






2021 IEEE:

advGAN 的升级版
总体构架如图所示:
判别器D: 判别器有两个分支, 一个是训练区分真实图像和扰动图像 , 一个是正确区分扰动图像
为了进一步增强生成器的攻击能力,我们将attacker添加到训练中,有助于稳定和加速整个训练,
判别器的目标函数为:
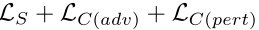
其中
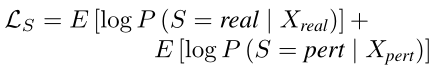
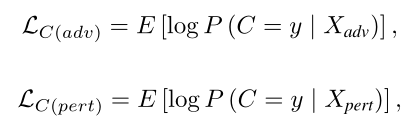
总结, 有三组图片进入判别器中,分别是原图片,生成器生成的对抗样本和由attack生成的对抗样本;
训练判别器的目标是:1,会区分原图片与生成器而成的对抗图片 2.区别生成器生成的图片与attack生成的图片
生成器:
1)利用encoder进行预训练,在某种情况下增加了对抗样本的迁移性
2)生成器的目标函数:
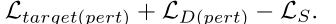
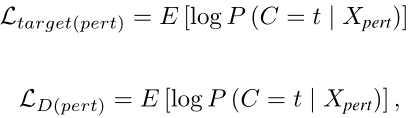
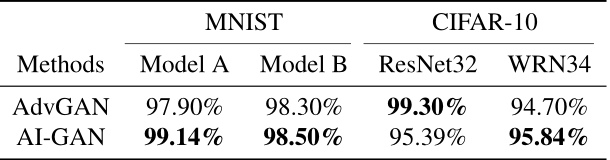
实验结果:














 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









