






Abstract
困难:
1.在nlp和cv中,一个大模型通常可以处理多个任务;而在时间序列中,预测模型通常是专门的
2.pre-trained LLM在nlp和cv中得到了很好的使用,但在时间序列预测中,受限于数据的稀缺,发展受限
➡️
该如何对齐时间序列数据和自然语言的模态,从而来利用大模型的推理和识别能力?
(1)LLM在离散令牌上操作,而时间序列数据本质上是连续的
(2)解释时间序列模式的知识和推理能力并不自然存在于LLM的预训练中
主要提出:
TIME-LLM,一个重新编程框架,用于将LLM重新用于一般时间序列预测,骨干语言模型保持不变。
TIME-LLM通过将时间序列数据重新编程为LLM更自然的文本原型,并通过Prompt as Prefix提供自然语言指导来增强推理,从而有望将冻结的大型语言模型用于时间序列预测
(1)我们首先用文本原型重新编程输入时间序列,然后将其输入到冻结的LLM中,以对齐两种模式。In doing so, we show that forecasting can be cast as yet another “language” task that can be effectively tackled by an off-the-shelf LLM.
(2)为了增强LLM处理时间序列数据的能力,我们提出了Prompt-as-Prefix(PaP),a novel idea in enriching the input time series with additional context and providing task instructions in the modality of natural language
优点:
1.TIME-LLM是一个强大的时间序列学习器,优于最先进的专门预测模型
2.在少样本和零样本中表现优秀
3.more general, data efficient, easy optimization, synergistic, and accessible compared to current specialized modeling paradigms
Model
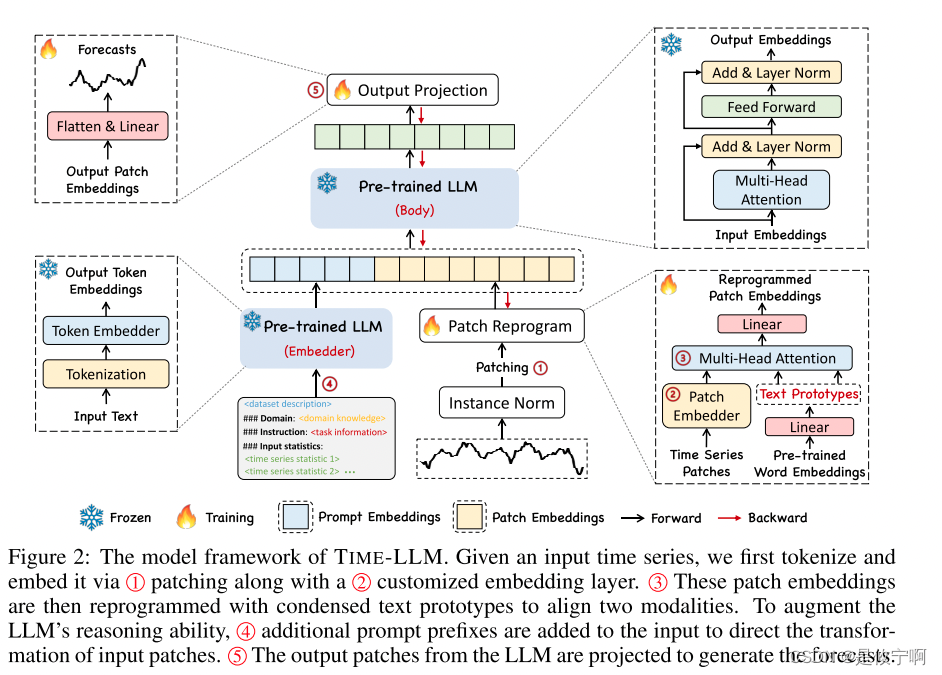
Input Embedding:
(1)Each input channel X(i) is first individually normalized to have zero mean and unit standard deviation via reversible instance normalization (RevIN) in mitigating the time series distribution shift
(2)

Patching Reprogramming
Here we reprogram patch embeddings into the source data representation space to align the modalities of time series and natural language to activate the backbone’s time series understanding and reasoning capabilities
当涉及时间序列数据时,我们可以使用 "patch" 和 "batch" 的概念来说明不同的情况。
Patch(补丁):对于时间序列数据,"patch" 可能指的是数据序列中的局部区域,例如一小段连续的时间窗口或者一组连续的时间点。在时间序列分析中,我们可能对整个时间序列进行划分,然后分别对每个小区域进行分析和建模,这些小区域就可以看作是补丁。
Batch(批量):在训练时间序列模型时,"batch" 意味着同时处理的一组时间序列样本。例如,在循环神经网络(RNN)的训练过程中,我们通常会将多个时间序列样本组合成一个批量,然后一起输入到模型中进行训练,以提高训练效率。
因此,以时间序列为主题,"patch" 可能表示时间序列中的局部区域或子序列,而 "batch" 则表示在训练模型时同时处理的一组时间序列样本。
the source data representation space:
源数据表示空间是指原始数据在某个特定任务中所采用的表示方式,通常是指输入数据在模型训练或推理过程中所使用的表征形式。例如,在图像分类任务中,源数据表示空间可以是像素值或者经过预处理后的图像特征向量;在自然语言处理任务中,源数据表示空间可以是词向量或者句子向量等。
源数据表示空间的选择对于模型的性能和效率具有重要影响,因为不同的表示方式可能会捕捉到不同的数据特征和模式。因此,在训练模型之前,需要仔细考虑如何对原始数据进行预处理和转换,以便更好地适应模型的需求,并提高模型性能。
对齐不同模态的一个常见方法就是cross-attention,只需要把所有词的embedding(在这里是通过线性探测词嵌入矩阵 E 来维护一个小型的文本原型集合,表示为 E′ ∈ RV′×D,其中 V′ ≪ V)和时序输入特征做一个cross-attention(其中时序输入特征为Query,所有词的embedding为Key和Value)。但是,词汇表很大,肯定无法直接将时序特征对齐到所有词上,而且也并不是所有词都和时间序列有对齐的语义关系
补:cross-attention和self-attention
Cross Attention和Self-Attention都是深度学习中常用的注意力机制,用于处理序列数据,其中Self-Attention用于计算输入序列中每个元素之间的关系,Cross Attention则是计算两个不同序列中的元素之间的关系。它们的主要区别在于计算注意力分数时所用的查询、键和值的来源不同。
在Self-Attention中,输入序列被分成三个向量(即查询向量,键向量和值向量),这三个向量均是来自于同一组输入序列,用于计算每个输入元素之间的注意力分数。因此,Self-Attention可以用于在单个序列中学习元素之间的依赖关系,例如用于语言建模中的上下文理解。
在Cross Attention中,有两个不同的输入序列,其中一个序列被用作查询向量,另一个序列被用作键和值向量。Cross Attention计算的是第一个序列中每个元素与第二个序列中所有元素之间的注意力分数,通过这种方式来学习两个序列之间的关系。例如,在图像字幕生成任务中,注意力机制可以用来将图像的特征与自然语言描述的句子相关联。
下面是一个简单的例子,演示Self-Attention和Cross Attention的区别。假设有两个序列A和B,它们分别表示句子和单词:
A = ["The", "cat", "sat", "on", "the", "mat"]
B = ["mat", "cat", "dog", "on"]
在Self-Attention中,我们会用A本身的向量来计算注意力分数,查询向量、键向量和值向量都是从A中提取的。例如,我们可以通过将A传递给一个Self-Attention层来计算每个单词之间的注意力分数。
在Cross Attention中,我们将B的向量用作键和值向量,而A的向量用作查询向量。这允许我们计算句子中每个单词与单词序列B中的所有单词之间的注意力分数。例如,我们可以通过将A和B传递给一个Cross Attention层来计算单词和单词序列B之间的注意力分数。
总之,Self-Attention和Cross Attention都是非常有用的注意力机制,它们分别用于处理序列内部和跨序列的关系

补:text prototypes.
词汇表E➡️E'


代码:
import torch
import torch.nn as nn
from math import sqrt
self.vocab_size = self.word_embeddings.shape[0]
self.num_tokens = 1000
self.mapping_layer = nn.Linear(self.vocab_size, self.num_tokens)
self.reprogramming_layer = ReprogrammingLayer(configs.d_model, configs.n_heads, self.d_ff, self.d_llm)
#source_embedding是词库,enc_out是cross-attention后的输出,用文本来表示时序序列
source_embeddings = self.mapping_layer(self.word_embeddings.permute(1, 0)).permute(1,
x_enc = x_enc.permute(0, 2, 1).contiguous()
enc_out, n_vars = self.patch_embedding(x_enc.to(torch.bfloat16))
enc_out = self.reprogramming_layer(enc_out, source_embeddings, source_embeddings)
class ReprogrammingLayer(nn.Module):
def __init__(self, d_model, n_heads, d_keys=None, d_llm=None, attention_dropout=0.1):
super(ReprogrammingLayer, self).__init__()
# Initialize key dimension if not provided
d_keys = d_keys or (d_model // n_heads)
# Linear projections for query, key, value and output
self.query_projection = nn.Linear(d_model, d_keys * n_heads)
self.key_projection = nn.Linear(d_llm, d_keys * n_heads)
self.value_projection = nn.Linear(d_llm, d_keys * n_heads)
self.out_projection = nn.Linear(d_keys * n_heads, d_llm)
self.n_heads = n_heads
self.dropout = nn.Dropout(attention_dropout)
def forward(self, target_embedding, source_embedding, value_embedding):
#batch_size, Target sequence length, source sequence length
B, L, _ = target_embedding.shape
S, _ = source_embedding.shape
H = self.n_heads
# Project target, source and value embeddings
target_embedding = self.query_projection(target_embedding).view(B, L, H, -1)
source_embedding = self.key_projection(source_embedding).view(S, H, -1)
value_embedding = self.value_projection(value_embedding).view(S, H, -1)
# Reprogramming operation
out = self.reprogramming(target_embedding, source_embedding, value_embedding)
out = out.reshape(B, L, -1)
return self.out_projection(out)
def reprogramming(self, target_embedding, source_embedding, value_embedding):
B, L, H, E = target_embedding.shape
scale = 1. / sqrt(E)
# Compute attention scores and apply softmax
#"blhe" 表示第一个张量 target_embedding 的维度对应关系,具体为 (Batch size,Target sequence length, Number of attention heads, E);
#"she" 表示第二个张量 source_embedding 的维度对应关系,具体为 (Source sequence length, H, E);
#"->bhls" 表示输出张量的维度顺序,具体为 (Batch size, Number of attention heads, L, S)
scores = torch.einsum("blhe,she->bhls", target_embedding, source_embedding)
A = self.dropout(torch.softmax(scale * scores, dim=-1))
# Reprogramming based on attention weights
reprogramming_embedding = torch.einsum("bhls,she->blhe", A, value_embedding)
return reprogramming_embedding
Prompt-as-Prefix(提示做为前缀)
提示是否可以作为前缀来丰富输入上下文并指导编程时间序列补丁的转换?Yes
一个提示示例如图4所示。数据集上下文为LLM提供了有关输入时间序列的基本背景信息,这些信息通常在各个领域表现出不同的特征。在特定任务的补丁嵌入转换中,任务指令是LLM的重要指南。我们还用额外的关键统计数据(如趋势和滞后)丰富输入时间序列,以促进模式识别和推理

代码:
prompt_ = (
f"<|start_prompt|>Dataset description: The Electricity Transformer Temperature (ETT) is a crucial indicator in the electric power long-term deployment."
f"Task description: forecast the next {str(self.pred_len)} steps given the previous {str(self.seq_len)} steps information; "
"Input statistics: "
f"min value {min_values_str}, "
f"max value {max_values_str}, "
f"median value {median_values_str}, "
f"the trend of input is {'upward' if trends[b] > 0 else 'downward'}, "
f"top 5 lags are : {lags_values_str}<|<end_prompt>|>"
)
prompt.append(prompt_)
#将cross-atteion后的结果和前缀结合起来
llama_enc_out = torch.cat([prompt_embeddings, enc_out], dim=1)
#进入llama大模型,得到输出
dec_out = self.llama(inputs_embeds=llama_enc_out).last_hidden_state
dec_out = dec_out[:, :, :self.d_ff]
Expriments(真的有那么好的性能吗,很存疑)
四个实验:
LONG-TERM FORECASTING
SHORT-TERM FORECASTING
由表中可以看出训练50epoches后的TimeLLM效果很好,一个epoch也有不错的性能

FEW-SHOT FORECASTING
ZERO-SHOT FORECASTING
补充链接:














 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









