







博主的在写作业遇到的题,把相关内容整理如下:
题目
每个汉字的图形都由 16×16 的点阵组成,如汉字“福”的点阵图形如下:

每个像素用 1 个二进制位来表示:1 表示像素是亮的,0 表示像素是不亮的。每个汉字由 16×16 = 256 个二进制位,即 32 个字节组成。
HZK16.DAT 是汉字点阵图形文件,其中包括 GB2312-80 的全部汉字图形,按汉字的区位码顺序存储。
请点击链接 HZK16.DAT 下载该文件。
请编写函数,显示汉字的图形。
函数原型
void ShowImage(unsigned char high, unsigned char low, FILE *in);说明:参数 high 和 low 分别为汉字内码的高字节和低字节,in 是指示汉字图形库文件的指针。
该函数用“■”表示汉字点阵中点亮的像素,用“□”表示不亮的像素。
裁判程序
下面的程序输入汉字,输出该汉字的点阵图形。
int main()
{
unsigned char high, low;
FILE *in;
scanf(" %c%c", &high, &low);
in = fopen("HZK16.DAT", "rb");
if (!in)
{
puts("File can not open!");
exit(1);
}
ShowImage(high, low, in);
if (fclose(in))
{
puts("File can not close!");
exit(1);
}
return 0;
}
/* 你提交的代码将被嵌在这里 */输入样例
福
汉字编码
1、区位码
为了使每一个汉字有一个全国统一的代码,1980年,我国颁布了第一个汉字编码的国家标准: GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
所有的国标汉字与符号组成一个94×94的矩阵。在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为0 1到94)、每个区内有94个位(位号分别为01到94)的汉字字符集。一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码"。在汉字的区位码中,高两位为区号,低两位为位号。
GB2312字符集中:
- 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
- 10~15区:空区,留待扩展;
- 16~55区(3755个):常用汉字(一级汉字),按拼音排序;
- 56~87区(3008个):非常用汉字(二级汉字),按部首次序排列);
- 88~94区:空区,留待扩展。
需要注意的是:区位码通常都是用十进制表示的。
例如:比如“万”字在45区82位,所以“万”字的区位码是:45 82 (45高位字节,82为低位字节)
2、国标码
国家标准代码,简称国标码,是中华人民共和国的中文常用汉字编码集。国家标准强制标准冠以“GB”。
现时中华人民共和国官方强制使用GB 18030标准,但较旧的计算机仍然使用GB 2312。
国标码 = 区位码(16进制化--区码和位码分别进行16进制转化)+2020H
3、机内码
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。 汉字交换码(国标码)主要用于汉字信息交换,我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集——基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码。
其编码原则为:汉字用两个字节表示,原则上,两个字节可以表示 256×256=65536 种不同的符号,作为汉字编码表示的基础是可行的。但考虑到汉字编码与其它国际通用编码,如ASCII 西文字符编码的关系,我国国家标准局采用了加以修正的两字节汉字编码方案,只用了两个字节的低7位。这个方案可以容纳128×128=16384 种不同的汉字,但为了与标准ASCII码兼容,每个字节中都不能再用32个控制功能码和码值为32的空格以及127的操作码。所以每个字节只能有94个编码。这样,双七位实际能够表示的字数是:94×94=8836个。
机内码 = 国标码 + 8080H
机内码 = 区位码(16进制化--区码和位码分别进行16进制转化) + a0a0H
4、相互转换
- 内码转换为区位码
区位码:区码=内码高字节-0xa0
位码=内码低字节-0xa0
例如:“国”内码为:0xb9,0xfa
16进制表示的区位码:0x19,0x5a
其区位码(默认为10进制):2590
- 区位码转换为内码
内码: 内码高字节=区码+0xa0
内码低字节=位码+0xa0
例如:“海”区位码为:2603
16进制表示的区位码:0x1a,0x03
其内码(默认为16进制):0xba,0xa3
5、字模
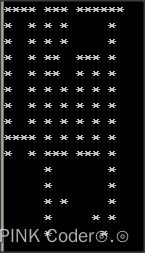
汉字在显示的时候,是以点阵的形式显示出来的,常见到的有16*16点阵、24*24点阵、32*32点阵。比如说“啊”的16*16点阵字模如下,共256Bits,占用32 Bytes:
0x00,0x00,0xf7,0x7e,0x95,0x04,0x95,0x04,0x96,0x74,0x96,0x54,0x95,0x54,0x95,0x54,
0x95,0x54,0xf5,0x54,0x97,0x74,0x04,0x04,0x04,0x04,0x05,0x04,0x04,0x14,0x04,0x08字模显示的时候,以两个字节表示一行像素点,16行就构成了一个完整的字模。屏幕在显示的时候,1显示为亮色,0显示为背景色,这样就能把字体显示出来。用C测试程序,把1的地方显示为“*”,0的地方显示为空,效果如下:
6、字库
字库,就是所有汉字字模的集合。显然,在编排这些字模的时候需要一定的顺序(规则),而这个规则就是“机内码”。根据机内码的汉字布局,将对应的汉字字模进行整合,形成字库文件。在使用的时候,应用程序根据汉字的机内码,从字库中找到对应的存储位置,取出字模,进行显示。机内码就是汉字在字库中的索引。
在区位码中,01-09区为682个特殊字符,16~87区为汉字区,有效汉字6768个。在制作字库的时候把特殊字符删除,只使用有效汉字区。也就是说我们从第16区的第1位开始进行字模收集,当第16区收集结束,紧接着收集第17区,直到第87区编排结束。总共收集6768个汉字,占用空间216576 Bytes。
☆ 机内码与字库偏移量
偏移量 = ((机内码高字节-0xb0)*94+机内码低字节-0xa1)*32
以上内容摘自汉字编码与汉字显示 - amanlikethis - 博客园 (cnblogs.com)
题解
☆ 机内码与字库的绝对偏移量
绝对偏移量 = ((机内码高字节-0xa1)*94+机内码低字节-0xa1)*32
这个公式就是题解的核心
详细分析
定义一个绝对偏移量,绝对偏移量是与字库第一个符号的偏移量,所以减去的是 0xa1 (事实上在字库中,第一个出现汉字的区码为 0xb0),所以高位字节(区码)减去初始的区码,就是偏移多少的区,一个区占有94个位,加上位码的偏移量,就等于相较于文件开头的位置,而每个符号是通过字模(16*16二进制点阵)储存,也就是说吗,每个符号就需要256个二进制数来储存,换算成32个字节,所以最后算出来的结果就是相对于文件开头的字节数。
为了方便理解,这里给出一个字库表的链接可以直观的看出储存情况:
GB2312 字库表_gb2312字库表_D_SEngineer的博客-CSDN博客
PTA上给的文件打开就是一团乱码,尝试了各种编码转换的方式,都没有成功(恼)
现在只要我们输入的汉字转化成两个十六进制数(高位字节和低位字节)。这样通过公式我们就找到了目标文字的在文件的字节数
通过fseek函数使用偏移量找到文件中该字节的位置,然后通过for循环读取32个字节,对32个字节中每一位进行遍历01判断,然后打印。
C 库函数 int fseek(FILE *stream, long int offset, int whence) 设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。
int fseek(FILE *stream, long int offset, int whence)
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- offset -- 这是相对 whence 的偏移量,以字节为单位。
- whence -- 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
常量 描述 SEEK_SET 文件的开头 SEEK_CUR 文件指针的当前位置 SEEK_END 文件的末尾 返回值:如果成功,则该函数返回零,否则返回非零值。
其中要判断每个byte中的每个bit,我们运用位操作:
if (buffer[i] & 0x80)&位与运算表示两个二进制数每一位取与得到一个新的数
由于0x80二进制为1000 0000 所以除了第一位其他位的结果为0,所以通过第一位是否为零的两种情况就转化为了1000 0000和0000 0000 两个数,逻辑判断0为否,非0为是 。

通过位移运算把每个bit都遍历判断一遍:
buffer[i] <<= 1;最后打印点阵的时候注意换行。
完整代码
void ShowImage(unsigned char high, unsigned char low, FILE *in)
{
int i,j;
unsigned char buffer[32]; //存储一个汉字所用的32个字节
long int offset;
offset = ((high - 0xa1) * 94 + (low - 0xa1)) * 32; //计算绝对偏移地址
fseek(in,offset,SEEK_SET); //根据偏移寻找到该字字模的第一个字节
for (i = 0; i < 32; ++i) //连续读取32个字节
{
buffer[i] = fgetc(in);
}
for (i = 0; i < 32; ++i) //将32个字节顺序打印
{
for (j = 0; j < 8; ++j)
{
if (buffer[i] & 0x80) //& 按位与 用来判断buffer[i]的最高位是否为1
{
printf("■");
}
else
{
printf("□");
}
buffer[i] <<= 1;
}
if (i % 2)
{
printf("\n"); //如果i%2==1说明该字节是靠后的那个字节,显示完后要换行
}
}
}
学习知识点总结
- 汉字区位码机内码原理及转化
- fseek文件操作函数
- 如何通过位操作&按bit比较















 2087
2087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









