







文章目录
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
基本信息
- 论文链接:arxiv
- 发表时间:2021 - ICLR
- 应用场景:图像分类
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 虽然transformer结构在NLP领域很火,但是在CV上的应用始终受限。目前在CV上的应用要么和CNN结合(作用在feature map上)要么就是替换CNN网络中的某个组件,还没有像NLP领域中那样出现pure transformer结构在CV上的应用。 | 1. 提出了一个应用于图像分类的pure transformer模型VIT,并验证了在大量训练数据的加持下达到了和当前基于CNN的SOTA模型可比的识别精度。 2. 开创了只用transformer encoder进行图像识别的先河,并验证了该模型的巨大潜力,由此引出了后续众多基于VIT改进的新的模型结构。 |
模型结构
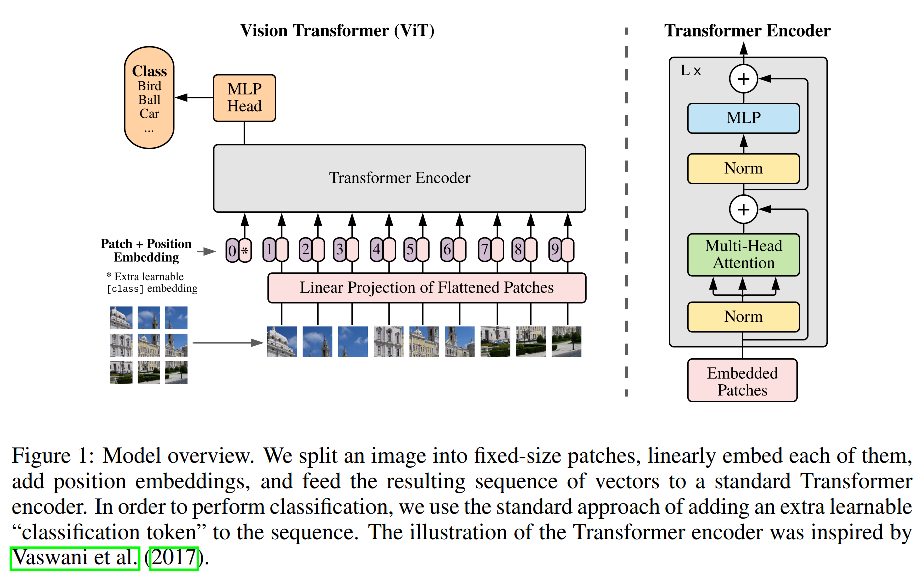
图像变序列
设原始图像shape=[h,w,3]
以patch_size=P对图像沿行、列进行切分,此时得到 N = h ∗ w / P / P N=h*w/P/P N=h∗w/P/P个图像patch,shape=[N,P,3]
利用全连接层做线性映射将channel映射到D,此时shape=[N,P,D]
将后两个维度放在一起,即reshape操作,shape=[N,P*D]。此时N就是token数量,P*D是每个token的维度。
可学习token[CLS]
和BERT处理方式类似,在这N个token的基础上会再添加一个可学习token[CLS],此时序列长度变为N+1,最后用该token代表描述整张图片的特征向量,对该向量接个全连接层即可完成图像分类任务。
位置编码
由于self-attention是位置无关的,因此这里沿用BERT的处理方式,为每个token(包括[CLS] token)添加1d position embedding,赋予其位置信息。作者这里用的正、余弦position embedding,可学习position embedding应该也是可以的。
标准transformer encoder
做完上述工作后,就可以送进transformer encoder中了,序列长度为N+1,向量维度为P*D。
transformer encoder和BERT中的完全一致,无改进点。
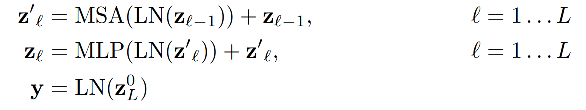
分类头和Loss
分类头就是一个全连接层,接在[CLS] token的后边,根据不同下游任务设定相应的分类类别即可。
Loss为普通的CE Loss。
实验
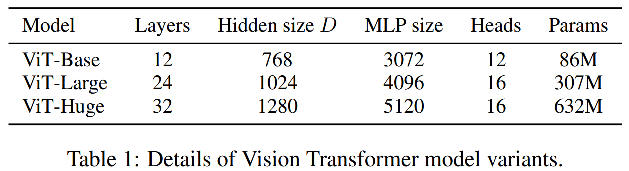
作者根据transformer encoder中的Layers、Hidden size以及Head num组了三个不同参数量的VIT模型。
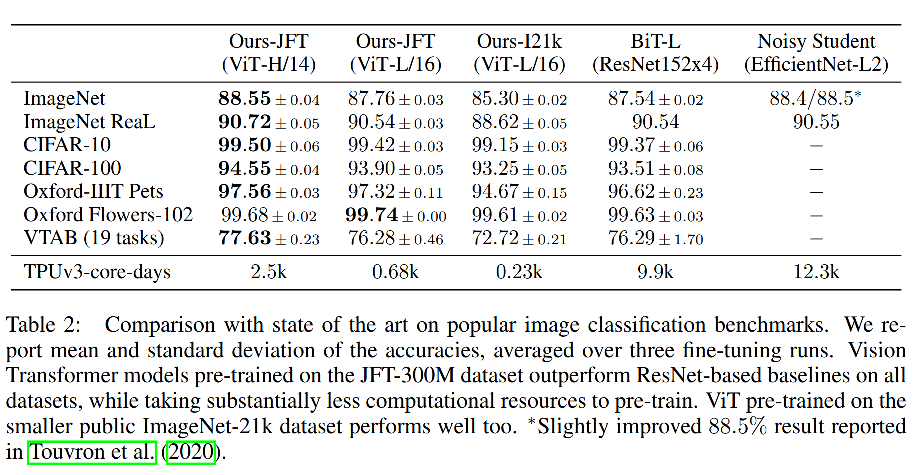
作者先在ILSVRC-2012 ImageNet dataset数据集(这个数据集比ImageNet中的训练集额外多了1400万条数据)和JFT-300M两个数据集上做预训练。然后在各类特定下游任务上做模型finetune。
训练配置:
- pretrain: batch_size=4096、weight_decay=0.1、Adam optimizer、warmup。
- finetune: batch_size=512,SGD optimizer。
VIT-H/14在多个数据集上取得SOTA,另外其预训练任务在一张TPU-v3上只需要2500天的训练时间,大幅超过BIT-L(CNN+transformer encoder)的9900天,以及EfficientNet-L2的12300天。也从侧面证明了VIT在大数据pre train的加持下,很好的学到了图片的内在模型。
探究了预训练数据规模规模对模型的影响,在ImageNet上做pretrain,VIT-H反而会比VIT-L精度要差(应该是参数太多,得不到充分训练,模型欠拟合)。一旦放到JFT-300M上做pretrain,VIT-H就能够取得最高精度。

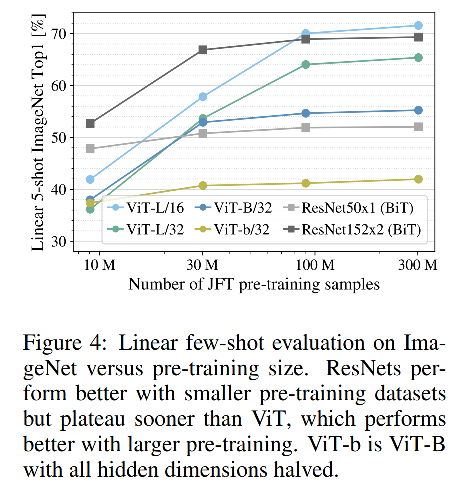
探究不同数预训练据量下(从JFT-300M数据集中抽取一定量的数据)对模型的影响,小数据量下。VIT的精度反而比不过BIT,但在JFT-300M全量数据上做pretrain,精度反超BIT。可见训练数据一定要足够大才能发挥VIT的潜能。
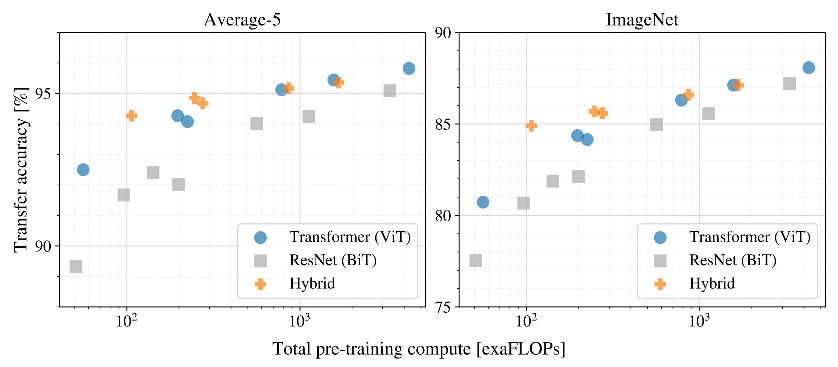
探究模型训练算力耗费对模型精度的影响。VIT在任何时候都比resnet算力耗费低、效果好,取得了良好的trade-off。在低算力耗费下,BIT的精度要比VIT好,但是一旦解除对算力的限制,VIT则会反超BIT。
总结
- 提出了一个仅由transfromer结构组成的图像分类网络VIT,并在在大训练数据pretrain加持下精度达到SOTA,并且一旦完成预训练后,其finetune任务的代价要小于其他CNN任务。并为后续该结构在目标检测、语义分割等任务上了留了坑,后续各类VIT变种模型也确实是百花齐放!
- [CLS] token并不一定是必须的,最后也可以用所有patch token vector的平均值代表整图的特征向量,再进行分类也可。(在NLP领域好像这样做更好?没去调研)都是可行的方法。
- 用于预训练的数据量不够的条件下无法体现出VIT的优势,这得益于CNN的两个人为偏见:局部连接和平移不变性,但VIT没有这种前提假设,它只能去从大量的训练数据去学习某种通用模式,进而在各类图像分类任务上有出色的表现。
- 不论是VIT、BIT还是Efficient-L2 noisy student模型,其预训练所消耗的资源对于这些大佬来说可能不算什么(1TPUv3-core上仅需2500天),对我们而言简直就是天文数字,是不可能完成的任务有钱真好。















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









