







 该博客介绍了使用PyTorch进行情感分类的全过程,包括数据集预览、数据加载与探索、模型构建、模型训练及Text数据增强方法,特别是详细讨论了Back Translation在数据增强中的应用和优势。
该博客介绍了使用PyTorch进行情感分类的全过程,包括数据集预览、数据加载与探索、模型构建、模型训练及Text数据增强方法,特别是详细讨论了Back Translation在数据增强中的应用和优势。
1. 背景说明
本实验使用Twitter上发布的数据集Sentiment140,包含160W条记录,三个分类,其中{0: 负面;2: 中性;4: 正面},但真实数据集中并未发现“中性”数据,即正负样本各80W。
1.1 数据集预览
1. 数据信息预览
print(dataset.info())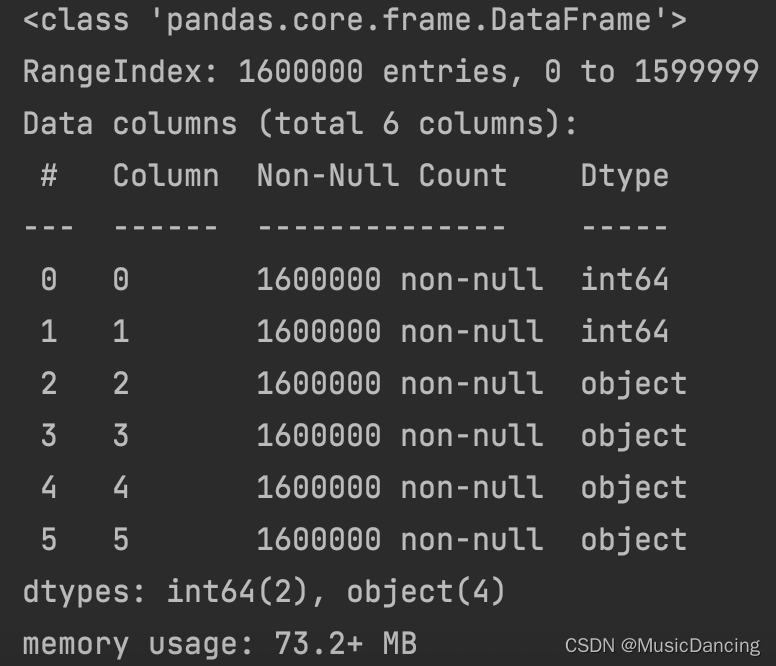
2. 显示前5条数据:
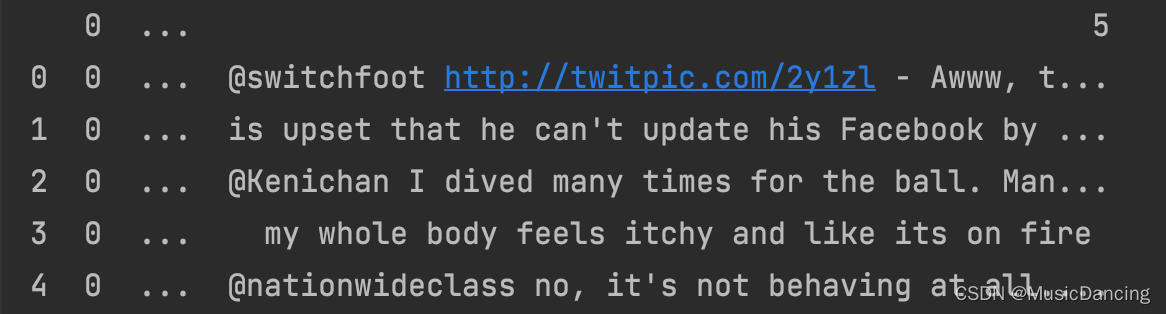
3. 数据分布(各个类别占比)
print(dataset[0].value_counts())![]()
2. 数据加载与探索
2.1 类别标签转换
将label标签转换为0、1两个类别
def transform_lable_to_01(input_path, output_path, sample_path):
dataset = pd.read_csv(input_path, engine='python', header=None, encoding='utf-8')
# 类型转换 --> 分类变量
dataset['sentiment_category'] = dataset[0].astype('category')
# 将类别变量转换为0和1两个类别
dataset['sentiment'] = dataset['sentiment_category'].cat.codes
# 查看分布
# print(dataset['sentiment'].value_counts())
dataset.to_csv(output_path, header=None, index=None)
# 随机选择1K个样本当作测试集
dataset.sample(10000).to_csv(sample_path, header=None, index=None)
if __name__ == '__main__':
data_path = '../data/training.1600000.processed.noemoticon.csv'
data_processed_path = '../data/training_processed.csv'
data_sample_path = '../data/test_sample.csv'
transform_lable_to_01(data_path, data_processed_path, data_sample_path)2.2 分隔训练集、测试集、验证集
from torchtext.legacy import data
def get_train_test_val_data_set(data_path):
LABEL = data.LabelField() # 标签
TWEET = data.Field(lower=True) # 内 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8962
8962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









