







1. 背景
在图卷积神经网络GCN之前,采取CNN提取图片特征,其核心在于卷积核(卷积核相当于一个小的窗口,在图片上平移,通过卷积来提取特征)。这一过程的关键点就是图片在其域中的平移不变性:
在欧几里得几何中,平移是一种几何变换,表示把一幅图像或一个空间中的每一个点在相同方向移动相同距离。比如对图像分类任务来说,图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的,这就是卷积NN中的平移不变性。
CNN中的卷积是一种离散卷积(本质是一种加权求和),利用一个共享参数的过滤器kernel,通过计算中心像素点以及相邻像素点的加权和来构成feature map 实现空间特征的提取,加权系数就是卷积核的权重系数W。卷积核的系数如何确定的呢?
随机化初值,然后根据误差函数通过BP梯度下降进行迭代优化。这是一个关键点,卷积核的参数通过优化求出才能实现特征提取的作用,而GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。
1.1 为什么是GCN?
CNN 之所以可以应用到图像而无法应用到图网络中主要是因为图像具有平移不变性,而图网络不具备这一属性(图非欧氏空间)。由于图网络是不规整的关系型数据(如邻居节点数量的不确定和节点顺序的不确定),不存在平移不变性,难以选取固定的卷积核来适应整个图的不规则性,因此 CNN 无法直接在图上进行卷积(每一个节点的周围结构可能都是独一无二的)。
CNN 核心在于使用了基于卷积核的卷积操作来提取图像的特征(利用卷积核实现参数共享),这里的卷积操作类似于对「计算区域内的中心节点和相邻节点进行加权求和」。利用这种平移不变性来对扫描的区域进行卷积操作,从而实现了图像特征的提取。
既然是因为卷积核的原因,可不可以不使用卷积核?
不可以,因为卷积NN的核心:
1. 利用卷积核实现参数共享(参数大小只与卷积核大小有关);
2. 局部连接性:卷积计算每次只在与卷积核大小对应的区域进行,也就是说输入和输出是局部连接的。如果不进行局部连接的话,相当于将图片的矩阵展开成向量进行输入,类似于全连接NN,此时的参数量会变得非常巨大。
3. 层次化表达(是特点,非核心):可以通过卷积层叠加得到,每一个卷积层都是在前一层的基础上进行的,意义在于,网络越往后,其提取到的特征越高级。比如说:第一层可能是一些线条,第二层可能会是一些纹理,第三层可能是一些抽象图案。
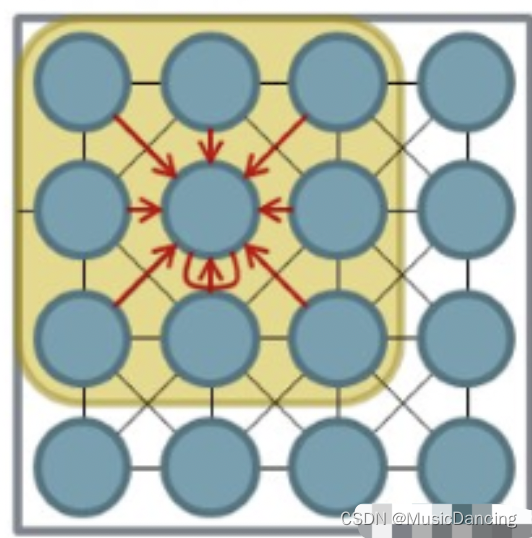
GCN是一个针对图数据的特征提取器(与CNN的作用一样),借助谱图理论来实现在拓扑图上的卷积操作,可以使用这些特征去对图数据进行节点分类、图分类、边预测,还可以顺便得到图的嵌入表示(graph embedding),用途广泛。
大致步骤为将空域中的拓扑图结构通过傅立叶变换映射到频域中并进行卷积,然后利用逆变换返回空域,从而完成了图卷积操作。
1.2 GCN的公式
一批N个节点的图数据,每个节点都有自己的特征,组成一个N×D维的矩阵X,另外各个节点间的关系也会形成一个N×N 维的矩阵A,即邻接矩阵,X和A便是模型的输入。GCN 的第l层表示:
![]()
多层GCN 可以通过重复应用这个公式来构建,其中:
H(l)是第l层的节点表示矩阵,每一行对应一个节点的表示;
是图的邻接矩阵A加上自环(self-loop)的结果;
是
的对角线度矩阵,其中
;
激活函数一般选择ReLU等,引入非线形;增强模型的表达能力;
是为了归一化邻接矩阵,使得每个节点的表示能够考虑到其邻居节点的信息。
1.3 度矩阵 Degree
是一个对角阵,对角上的元素为各个顶点的度(与该顶点相关联的边的数量)。注意:有向图中包括出度和入度。
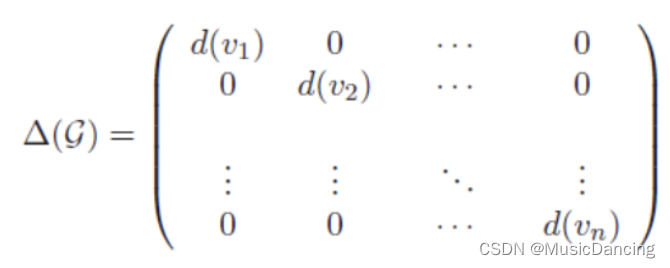
其中 是可以事先算好的,因为
由A计算而来,而A是输入之一。
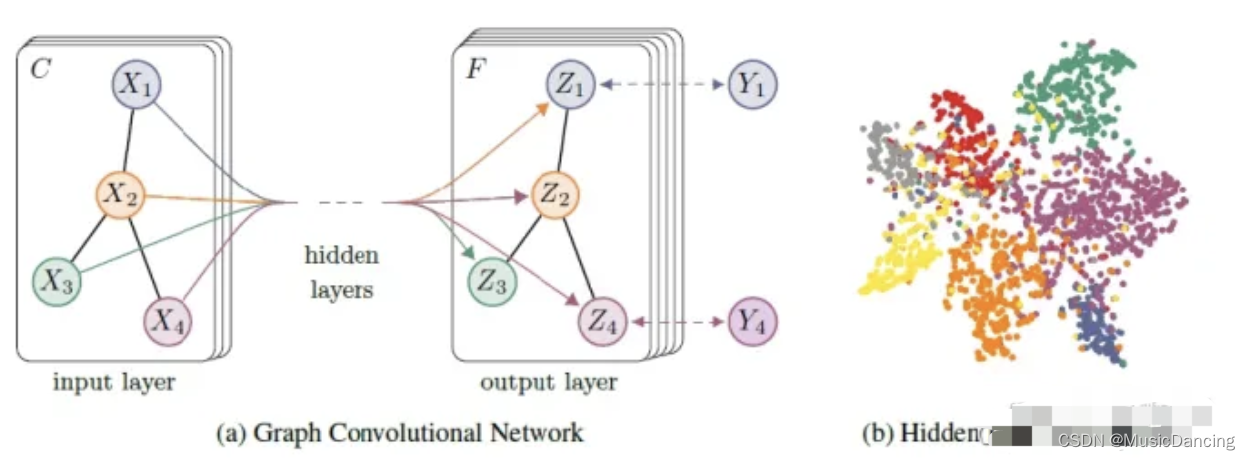
2. GCN 原理
GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但无论中间有多少层,node之间的连接关系A,都是共享的。假设构造一个两层的GCN,激活函数分别采用ReLU和Softmax,则整体的正向传播的公式为:
![]()
最后针对所有带标签的节点计算cross entropy 损失函数,就可以训练一个node classification的模型了。由于即使只有很少的node有标签也能训练,所以也称该方法为半监督分类。每一层GCN的输入都是邻接矩阵A和node的特征H,那么直接做一个内积,再乘一个参数矩阵W,然后激活一下,就相当于一个简单的NN层。
![]()
实验证明,即使这么简单的NN层,就已经很强大了。但这个简单模型有几个局限性:
1. 若只使用A,由于对角线上都是0,在和特征矩阵H 相乘时,只会计算一个node 的所有邻居特征的加权和,该node 自己的特征却被忽略了。因此给A 加上一个单位矩阵I,这样就让对角线元素变成1了。
2. A是没有经过归一化的矩阵,这样与特征矩阵H 相乘会改变特征原本的分布,产生一些不可预测的问题。需要对A做一个标准化处理:让A的每一行加起来为1,即乘上度矩阵。
改进后最终的层特征传播公式如下:
![]()
公式中的 与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。
3.应用&数据
图NN最难的一步,就是把数据处理成算法能够使用的标准格式,这比其训练更难一些。设计一个小型的数据集,做一个GCN的demo。
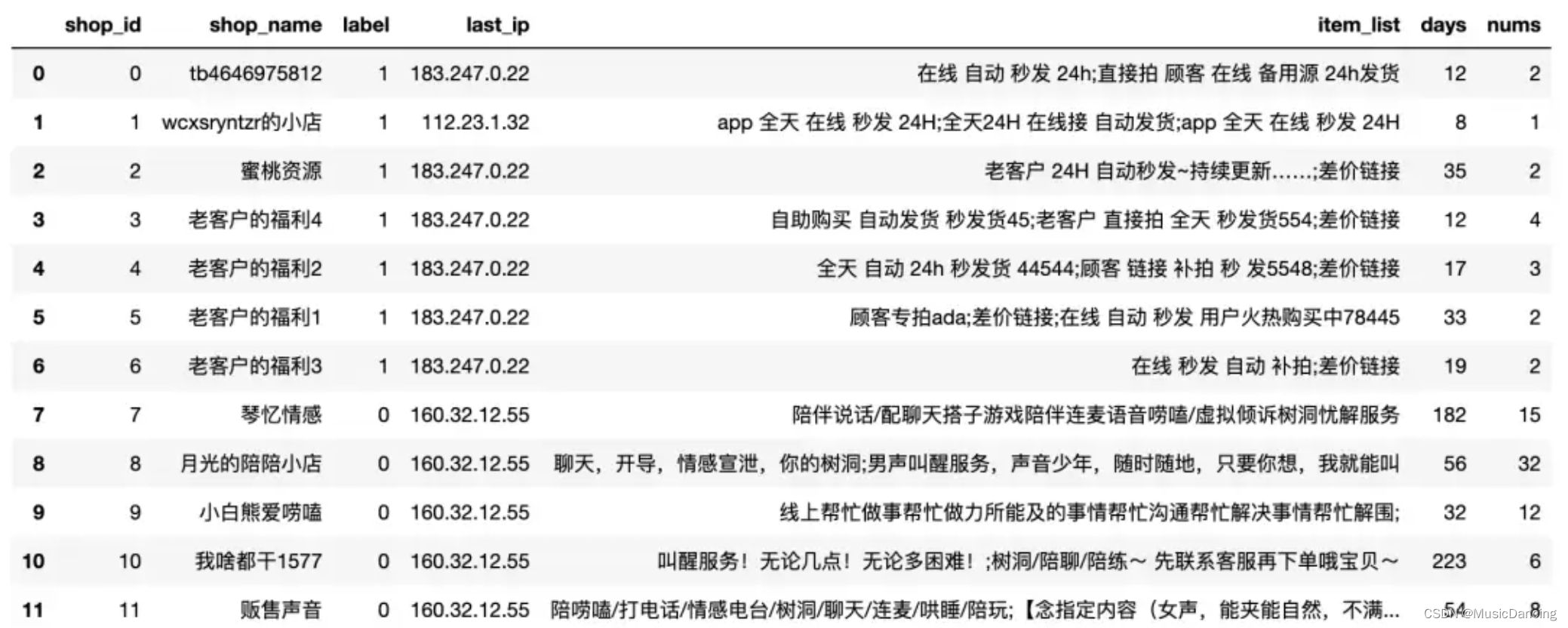
3.1 数据探索
12个商家的样本,11为黑样本(卖片的),0为白样本。
 3.2 图数据构建
3.2 图数据构建
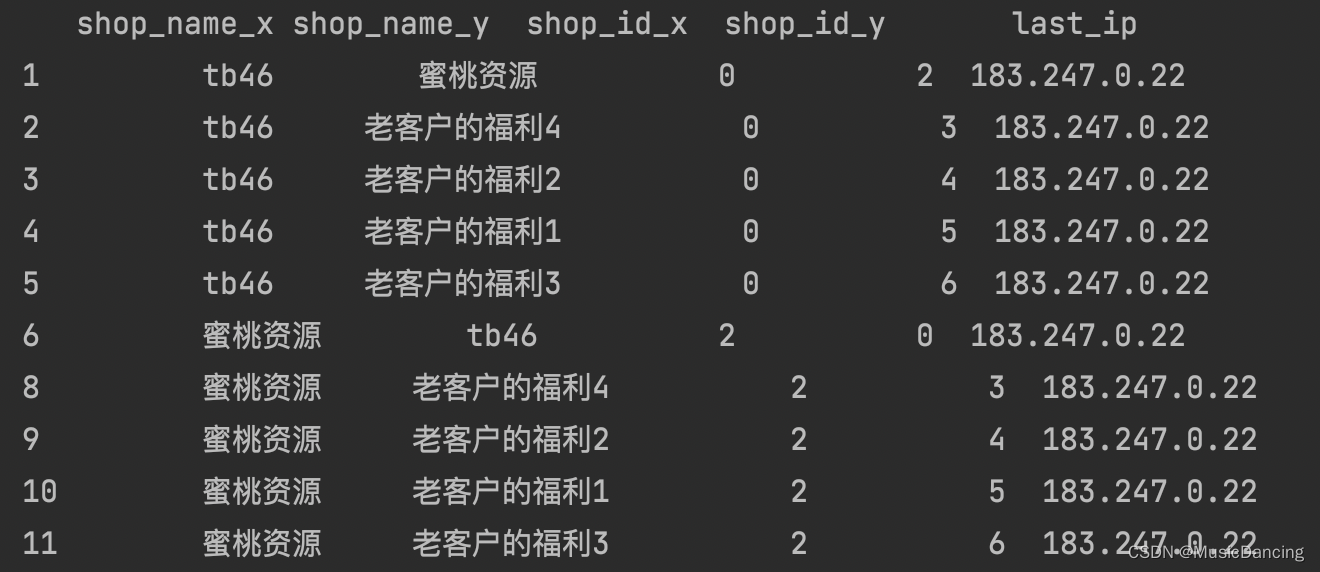
IP是这里的介质,用其来构建一个同构图,然后利用商品标题litem_list、注册时长days、商品数目nums来作为特征,进行训练、验证、预测。
df = pd.read_csv('data.csv')
df_new = df.merge(df, on='last_ip')
# df_new = df_new[df_new['shop_id_x'] != df_new['shop_id_y']] # 去除自身关联
df_new = df_new[['shop_id_x', 'shop_id_y', 'shop_name_x', 'shop_name_y', 'last_ip']]
print(df_new.head(20))
scr = df_new['shop_id_x'].to_numpy()
dst = df_new['shop_id_y'].to_numpy()关联结果:
可视化后,大概分为两个群体,以及一个孤立点。图NN通过添加自环的形式,对孤立节点,也能很好的进行预测。
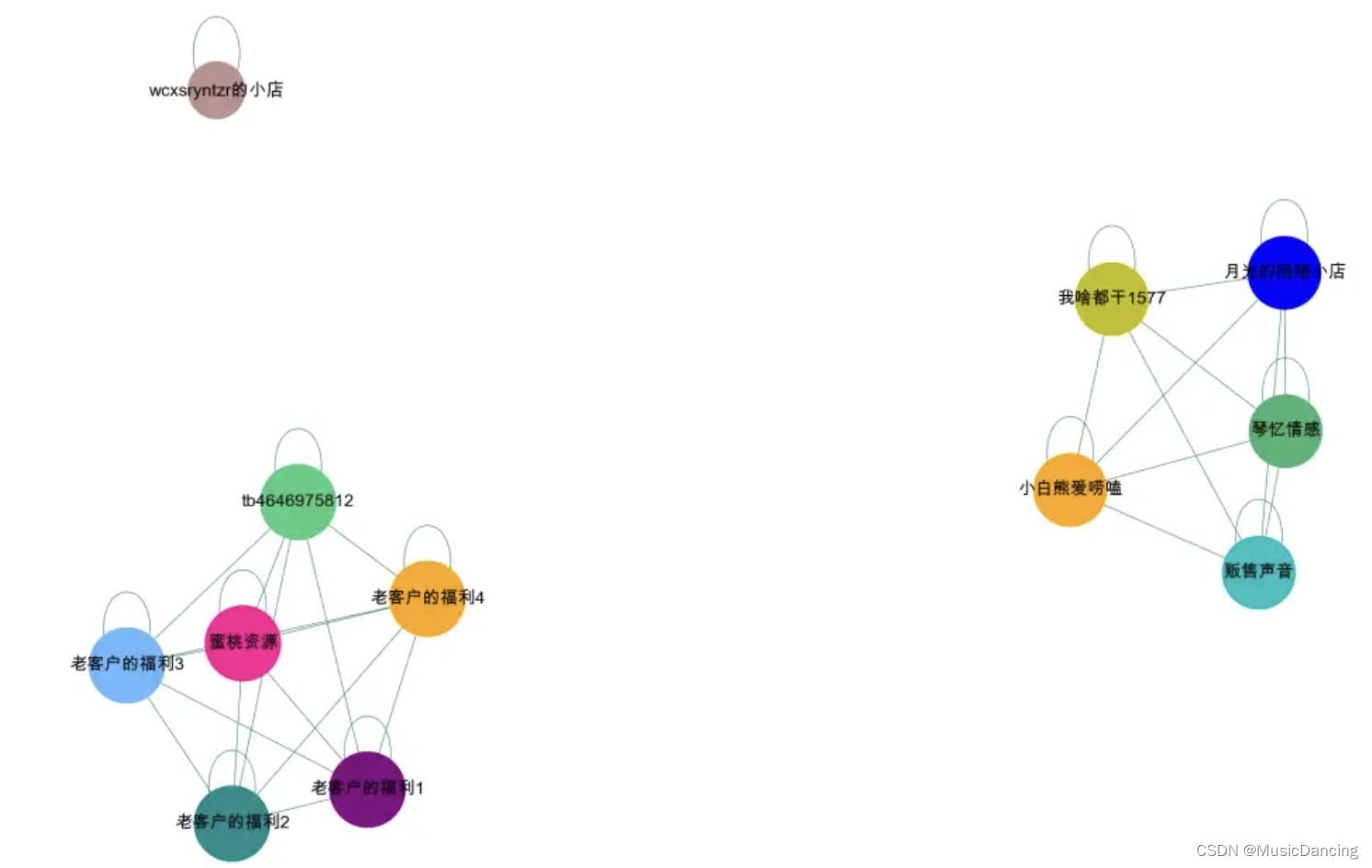
4. 图NN构建
4.1 节点编码
注意使用DGL框架,输入的节点必须是数字类型的,所以要对节点进行数字编码。这里直接使用shop_id。
4.1 构建dgl图
根据编码后的节点,构建dgl的图。pip install dgl
import dgl
g = dgl.graph((scr, dst)) # dgl图构建
g = dgl.add_self_loop(g) # 添加自环,否则部分节点无法预测
g = dgl.to_bidirected(g) # 去重 还可以通过nx去重
print(g)4.3 特征工程
1. 处理文本特征
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
df['text'] = df['item_list'].apply(lambda x: ' '.join(jieba.cut(x))) # 进行分词处理
# 初始化
vectorizer = CountVectorizer(max_features=25, token_pattern=r"(?u)\b\w+\b", min_df=1, analyzer='word')
vectorizer.fit(df['text'])
# 词转换成CountVectorizer向量
feat_item = vectorizer.transform(df['text'])
feat_item = pd.DataFrame(feat_item.toarray())把单词还原
# 对字典进行反转
onehotdic = {}
for k, v in vectorizer_word.vocabulary_.items():
onehotdic[v] = k
feat_item.columns = [onehotdic[i] for i in list(feat_item.columns)]
feats = pd.concat([feat_item, df[['days', 'nums']]], axis=1)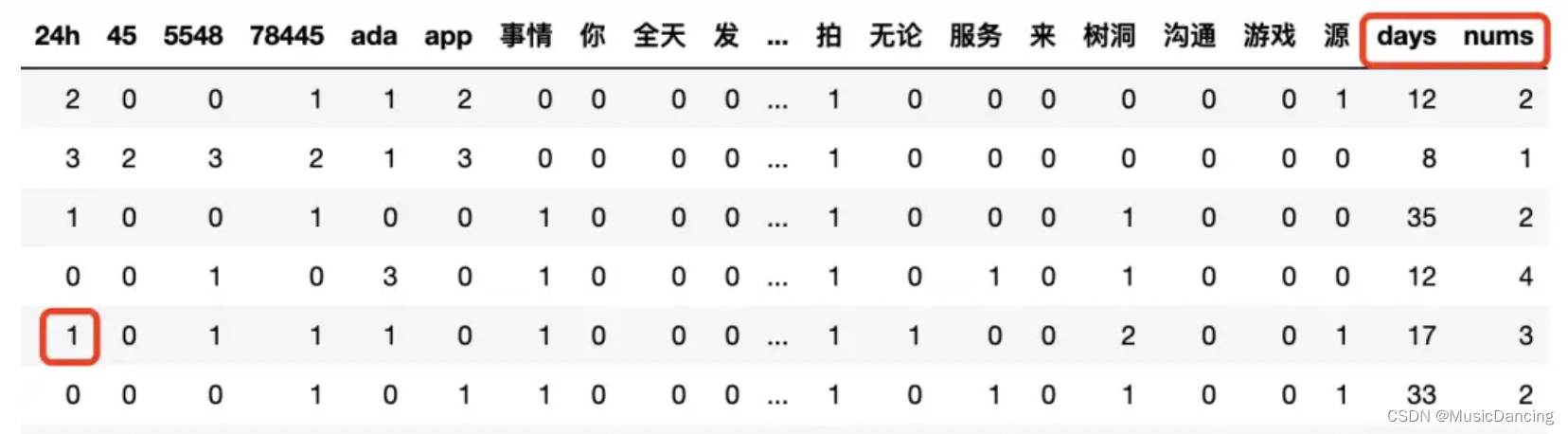
2. 处理数字特征
每个词表示每个样本包含某个词的个数(限制了top25个),和数字特征拼接起来,共27个维度。图NN的特征,需要进行归一化,然后再转换成tensor格式。
from sklearn.preprocessing import MinMaxScaler
import torch
transfer = MinMaxScaler(feature_range=(0, 1)) # 实例化一个转换器类
features = transfer.fit_transform(feats) # 调用fit_tra
features = torch.tensor(np.array(features))4.4 数据集划分
mask操作,相当于常规ML的训练集、验证集、测试集划分。
def sample_mask(idx, n):
mask = np.zeros(n)
mask[idx] = 1
return np.array(mask, dtype=np.bool_)
# 0-6是黑样本,7-11是白样本,1 这个样本是独立的
idx_train = [0, 2, 3, 4, 7, 8, 9]
idx_val = [5, 6, 10]
idx_test = [1, 11]
train_mask = sample_mask(idx_train, 12)
val_mask = sample_mask(idx_val, 12)
test_mask = sample_mask(idx_test, 12)
masks = train_mask, val_mask, test_mask5. 模型构建
1. 模型定义
import torch
import torch.nn as nn
import torch.nn.functional as F
import dgl.nn as dglnn
torch.set_default_tensor_type(torch.DoubleTensor)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
in_size = features.shape[1]
out_size = 2
class GCN(nn.Module):
def __init__(self, in_size, hid_size, out_size):
super().__init__()
self.layers = nn.ModuleList()
# two-layer GCN
self.layers.append(dglnn.GraphConv(in_size, hid_size, activation=F.relu))
self.layers.append(dglnn.GraphConv(hid_size, out_size))
self.dropout = nn.Dropout(0.3)
def forward(self, g, features):
h = features
for i, layer in enumerate(self.layers):
if i != 0:
h = self.dropout(h)
h = layer(g, h)
# h = F.softmax(h,dim=1)
return h2. 模型训练
# 输入依次为图、结点特征、标签、训练、验证、测试的masks、模型、epoches
# 图和结点特征和标签应该输入所有结点的数据,而不能只输入验证集的数据
def train(g, features, labels, masks, model, epoches):
train_mask = masks[0]
val_mask = masks[1]
loss_fcn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, weight_decay=5e-4)
for epoch in range(epoches):
model.train()
logits = model(g, features)
loss = loss_fcn(logits[train_mask], labels[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = evaluate(g, features, labels, val_mask, model)
print("Epoch {:05d} | Loss {:.4f} | Accuracy {:.4f} ".format(epoch, loss.item(), acc))3. 模型验证
# 输入依次为图、结点特征、标签、验证集或测试集的mask、模型
def evaluate(g, features, labels, mask, model):
model.eval()
with torch.no_grad():
logits = model(g, features)
logits = logits[mask]
labels = labels[mask]
# probabilities = F.softmax(logits, dim=1)
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)4. 开始训练
样本很少,第二轮就100%的准确了,验证集和测试数据都是100%。
model = GCN(in_size, 16, out_size).to(device)
epoches = 5
train(g, features, labels, masks, model, epoches)
acc = evaluate(g, features, labels, masks[2], model)
print("Test accuracy {:.4f}".format(acc))调整下函数,让测试集直接输出概率
def predict(g, features, labels, mask, model):
model.eval()
with torch.no_grad():
logits = model(g, features)
logits = logits[mask]
labels = labels[mask]
probabilities = F.softmax(logits, dim=1)
return probabilities
predict(g, features, labels, masks[2], model)测试集是0和11两个样本,0号样本是黑样本的概率为0.8335,11号样本为白样本的概率为0.6135。其中“wc的小店”作为孤立节点,特征和黑样本相似,也是预测概率蛮高的,所以图NN,对于孤立节点也是有很好的学习能力,不一定是一定都要构成图。
















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









