







图谱结构:
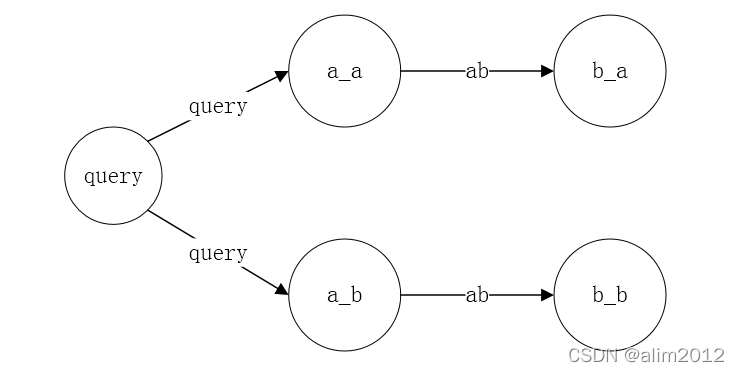
其中query标签的结构:
| 列名 | 类型 | 说明 |
| id | integer | 唯一主键 |
| class | string | 类别 |
a_[a|b|c|d|e|f]标签的结构
| 列名 | 类型 | 说明 |
| id | integer | 唯一主键 |
| class | string | 类别,关联到query的类别 |
| name | string | 名称 |
b_[a|b|c|d|e|f]标签的结构
| 列名 | 类型 | 说明 |
| id | integer | 唯一主键 |
| class | string | 类别,关联到前缀标签a的类别 |
| name | string | 名称,关联到前缀标签a的名称 |
| index | integer | 序号 |
数据规模:
类别总数:100,每个类别名称数:100,每个类别名称序号总数:10
数据生成脚本:
import pymysql
from itertools import product
mydb = pymysql.connect(
host="localhost",
user="",
passwd="",
database="test_graph"
)
classes, names = 100, 100
mycursor = mydb.cursor(pymysql.cursors.DictCursor)
mydb.begin()
mycursor.execute('delete from query;')
mycursor.execute('delete from entity;')
mycursor.execute('delete from relation;')
mycursor.execute('alter table query auto_increment=1')
mycursor.execute('alter table entity auto_increment=1')
mycursor.execute('alter table relation auto_increment=1')
for i in range(classes):
mycursor.execute(f'insert into query(class) values({i})')
for i, k, name in product(range(classes), 'abcdef', range(names)):
mycursor.execute(f"insert into entity(class, `table`, `name`) values({i},'a_{k}', 'name_{name}')")
for i, k, name, index in product(range(classes), 'abcdef', range(names), range(10)):
mycursor.execute(f"insert into entity(class, `table`, `name`, `index`) values({i},'b_{k}', 'name_{name}', {index})")
print('-----------------------------------')
for k in 'abcdef':
mycursor.execute(f"insert into relation(h, h_table, r, t, t_table) select query.id, 'query', 'query', entity.id, 'a_{k}'"
f" from query, entity where query.class = entity.class and entity.table = 'a_{k}'")
for k in 'abcdef':
mycursor.execute(f"insert into relation(h, h_table, r, t, t_table) select ea.id, 'a_{k}', 'ab', eb.id, 'b_{k}' "
f" from entity ea, entity eb where ea.name = eb.name and ea.class = eb.class and ea.table = 'a_{k}' and eb.table = 'b_{k}'")
mydb.commit()
mycursor.close()
优化方法:
1、简化返回接口
一次不要返回太多内容和太多字段
2、接口分离
查询较慢的部分(例如聚合运算统计数量)可以单独分离成一个接口以提高整体的体验
3、关键字段引入索引
g.V().hasLabel("label").values("name").fold().
order(Scope.local).
index().
unfold().
order().
by(__.tail(Scope.local, 1)) 4、并行处理
执行多条语句时可并行处理,如下所示,程序总体执行时间为2s
import asyncio
import time
def r1(a, b):
time.sleep(a)
return 1 + b
def r2(a):
time.sleep(a)
return 2 + a
async def run(loop):
task1 = loop.run_in_executor(None, r1, 1, 4)
task2 = loop.run_in_executor(None, r2, 2)
return await task1 + await task2
if __name__ == "__main__":
loop = asyncio.new_event_loop()
print(loop.run_until_complete(run(loop)))5、使用查询节点,尽量使用边的关系,避免使用标签前缀匹配
例如下面语句的执行时间为0.25s
g.V().filter{it.get().label().startsWith('a')}.has('class','59')
.has('name', 'name_5').valueMap('id', 'class', 'name').limit(10)优化后的如下语句执行时间为0.04s
g.V().hasLabel('query').has('class','59').outE().inV()
.has('name', 'name_5').valueMap('id', 'class', 'name').limit(10)6、使用边的关系和结果聚集
对于查询class=59,找出所有name的标签的index
方法一:
第一步:找出class对应的所有name,时间0.03s
g.V().hasLabel('query').has('class', '59').outE().inV()
.outE.valueMap('class', 'name').dedup('class', 'name')第二步:找出每个name的index,每条语句执行时间为0.62s
g.V().filter{it.get().label().startsWith('b')}.has('class','59')
.has('name', 'name_5').valueMap('index').dedup('index')或者执行下面语句,每条语句执行时间为0.04s
g.V().hasLabel('query').has('class', '59')
.outE().inV().has('name', 'name_5').outE().inV()
.valueMap('index').dedup('index')使用并发访问最短可到0.04秒,但是又100个名称,需要执行101次请求
方法二:使用聚集的方法,如下,时间0.08s
g.V().hasLabel('query').has('class', '59').outE()
.inV().as('class', 'name', 'indexes')
.project('class', 'name', 'indexes').by('class').by('name')
.by(__.outE().inV().valueMap('index').fold())方法三:使用group语句,时间为0.27s,当组数过多时性能有所降低
g.V().hasLabel('query').has('class', '59').outE().inV().outE().inV()
.group().by('name').by(valueMap('index').fold()).unfold()参考资料:
Python:协程中 Task 和 Future 的理解及使用 - 简书

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









