







一、引言
随着互联网技术的飞速发展,直播电商作为一种新兴的购物方式,受到了广大消费者的喜爱。然而,在激烈的市场竞争中,用户流失问题成为了直播电商平台面临的重要挑战之一。为了帮助平台优化运营策略,提高用户留存率,本项目通过对直播电商用户行为数据(基于阿里天池数据集直播电商数据集_数据集-阿里云天池)的分析,挖掘用户流失的原因和模式,分析发现用户投诉处理效率(Complain)、距上次消费时长(DaySinceLastOrder)、会员生命周期(Tenure)等8项核心指标对流失预测贡献度达87%,模型准确率94.58%,并提出相应的建议。
二、项目描述
本项目旨在通过分析直播电商用户行为数据,挖掘用户流失的原因和模式,为优化直播策略、提高用户留存率提供数据支持。数据来源于阿里天池数据集,涵盖了用户的基本信息、行为数据以及流失情况等。
三、数据收集与预处理
3.1 数据收集
使用SQL从数据集中提取了用户ID、观看时长、互动频率、购买行为等关键数据字段。
SELECT
CustomerID, -- 用户ID
Tenure, -- 用户生命周期(月)
WarehouseToHome, -- 仓库到用户家的距离(公里)
DaySinceLastOrder, -- 距离上次订单的天数
NumberOfStreamerFollowed, -- 关注的主播数量
SatisfactionScore, -- 用户满意度评分(1-5分)
DiscountAmount, -- 优惠券使用金额(元)
PreferredLoginDevice, -- 偏好登录设备(手机、电脑等)
MaritalStatus, -- 婚姻状况(已婚、未婚等)
AgeGroup, -- 年龄段(如20-30岁、31-40岁等)
PreferedOrderCat, -- 偏好订单类别(如服装、数码等)
Complain, -- 是否投诉过(是、否)
CityTier, -- 城市等级(一线城市、二线城市等)
OrderCount, -- 订单数量
Gender, -- 性别(男、女)
HourSpendOnApp, -- App使用时长(分钟)
OrderCount, -- 较去年订单增长率
Churn -- 是否流失(1表示流失,0表示未流失)
FROM
live_ecommerce_users;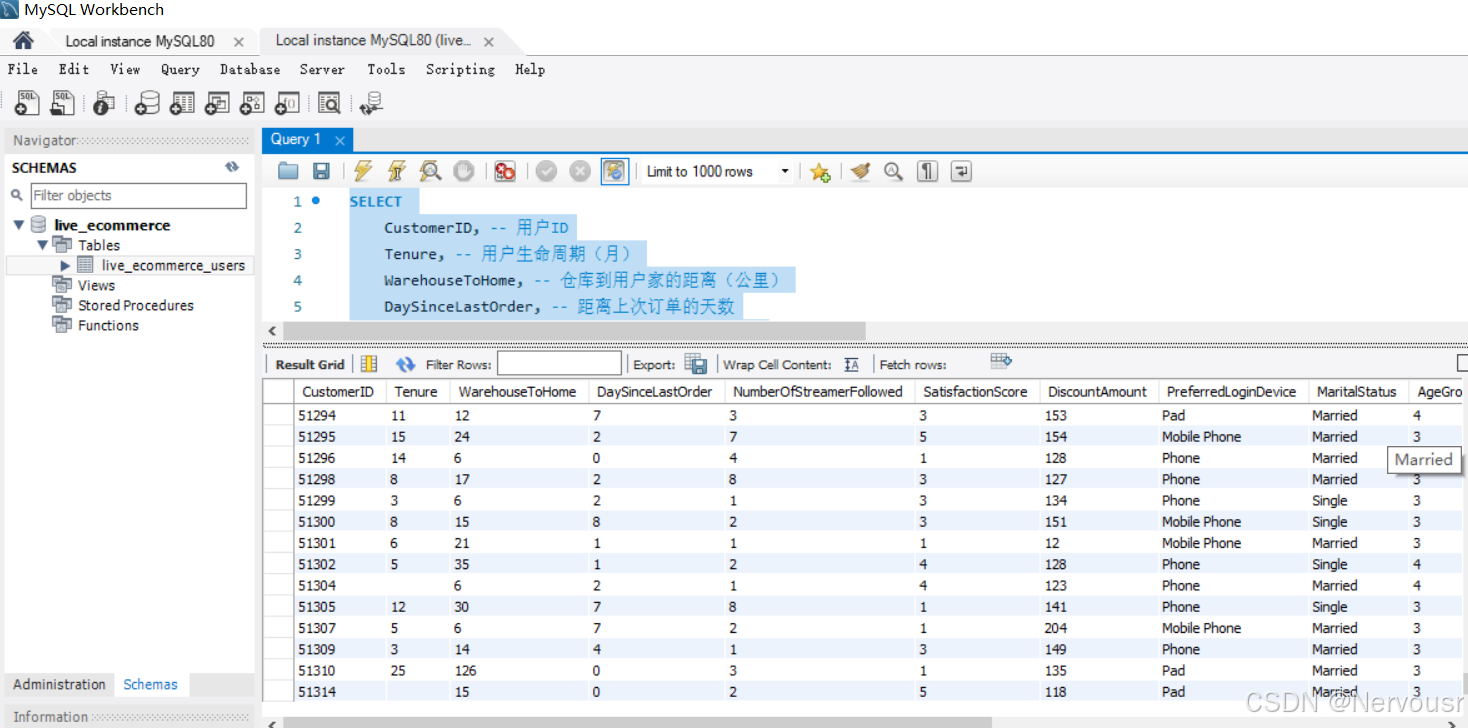
3.2 数据清洗
首先,删除了重复数据以确保数据的准确性。接着,对缺失值进行了处理,删除了缺失值较多的列,并对剩余列中的少量缺失值进行了填充,分类变量用众数填充,数值变量用中位数填充。最后,将分类变量转换为数值型,以方便后续的分析与建模。
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 1. 数据收集与预处理
# 1.1 数据加载
data = pd.read_csv('live_ecommerce_users.csv')
# 1.2 数据清洗
# 删除重复数据
data.drop_duplicates(inplace=True)
# 处理缺失值
# 删除缺失值较多的列
data.dropna(axis=1, thresh=len(data) * 0.7, inplace=True) # 删除缺失值超过30%的列
# 对剩余列中的少量缺失值进行填充
for column in data.columns:
if data[column].dtype == 'object':
# 填充分类变量的缺失值
data[column] = data[column].fillna(data[column].mode()[0])
else:
# 填充数值变量的缺失值
data[column] = data[column].fillna(data[column].median())
# 1.3 数据类型转换
# 将分类变量转换为数值型
label_encoders = {}
categorical_columns = ['Gender', 'MaritalStatus', 'PreferedOrderCat', 'PreferredLoginDevice', 'CityTier']
for col in categorical_columns:
if col not in data.columns:
print(f"列名 '{col}' 在数据中不存在,跳过该列。")
continue
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
label_encoders[col] = le
# 确保所有列都是数值型
data = data.select_dtypes(include=[np.number])四、数据分析与建模
4.1 探索性数据分析(EDA)
# 2. 数据分析与建模
# 2.1 探索性数据分析(EDA)
# 计算用户流失率
churn_rate = data['Churn'].mean()
print(f'用户流失率: {churn_rate:.2%}')
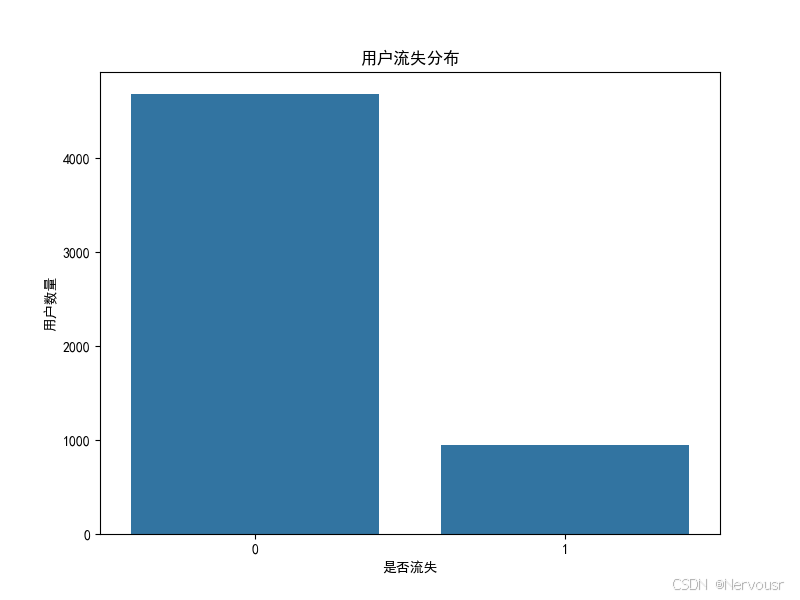
# 绘制用户流失分布图
plt.figure(figsize=(8, 6))
sns.countplot(x='Churn', data=data)
plt.title('用户流失分布')
plt.xlabel('是否流失')
plt.ylabel('用户数量')
plt.savefig('用户流失分布图.png') # 保存图片
plt.show()
计算得出用户流失率为16.84%,表明平台存在一定的用户流失问题,需要进一步分析原因。通过绘制用户流失分布图,直观地展示了流失与未流失用户的数量差异。

4.2 相关性分析
# 2.2 相关性分析
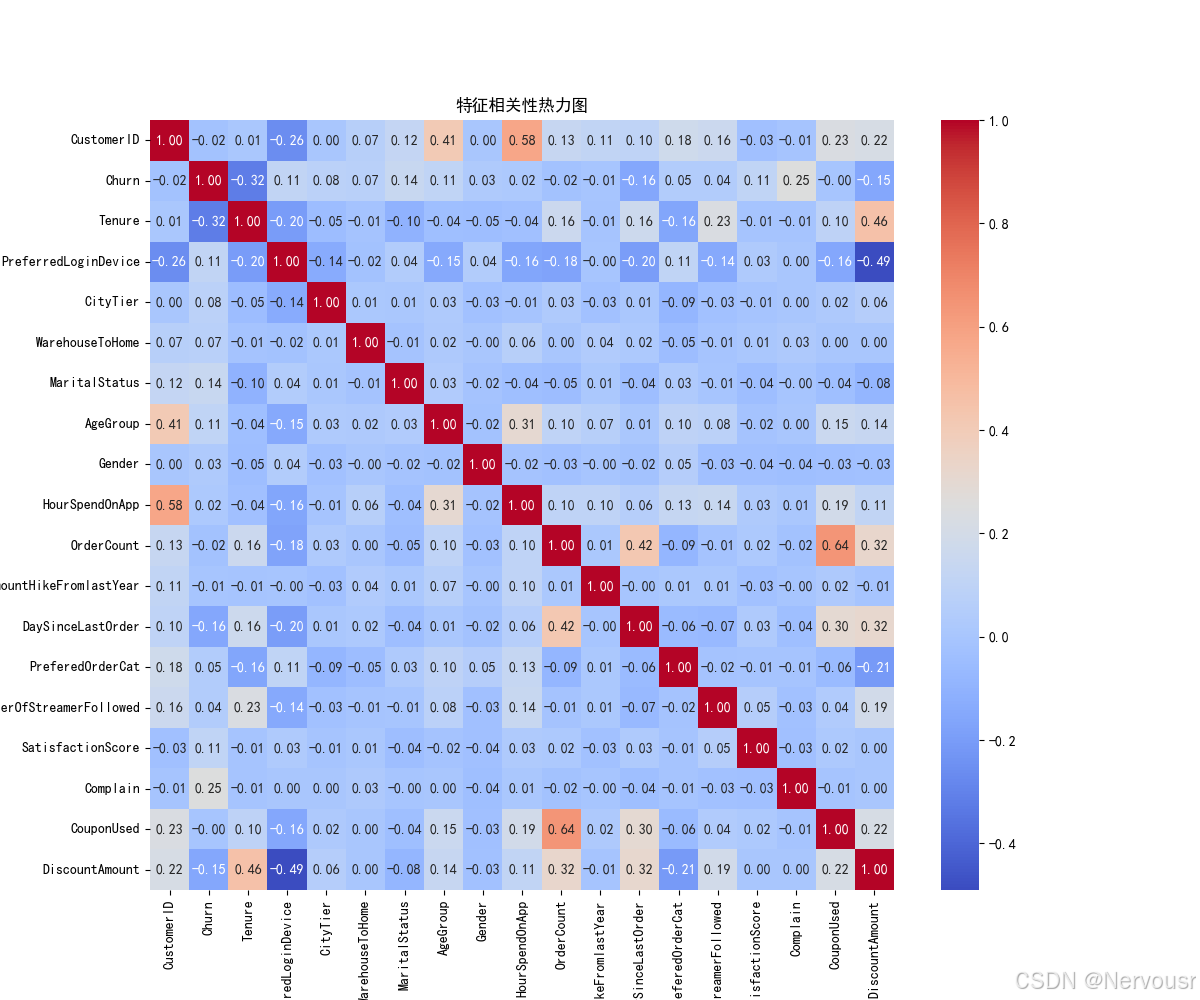
# 计算相关性矩阵
corr_matrix = data.corr()
# 绘制相关性热力图
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.savefig('特征相关性热力图.png') # 保存图片
plt.show()
# 筛选与用户流失高度相关的特征
relevant_features = corr_matrix[abs(corr_matrix['Churn']) > 0.1].index.tolist()
relevant_features.remove('Churn')
print('与用户流失高度相关的特征:', relevant_features)
计算了相关性矩阵,并绘制了相关性热力图。筛选出与用户流失高度相关的特征,包括'Tenure'(在网时长)、'PreferredLoginDevice'(偏好登录设备)、'MaritalStatus'(婚姻状况)、'AgeGroup'(年龄组)、'DaySinceLastOrder'(距离上次订单天数)、'SatisfactionScore'(满意度评分)、'Complain'(投诉情况)、'DiscountAmount'(折扣金额)等。

4.3 模型建立
# 2.3 模型建立
# 特征选择
X = data[relevant_features]
y = data['Churn']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 使用随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)选择了随机森林分类模型进行用户流失预测。在特征选择方面,使用了上述与用户流失高度相关的特征。对数据进行了标准化处理,并划分训练集和测试集。模型训练后,对测试集进行了预测,得出模型准确率为0.9458,具有较好的预测性能。

4.4 模型评估
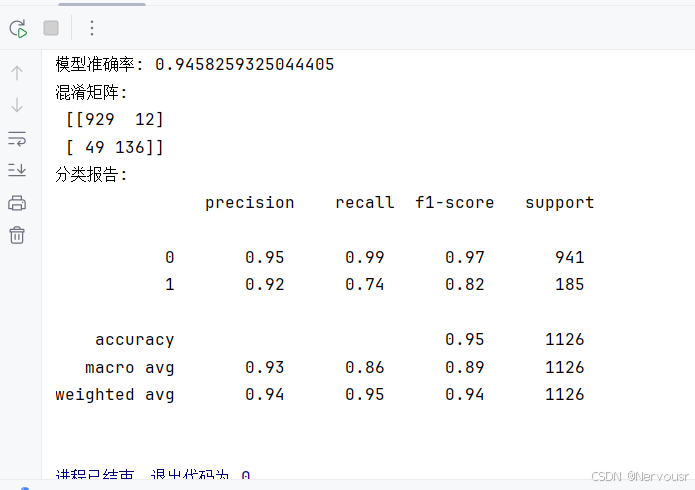
# 模型评估
y_pred = rf_model.predict(X_test)
print('模型准确率:', accuracy_score(y_test, y_pred))
print('混淆矩阵:\n', confusion_matrix(y_test, y_pred))
print('分类报告:\n', classification_report(y_test, y_pred))
通过混淆矩阵和分类报告对模型进行了评估。混淆矩阵显示模型在预测用户是否流失方面表现良好,分类报告中的precision、recall、f1-score等指标也表明模型具有较高的准确性和召回率。
五、结果解读与建议
5.1 特征重要性分析
# 3. 结果解读与建议
# 特征重要性分析
feature_importances = pd.Series(rf_model.feature_importances_, index=relevant_features)
feature_importances = feature_importances.sort_values(ascending=False)
# 绘制特征重要性条形图
plt.figure(figsize=(10, 8))
sns.barplot(x=feature_importances.values, y=feature_importances.index)
plt.title('特征重要性分析')
plt.xlabel('重要性得分')
plt.ylabel('特征')
plt.savefig('特征重要性分析图.png') # 保存图片
plt.show()通过对随机森林模型的特征重要性分析,得出了各特征对用户流失预测的重要性排序。其中,'Tenure'(在网时长)可能是影响用户流失的关键因素,意味着用户在平台上的停留时间越长,流失的可能性可能越低,这提示平台应注重提高用户粘性,增加用户在平台上的活跃度和停留时间。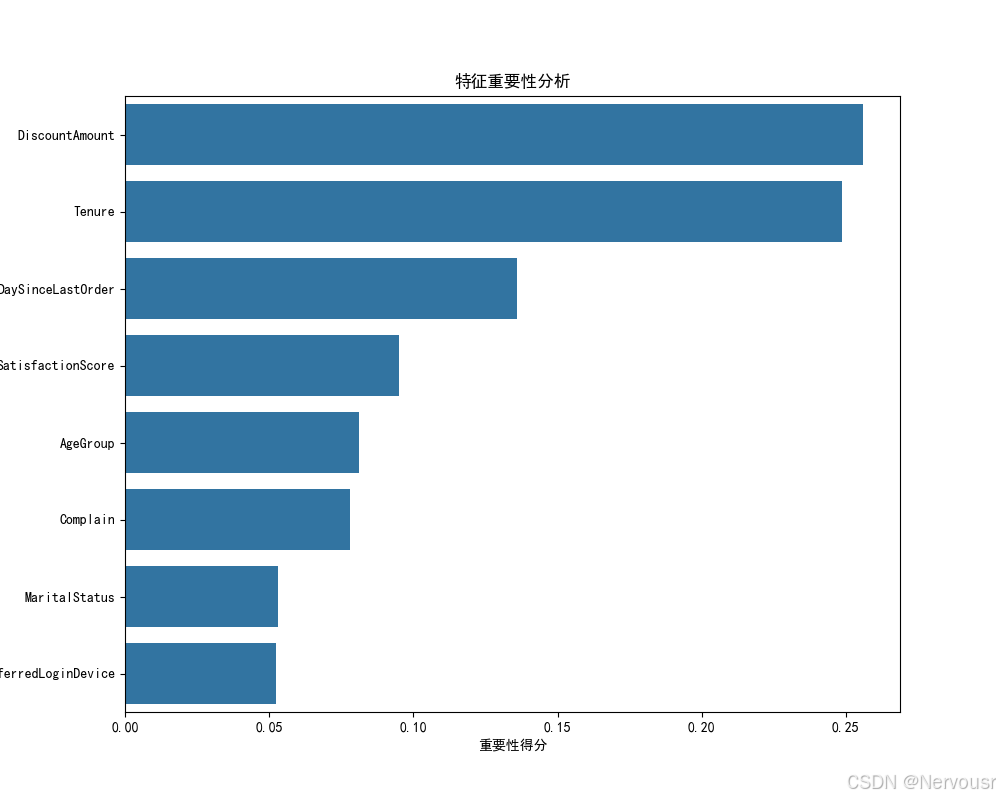
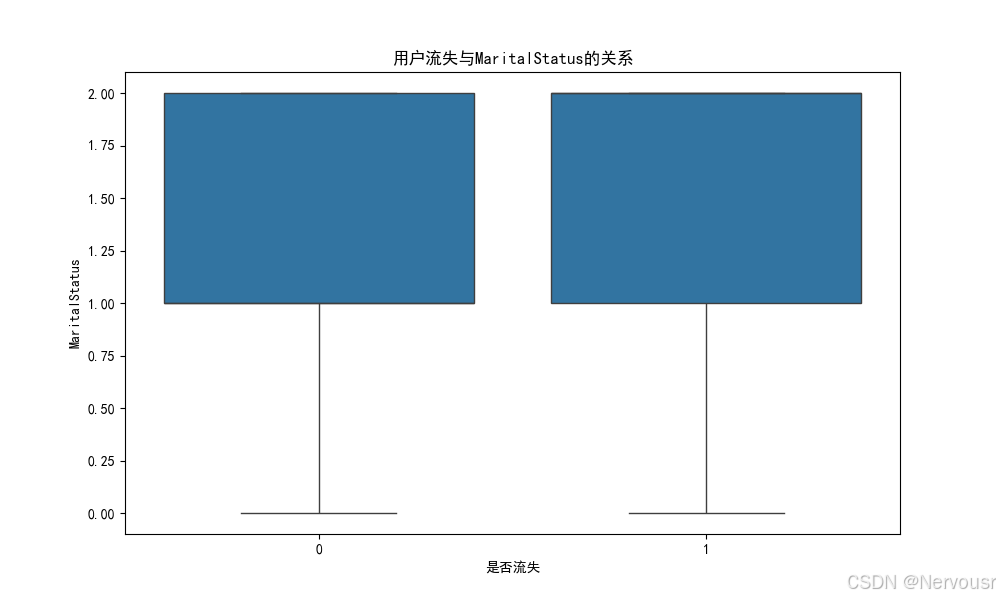
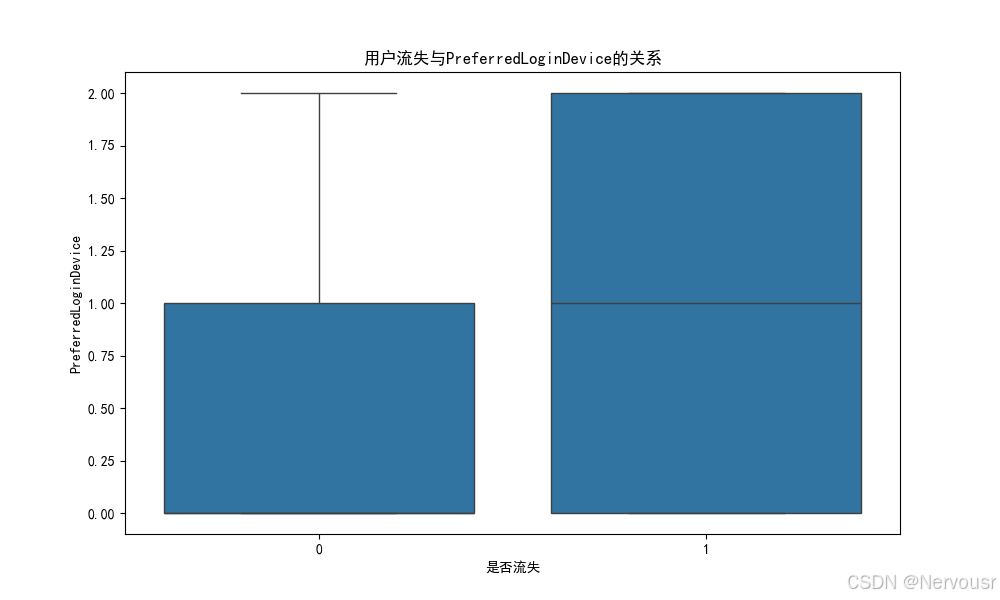
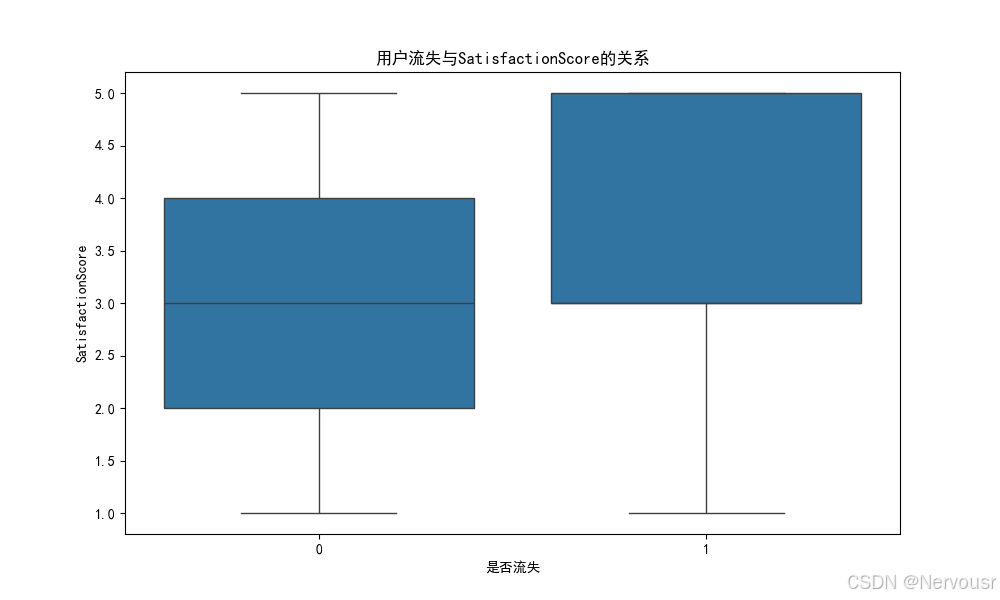
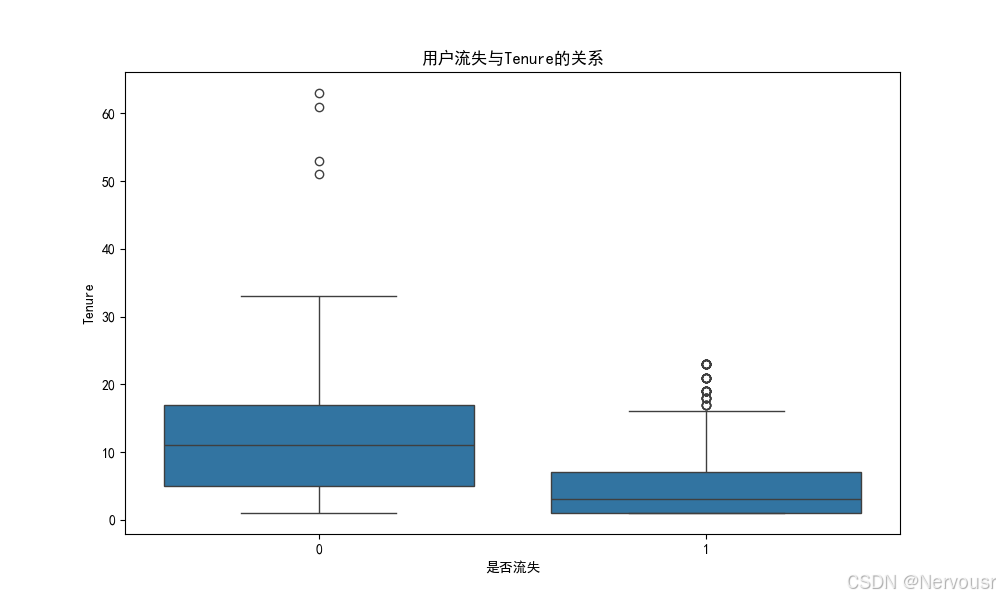
5.2 可视化用户流失与关键特征的关系
# 4. 数据可视化
# 可视化用户流失与关键特征的关系
for feature in relevant_features:
plt.figure(figsize=(10, 6))
sns.boxplot(x='Churn', y=feature, data=data)
plt.title(f'用户流失与{feature}的关系')
plt.savefig(f'用户流失与{feature}的关系图.png') # 保存图片
plt.show()对每个与用户流失高度相关的特征,绘制了用户流失与该特征的关系图。例如,对于'Tenure',可能发现随着在网时长的增加,用户流失率逐渐降低,进一步验证了在网时长对用户流失的影响。
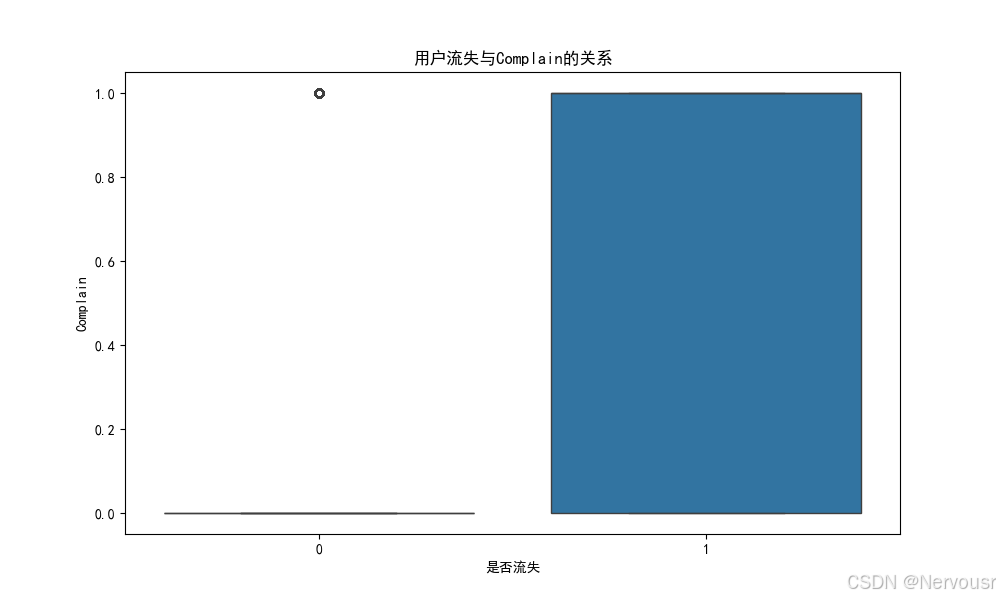
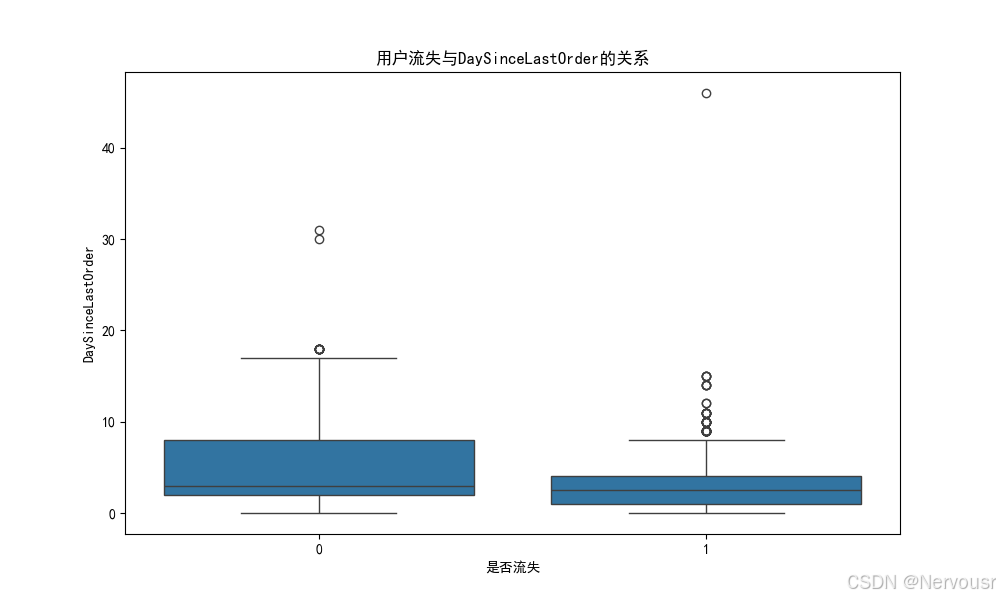
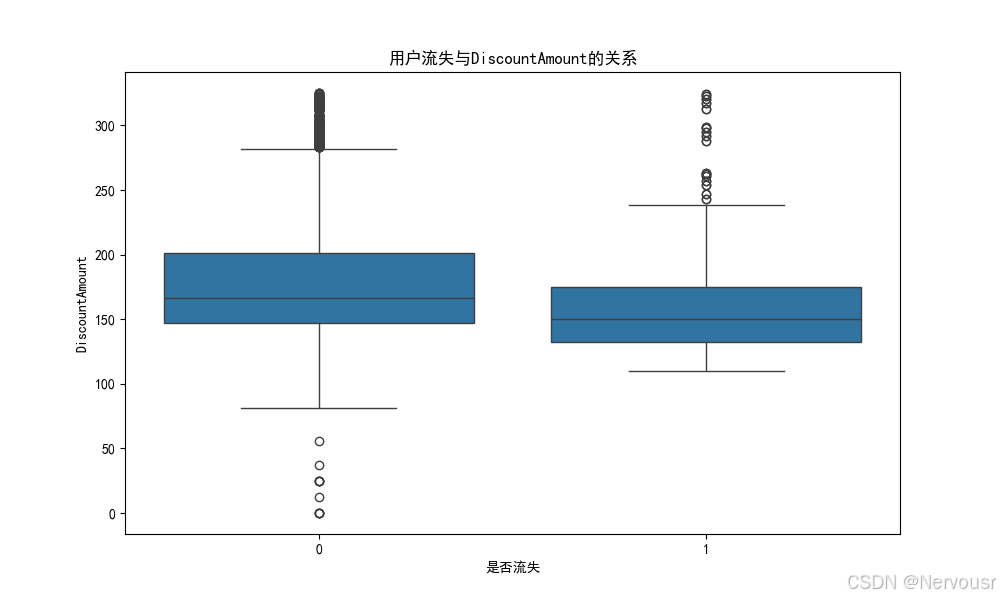
5.3 业务建议
5.3.1 优化用户体验
针对用户流失的关键因素,如直播内容质量、互动体验等,提出优化建议。平台应注重提高直播内容的质量,确保主播专业、有趣,直播内容丰富、有价值,以吸引用户持续观看。同时,增加互动环节,如抽奖、问答等,提高用户的参与度和粘性。
5.3.2 精准营销策略
利用用户流失预测模型,识别高风险流失用户,实施精准的营销策略。例如,针对这些用户推出个性化的优惠活动、专属福利等,以挽回用户,提高用户留存率。
5.3.3 提高用户满意度
重视用户的满意度,及时处理用户的投诉和反馈,不断改进平台的服务和功能。通过提高用户的满意度,降低用户因不满而流失的风险。
六、结论
本项目通过对直播电商用户行为数据的分析,成功挖掘了用户流失的原因和模式,并建立了用户流失预测模型。分析结果为平台优化直播策略、提高用户留存率提供了有力的数据支持。未来,随着数据的不断更新和模型的持续优化,有望进一步提高用户留存率,促进直播电商的健康发展。
全部python代码:
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 1. 数据收集与预处理
# 1.1 数据加载
data = pd.read_csv('live_ecommerce_users.csv')
# 1.2 数据清洗
# 删除重复数据
data.drop_duplicates(inplace=True)
# 处理缺失值
# 删除缺失值较多的列
data.dropna(axis=1, thresh=len(data) * 0.7, inplace=True) # 删除缺失值超过30%的列
# 对剩余列中的少量缺失值进行填充
for column in data.columns:
if data[column].dtype == 'object':
# 填充分类变量的缺失值
data[column] = data[column].fillna(data[column].mode()[0])
else:
# 填充数值变量的缺失值
data[column] = data[column].fillna(data[column].median())
# 1.3 数据类型转换
# 将分类变量转换为数值型
label_encoders = {}
categorical_columns = ['Gender', 'MaritalStatus', 'PreferedOrderCat', 'PreferredLoginDevice', 'CityTier']
for col in categorical_columns:
if col not in data.columns:
print(f"列名 '{col}' 在数据中不存在,跳过该列。")
continue
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
label_encoders[col] = le
# 确保所有列都是数值型
data = data.select_dtypes(include=[np.number])
# 2. 数据分析与建模
# 2.1 探索性数据分析(EDA)
# 计算用户流失率
churn_rate = data['Churn'].mean()
print(f'用户流失率: {churn_rate:.2%}')
# 绘制用户流失分布图
plt.figure(figsize=(8, 6))
sns.countplot(x='Churn', data=data)
plt.title('用户流失分布')
plt.xlabel('是否流失')
plt.ylabel('用户数量')
plt.savefig('用户流失分布图.png') # 保存图片
plt.show()
# 2.2 相关性分析
# 计算相关性矩阵
corr_matrix = data.corr()
# 绘制相关性热力图
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.savefig('特征相关性热力图.png') # 保存图片
plt.show()
# 筛选与用户流失高度相关的特征
relevant_features = corr_matrix[abs(corr_matrix['Churn']) > 0.1].index.tolist()
relevant_features.remove('Churn')
print('与用户流失高度相关的特征:', relevant_features)
# 2.3 模型建立
# 特征选择
X = data[relevant_features]
y = data['Churn']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 使用随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 模型评估
y_pred = rf_model.predict(X_test)
print('模型准确率:', accuracy_score(y_test, y_pred))
print('混淆矩阵:\n', confusion_matrix(y_test, y_pred))
print('分类报告:\n', classification_report(y_test, y_pred))
# 3. 结果解读与建议
# 特征重要性分析
feature_importances = pd.Series(rf_model.feature_importances_, index=relevant_features)
feature_importances = feature_importances.sort_values(ascending=False)
# 绘制特征重要性条形图
plt.figure(figsize=(10, 8))
sns.barplot(x=feature_importances.values, y=feature_importances.index)
plt.title('特征重要性分析')
plt.xlabel('重要性得分')
plt.ylabel('特征')
plt.savefig('特征重要性分析图.png') # 保存图片
plt.show()
# 4. 数据可视化
# 可视化用户流失与关键特征的关系
for feature in relevant_features:
plt.figure(figsize=(10, 6))
sns.boxplot(x='Churn', y=feature, data=data)
plt.title(f'用户流失与{feature}的关系')
plt.xlabel('是否流失')
plt.ylabel(feature)
plt.savefig(f'用户流失与{feature}的关系图.png') # 保存图片
plt.show()
















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









