






单应矩阵+相机标定+ICP 算法讲解和实现
前言
在相机标定、点云、三维等计算机视觉领域中经常会用到数学方法对问题进行求解,搞清楚这些数学方法可以让我们对模型的求解有更深入的理解。本帖是针对工作中遇到过的单应矩阵求解、相机标定、ICP等问题在数学上的理解。笔者最近在工作中有所感悟:调参仅需5秒,但是想要知道咋调,需要把算法原理一层一层剥开来看。
关键词:DLT、单应矩阵、相机标定、ICP、正定方程、超定方程

附赠自动驾驶学习资料和量产经验:链接
1. DLT直接线性变换问题与单应矩阵求解
关键字:DLT、正定方程、超定方程、单应矩阵
1.1 DLT是个什么东西
以前在学习这部分内容的时候发现很多资料上介绍DLT的时候都是直接推导公式,所以让我误以为DLT是某种“方法”,而且推导的方式又有很多种,所以我一直很困惑DLT到底是个什么,如果它是某种数学方法,为啥大家推导的过程各不相同。
Direct Linear Transform直接线性变换,它不是某种特定的方法,它描述的是两组坐标点之间的线性映射关系。而解这种问题的方法有若干种:svd、求导、求逆等。例如单应矩阵的求解。
1.2 DLT在单应矩阵中的应用
单应矩阵描述的是平面上的点在两个相机的图像平面上像素坐标之间的映射关系,它也是一种DLT问题,即两组坐标点之间的线性映射关系。其公式如下:

(1)
展开:

(2)

1.3 正定方程与超定方程
- 正定方程:约束方程数量 = 参数量 (一种求解问题)
如图所示,二维空间中直线AB的方程y=ax+b求解问题中:理想情况下,如果已知两个点的坐标A,B,可以通过解方程计算出a和b两个参数,这是一个正定方程的求解问题。

正定方程求解问题
但是很遗憾在实际问题中由于噪声的原因,我们实际拿到的用于求解a,b的可能是在A,B附近的A’,B’,即输入本身就存在误差,我们用含有误差的A’,B’求出的直线方程必然与AB直线方程存在误差,这是不可避免的。但是如果我们引入了更多的约束来拟合这个方程呢?
- 超定方程:约束方程数量 > 参数量 (一种拟合问题)


超定方程拟合问题
显然通过A’,B’,C’三个点拟合的直线方程要比通过A’,B’直接计算出来的直线方程更加准确。
总结一波:
a. 正定方程是一个求解问题,能根据输入求出一个满足输入条件的精确解,这个“精确”只是针对于输入而言,不是真正的精确,由于输入本身有误差,导致计算结果与理想模型有误差。
b. 超定方程是一个拟合问题,是根据更多输入数据提供的约束关系,拟合出一个最佳结果。由于输入数据更多,如果某一个数据存在较大的误差,其他数据提供的约束关系可以帮忙修正,因此容错率高。而且输入数据的分布更多样,因此更稳定,例如上图中A’,B’分布在直线上方,C’在直线下方,C’对直线拟合精度有正收益。
1.4 单应矩阵的求解
回到正题,再来说说单应矩阵如何求解。从(2)式中能够看出一组点可以提供两个约束关系,单应矩阵8个参数量至少需要4组点来求解。
(1)仅提取4组点(正定方程求解问题)

为什么getPerspectiveTransform方法很多时候误差很大呢:我们的输入数据通常是从图像上提取的像素点坐标,或者标定出的世界坐标,它们都是存在误差的,导致我们最终求解的结果完美吻合这种带误差数据提供的约束关系,而不是理想情况下无误差的约束关系,而无误差数据提供的约束关系,才是我们想要的模型。
因此,这种由4组点计算单应矩阵的方法误差较大,容错率低。
(2)提取到很多组点(超定方程拟合问题)

btw:由于大型矩阵解svd比较耗时,因此opencv有一种策略是:每次选取4个点计算H并使用ransac剔除外点,然后再在剩余内点中选取4个点继续计算H,这样一步一步迭代。其实也是引用更多的数据来做拟合。

(3)
求解这个问题有两种方法:
- 方法一:构造最小二乘然后求偏导

- 方法二:奇异值分解





2. 特征分解与奇异值分解的几何意义
本节只讨论特征分解与奇异值分解的几何意义,具体的计算过程忽略掉。
2.1 特征分解
矩阵可以表示一种线性变换,包括拉伸、缩放、旋转、剪切、透视等。以简单的线性变换矩阵为例:

A 矩阵作用于左侧x-y坐标系,分别将x方向的基(1,0)和y方向的基(0,1)变换到(2,1)和(1,2)作为新的u-v坐标系的基。也就是新的坐标系的u,v轴方向分别与原坐标系下的向量(2,1)向量(1,2)方向相同,且同时在这两个方向下存在 5 的拉伸。



2.2 SVD分解
但是很遗憾,并不是所有矩阵所表示的线性变换都存在只有拉伸缩放而没有旋转的特征向量。对于这种情况,只能退而求其次,寻找线性变换前后都正交的一组向量。如图所示:

奇异值分解的结果为:


3. 相机标定
3.1相机模型
下图中展示了相机成像过程中的几个主要的坐标系:


坐标系转换关系
实际上从相机坐标系到图像坐标系之间还有一个成像平面坐标系,它是一个物理平面,即现实中的物体投影到相机的ccd上。成像平面与图像坐标系之间是一个物理单位转换(从真实的物理单位mm、μm等到“像素”的转换)以及平移变换。相机物理模型的意义以及内参公式可见视觉SLAM十四讲第五章。

相机模型
综上,世界中的某一个物体呈现在图像上的过程包含:
-
从世界坐标系转换到相机坐标系(三维到三维的转换)
-
相机坐标系->成像平面坐标系(三维到二维)
-
成像平面坐标系->图像坐标系(二维到二维)


外参
过程2和3表示如下,中间的矩阵为相机的内参,可将相机坐标系下的三维点转换到图像坐标系上。

内参
整个成像过程可简化如下, K 为相机内参矩阵

相机标定模型
上式就是相机标定的数学模型,我们就是要使用世界坐标系下棋盘格角点坐标(先验)+图像坐标系下角点的图像坐标(使用棋盘格角点检测算法提取)对世界坐标系投影到图像坐标系这个物理过程进行量化。
3.2相机标定
张正友的棋盘格标定法需要用相机多角度地拍摄棋盘格,使用足够多组数的世界坐标->图像坐标的角点映射关系,拟合出一组最佳的参数。相机参数的求解过程如下:
- 单应矩阵


即:


- 内参


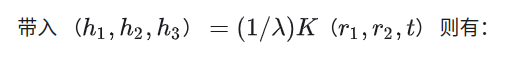

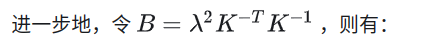



- 非线性优化
上述过程我们只是为非线性优化计算了一个比较优秀的初始值,最终的结果还需要使用非线性优化方法迭代。在这个过程中,我们会把面求得的内参、外参作为初始值,并令相机的畸变参数为0,一步步优化逼近最优解。
综上,相机标定的过程大概分为以下几步:
| 棋盘格标定算法流程 |
|---|
| 1. 通过世界坐标系下的棋盘格角点坐标和图像坐标系下的角点坐标计算单应矩阵H 2. 通过外参中旋转矩阵提供的约束建立约束方程,并使用至少3张图来计算相机的内参K 3. 通过已知的H和K反推出外参R,t 4. 将畸变系数初始化为0,并将1.2.3计算出的内参、外参作为初始值进行非线性优化 |
4. ICP
三维重建中经常要解决3D-3D位姿估计的问题,这个问题可用迭代最近点(Iterative Closest Point, ICP)方法求解。ICP可在三维重建的过程中计算出相邻帧间相机的位姿变换关系。
ICP解决的问题类型通常有两种:
-
匹配好的两组点间的运动估计(通过rgb进行匹配)
-
未匹配的点云之间的运动估计
4.1 匹配点之间的运动估计


最小二乘问题
令两组点的质心为:

进一步地转化为:








def pose_estimation_3d3d(pt1_3d,pt2_3d,R,t):
kp1_3d =pt1_3d
kp2_3d =pt2_3d
p1 = np.zeros([1,3])
p2 = np.zeros([1, 3])
N = np.size(kp1_3d,0)
#center pts
for i in range(N):
p1 = p1 + kp1_3d[i]
p2 = p2 + kp2_3d[i]
p1 = p1 /N
p2 = p2 /N
q1 = np.zeros([N,3])
q2 = np.zeros([N,3])
#reconstruct W
for i in range(N):
q1[i]=kp1_3d[i]-p1
q2[i]=kp2_3d[i]-p2
#W=q1*q2^T
W = np.zeros([3,3])
for i in range(N):
W = W + np.dot(q1.transpose(),q2)
#svd
U, sigma, VT = la.svd(W)
R_ = np.dot(U,VT)
#计算行列式
B = np.linalg.eigvals(R_)
if np.all(B>0):
R =R_
else:
R =-R_
#extrinsic.t
t_ = p1.transpose() - np.dot(R,p2.transpose()) #注意观察p1和p2
return R,t_
4.2 未匹配点云之间的运动估计


未配准的两个点云
如图所示为相机在不同位姿状态下拍摄到的点云,可以看出相机的位姿相差较大。这时候需要给定一个初始的相对位姿关系(称为初始变换,这个初始变换通常由“粗配准”来提供,或者由上一帧计算的与上一帧的上一帧的外参结果提供,我理解是因为相机在相邻帧的运动可能会比较相似,因此在计算当前帧之前,把上一帧计算的结果当作当前帧的初始变换。目的就是给精配准提供一个优秀的初始值),以便后续的非线性优化。这一点类似于相机标定时,相机标定中先通过解DLT和旋转矩阵提供的约束关系计算出一个比较不错的初试内参、外参,然后继续进行非线性优化。在这个demo中,因为两个点云相机的位姿相差较大,因此也需要给出一个初始变换,否则优化效果很差。下图为给定初始变换后,直接使用这个初始变换没有进一步优化得到的结果。从图中可以看到,椅子没有重合在一起,还是有较大的偏移。

通过初始位姿进行配准
进行2000次迭代得到的配准结果,可以看到椅子上的点云已经基本配准了。

| ICP点云配准算法流程 |
|---|
| 1. 使用初始变换矩阵对点云做坐标变换(初始变换由粗匹配或者上一帧的变换矩阵提供) 2. 通过“最小距离”思想构造最小二乘问题,使用4.1的 svd方法计算最优R t 不断对1、2进行迭代,达到终止条件后得到最终优化结果 |
本章说的“匹配点之间的运动估计”,强调的是匹配好的点。如果点的数量太少,且点云不精确,那么就不适合用这个方法来计算相机之间的位姿。在实际应用中,我本打算在BIWI数据集上用kinect的点云坐标和头模关键点三维坐标通过ICP计算出头姿并与GT进行比较,想看下头姿的精度。结果发现由于点云并不精确,因此使用4.1的方法求解并不理想。又因为点的数量太少只有几十个,因此即便使用4.2中的方法也不合理。
总结
本帖整理了在计算机视觉领域常用的数学方法和它们的思想,包括正定方程、超定方程、SVD、最小二乘、DLT、ICP。理解这些数学方法的推导和它们的思想,当再遇到单应矩阵求解、相机标定、点云配准等应用时可以更本质地理解这些问题来优化自己的算法。
对于大部分人来说,这些问题的数学推导过程并不重要,只要理解了上面每个小节最后总结的“算法流程”基本就可以cover住SLAM源码中的实现过程。
Todo List:
非线性优化方法整理
点云配准















 4767
4767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









