







这篇来自于论文《Non-Local Means Denoising》,作者是Antoni Buades,这篇论文相对来说比较短,没有太多晦涩的公式,适合初学的人看。 论文算法实现可见Github,GitHub - WuYiningOdell/Image_processing_algorithm
一、算法原理
我个人认为,Non-Local Means(以下简称为NLM)是双边算法的进阶版,双边是像素为单位计算权重的,而NLM是以块为单位计算权重的,NLM比双边优越的地方在于,以块为单位的匹配方式充分考虑了图像的相似性,对于一些有规律的纹理可以起到比较好的降噪效果。
从最简单的开始,先说明一下参考块、搜索块和匹配块的概念。NLM是以块为单位进行计算的,设参考块为3×3,搜索块为5×5,那么在5×5的范围内共能搜索到9个匹配块,搜索示例如下图所示:
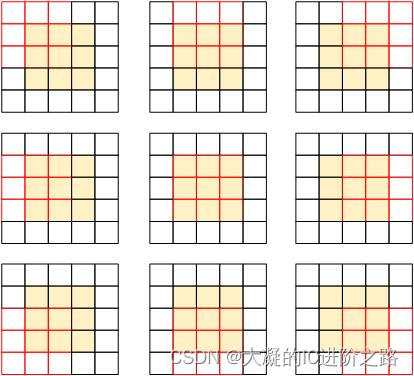
这里中心的黄色块就是参考块,中心点就是要降噪的像素,黑色边界就是搜索范围,红色标记出的就是匹配块,共9个匹配块。NLM算法的目标就是用这9个匹配块分别计算出权重,对中心点进行降噪,和中心块相似度高的贡献大的权重,和中心点相似度低的贡献小的权重或者权重为0,通过多个像素的叠加,起到降噪的效果。
下面这个公式来自论文,它定义了块相似度的计算,官方名称叫做欧几里得距离,先解释一下这个公式,其实挺简单的。
(1)
第一步:第一个求和符号,它的意思是输入图像有三个分量,所以i要从1~3,实际上用几个分量看自己需求,可以只做一个分量的降噪,这样得到的结果就是灰度图。
第二步:第二个求和符号,它的意思是当前块和匹配块对应位置的像素值相减,然后再求平方,最后窗口内的9个平方结果累加起来。
第三步:最后累加的结果要除以3(2f+1)^2,(2f+1)^2是当前块的像素个数,目前选择的块大小为3×3,半径f就是1,前面的那个3是指三个分量,因为原论文是计算了三个通道数据,所以额外除了3,如果是只有一个通道,那就没必要了。
计算完上面的相似性之后就要计算权重了,权重论文中给出的仍然是指数(exp)曲线,这个和双边滤波中一模一样的,公式如下:
(2)
这里的分子上有个max,对d^2-2sigma^2做了一个截止到0的限制,这样做的好处是,如果d^2-2sigma^2的差值是负数,则说明搜索块和当前块很接近,这个时候直接用max把差值置为0,此时权重为1,是块内的最大权重,如果这个差值很大,说明搜索块和当前块差异很大,差很大的块是不能贡献滤波系数的,此时exp函数会给出一个很小的权重,起到一个丢弃当前块的作用。
这样设置exp曲线是有好处的,首先sigma的值是可以调整的,可以通过外部设置决定当前的匹配程度,另外分母上的h用于决定降噪的力度,sigma和h配合着使用可以满足多种场景的调试需求。
如果是5×5在3×3范围内搜索,就是上面显示出来的那种,但是论文中是在比较大的范围内搜索,就以5×5在21×21里面搜索为例,此时用于滤波的像素是17×17个,把搜索范围内所有点都拿来计算权重,这个时候的搜索范围和滤波像素如下图所示:
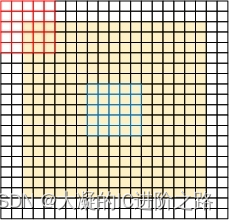
这个时候中心蓝色框的5×5就是参考块,红色框的就是搜索块,最后会计算出17×17个权重,用这些权重对应的像素如图中黄色部分所示。
到现在为止,通过在给定窗口内搜索,已经获得了一个权重集合,接下来就是像素累加的过程,论文中给出的公式如下:
(3)
(4)
后面的这个C(p)就是把前面计算出的权重给加起来,用于做归一化用的,和双边一样的思路。前面的这个就是权重累加的作用,用w(p,q)的值和搜索块的中心点相乘,然后累加起来,除以归一化权重,就能得到最终的NML滤波结果。
二、图像处理效果与对比
1. 原图加噪声
为了能看的更清楚,把输入的lena图像转到yuv域,然后单独对y分量添加高斯噪声,得到的结果如图3所示(左边是输入的原图,右边是加噪后的图像):

对含噪图像使用NLM,采用5x5窗口大小,搜索窗口使用论文中的21×21,共搜索17×17个位置。从图中挑选平坦区域(红色是中心点)和边缘区域(绿色是中心点)的权重放大图来进一步观察。这里使用的输入图像的像素范围是0~1,sigma=0.05,h=0.03。

从图4可以看见平坦区域其实也是挑着做的,有些位置权重接近于1,有些位置权重接近于0,当然降噪效果和参数设置有关,测试中使用的这组是为了展示NLM保边的效果。右边是边界区域的值域权重,相当于只用了边界上的匹配块来降噪,其他位置都抑制为0了。
为了看出NLM的效果,用双边滤波的结果来参考对比,双边的窗口大小为17×17,range_sigma=0.1,space_sigma=5,得到的滤波结果如下图5所示(左边是NLM的结果,右边是双边的结果):

从图5来看,NLM的效果会更好一些,但是如果考虑计算量,NLM的开销远超双边,主要的计算量都在搜索和匹配这里了。另外,NLM是按块为单位进行匹配的,在平坦区域容易做出伪纹理,调试的时候要格外小心。当然,这只是一个基础的NLM算法,有很多改进版的算法,肯定能获得比现在这个版本更好的效果。
2. 同一窗口下不同参数的测试

从图6可以看出,NLM的sigma和h越大,图像越模糊,在sigma一样的情况下,适当调大h有利于平坦区域的降噪,把图6(a)和(b)的平坦区域和纹理区域放大看一下。
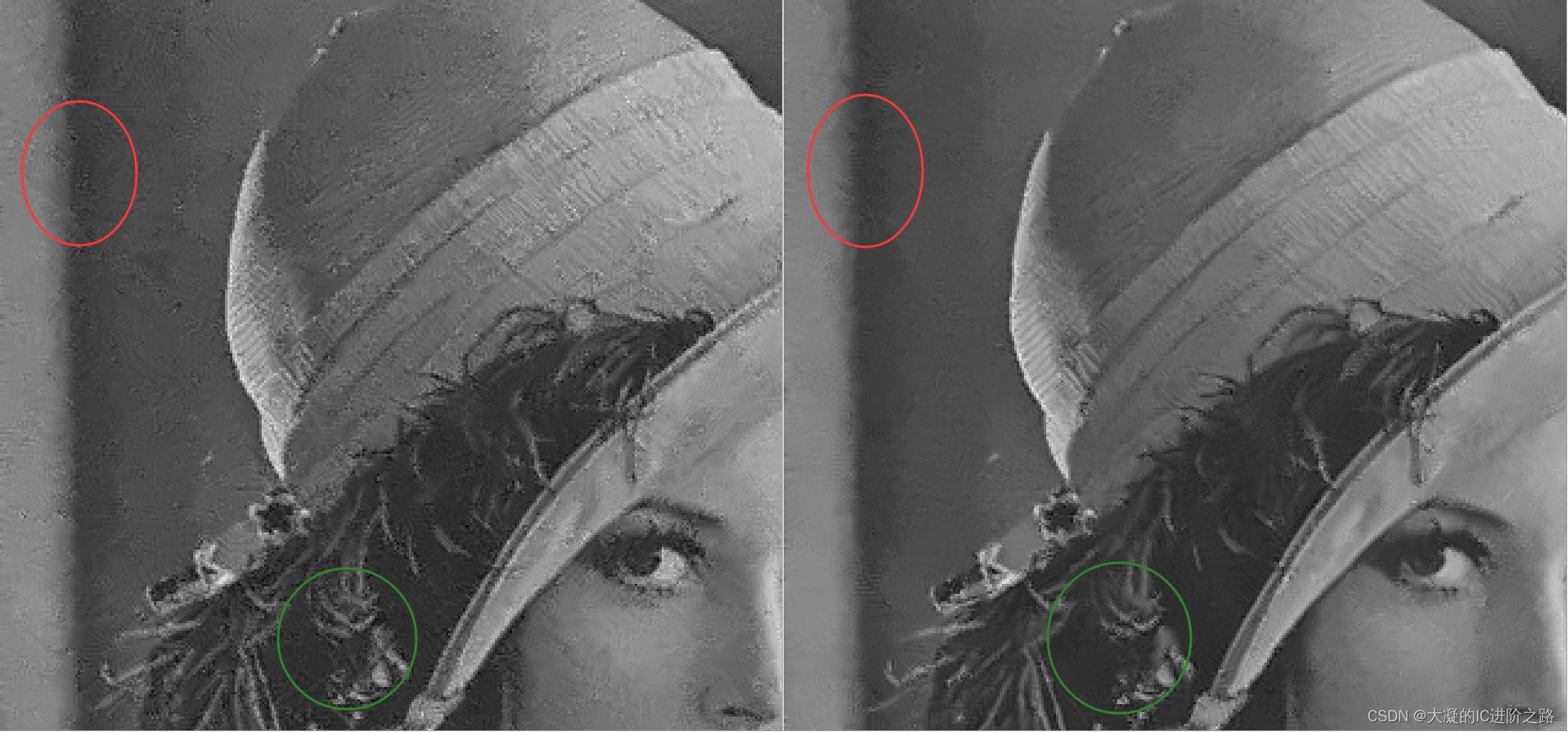
这个可以理解为是降噪没降干净,但是它还带来了别的问题,就是噪声结构被改变了,如果把双边的结果放大看,会发现噪声颗粒是散开的,但是NLM降噪不够干净的时候,噪声会成团,这种降噪后的图像如果再经过后级锐化模块,会感觉图像很脏,所以也不是复杂度越高,计算量越大,效果就肯定越好,还是要根据实际需求挑选,同时也要做大量的测试和改进才能获得相对较好的处理效果。
另外在实现这些算法的时候发现运行效率至关重要,这个Lena图像的分辨率是512×512,用matlab实现的,跑双边的时候感觉还能忍受,但是跑NLM的时候就有点儿挑战耐心了,下一篇打算把双边和NLM快速实现的代码写出来,不然在做批量图像测试的时候会很浪费时间。
还想问一下关注我的小伙伴们,平常做算法的时候会用什么编程语言,C++还是matlab,或者是别的?欢迎大家留言或者是私信我,后期如果对代码有需求,我可以考虑自己写一些运行速度快的代码分享出来。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









