







Phoenix 论文
传统方法仅通过高层语义调整,但底层仍依赖预训练的子动作;而强化学习在复杂机器人环境中学习效率低,末端执行器位姿调整仅适用于简单规划任务;Phoenix 将多模态大语言模型的语义反思转化为细粒度机器人动作校正,提高泛化能力。

LLaVA-v1.5 + DP
Dual-process Motion Adjustment Mechanism
- Motion Prediction Module(MPM):利用专家示范数据 D e D_e De,和给定观测 O 和任务描述 T,生成初始运动指令 m i m_i mi,此时 m i m_i mi 仅使用于理想工况;
- Motion Correction Module(MCM):利用故障修正数据
D
c
D_c
Dc,通过思维链的方式调整
m
d
m_d
md。(延迟很高 avg ≥ 200ms)。
以 5Hz 的频率提供运动指令。

MPM 通过设定阈值对机器人动作进行筛选,提取主导运动特征,生成包含机械臂方向控制与夹爪控制的运动指令集。实验发现,若将机械臂方向指令与夹爪控制指令分离处理,会导致文本运动指令与细粒度机器人动作之间的不匹配——将方向运动与夹爪控制相结合,形成统一的指令格式,例如"机械臂右移同时保持夹爪闭合"。此外,我们还添加了"微调夹爪位置"等指令,以建模低于阈值的细微机器人动作,最终建立了包含37类运动指令的指导集。
MCM 构建了校正数据集,包含三种反馈:1)humanin-the-loop:当智能体遭遇故障时,人工介入修正运动指令;2)Offline Human Annotation:用运动预测模型收集轨迹数据并采样,标注语义反思和运动校正信息;3)Expert Demonstration:对成功示范轨迹进行自动化标注。

- 由于预训练语言模型难以捕捉不同运动指令的判别性特征,故构建可训练的运动码本(motion codebook),对每个决策指令 m d m_d md 检索对应的运动特征向量。
- 由于直接拼接视觉观测与运动特征会导致策略过度依赖视觉信息,故在扩散过程的前向过程注入 O;逆向过程注入运动特征 M;
L = M S E ( E k , π ( O , M , A 0 + E k , k ) ) \mathcal{L}=\mathrm{MSE}(\mathcal{E}^k,\pi(\mathcal{O},\mathcal{M},\mathcal{A}^0+\mathcal{E}^k,k)) L=MSE(Ek,π(O,M,A0+Ek,k))
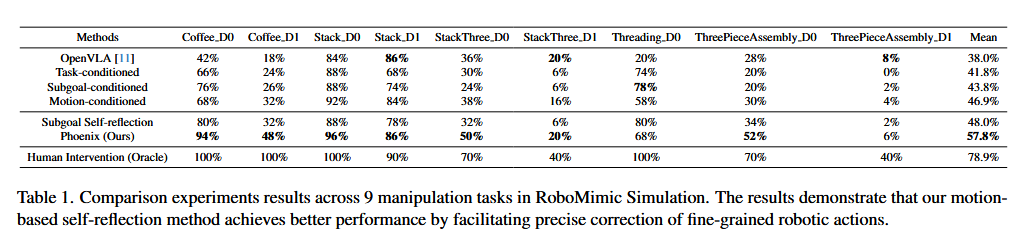
实验结果
决策模型使用 LLaVA-v1.5,底层策略采用扩散策略。
- OpenVLA:对 OpenVLA 模型微调,为多任务实验提供基线性能。
- 任务条件策略:将任务描述作为扩散策略的条件,不使用反思框架,是 RT-1 和 Octo 的变体。
- 子目标条件策略:对 LLaVA-v1.5 微调,以 5Hz 频率预测子目标并作为扩散策略条件,不使用反思框架,借助多模态大语言模型语义理解能力,是 PaLM-E 的变体,采用单独扩散策略。
- 运动条件策略:对 LLaVA-v1.5 微调作为运动预测模型,以 5Hz 频率提供运动指令并作为扩散策略条件,不使用反思框架,利用多模态大语言模型感知和推理能力,是 RT-H 的变体,采用单独扩散策略。
- 人工干预:手动校正运动条件策略中错误的运动指令,为自反思方法性能提供上限,结果以 10 次试验平均成功率呈现。
子目标自反思:对 LLaVA-v1.5 微调作为子目标自反思模型并应用于子目标条件策略,验证语义自反思模型的有效性。
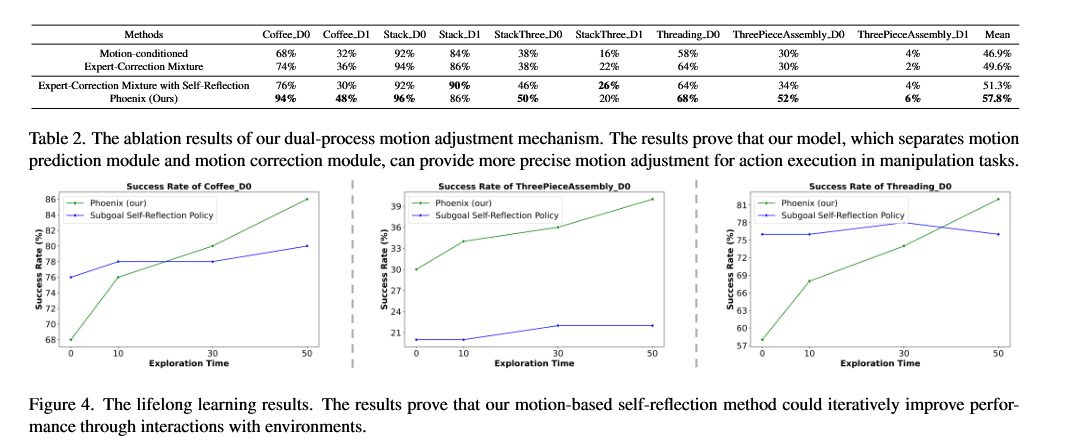
采用以下消融实验方法:
- 专家 - 校正混合:我们将专家演示和校正数据混合,共同训练运动预测模型。
- 带自反思的专家 - 校正混合:我们将专家演示和校正数据混合,共同训练一个统一的模型,以提供初始运动指令并调整指令。

















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









