







 本文介绍了卷积神经网络(CNN)的基本原理,包括卷积、池化、展平等步骤,并详细阐述了CNN在图像识别中的作用。通过PyTorch实现了一个食物识别模型,进行了多分类任务,展示了训练过程和性能指标,揭示了Max Pooling在减少计算消耗和保持特征不变性方面的优势。
本文介绍了卷积神经网络(CNN)的基本原理,包括卷积、池化、展平等步骤,并详细阐述了CNN在图像识别中的作用。通过PyTorch实现了一个食物识别模型,进行了多分类任务,展示了训练过程和性能指标,揭示了Max Pooling在减少计算消耗和保持特征不变性方面的优势。
文章目录
CNN
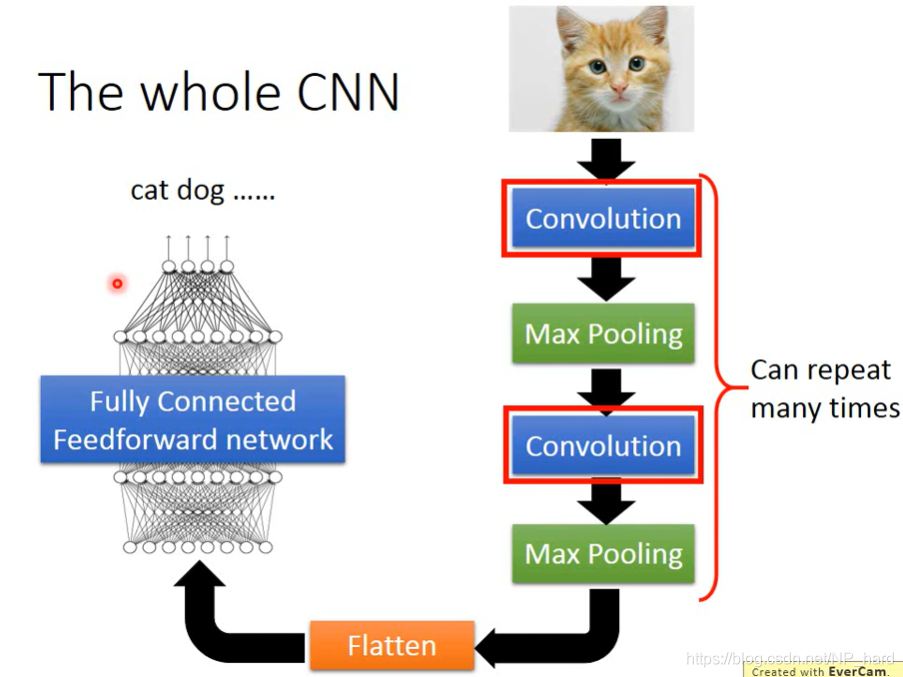
下图为CNN的整体架构,主要分为
- Convolution
- Max Pooling
- Flatten
Convolution
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
- in_channels表示的是输入卷积层的图片厚度
- out_channels表示的是要输出的厚度,即filter的数目
- kernel_size表示的是卷积核的大小,可以用一个数字表示长宽相等的卷积核,比如kernel_size=3,也可以用不同的数字表示长宽不同的卷积核,比如kernel_size=(3, 2)
- stride表示卷积核滑动的步长
- padding表示的是在图片周围填充0的多少,padding=0表示不填充,padding=1四周都填充1维
其实卷积很简单,就是使用卷积核(Filter)对image进行步长为stride的平移,依次于image对应的小矩阵计算内积
假设你有一张128x128的image,你用n个3x3的Filter去对它做convolution,那么你会得到nx126x126的cube,多少个Filter就会有多少层
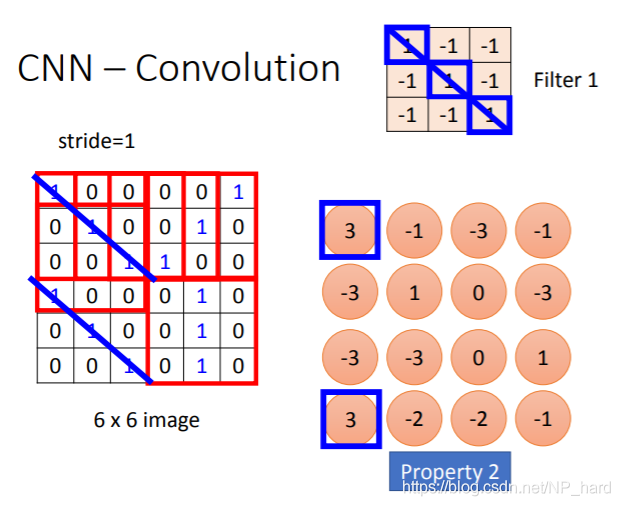
对于不同的filter,重复这样的操作得到多层property,这就是feature map
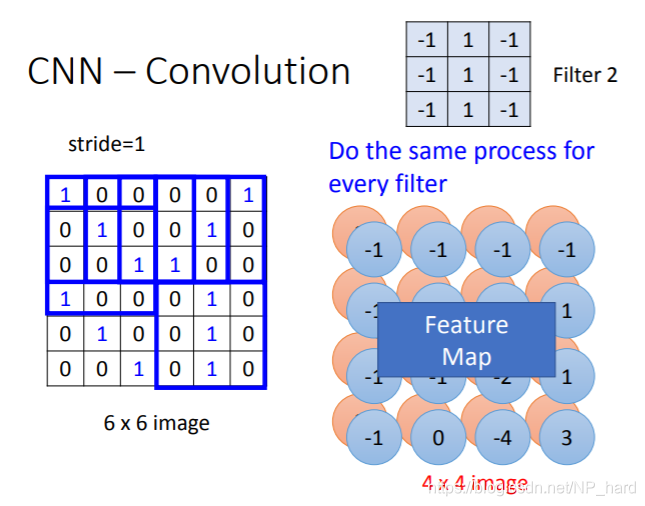
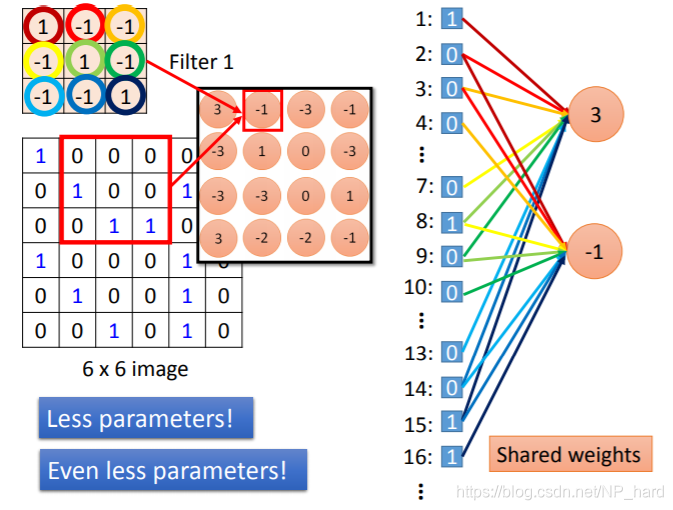
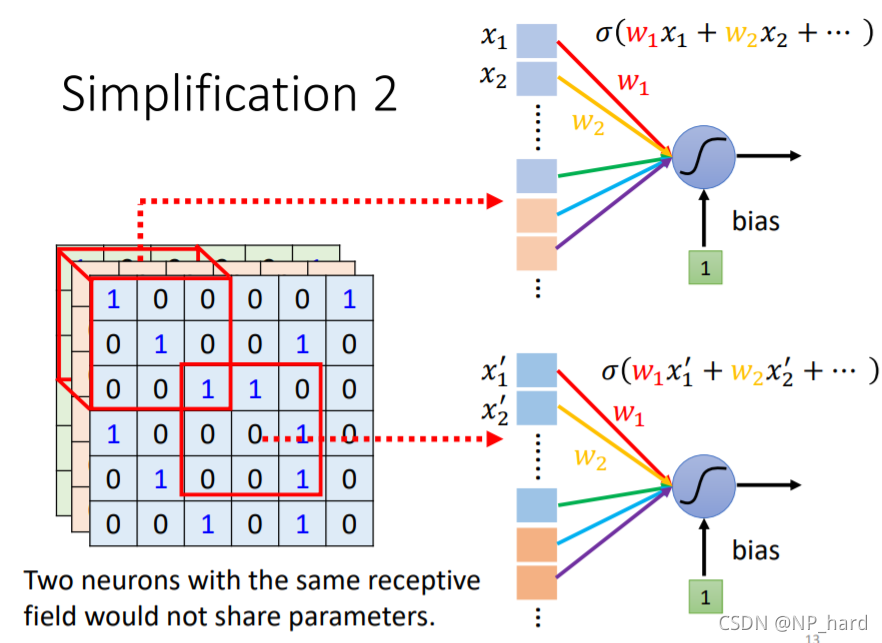
如图所示,对于filter1,其对36维图像的循环内积的过程,就是第一层hidden-layer的train过程,这样做的好处是
- 减少了每个neuron的weight数量,即减少了参数
- neuron3和neuron-1所用的weight之间存在共用(相同的颜色表示相同的weight),又减少了参数
卷积的动态效果
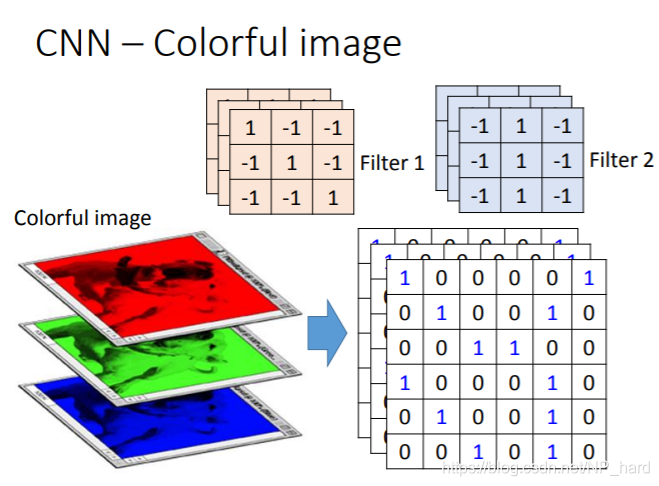
此时我们的输入的图片为7x7x3,即常见的RGB三色图,我们有两个filter,每个filter的维度为3x3x3,filter的厚度对应图片的厚度,卷积过程如下图所示
在卷积时,外层一圈为padding,这是为了利用边缘的信息,我们的卷积核按照步长进行移动,三张图片按对应的filter的三个维度进行卷积,得到的值和bias进行加和,输出到Output Volume对应的位置(两个filter对应两个Output矩阵),以此类推

Max Pooling
nn.MaxPool2d(kernel_size =2, stride=2, padding=0)
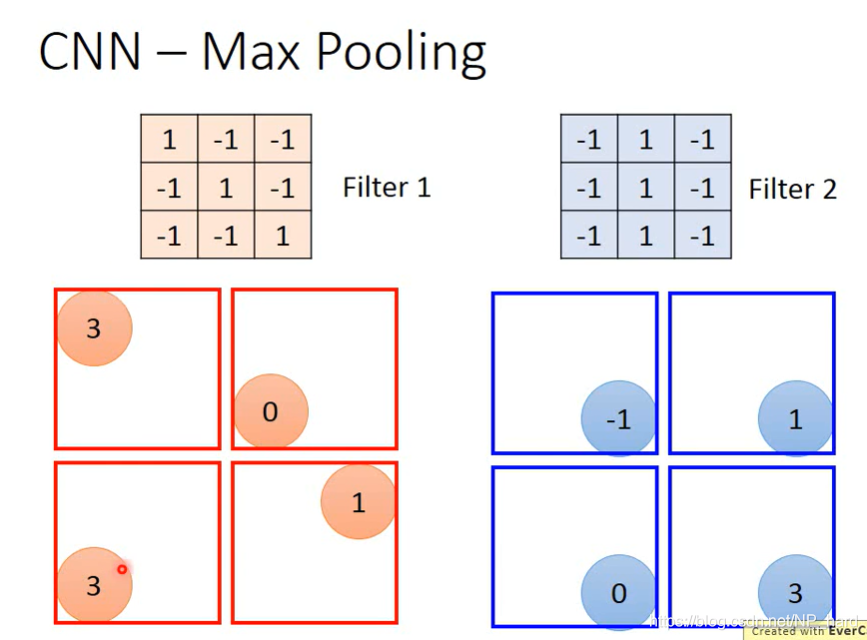
Max Pooling其实也很简单,就是根据kernel_size和stride,对convolution得到的cube进行区域分割并取区域最大值
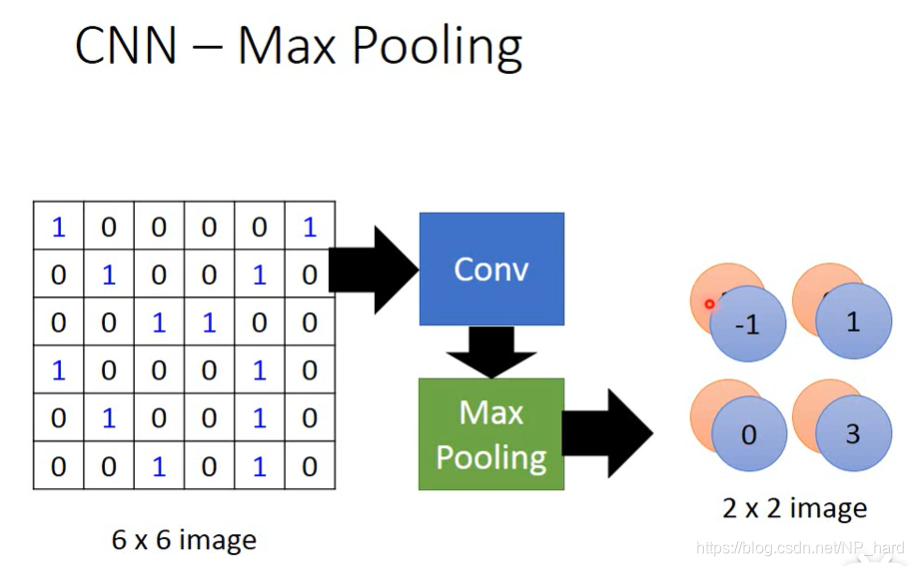
例如下图,一张6x6的image,经过convolution之后变为2x4x4,再经过Max Pooling之后变为2x2x2
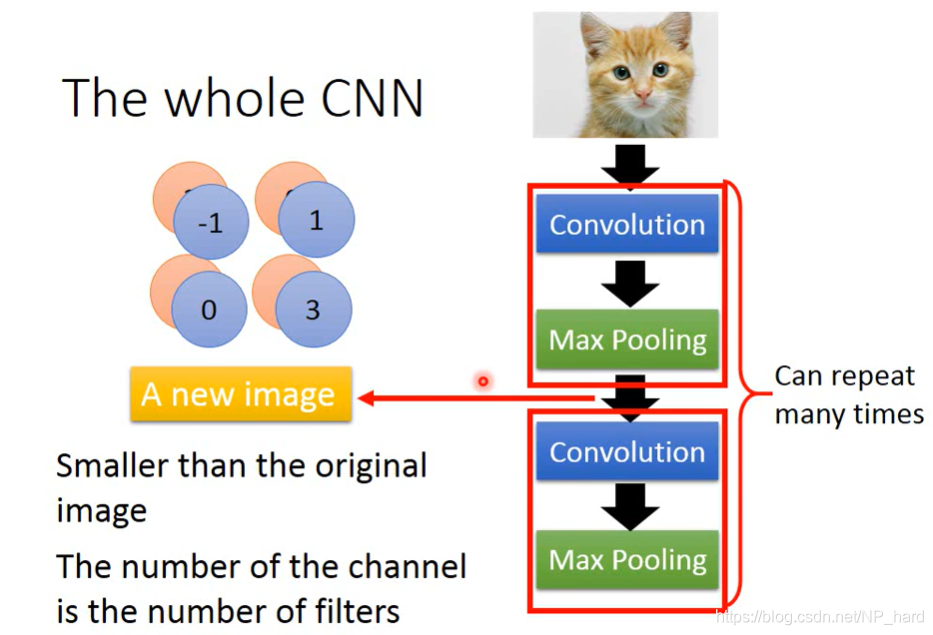
在经过第一次convlution和Max pooling之后,image变为了2x2,2 layer的cube,再次经过上述过程后,image的layer不会增加,始终为filter的数目,这是因为下一次convolution时会考虑image-cube的深度
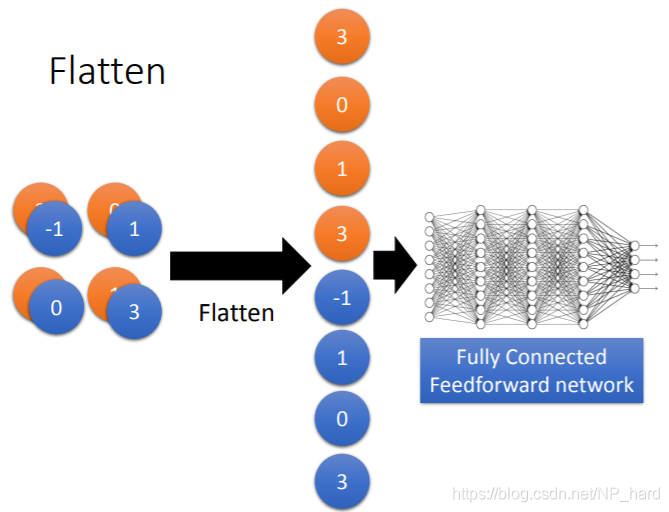
Flatten
当我们的图片经过多次Convolution和Max Pooling后,得到了2x2x2(厚度为2)的cube,我们可以直接将其展开为一列,并将其输入到全连接网络进行最后的训练
CNN的训练流程
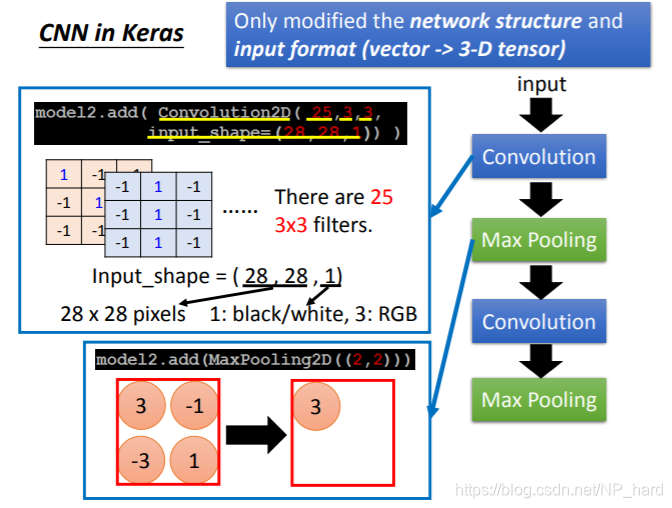
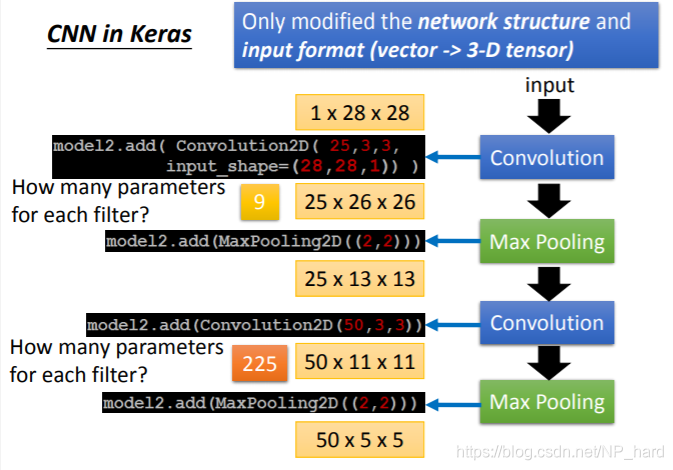
- 首先传入28x28的image
- 通过25个3x3的filter,矩阵由1x28x28变为了25x26x26
- 然后再通过2x2的max pooling,矩阵变为了25x13x13
- 然后再通过50个3x3的filter得到50x11x11的矩阵
- 再通过2x2的max pooling得到50x5x5的矩阵
- 最后flatten得到1250维的layer,再使用全连接BP
参数个数为:(3x3=9)+(3x3x25=225)=234
为什么要卷积?
卷积可以找到图像中不同位置出现的目标

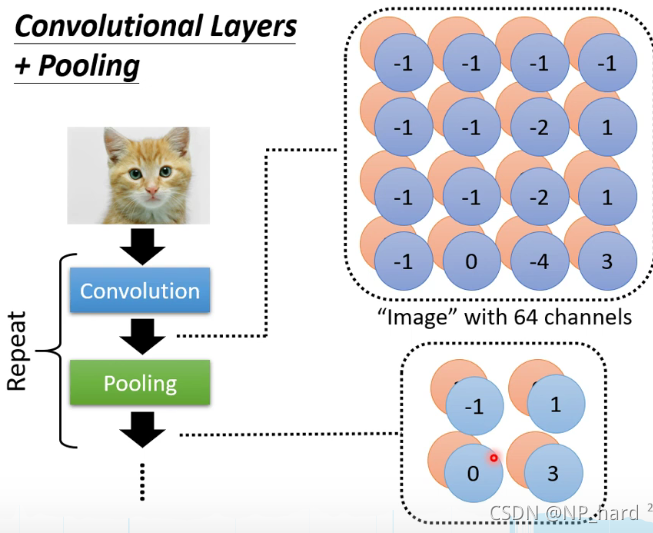
为什么要Max Pooling?
作用一:减少图像的像素点,减少计算消耗
如下图所示,将这幅含有鸟的图片按(行/列)分别取奇数位置的(行/列),这样可以减少图片的像素点个数,并且对图片的影响不会太大

Maxpooling也是一样,行和列的数量都少了一半
当然,如果你很有钱,不缺计算资源,那么干脆不用Maxpooling,因为Maxpooling还是会损失一些精度,例如Alphago的类神经网络就不做Maxpooling
作用二:invariance(不变性)
-
translation
像这样的图像,上下两张图的区别就是下面的图平移了,通过max pooling之后得到的filter矩阵相同

-
rotation
旋转后的特征经过max pooling之后filter矩阵也能相同

-
scale

作用三:增大感受野
特征在image的不同位置时,通过max pooling得到的filter矩阵相同

pytorch实现食物识别并进行多分类
Import需要的套件
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
利用opencv2读取数据,并存放再numpy数组中,作为x和y
def readfile(path, label):
# label:测试集不需要返回y值
image_dir = sorted(os.listdir(path))
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
# 枚举图片,填充数据集x,y
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])# 切分得到样本的label
if label:
return x, y
else:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









