







摘要 网络钓鱼邮件是网络安全领域的重要威胁,其精准识别对于保护用户信息和防止欺诈至关重要。本文利用Kaggle平台下载了包含钓鱼邮件和安全邮件的数据集,结合数据集特点,采用卷积神经网络(CNN)模型对邮件进行分类识别。通过对数据的预处理与特征提取,将邮件内容转化为适合CNN处理的形式,并利用深度学习算法训练分类模型。实验结果表明,所构建的CNN模型能够有效区分钓鱼邮件与安全邮件,识别准确率达到较高水平,为邮件安全管理提供了一种高效可靠的技术方案。
关键词 钓鱼邮件;卷积神经网络(CNN);网络安全
Abstract Phishing emails are an important threat in the field of network security, and their accurate identification is crucial for protecting user information and preventing fraud. In this paper, a dataset containing phishing emails and secure emails is downloaded using the Kaggle platform, and a convolutional neural network (CNN) model is used to classify and identify the emails by combining the characteristics of the dataset. Through the preprocessing and feature extraction of the data, the content of the emails is transformed into a form suitable for CNN processing, and the deep learning algorithm is used to train the classification model. The experimental results show that the constructed CNN model can effectively distinguish between phishing emails and secure emails, and the recognition accuracy reaches a high level, providing an efficient and reliable technical solution for email security management.
Key words Phishing emails; Convolutional neural network (CNN); Cyber security
1. 引言
随着网络安全技术的不断进步,钓鱼邮件依然是网络攻击中广泛使用的手段之一,且在许多网络攻击事件中扮演着重要角色。尽管目前已有多种钓鱼邮件检测技术,且其性能不断提高,但随着攻击者使用的手段变得更加复杂且隐蔽,传统的检测方法依然面临着不少挑战。钓鱼邮件通常通过伪装成合法邮件,诱导用户点击恶意链接或下载恶意附件,进而实现敏感信息的窃取或发起进一步的系统入侵。
本文首先介绍钓鱼邮件的危害与影响,其次,本文回顾了当前钓鱼邮件检测技术的发展历程,探讨了传统检测方法与新兴深度学习技术的优缺点。最后,本文提出了一种基于卷积神经网络(CNN)的钓鱼邮件识别方法。通过引入深度学习技术,本文构建了一个高效且具有较强鲁棒性的模型,能够在复杂的邮件数据中高效识别钓鱼邮件。实验结果表明,该CNN模型能够显著提高钓鱼邮件检测的准确性和可靠性,为实际应用中的钓鱼邮件识别提供了更具有效性的解决方
2. 相关研究现状
2.1. 钓鱼邮件的危害与影响
网络钓鱼攻击是一种通过伪装成可信赖实体,诱使用户泄露敏感信息(如账户密码、银行信息等)的网络欺诈行为。钓鱼邮件作为这种攻击的主要手段,通常伪装成来自合法机构的通信,诱导用户点击恶意链接或下载恶意附件,导致个人信息泄露、系统入侵甚至财产损失。钓鱼邮件的欺骗性极强,攻击者通过伪造发件人地址、仿冒网页和使用虚假紧急信息(如账户异常、中奖通知等),诱使用户泄露账户凭证或点击恶意链接。通过获取用户的登录信息,攻击者不仅可以窃取资金,还可能进一步感染受害者的计算机系统,造成更严重的后果[1]。
钓鱼邮件的检测面临诸多挑战[2]。首先,攻击者的灵活性使得邮件地址、IP地址和域名的伪造变得更加隐蔽,传统的基于规则的检测方法难以应对这一变化。其次,钓鱼邮件通常以大范围群发的方式传播,攻击者并不关心具体受害者,而是依靠广泛传播增加攻击成功的可能性。此外,钓鱼邮件的诱导性通过紧急、吸引眼球的内容使得用户更容易上当。一旦用户点击恶意链接或附件,攻击者就能远程控制设备、窃取机密文件,甚至窃取财务信息,造成巨大的经济损失。
随着人工智能的发展,恶意行为者开始利用AI生成高度逼真的钓鱼邮件[3]。这些邮件能够模仿正常邮件的内容、格式和语言风格,甚至针对目标用户的特点进行个性化定制,从而大大提高攻击成功率。同时,AI也可以自动化地扫描网络漏洞,制定更有效的攻击策略,使网络钓鱼攻击更加智能化和高效。这一技术的应用使得钓鱼攻击更加隐蔽和难以防范,给网络安全防御带来了前所未有的挑战。
2.2 钓鱼邮件检测技术的挑战与发展
随着钓鱼邮件攻击手段的不断演变,现有的钓鱼邮件检测技术面临许多挑战。首先,传统的基于规则和关键词的检测方法已无法应对复杂多变的钓鱼邮件攻击[2]。虽然基于沙箱和黑白名单的检测方法仍然广泛应用,但其局限性也逐渐显现。例如,基于沙箱的检测方法无法有效检测云附件,而黑白名单方法则受到钓鱼邮件伪装域名和动态IP地址的影响,导致检测准确性较低。随着攻击者不断创新,新的检测方法和技术亟需发展。
近年来,机器学习技术逐渐在钓鱼邮件检测中发挥了重要作用。通过对大量钓鱼邮件样本的训练,机器学习算法能够提取出更加复杂且隐蔽的特征,从而提高检测准确性。特别是分类算法,如支持向量机(SVM)和随机森林(RF)[4]等,通过对邮件内容进行深度学习,能够有效识别钓鱼邮件的特征并进行分类判断。与此同时,深度学习技术也开始在钓鱼邮件检测中得到越来越广泛的应用,尤其是通过训练模型从邮件内容中提取上下文信息,从而对复杂的钓鱼邮件攻击进行更准确的判定。
随着攻击模式的不断变化和检测需求的增加,未来的钓鱼邮件检测技术将更加注重算法的智能化与实时性。为了提高检测的效率和准确性,研究者正在不断探索新的技术与方法,如基于深度学习的模型改进,自动化特征提取等技术。此外,结合多种技术手段,尤其是跨领域的技术融合,将有助于增强钓鱼邮件检测系统的鲁棒性,并为应对更为复杂的攻击提供更有力的支持。
3. 研究模型
在本实验中,采用 Python 编程语言实现了一种基于 CNN(卷积神经网络)算法的钓鱼邮件检测系统。实验旨在对收集的邮件数据进行分类和识别,通过设计的数据清洗,特征提取和模型训练流程,有效提高检测精度和效率。
3.1 数据准备
在本次实验中,所使用的数据资料来源于 Kaggle 平台提供的钓鱼邮件数据集。数据集内容涵盖多个来源,包括不同场景下的邮件样本,如钓鱼邮件和正常邮件。本次实验将对多个数据集进行整合,以丰富样本多样性,增强模型的泛化能力,从而提高钓鱼邮件检测的准确性和可靠性。
表1 不同数据集的邮件占比情况
| 数据集名称 | 数据集数量 | 安全邮件占比 | 钓鱼邮件占比 |
| Phishing_Email | 18650 | 61% | 39% |
| CEAS_mail_body | 24000 | 45% | 55% |
| CEAS-08 | 39154 | 44% | 56% |
| Enron | 29767 | 56% | 46% |
3.2 数据处理
本研究通过多个平台收集不同的数据集,包括邮件内容及其对应的分类标签(1 表示钓鱼邮件,0 表示安全邮件)。为了确保数据的规范性和一致性,本次实验对数据进行了整合、清洗与数据集构建。整合后的数据包含两列:一列为邮件内容文本,另一列为分类标签。
(1)在清洗过程中,主要包括以下步骤:
- 链接替换:将所有链接替换为占位符 “url”,以消除链接信息对分类的干扰。
- 邮箱地址替换:将所有邮箱地址替换为占位符“email”,避免敏感信息的泄露。
- 特殊字符处理:删除所有特殊字符,仅保留字母、数字、空格和引号等必要内容。
- 文本格式统一:将文本统一转化为小写,并移除多余的空格,以确保数据格式的一致性。
这些处理措施为后续模型训练提供了干净且结构化的输入数据。
(2)构建词汇表,主要步骤如下:
为了有效地处理文本数据,首先将文本转化为词汇索引。在此过程中,本实验利用了一个简单的词汇表(vocabulary),其大小由训练集中的词频决定。每个文本被分割为单词,并通过词汇表映射为对应的索引。该过程保证了文本数据的结构化,并为后续的卷积操作提供了所需的输入格式。
最后,为了清晰地评估分类模型的效果,将清洗整理后的数据集按 2:8 的比例将数据集划分为测试集和训练集,最后将使用于后期测试评估和训练。
3.3 模型构建
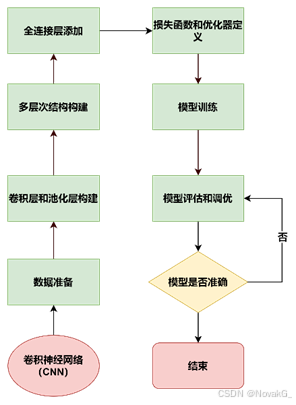
图1 CNN模型构建流程图
(1)卷积层与池化层
在CNN模型[5]中,文本数据首先经过嵌入层,该层将词汇索引映射到一个固定维度的向量空间中。接着,文本数据经过多个卷积层进行特征提取。本研究中采用了三种不同大小的卷积核(3, 4, 5),每个卷积层的输出通道数为100。这些卷积操作通过卷积核在词嵌入空间中滑动,捕捉局部特征。随后,通过池化层对卷积结果进行最大池化(max pooling),以减少特征维度并提高模型的平移不变性。
(2)全连接层与分类输出
卷积和池化操作后,提取到的特征被展平,并输入到全连接层进行分类。全连接层将高级特征映射到最终的输出类别,在本实验中,共有两个类别(正常邮件与钓鱼邮件),为了防止过拟合,模型使用了Dropout层,随机丢弃部分神经元以提高模型的泛化能力。
(3)损失函数与优化器
模型训练过程中,本次实验选择了交叉熵损失函数(Cross-Entropy Loss),这是多类别分类问题中常用的损失函数。为了优化损失函数,本次实验采用了Adam优化器,它能够动态调整学习率,帮助网络快速收敛。学习率设置为1e-3。
(4)模型评估与性能分析
在训练过程中,数据集被分为若干个小批次(batch),每个批次通过反向传播算法进行权重更新。训练过程中,通过记录了每个epoch的损失值,并在每个epoch结束后通过测试集对模型进行评估。评估使用了准确率(Accuracy)、F1分数和AUC(Area Under Curve)等指标来判断模型的性能。
4. 实验结果及分析
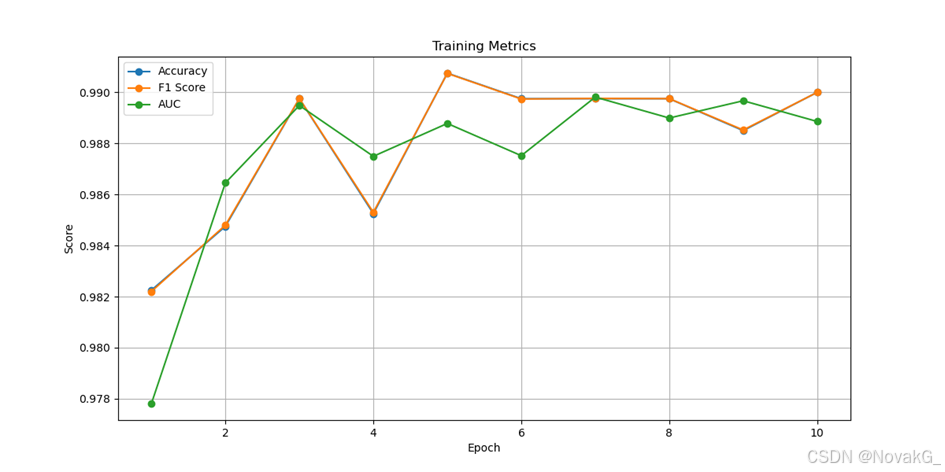
图2 样本数为27892的训练结果
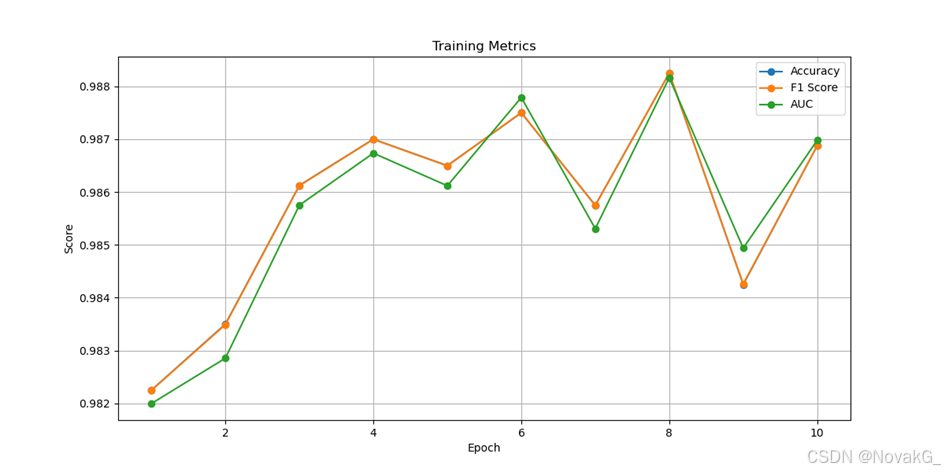
图3 样本数为55785的训练结果
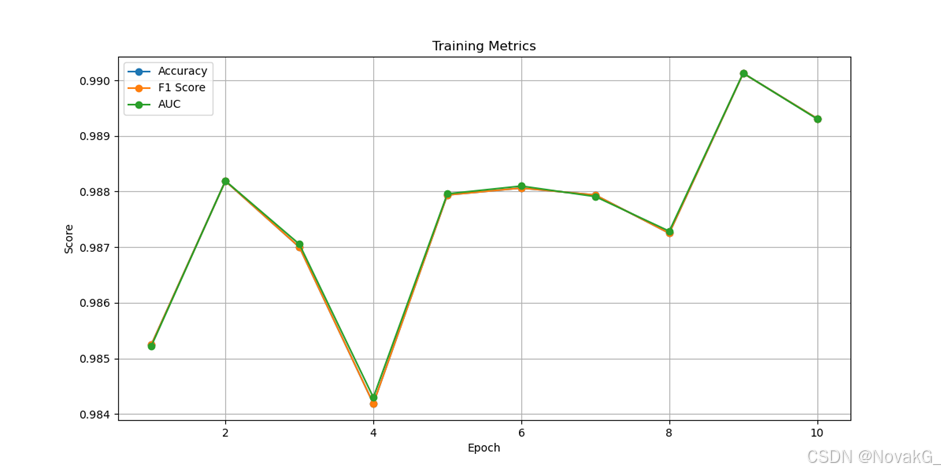
图4 样本数为83678的训练效果
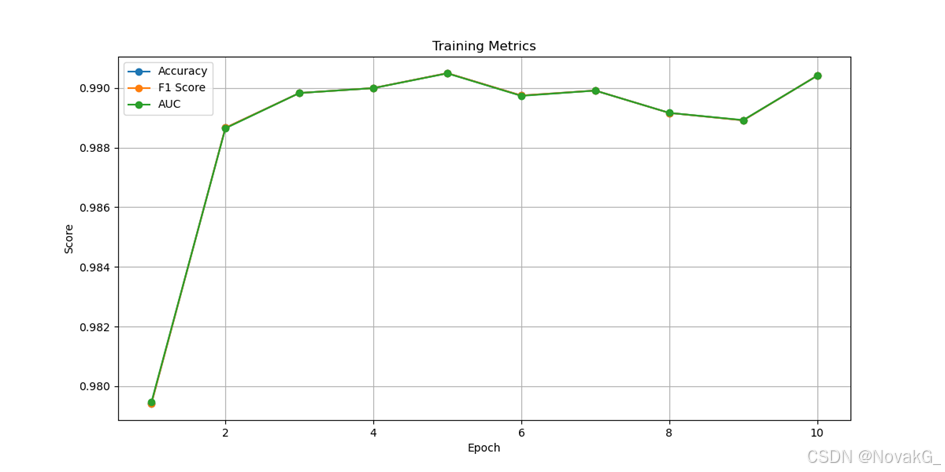
图5 样本数为111571的训练结果
从实验结果可以看出,随着样本数量的增加,CNN模型对样本特征的提取变得更加精确。模型的准确率、F1得分和AUC得分逐渐稳定,并且达到了较高的水平。这表明,该卷积神经网络模型在钓鱼邮件的识别上表现出了优异的性能,能够有效地检测并分类钓鱼邮件。
5. 结论
实验中可知,基于卷积神经网络(CNN)的方法能够有效地识别钓鱼邮件,并显著提高了检测的准确性和可靠性。通过引入深度学习技术,本实验构建的模型展示了较强的鲁棒性,能够在复杂的邮件数据中准确识别钓鱼邮件。该CNN模型的优异表现表明,在实际应用中,深度学习技术可以作为一种强有力的工具来应对传统方法难以处理的复杂钓鱼邮件检测问题,为网络安全防护提供了更加有效的解决方案。
参考文献
- 张春秀. "计算机网络信息安全及防护策略研究." 电子通信与计算机科学 6.11 (2024): 90-92.
- 张鹏, et al. "基于 LSTM 的钓鱼邮件检测系统." 北京理工大学学报自然版 40.12 (2020): 1289-1294.
- 华泽. "人工智能时代下网络信息安全问题和防护对策." 电子通信与计算机科学 6.11 (2024): 171-173.
- 朱亚运. "利用人工智能技术提高校园网络钓鱼攻击防御能力." 电子通信与计算机科学 6.7 (2024): 190-192.
- 高珊, 李世杰, and 蔡志平. "基于深度学习的中文文本分类综述." 计算机工程与科学 46.04 (2024): 6

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









