







RoboBrain 论文
将任务规划、Affordance 感知(人手与物体接触的区域)、轨迹预测整合进 MLLM,实现指令->具体动作的端到端能力,结合 RoboOS 实现多机器人任务分配。
ShareRobot
- 细粒度:与 Open X-Embodiment 不同,ShareRobot 为每个数据点都包含于各个帧相关联的详细低级规划指令;
- 多维度:对任务规划、物体可操作性(affordances)以及末端执行器轨迹进行了标注;
- 采用 QA 问答形式标注。(个人理解:QA 标注相比于直接低级规划指令标注让模型更关注任务到动作的映射)
- 末端执行器
- 丰富多样性:ShareRobot 具有 102 个场景,涵盖 12 个实施例和 107 种原子任务。这种多样性使 MLLM 能够从不同的现实世界环境中学习,从而增强复杂、多步骤规划的稳健性。

RoboBrain
 采用 SigLIP 作为视觉编码器,然后通过两层 MLP 将其投影到语义空间,采用 Qwen2.5-7B-Instruct 作为 LLM。
采用 SigLIP 作为视觉编码器,然后通过两层 MLP 将其投影到语义空间,采用 Qwen2.5-7B-Instruct 作为 LLM。
采用 bounding box 来表示 affordance region:
O
i
=
{
A
i
0
,
A
i
1
,
…
…
,
A
i
N
}
O_i=\{A_i^0,A_i^1,……,A_i^N\}
Oi={Ai0,Ai1,……,AiN} N 为 affordance region 的数量,边界框采用矩形四角标注。轨迹则是一系列 2D 坐标
{
x
,
y
}
\{x,y\}
{x,y}。
目标是使多模态大语言模型 (MLLM) 能够理解抽象指令并明确输出目标affordance区域和潜操作轨迹,从而促进从抽象到具体的过渡。采用多阶段训练策略:第一阶段专注于通用 OneVision (OV) 训练,以开发具有强大理解和指令遵循能力的基础 MLLM。第二阶段,即机器人训练阶段,旨在增强 RoboBrain 的核心能力,使其从抽象到具体。
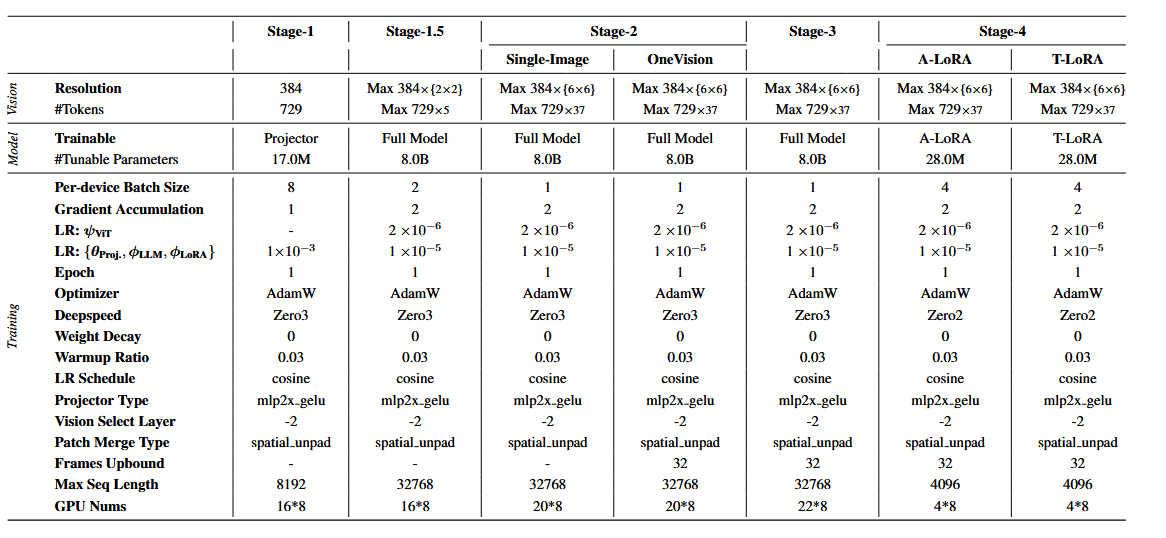
训练流程:
- 阶段 1:利用 LCS558K dataset 训练 Projector,对齐视觉-语义特征;
- 阶段 1.5:采用 4M 高质量图像-文本数据,训练整个模型,提高通用理解;
- 阶段 2:利用 LLaVAOneVision-Data 中的 3.2M 图像数据和 1.2M 图像视频数据,提高高分辨率图像理解;
- 阶段 3:RoboVQA800K, ScanView-318K(MMScan-224K, 3RScan-43K, ScanQA-25K, SQA3d26K 和 ShareRobot-200K 一个子集)以及阶段 1 中 1.7M 图像-文本对来缓解灾难性遗忘。
- 阶段 4:LoRA 微调。
跨本体机器人协作能力:云端的 RoboBrain 将任务规划分解,发给各个机器人,机器人执行过程中通过 RoboOS 实时反馈。
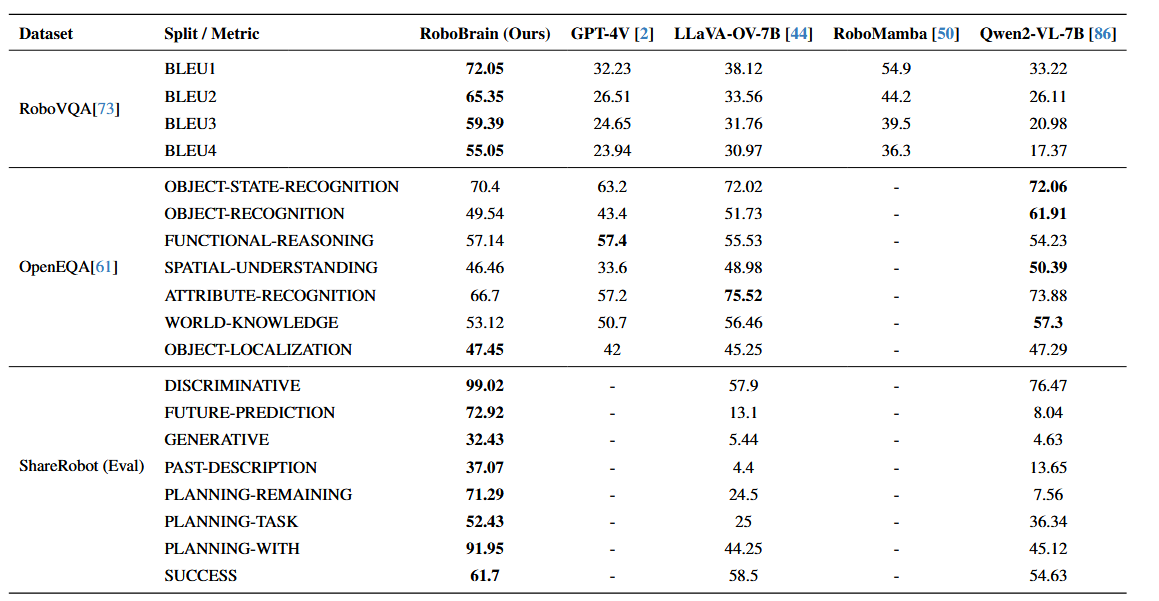
实验结果
在整个训练阶段,采用 Zero3 分布式训练策略,所有实验都在一个服务器集群上进行,每个服务器配备 8×A800 GPU。
config 配置


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









