







- 这节理论部分传送门:NLP学习—10.循环神经网络RNN及其变体LSTM、GRU、双向LSTM
- 数据集代码链接
一、文本情感分析简介
利用算法来分析提取文本中表达的情感。 分析一个句子表达的好、中、坏等判断,高兴、悲伤、愤怒等情绪。如果能将这种文字转为情感的操作让计算机自动完成,就节省了大量的时间。对于目前的海量文本数据来说,这是很有必要 的。我们可以通过情感分析,在电商领域挖掘出口碑好的商品,订餐订住宿领域挖掘优质场所等。
文本情感分析主要有三大任务 即文本情感特征提取,文本情感特征分类,文本情感特征检索与归纳。
二、文本情感分类任务
1.基于情感词典的方法
第一种方法:基于情感词典的方法

举个例子:这个/电影/不是/太好看,一共分为四个词,这个,电 影,不是,太好看。 “太好看”在情感词典中的pos词典中出现,所以pos_score得分为1,然后往前遍历是否出现程度词,无程度词,再搜索否定词,出现了“不是”为-1,相乘最终得分为-1。
词典的构建有如下方法:
- 人工构建情感字典(人工总结标注)
- 自动构建情感词典(基于知识库)
基于关键词(高兴、悲伤、愤怒等)挖掘出包含同样情感的词
- 利用gensim找出最相近的词向量
- 利用爬虫或者查词典的方式做同义词的替换
2.基于机器学习的方法
一般流程如下:

- 朴素贝叶斯
- SVM分类器
- 集成学习
- 深度学习方法
这里介绍LSTM与LSTM+Attention,起到融合信息的作用。
诸如在词性标注下游任务中,我们不仅考虑上文信息,而且还要考虑下文信息,此时,就需要双向LSTM。双向LSTM可以理解为同时训练两个LSTM,两个LSTM的方向、参数都不同。当前时刻的 h t h_t ht就是将两个方向不同的LSTM得到的两个 h t h_t ht向量拼接到一起。我们使用双向LSTM捕捉到当前时刻 t t t的过去和未来的特征。通过反向传播来训练双向LSTM网络。
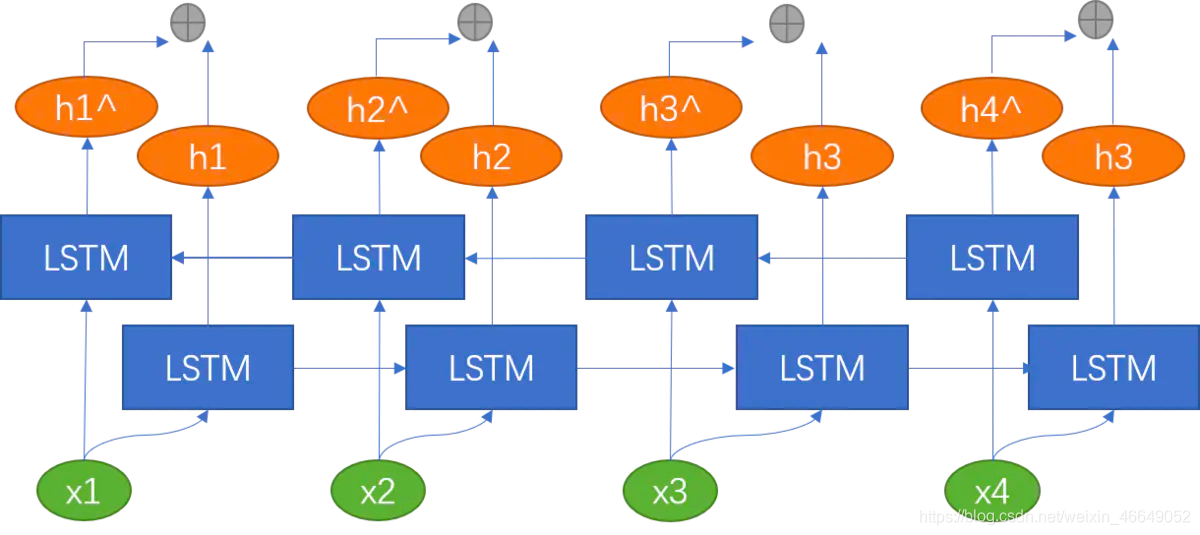
如果是双向LSTM+Attention,这里是静态的Attention,则网络结构如下:
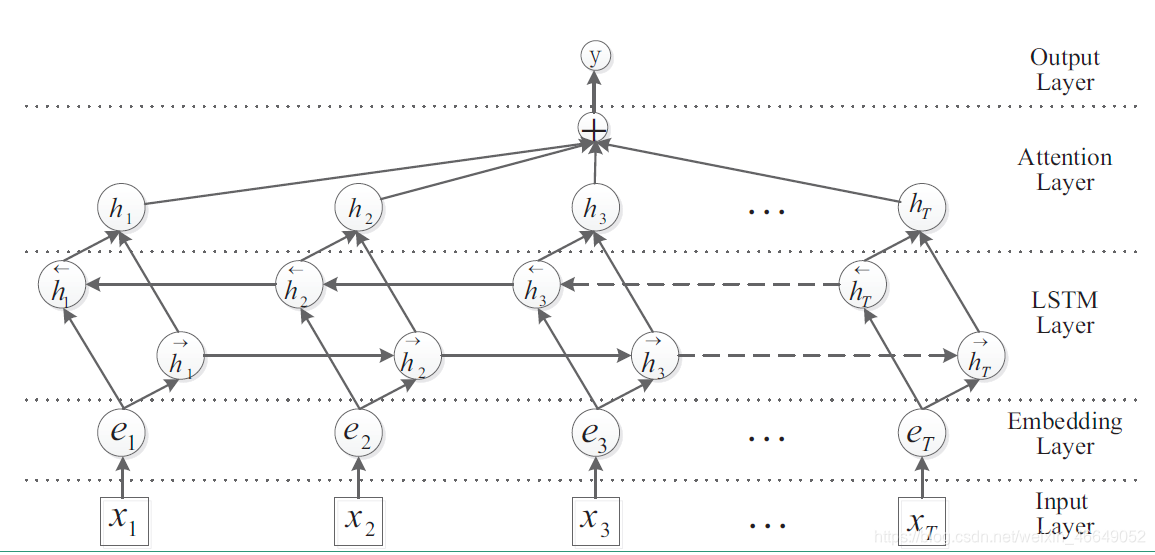 h t h_t ht是每一个词的hidden state,而 h s ‾ \overline{h_s} hs是向量,开始是随机生成的,后面经过反向传播可以得到 ∂ L o s s ∂ h s ‾ \frac{\partial{Loss}}{\partial{\overline{h_s}}} ∂hs∂Loss,通过梯度不断迭代更新,得到标准。
h t h_t ht是每一个词的hidden state,而 h s ‾ \overline{h_s} hs是向量,开始是随机生成的,后面经过反向传播可以得到 ∂ L o s s ∂ h s ‾ \frac{\partial{Loss}}{\partial{\overline{h_s}}} ∂hs∂Loss,通过梯度不断迭代更新,得到标准。
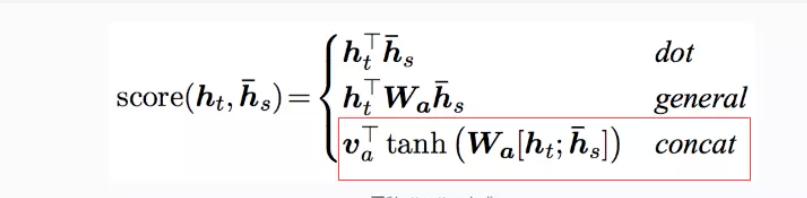
score是标量。每句话进行拼接,然后做softmax得到概率,然后对hidden state进行加权平均,得到总向量,然后经过一个分类层,经softmax得到每一个类别的得分。
三、PyTorch中LSTM介绍
torch.nn.LSTM(*args, **kwargs)
参数:
- input_size –输入特征数
- hidden_size – 隐藏层的大小
- num_layers – LSTM的层数,例如,设置num_layers=2意味着将两个LSTM堆叠在一起,形成一个堆叠的LSTM,第二个LSTM接收第一个LSTM的输出并计算最终的结果。默认值:1
- bias – 如果为False,则该层不适用偏置权重。Default: True
- batch_first – 如果为True,则输入和输出张量被提供为(batch, seq, feature)而不是(seq, batch, feature)。注意,这并不适用于隐藏或单元格状态。 Default: False
- dropout – 如果非0,则在除最后一层外的每个LSTM层的输出上引入Dropout层,Dropout概率等于Dropout。默认值:0。 Default: 0
- bidirectional – 如果为True,则为双向LSTM。 Default: False
- proj_size – if> 0,则使用LSTM,并进行相应大小的投影。 Default: 0
输入:Inputs: input, (h_0, c_0)

输出:Outputs: output, (h_n, c_n)


四、基于PyTorch与LSTM的情感分类流程
- 拿到文本,分词,清洗数据(去掉停用词)
- 建立word2index index2word 表
- 准备好预训练好的 word embedding ( or start from one hot)
- 做好 Dataset / Dataloader
- 建立模型(soft attention/ hard attention/ self-attention/ scaled dot /product self attention)
- 配置好参数
- 开始训练
- 测评
- 保存模型
数据预处理部分代码:Sentiment_Analysis_DataProcess.py
from __future__ import unicode_literals, print_function, division
from io import open
import torch
import re
import numpy as np
import gensim
from torch.utils.data import Dataset
from Sentiment_Analysis_Config import Config
class Data_set(Dataset):
"""
自定义数据类,只需要定义__len__和__getitem__这两个方法就可以。
我们可以通过迭代的方式来取得每一个数据,但是这样很难实现取batch,shuffle或者多线程读取数据,此时,需要torch.utils.data.DataLoader来进行加载
"""
def __init__(self, Data, Label):
self.Data = Data
# 考虑对测试集的使用
if Label is not None:
self.Label = Label
def __len__(self):
# 返回长度
return len(self.Data)
def __getitem__(self, index):
# 如果是训练集
if self.Label is not None:
data = torch.from_numpy(self.Data[index])
label = torch.from_numpy(self.Label[index])
return data, label
# 如果是测试集
else:
data = torch.from_numpy(self.Data[index])
return data
def stopwordslist():
"""
创建停用词表
:return:
"""
stopwords = [line.strip() for line in open('word2vec_data/stopword.txt', encoding='UTF-8').readlines()]
return stopwords
def build_word2id(file):
"""
将word2id词典写入文件中,key为word,value为索引
:param file: word2id保存地址
:return: None
"""
# 加载停用词表
stopwords = stopwordslist()
word2id = {
'_PAD_': 0}
# 文件路径
path = [Config.train_path, Config.val_path]
# print(path)
# 遍历训练集与验证集
for _path in path:
# 打开文件
with open(_path, encoding='utf-8') as f:
# 遍历文件每一行
for line in f.readlines():
out_list = []
# 去掉首尾空格并按照空格分割
sp = line.strip().split()
# 遍历文本部分每一个词
f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5507
5507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









