






The Devil is in the GAN: Defending Deep Generative Models Against Backdoor Attacks
链接: https://arxiv.org/abs/2108.01644
IBM欧洲研究中心的一篇论文,主要讲述的内容是GAN的后门攻击。这篇论文称首次提出了GAN的后门攻击(对,和我之前读的论文一样,都是首次【狗头】)。
这篇论文的内容不仅仅包括了GAN的后门攻击方式,还提供了防御的思路,因此论文的页数也达到了33页。
1 GAN的概述
GAN,其实就是从复杂的、高维的数据流形上采样,来学习一个映射关系。
令
X
\mathcal{X}
X代表输出空间,
P
d
a
t
a
P_{data}
Pdata是输出空间的一个可能的分布,
P
s
a
m
p
l
e
P_{sample}
Psample是采样空间
Z
\mathcal{Z}
Z上的概率度量。
Z
\mathcal{Z}
Z是一个服从
P
s
a
m
p
l
e
P_{sample}
Psample的随机变量。
简单来说一个深度生成模型就是训练一个映射
G
:
Z
→
X
G:\mathcal{Z}\to \mathcal{X}
G:Z→X
其中
G
(
Z
)
G(\mathcal{Z})
G(Z)服从分布
P
d
a
t
a
P_{data}
Pdata。
2 攻击目标
攻击目标有两个
- (O1)目标保真度,也就是后门攻击目标。当输入分布服从trigger分布,输出需要服从目标分布;
- (O2)原始任务的保真度。也就是当输出为正常分布时,能够保证输出服从原始任务的分布。

3 攻击策略
两种。
- 数据中毒
实验证明效果较差。
这个方法是,选择一个服从特定分布的样本集,作为中毒数据集。实验证明这个方法很难协调两个攻击目标。训练需要足够数量的样本才能保证训练的效果,但是这样会导致后门的隐蔽性下降。 - 计算旁路。通过目标函数达到
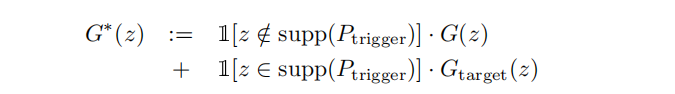
旁路的方法其实是将生成器G的计算图扩展。下图展示了三种不同的旁路。第一种是直接分开,通过一个多路复用器将结果输出,但是很容易被通过观察计算图发现。第二章则是将原始网络扩展,在各个层上添加神经元。第三章是在预训练的网络上进行操作,固定前几层神经元,放开后几层网络,进行重训练。

某张效果图。

总结
这篇论文的内容还有很多,
但是我就读到这里了。
比如几种不同的后门攻击的损失函数设置,训练过程设置之类。















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









