






[轨迹预测]What-If Motion Prediction for Autonomous Driving
来源
Arxiv 2020
https://arxiv.org/abs/2008.10587
开源代码
https://github.com/wqi/WIMPgithub.com/wqi/WIMP
摘要
预测道路参与者的长期未来运动是部署安全自动驾驶汽车(AV)的核心挑战。可行的解决方案必须考虑到静态的结构信息,如道路车道,以及由多个参与者引起的动态社会互动。虽然最近的深度架构在基于距离的预测指标上取得了最先进的性能,但这些方法产生的预测与自动驾驶汽车的预期运动规划无关。
相比之下,我们提出了一种基于循环图的注意力方法,该方法具有可解释的几何(agent-lane)和社会(agent-agent)关系,支持注入反事实几何geometric目标和社会信息。
我们的模型可以根据假设或“假设”的道路车道和多智能体相互作用,从而产生不同的预测。我们表明,这种方法可以在规划循环中用于推理与AV预期路线直接相关的未观察到的原因或不太可能的未来
附赠自动驾驶最全的学习资料和量产经验:链接
问题
现有的方法预测轨迹时未考虑自动驾驶车辆的预期运动规划
原文补充:此处原文中描述为"these approaches produce forecasts that are predicted without regard to the AV’s intended motion plan.",字面意思理解为现在的方法在产生预测结果时并没有考虑自动驾驶车辆的预期运动规划
方法
提出了一种基于循环图的注意力方法,通过假设agent同lane以及agent之间的交互产生不同的预测,同时该方法中agent-lane以及agent2agent之间的关系是可解释的,支持注入反常的几何和社会交互信息进行预测
下图为本文所提出方法WIMP的示意图

WIMP的示意图
由上面的示意图可知,红色实线为主要预测的轨迹并没有同蓝色车辆(自动驾驶车辆AV)的灰色预期规划轨迹交互;这种情况说明,自动驾驶车辆AV上的规划器planner需要考虑到红色车辆进行非正常的左转(a图中的虚线)。planner可以通过c图中的有向图来识别和预期路径相交互的车道。
本文提出了一种基于RNN的环境感知多模态行为预测方法。我们的方法不需要光栅化的输入,并且包括道路网络注意力模块road network module和动态交互图dynamic interaction graph,以捕捉可解释的几何和社会关系。该模型支持有效地支持反事实推理。可以操纵单独agent的社会信息,以附加假设(未观察到)的行为者或消除特定的社会影响。
拓扑目标topological goals
地图中每个路段lane segment用节点表示,路段之间的连接关系为边,基于节点和边构建有向图。上图中©即为构建的有向图。**从此有向图上某一节点沿着边进行遍历,得到的节点和边的集合称之为lane polyline。**本文中的方法充分利用地图信息,生成拓扑目标topological goals,所谓拓扑目标就是车辆未来经过的lane segment及边的集合,也就是lane polyline。原文中提到以lane polylines的形式生成拓扑目标“We make intimate use of the road network, generating topological goals in the form of lane polylines that are constructed from the underlying directed graph of lane segments (Fig. 1c).”
反事实推理counterfactual forecasts
同时本文中的方法没有对完整的地图信息进行编码,对未来的轨迹预测是以某个拓扑目标为条件的。这样的做法使得自动驾驶汽车的规划器能够推理和查询相关轨迹。本文的突出创新点在基于这种拓扑查询验证反事实推理。
相关工作
论文中列举了一些相关的工作。
条件预测Conditional Forecasting
一些工作的预测是基于目的intent进行的;另外一些工作是以maneuver为条件进行预测的;其他一些工作预测其他agent的未来轨迹是以假设的focal agent未来轨迹的rollout推出为条件的(**个人理解:**假设focal agent的未来轨迹后预测其他agent的未来轨迹)。
本文的工作最接近PRECOG,PRECOG中证明了以某个agent的目标为条件预测其他agent未来轨迹时,相较于不使用以目标为条件预测的结果,结果是不同的。即以某个agent的目标为条件进行预测,更加有效;类似地,本文中的方法是以拓扑目标为条件进行预测的。同PRECOG中不同的点在于,本文方法不使用栅格化的图像,而且本文的方法可以高效的改变社会信息social context。(**个人理解:**这种高效的改变社会信息的原因来自于本文使用的是矢量化的输入数据,可以高效地改变预测轨迹时所基于的拓扑目标)
图神经网络Graph Neural Networks
图神经网络用于那些没办法使用像素矩阵以及简单向量表示的问题;本文的工作中使用了GAT图注意力网络;VectorNet同本文的方法有相似之处,但是存在以下不相同之处。
-
VN中用图结构表示车道折线lane polyline,而本文将车道折线表示为有序的点序列。
-
此外,VN中预测agent的未来轨迹时,是以agent周围指定范围领域内所有的地图元素为条件的。因此这与本文中以某个拓扑结构为条件进行预测的做法是不同的,本文的这种做法使得可以进行反事实的推理;
-
而且VN采用了一个仅限于单一轨迹的确定性解码器,而本文使用一种能够生成不同预测结果的多模态解码器。(尚未理解最后一点)
由上述内容可知,本文提出的方法主要有以下两个大的特点
-
本文提出的WIMP是一种基于RNN的环境感知多模态行为预测方法,包括道路网络注意力模块road network module和动态交互图dynamic interaction graph
-
WIMP的预测是以某个单一的拓扑目标为条件进行预测,因此支持反事实下的未来轨迹预测
接下来从两个特定出发介绍本文提出的方法
模型
问题建模

本文道路网络结构road network来表示车辆经过的有效路径valid path;其中道路网络结构是由道路段lane segment的中心点的集合表示的。(c)图中a——>c——>f就是一个道路网络结构,同时代表了一个有效路径valid path。其中a,c,f为道路段的中心点。以polyline为条件进行预测有以下几个好处
-
它为准确的预测提供了一个强大的、基于证据的先验
-
它允许进行可解释的模型行为分析,并实现了以假设的折线Polyline为条件的反事实预测
-
不需要图像处理组件的更节省内存的模型
由此可见,本文所提及的最突出的创新点——基于反事实信息的预测,其来源于以假设的Polyline为条件的预测

个人疑问:此处的假设还有点懵
上式的建模公式将联合条件分布因子分解为基于单个折线网络的单个agent未来轨迹的乘积,其他关于agent和折线信息的全局信息通过历史X和之前的预测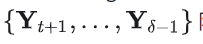 隐式的传递。
隐式的传递。
WIMP架构有三个关键组件,下图即为WIMP的结构图:
i)一个基于图的编码器,用于捕获场景上下文和高阶社交互动;此部分即为下图中的Social Graph Attention部分,用于捕获场景中agent之间的交互信息
ii)一个用于生成多样化的多模态预测的解码器;
iii)一种新的折线注意力机制,用于选择道路网络的相关区域作为条件。该部分为下图中的Polyline Attention部件
由下面的结构图可知,首先进行Polyline Attention操作,该操作实际上是建模agent同地图元素之间的交互关系;接下来通过Recurrent Encoder提取agent的时间特征;然后通过Social Graph Attention建模agent之间的交互,最后通过Actor Prediction输出多模态轨迹;总的来看,本文中特征建模的顺序为,agent2map——>agent temporal modeling——>agent2agent。下面对各个部分进行详细介绍。

WIMP的结构图
历史信息编码器Recurrent Encoder
所有agent的历史轨迹信息通过一个循环神经网络模块进行编码,所有类型的agent使用一个模块,共享一套参数


基于图注意力的agent2agent社会交互建模 Social Context via Graph Attention

多模态预测解码器

学习Learning


实验
下图为WIMP在数据集argoverse上表现,同WIMP同期的工作是LaneGCN,WIMP取得了接近的表现

WIMP同其他模型量化结果的比较
下表为WIMP在argoverse BT subset数据集的场景中的表现;BT subset由argoverse中大范围转弯的场景组成,WIMP在该集合中的表现要优于non-map-based的方法,因为polyline attention机制使模型能够更好地利用地图信息,即使在复杂场景中,也能捕获未来轨迹的多样性。

WIMP在BT数据集上的量化结果表现
WIMP在BT子集上表现优异,同时在整体数据集上的表现同样不错,这证明了WIMP在处理偏差-方差权衡(bias-variance trade-off)时的能力较好。
个人补充:偏差-方差权衡是一个统计学和机器学习领域的核心概念,它描述了模型的泛化误差可以分为偏差、方差和不可约误差三个组成部分。简单来说,偏差是由于模型过于简单而无法捕捉数据中的真实关系而产生的误差,而方差则是由于模型过于复杂,在训练数据上表现出过度拟合而在新数据上波动较大所产生的误差。
消融实验结果如下

消融实验
消融实验中没有对比WTA和EWTA,这点显得不足,论文内容中阐述EWTA优于WTA,但是在消融实验时并没有对比两者
WIMP在nuScenes数据集上的表现

nuScenes数据集上的量化结果
反事实推理实验效果 Counterfactual Validation
以下是反事实推理效果图1

反事实推理实现效果图2

总结
总的来看,我认为本文是一篇优秀的轨迹预测论文,论文的新颖性很好,主要有以下三个特点
-
Polyline attention建模agent同地图元素之间的交互
-
基于参考折线的反事实推理
-
EWTA
上述三个特点只是笔者暂时列举的,笔者目前仍在边看边学习,上文中的内容难免存在错误或重复叙述,如果有不足,非常欢迎指出!
总结以及联系待近期完善
联系
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals——Arxiv 2021















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









