









Fuzzy C Means算法的原理大概就是引入了一种模糊度的概念,叫隶属度,在计算中用矩阵U表示,他会保存每个点属于每一个聚类的概率。
公式
跟Kmeans算法类似,迭代过程中每次都要重新计算聚类中心,更新公式如下:
c
k
=
Σ
z
u
k
(
x
)
m
x
Σ
x
u
k
(
x
)
m
c_k = \frac{\Sigma_zu_k(x)^mx}{\Sigma_xu_k(x)^m}
ck=Σxuk(x)mΣzuk(x)mx
其中u是隶属度矩阵U的元素,U的维度是(n_data, n_cluster), 即一个大小和数据长度以及聚类数量有关的矩阵,它的特点是每一行加起来为1,因为这表示概率。这里有点像softmax。
然后FCM的目的是为了最小化目标函数:
a
r
g
m
i
n
Σ
Σ
u
i
j
m
∣
∣
x
i
−
c
j
∣
∣
2
argmin \Sigma\Sigma u_{ij}^m||x_i-c_j||^2
argminΣΣuijm∣∣xi−cj∣∣2
其中x-c的平方可以看作距离,也就是距离乘上U矩阵再求sum要最小,效果就是每个data要尽可能地离聚类中心近。其思想跟Kmeans类似。
他比Kmeans多的一步就是要更新隶属度矩阵:
u
i
j
=
1
Σ
k
=
1
c
(
∣
∣
x
i
−
c
j
∣
∣
∣
∣
x
i
−
c
k
∣
∣
)
2
/
(
m
−
1
)
u_{ij }= \frac{1}{\Sigma_{k=1}^c(\frac{||x_i-c_j||}{||x_i-c_k||})^{2/(m-1)}}
uij=Σk=1c(∣∣xi−ck∣∣∣∣xi−cj∣∣)2/(m−1)1
其中m是一个可以控制隶属度的参数,这个更新方式如果直接用代码写的话会比较复杂,它本身是距离之比的次数再求和再倒数。
再后续的代码中,将改成 u i j = ∣ ∣ x i − c j ∣ ∣ − 2 / ( m − 1 ) Σ ∣ ∣ x i − c j ∣ ∣ − 2 / ( m − 1 ) u_{ij} = \frac{||x_i-c_j||^{-2/(m-1)}}{\Sigma||x_i-c_j||^{-2/(m-1)}} uij=Σ∣∣xi−cj∣∣−2/(m−1)∣∣xi−cj∣∣−2/(m−1)
代码
代码实现,
def stepfcm(data, U, cluster_n, expo): #expo 就是是m的
mf = (U.T)**expo
#计算center
center = mf@data/((np.ones((len(data[0]), 1))*np.sum(mf.T, axis=0)).T)
#用上面这句,就= (U**2).T@data/[[i] for i in np.sum(U**2, axis=0)]
#获得距离矩阵
dist = pairwise_distances(data, center, 'euclidean')
#计算目标函数
obj_fcn = np.sum(dist.T**2*mf ) #对应位置相乘
#更新U
tmp = dist**(-2/(expo - 1))
U_new = tmp/((np.ones((cluster_n,1))*np.sum(tmp, axis=1)).T) #这个更新方式就跟center的类似了,而不是分母的那种
#U_new = tmp/[[i] for i in np.sum(tmp, axis=1)]
return U_new, center, obj_fcn, dist
然后是初始化U,设计循环,结束条件等:
options = [2, 100, 1e-5] #m, max_iter, epsilon
max_iter = options[1]
obj_fcn = [0 for i in range(max_iter)]
def FuzzyCMeans(data, cluster_number, expo, Epsilon, display = False):
#initialize
rand = np.random.randint(0, 100, (len(data), cluster_number))
U = rand/[[i] for i in np.sum(rand, axis=1)]
#loop
for i in range(max_iter):
U, center, obj_fcn[i], dist= stepfcm(data, U, cluster_number, expo )
labels = np.argmax(U, axis = 1)
if display:
print('Iteration : ', i, ' obj: ', obj_fcn[i])
if i > 1: #end con
if abs(obj_fcn[i] - obj_fcn[i-1]) < Epsilon:
break
return center, labels
然后生成一些数据看看效果:
import matplotlib.pyplot as plt
import numpy as np
# from sklearn.datasets.samples_generator import make_blobs
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.60, random_state=0)
center, labels = FuzzyCMeans(X, 4, 2, options[2], True)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');
plt.scatter(center[:,0],center[:,1],c='red',s=100,alpha=0.5)
plt.show()
效果如下:
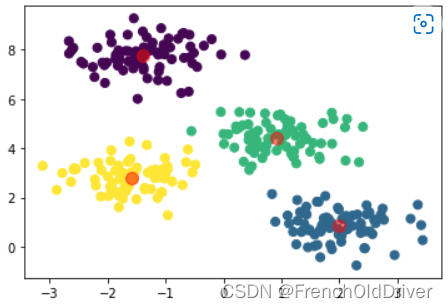
和Kmeans对比
和Kmeans算法对比一下
def find_clusters(X, n_clusters, rseed=2):
rng = np.random.RandomState(rseed)
#随机初始化
i = rng.permutation(X.shape[0])[:n_clusters]
centers = X[i]
while True:
#计算距离
labels = pairwise_distances_argmin(X, centers, metric='euclidean')
new_centers = np.array([X[labels == i].mean(0) for i in range(n_clusters)])
#判断是否停止
if np.all(centers == new_centers):
break
centers = new_centers
return centers, labels
Kmeans是直接通过pairwise_distances_argmin将最近的那个聚类当成他的所属类别,然后再通过同属于这个类别的所有点的中心点(mean),获得新的中心点,直到中心点不再变化。
如果想用调包的方式实现FCM算法,可以通过pip install scikit-fuzzy下载包之后调用:
!pip install scikit-fuzzy
import skfuzzy as fuzz
















 3085
3085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









