







一些小伙伴询问filebeat传输到logstash时如何调用pipeline,我这里补充一下。
关于数据过滤的方式,我了解的有两种:
- 传输到ES调用pipeline
- 传输到logstash,在logstash.conf文件中设置语句。
第一种方式就是本篇博客中使用的,而第二种可以参考ELK入门(五)——messages和log日志生成时间替换时间戳(grok+data)【关于grok语法和使用方式也参见这个博客】,同样实现了两种时间格式的时间戳替换。
其实这两种方式虽然语法略有不同,但本质是一样的,都使用了grok插件,运用某些匹配、修改、添加字段的操作来实现数据处理。
不过有一点需要注意的是,如果匹配不成功,则数据直接会无法传输到ES中。
一、在Dev tool中新建pipeline
我将pipeline名字定义为isodate,可以自命名,其中所做的操作是
1.利用grok插件在message字段中匹配TIMESTAMP_ISO8601时间,保存为logdate字段
2.利用date插件,匹配logdate字段,将timestamp字段替换。匹配格式为YYYY-MM-dd HH:mm:ss,SSS
其中,替换timestamp是默认的
在pattern中,分别对应了两种时间格式
%{SYSLOGTIMESTAMP:logdate} # 对应Jan 22 10:01:01
# "MMM dd HH:mm:ss" # 匹配方式
%{TIMESTAMP_ISO8601:logdate} # 对应2021-01-29 08:53:00,321
# "YYYY-MM-dd HH:mm:ss,SSS" # 匹配方式代码1(年份可能有误):
# 注释内容记得全部删除
PUT _ingest/pipeline/isodate # test-news-server-online 为流水线的名称
{
"description" : "ISOdate", # 对 pipeline 进行描述
"processors" : [
{
"grok" : { # 使用 grok 对日志内容进行提取
"field" : "message", # 选择要提取信息的字段
"patterns" : [
"%{TIMESTAMP_ISO8601:logdate}"
],
"ignore_failure" : true # 如果遇到错误则忽略
},
"date" : { # date默认会替换时间戳timestamp
"field" : "logdate", # 指定使用新增的 logdate 字段
"timezone" : "Asia/Shanghai", # 指定输出时间的时区,不指定的话可能会比正确的时间晚 8 个小时
"formats" : [
"YYYY-MM-dd HH:mm:ss,SSS"
],
"ignore_failure" : true
}
}
]
}
代码2:
实际运行的过程中发现很多数据的年份产生了错误,2020年9月的数据导入后变成了2021年9月,但是生成的logdate字段和其他的月日时分秒都没有问题,目前不知道具体是什么原因,但是解决办法是先删去timestamp字段,再利用date插件加上
# 注释内容记得全部删除
PUT _ingest/pipeline/isodate # test-news-server-online 为流水线的名称
{
"description": "ISOdate", # 对 pipeline 进行描述
"processors": [
{
"grok": { # 使用 grok 对日志内容进行提取
"field": "message", # 选择要提取信息的字段
"patterns": [
"%{TIMESTAMP_ISO8601:logdate}"
],
"ignore_failure": true # 如果遇到错误则忽略
},
"remove" : {
"field" : "@timestamp"
}
},
{
"date": { # date默认会替换时间戳timestamp
"field": "logdate", # 指定使用新增的 logdate 字段
"target_field" : "@timestamp",
"timezone": "Asia/Shanghai", # 指定输出时间的时区,不指定的话可能会比正确的时间晚 8 个小时
"formats": [
"YYYY-MM-dd HH:mm:ss,SSS"
],
"ignore_failure": true
}
}
]
}
GET语句可以查看pipeline,看是否成功生成
GET _ingest/pipeline/isodate
如果要删除pipeline可以运行
DELETE _ingest/pipeline/isodate二、配置filebeat.yml文件
现有的4个hadoop数据可以按名称分为2类输入,我们可以给现有的数据设置标签fields.index,分别设置为datanode和nodemanager

配置filebeat.yml
vim /data/elk-ayers/filebeat-7.10.1/filebeat.yml# hadoop数据的相关配置
filebeat.inputs:
- type: log
paths:
- /root/log/*datanode*.log.*
pipeline: isodate
fields:
index: 'datanode'
- type: log
paths:
- /root/log/*nodemanager*.log.*
pipeline: isodate
fields:
index: 'nodemanager'
# 输出
output.elasticsearch:
hosts: ["localhost:9200"]
indices:
- index: "filebeat-7.10.1-datanode"
when.equals:
fields.index: "datanode"
该方法使得传入的数据经过isodate管道处理,匹配时间戳后传输到elasticsearch
三、注意事项
(1) 重运行数据量变少
参考博客ELK入门——解决:删除索引,重运行logstach后messages数据量变少
由于filebeat每次运行会产生一个registry文件,记录文件读取情况,重新运行会从上次结束的地方继续,导致没有数据量。所以我每次都会停止filebeat,删除registry,删除索引,然后再重运行filebeat,以重新读取完整文件,具体过程是
1.终止filebeat
systemctl stop filebeat2.删除registry文件
rm -rf /data/elk-ayers/filebeat-7.10.1/data/registry3.删除产生的索引
没有重新设置index,所以产生的索引名字是filebeat-7.10.1-2021.02.03-000001
4.重新运行filebeat
systemctl start filebeat(2)通过检索快速查看时间戳是否匹配
运行filebeat之后可以直接在devtool运行命令,很快就知道结果对不对了,运行第一段内容,发现时间戳不匹配
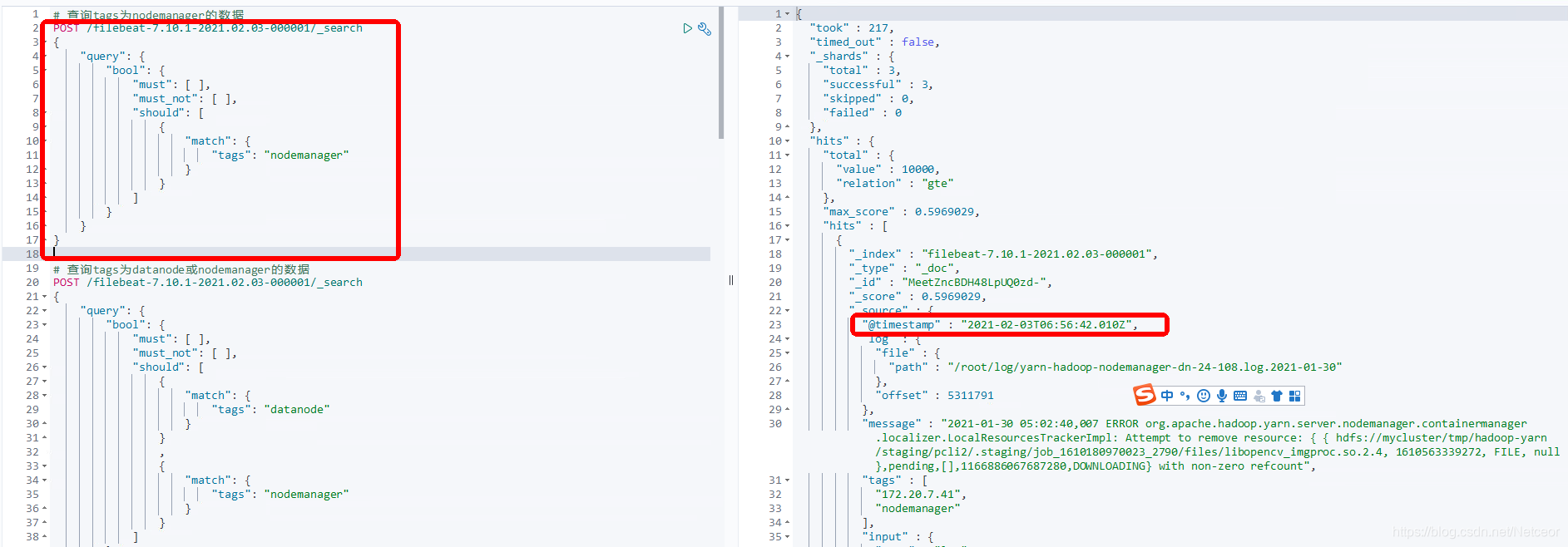
四、错误小结
1.pipeline with id [] does not exist
pipeline名字不要大写
由于我第一次定义的时候定义的管道名字是ISOdate,导致一直无法成功,启动filebeat的时候查看日志,发现一直说找不到我们定义的管道

发现我们定义和调用的都是ISOdate,但过程中会自动转换成小写的。
2.年份有误
实际运行的过程中发现很多数据的年份产生了错误,2020年9月的数据导入后变成了2021年9月,但是生成的logdate字段和其他的月日时分秒都没有问题,目前不知道具体是什么原因,但是解决办法是先删去timestamp字段,再利用date插件加上
3.500- Internal Server Error
如果报错500,错误提示compressor detection can only be called on some xcontent bytes or compressed xcontent bytes,可能是因为注释没有删除干净,在Dev tools中是没有# 的注释的
参考博客:















 4600
4600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









