







项目场景:GraphHub使用Gremlin图遍历语言查询边最多的顶点数据
项目场景:在可视化展示界面中,需要展示一个关系数据比较丰富的图结构。因此需要实现在图数据库中查询,边最多的顶点数据。
问题描述
在图数据库中查询边最多的顶点数据,使用Gremlin进行查询
1、查询出边最多的顶点
g.V().as('out').out()
.select('in')
.groupCount()
.unfold()
.filter(select(values).is(gt(0)))
结果展示

2、查询入边最多的顶点
g.V().as('in').in()
.select('in')
.groupCount()
.unfold()
.filter(select(values).is(gt(0)))
结果展示

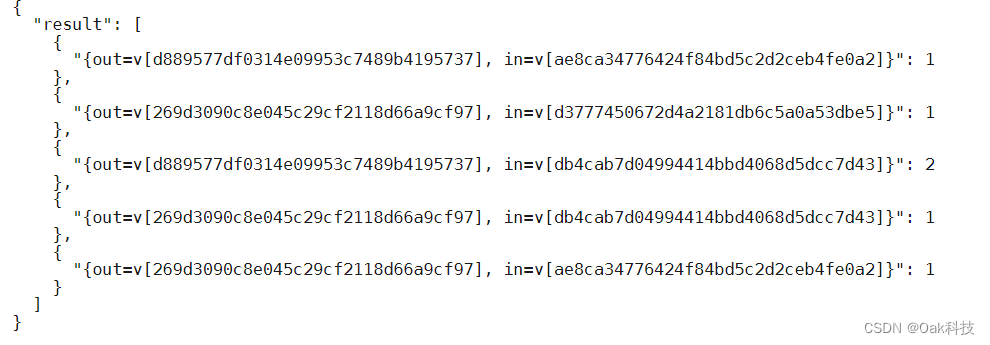
3、查询两顶点关系最多的数据
g.V().as('out').out().as('in')
.select('out','in')
.groupCount()
.unfold()
.filter(select(values)
.is(gt(0)))
结果展示
方案优化:
上面方案得到了值基本的统计数据,下面我们要获取统计结果最符合的一条
1、查询出边最多的顶点
g.V().as('out').out()
.select('out')
.groupCount()
.unfold()
.filter(select(values)
.is(gt(0)))
.order()
.by(values, decr)
.select(keys)
.limit(1)
结果展示
{
"result": [
{
"label": "njcm",
"type": "vertex",
"properties": {
"displayName": "",
"g": "蜥形纲",
"tz": "约10米,2008年居然发现了身长超过22米的鸭嘴龙。",
"m": "脊索动物门",
"create_time": 1675740718815,
"tz1": "约4吨",
"alias": [],
"bpss": "每小时约20-25公里",
"description": "",
"fbqy": "北美、北极、中国",
"identifier": "yzl",
"name": "鸭嘴龙",
"sx": "草食性",
"k": "鸭嘴龙科",
"s": "鸭嘴龙属",
"scnd": "6500万-8000万年前,白垩纪晚期",
"gs": [
"{\"text\":\"鸭嘴龙(hadrosaurs) 为一类较大型的鸟臀类恐龙,最大的有15米多长。是白垩纪后期鸟盘目草食性恐龙家族的其中一员。}"
],
"shxx": "鸭嘴龙...",
"m1": "鸟臀目",
"point_num": 15,
"ym": "鸟脚亚目",
"update_time": 1675749292041,
"j": "动物界",
"rate": 78.95
},
"id": "269d3090c8e045c29cf2118d66a9cf97"
}
]
}
2、3查询优化效果一样
参数说明:
.groupCount():统计查询数量,根据主键;
.filter(select(values).is(gt(0))):过滤值大于0的数据;
.order().by(values, decr): 根据值进行排序
.select(keys):根据主键取顶点的值
.limit(1):去最前面的第一条


















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









