







1. 基本概念
1.0 学习型算法
有很多问题无法编程直接解决,需要机器自己学习。
1.1 机器学习(Machine Learning)
简言之:就是把无序的数据转换成有用的信息。
Machine Learning: A computer program is said to learn from experience E with respect to task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. (对于一个计算机程序来说,给它一个任务T和一个性能测量方法P,如果在经验E的影响下,P对T的测量结果得到了改进,那么就说此程序从E中学习)
1.2 监督学习(Supervised Learning)
基本思想为:训练数据集中的每个样本都有相应的“标准答案”,再根据这些样本做出预测。(如房价预测)
1.2.1 分类(Classification)
尝试推测出离散的输出值
1.2.2 回归(Regression)
尝试推测出连续的输出值
1.3 无监督学习(Unsupervised Learning)
基本思想为:训练数据集中的每个样本没有相应的“标准答案”,则不需要预测目标变量的值,而是把这些数据分为离散的组。给你一组数据,然而不告诉你关于数据的任何正确答案,给你数据之后就问你“你能在这组数据中寻找一些有趣的结构吗?”
1.3.1 聚类(Cluster)
只是把数据分为离散的组。
1.3.2 密度估计算法
不仅把数据分为离散的组,而且需要估计数据与每个分组的相似程度。
1.4 Learning Theory
为什么学习型算法是有效的?需要多少学习样本?
1.5 强化学习(Reinforcement Learning)
它可以被用在你不需要进行一次决策的情形中,可以在一段时间内做一系列决策。
2. 机器学习程序开发步骤
1)收集数据
2)准备输入数据
3)分析输入数据(人工分析,确保数据集中没有垃圾数据)
4)训练算法(抽取知识或信息并进行存储,Unsupervised Learning不需要此步)
5)测试算法
6)使用算法
3. 算法
3.1 单变量线性回归(Linear Regression with One Variable)
- 它只有一个特征变量/输入变量,所以叫做单变量线性回归。
- 模型表示:
以房屋交易为例,其Training Set如下:


要解决此问题,需要将训练集喂给Learning Algorithm,从而学习得到一个假设h;然后再将需要预测的房屋尺寸作为输入变量输入给h,h再预测出此房屋的交易价格作为输出变量。一种可能的表达方式如下(因为只有一个特征变量):

- 代价函数
如何确定上面回归函数中的常量,以使此回归函数最大程度地符合训练实例,从而使预测更加准确。

我们选择的参数θ0和θ1决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距,就是建模误差(modeling error)。我们的目标是选择出使得建模误差的平方和最小的模型参数,即使如下代价函数的值最小。
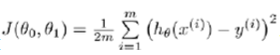
- 梯度下降(Gradient Descent)
Gradient Descent是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数J(θ0,θ1)的最小值。
梯度下降的基本思想:开始时,随机选择一个参数组合(θ0,θ1,...,θn),计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合。继续这样做直到到一个局部最小值(local minimum),因为没有尝试所有的参数组合,所以不能确定我们得到的局部最小值是否是全局最小值(global minimum),选择不同的初始组合,可能会找到不同的局部最小值。
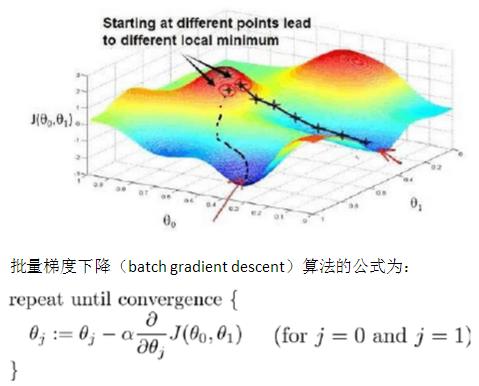
其中α是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习率乘以代价函数的导数。
- 梯度下降的线性回归
梯度下降算法和线性回归算法比较如图:

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









