定阈值proposal
经过NMS之后,对于剩余的proposal再使用回归器精细修正候选框位置

存在的问题:
- 测试速度慢
- 训练速度慢
- 训练所需空间大
2、Fast R-CNN
步骤:
-
一张图像使用(Selective Search方法)生成1~2K个候选区域
-
将图像(整个图像)输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵(这是将第一阶段生成的候选框映射到特征图上)
-
将每个特征矩阵通过ROI pooling层缩放到7X7大小的特征图,然后将特征图展平通过一系列全连接层获得预测结果
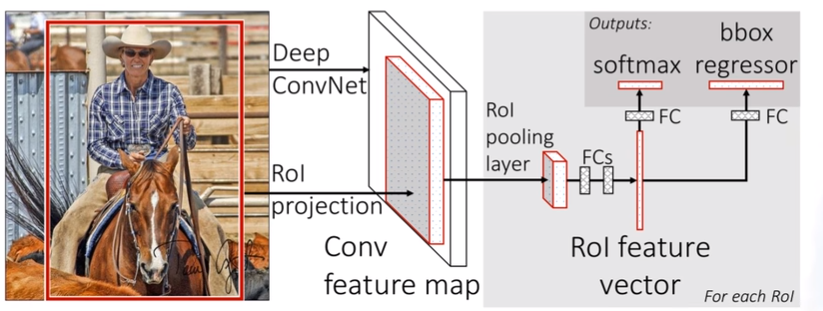
有一个优点就是在候选框生成之后,RCNN需要将每个候选框都输入卷积神经网络提取一遍特征,而Faste RCNN只需要将候选框投影到最开始由整幅图像生成的特征图上面。
就是将任意大小的特征图化成7X7份,对于每一块都采样最大下采样池化层,这样最终不管特征图多大,最终都会得到7X7大小的特征图。
3.Faster RCNN
步骤:
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵(这里生成的候选框,它是在feature map的基础上生成的)
- 将每个特征矩阵通过ROI pooling层缩放到7X7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
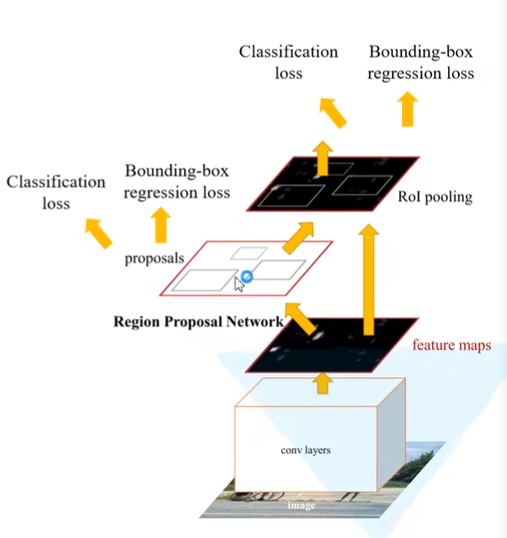
RPN
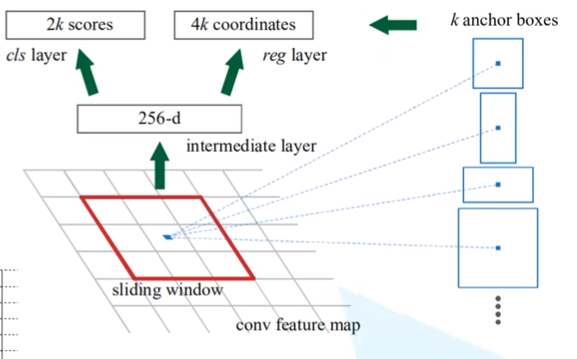
- 在特征图上,使用滑动窗口进行滑动,每到一个位置生成一个256-d(其中256是特征图的channel)的一维向量。然后再通过俩个全连接成生成2k scores,和4k coordinates(对于每个anchor box生成2个scores,4个coordinates)
其中2个score,一个是前景概率,一个是背景概率,只做一个二分类,并不去计算各个类别的概率。
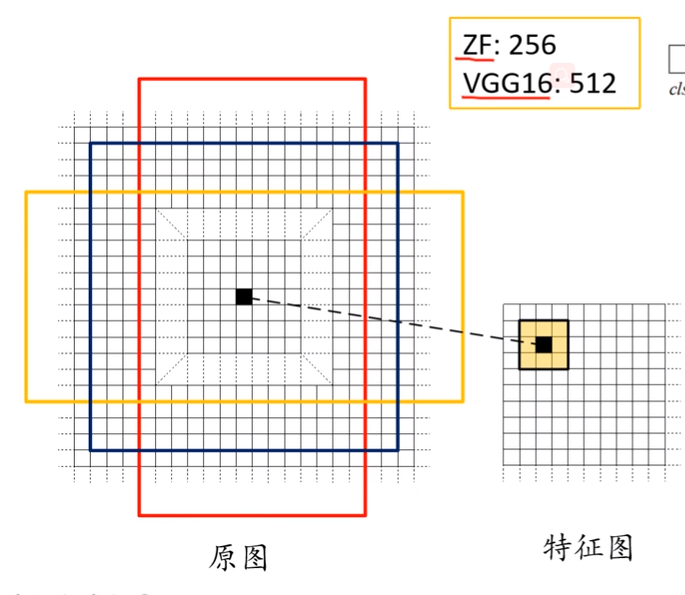
对于特侦图上的每个3X3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点位置,然后以原图对应的中心点为中心,在原图上计算出K个anchor box。其中anchor box是提前设置好的大小和长宽比例。
anchor尺度和比例:
三种尺度(面积) { 12 8 2 128_{2} 1282, 25 6 2 256_{2} 2562, 51 2 2 512_{2} 5122,}
三种比例{1:1, 1:2, 2:1}
anchor和proposal区别就是,生成的anchor经过筛选之后就可以变为proposal
正负样本生成:
每张图只从上万个anchor中采取256个anchor。其中,包括了正样本和负样本。其比例最好是1:1,如果正样本的数量不足128时,我们使用负样本来进行填充,反正总数是要有256个。
- 如何是正样本:
- 某个anchor/anchors和一个GT有着最大的IOU,那么它也是正样本
- anchor和任意一个GT的IOU>0.7就是正样本
- 负样本:
- 与所有的GT的IOU<0.3就是负样本。
RPN Muilti-task loss
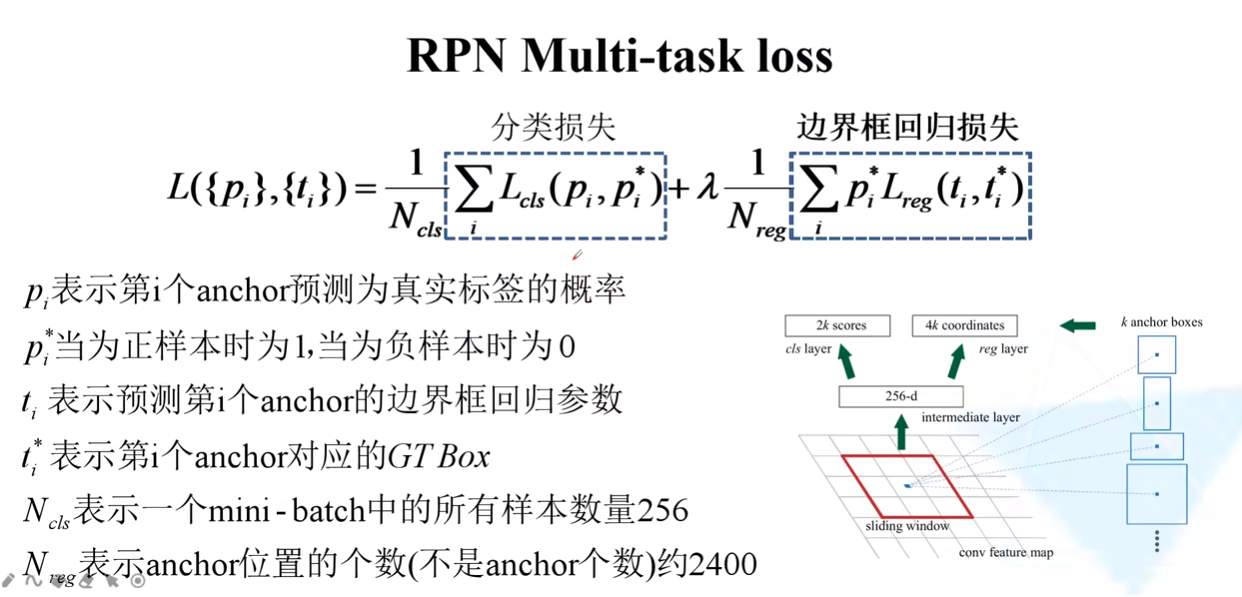
anchor的个数等于anchor位置个数 X k的。约2400是因为特征图大小为(60x40)
Faster RCNN训练
后来的Faster-RCNN训练是采用RPN Loss和Fast R-CNN Loss联合训练方式
原论文中采样分别训练RPN以及Fast R-CNN的方法:
- 利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数
- 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet与寻来你分类模型初始前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数
- 固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
- 同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数,最后RPN网络和Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
参考
https://www.bilibili.com/video/BV1af4y1m7iL?p=3&spm_id_from=pageDriver&vd_source=9d14e5d446c7c743208869eced3fcf60














 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









